







这节课是机器学习算法概述,感觉都挺简单的,总结一下吧:
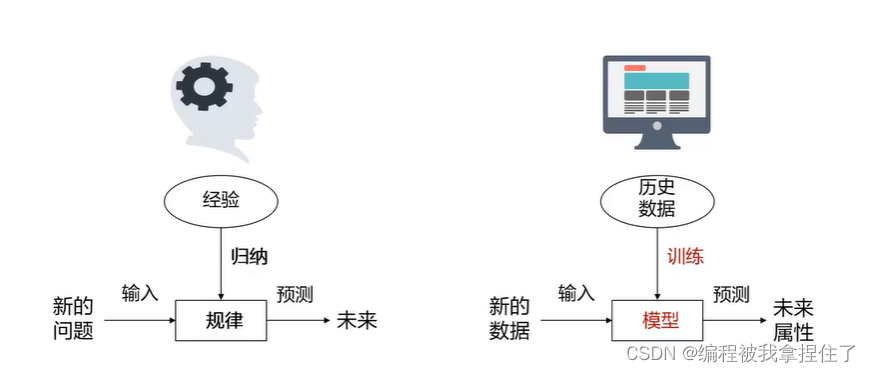
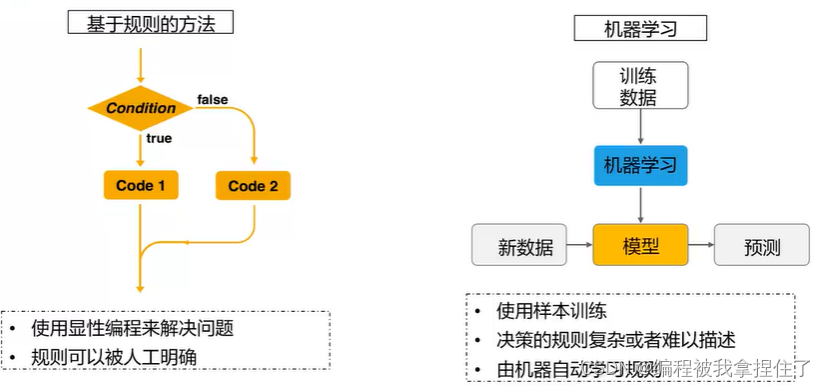 这两个图很是经典也很明晰,我觉得有必要先放一下。
这两个图很是经典也很明晰,我觉得有必要先放一下。
首先我认为,机器学习的表达式是这样的:
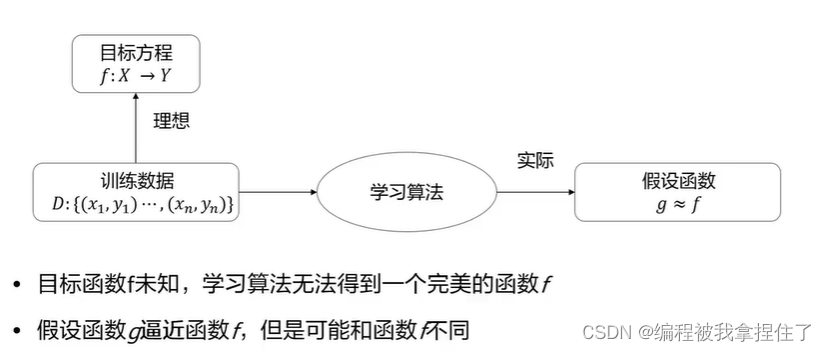
机器学习一般用来处理问题较为复杂并且问题规模大的问题,一般规则性的问题不足以处理此问题,因为数据越大,数据量越多,针对这个问题的数据分布就越完整,所学习得到的模型的参数就越可信,模型就越具有很好的泛化性能和鲁棒性。其实就是得到一个函数方程,这个函数也可以看作是线性代数里面的一个大的变换矩阵,将函数通过中间层的不断映射和计算映射到你所需要的空间里,来处理你的哪些任务,这是我浅显的理解。
机器学习可以处理的问题:分类,回归,(有监督);聚类(无监督)
机器学习类别:监督学习,半监督学习,弱监督学习、强化学习(模拟感知环境,做出行动,根据状态和奖惩做出调整和选择)
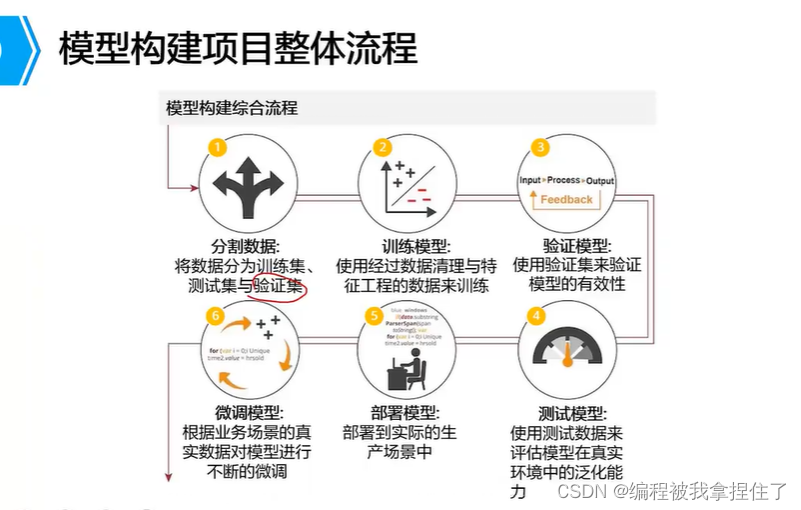
机器学习整体流程:
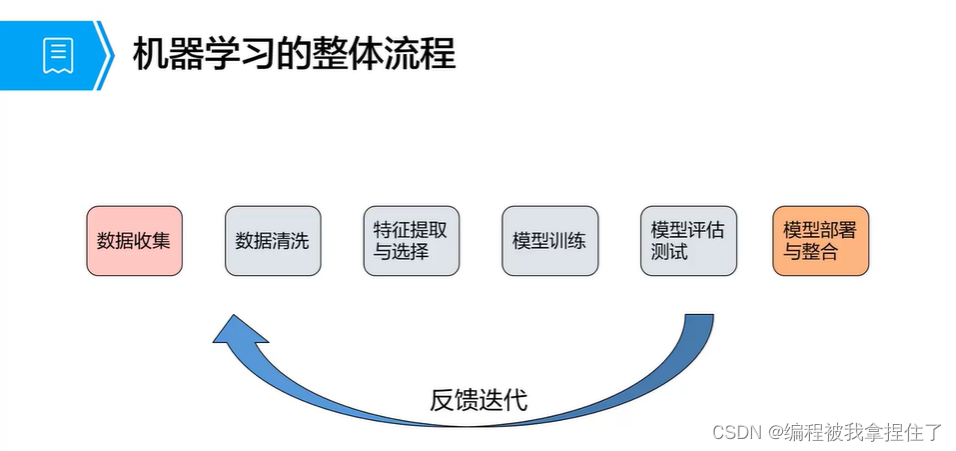 很经典的处理流程:
很经典的处理流程:
数据集:划分,训练集、测试集、验证集(结构化数据、非结构化数据)
数据预处理是至关重要的,他是模型性能的上限,数据清洗(处理异常值和缺失值),数据降维(防止维度爆炸和数据过拟合),数据标准化(减少噪音,讲特征属性放于同一尺度。
没有好的数据就没有好的模型!
你所做出来的模型或者结果,只是在尽可能地拟合你的数据的分布,而不是整个存在数据的分布,你的数据好坏也直接决定了你模型的好坏。
数据转换:(预处理后
分类问题中,通常将类别数据编码为对应的数值表示(哑编码);数值数据转换为类别数据以减少变量的值;非结构化数据(文本数据提取有用的词(词袋法),TF-IDF或者Word2vec),处理图像数据(颜色空间,灰度化,几何变换,harr特征,图像增强);特征工程:对特征进行归一化,标准化,保证模型的不同输入变量的值域相同,特征扩充:对现有变量进行组合或者转换以生成新特征,比如平均数,方差指标等等。
特征选择是非常有必要的!
Filter(过滤法):
其实就是找到特征与目标属性之间的相关性,这些方法应用一个统计度量来为每个特征赋值,然后根据分数给这些特征进行排序,然后就可以消除部分特征,但是弊端也非常明显,就是无法计算出特征之间的相关性(是否冗余),so:
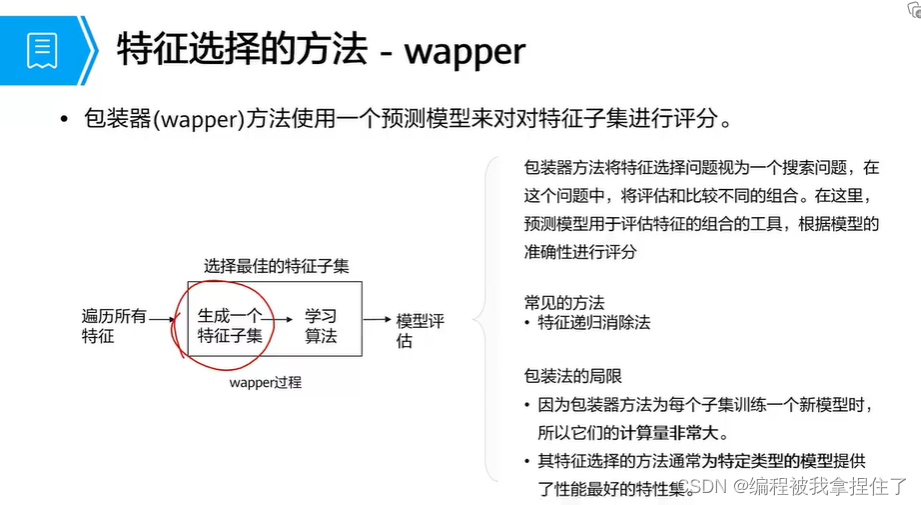
wapper(包装)法:
其实就是把特征和目标属性进行排列组合,生成所有可能的子集,把所有子集都分别算一个准确率,最后再选定,这其实对计算和时间成本是很高的,而且特定性很强,泛化能力很差,所以:
Embedding(嵌入法):
1.正则化方法(惩罚项)L1正则化进行特征筛选使模型复杂度降低,LASSO回归(L1)、RIDGE回归(L2)

有监督学习:
训练阶段:有特征->标签;预测阶段:特征->预测标签
模型的有效性:过拟合,欠拟合
过拟合原因:
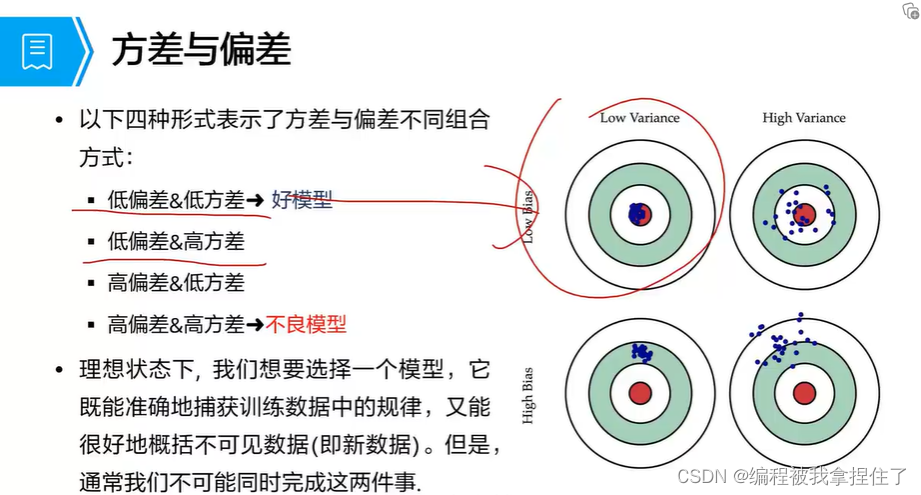
模型误差=偏差^2 + 方差 + 不可消解的误差
方差(Variance):
模型的预测结果在均值附近偏移的幅度;来源于模型在训练集对小波动的敏感性的误差。
偏差(Bias):
模型的预期(或平均)预测值与我们试图预测的正确值之间的差异。

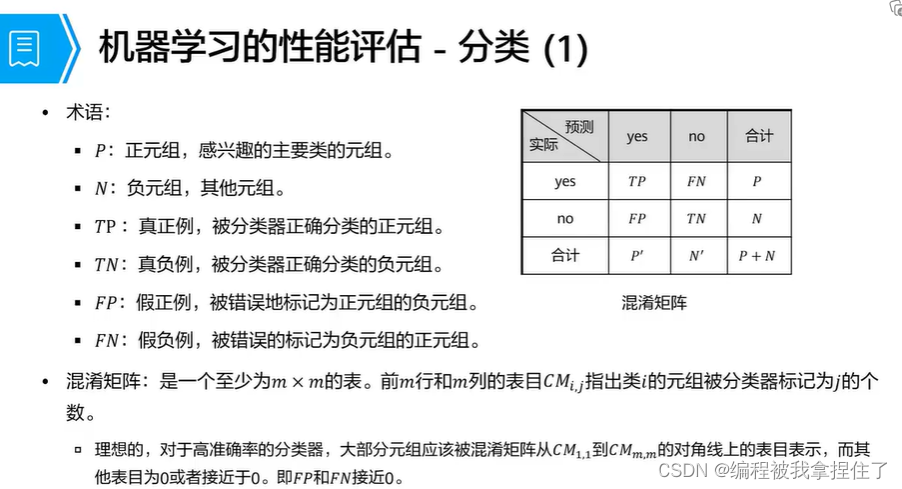
评价函数:

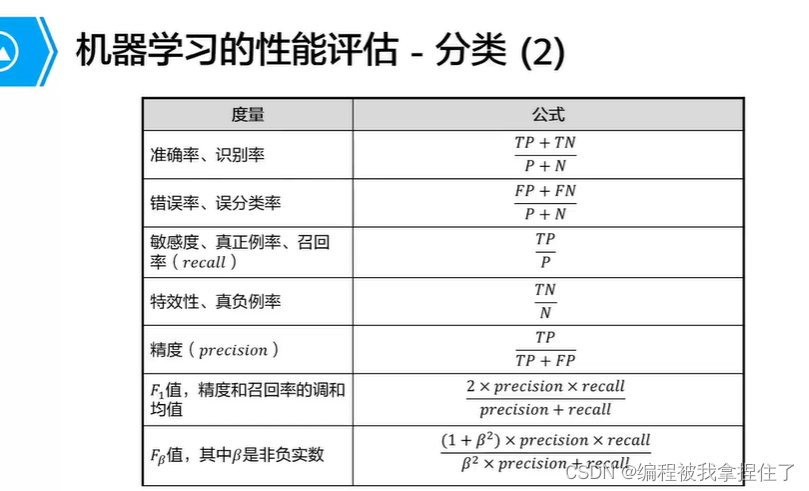
机器学习的几个重要方法:
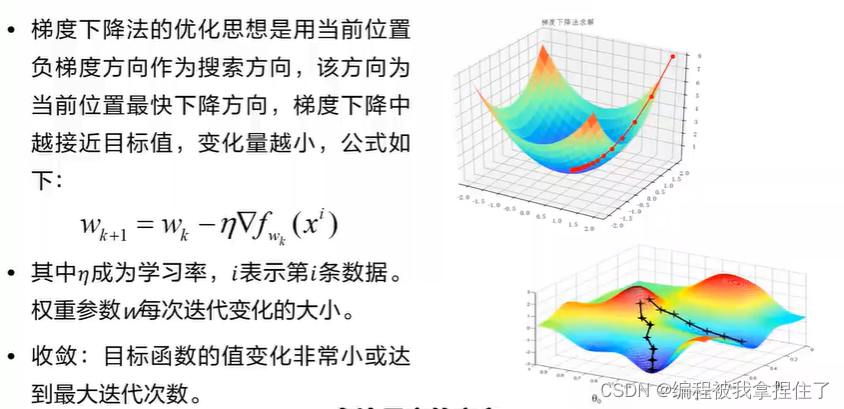
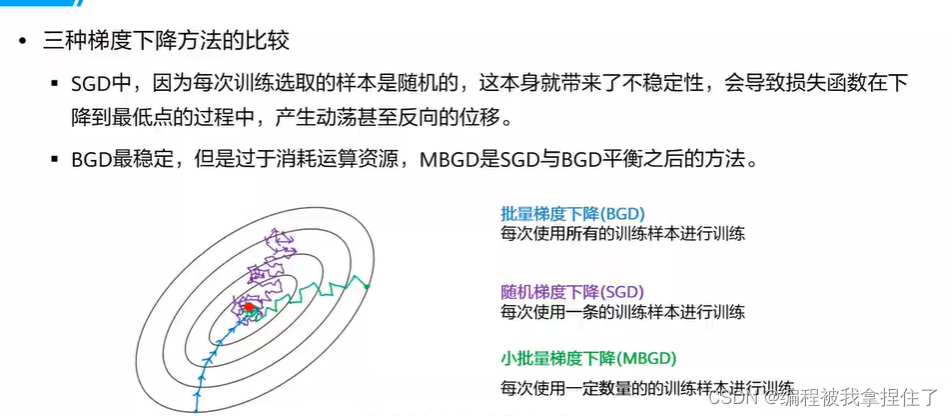
1.梯度下降

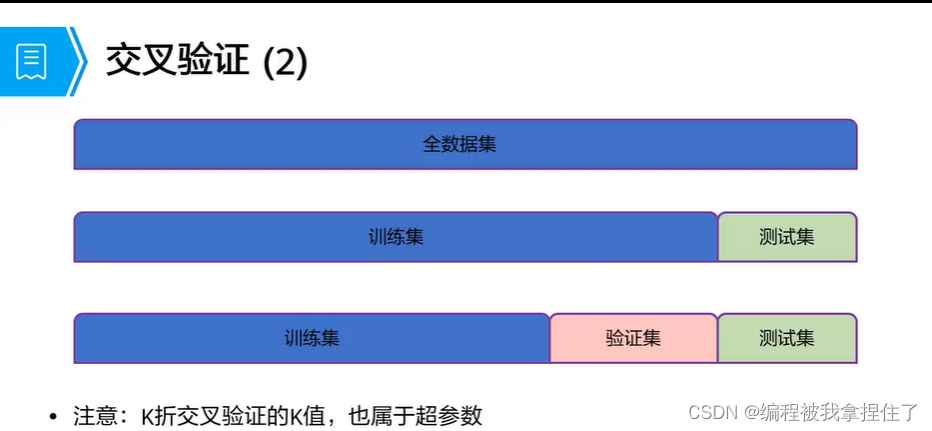
交叉验证方法:
K-折交叉验证
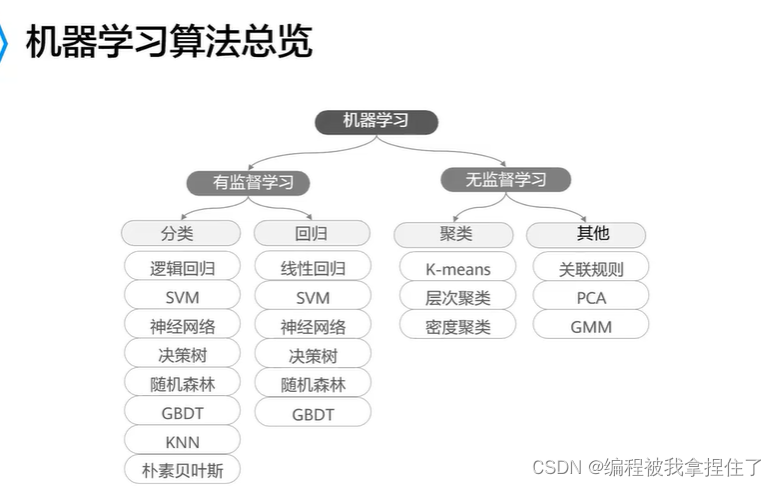
机器学习算法总览:
最简单的线性回归:
线性回归、多项式回归、过拟合->正则项;Lasso回归和Red回归.
逻辑回归:加了个sigmoid函数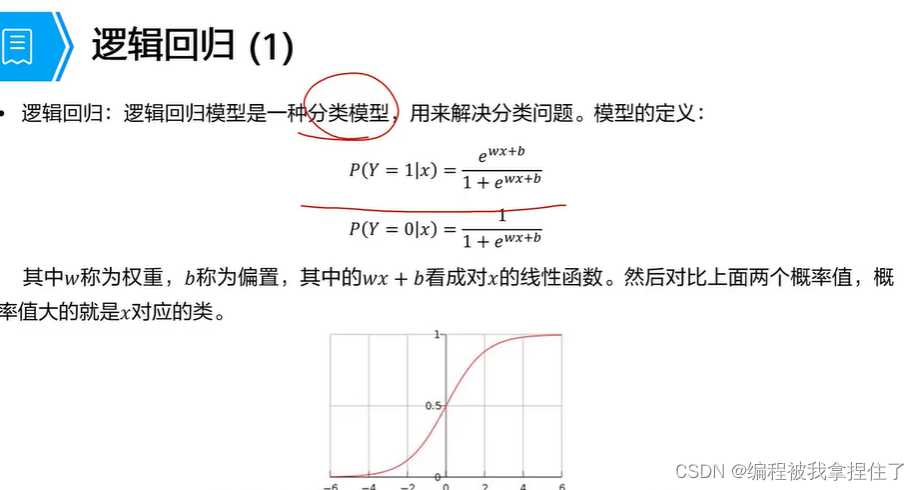
最大似然估计推出损失函数:
 softmax函数:
softmax函数:

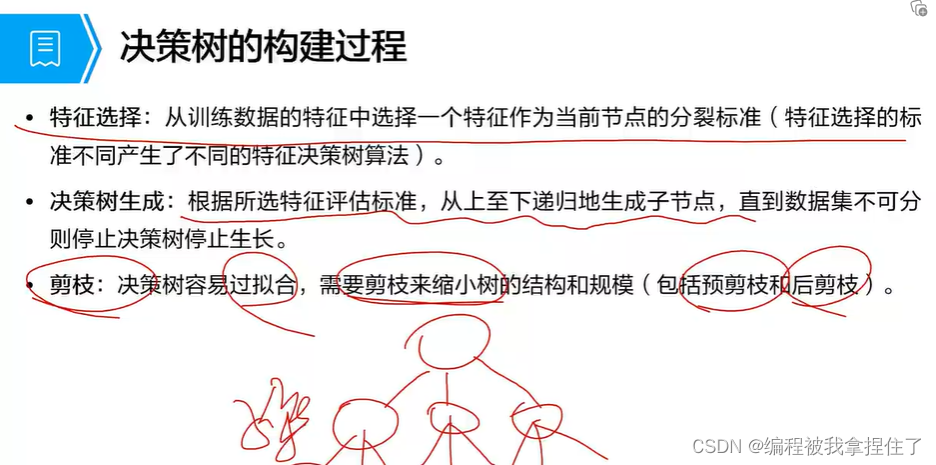
决策树:

根据信息熵和基尼系数作为量化指标,分割前与分割后的纯度差异越大,决策树越好。
通俗来讲就是:在分类前我的信息熵或者基尼系数的值很大,(数据越混乱越复杂),而在分类后他的信息熵或者基尼系数的值很小,(很小说明,这一特征(或属性只有一种样本,)说明决策树是非常成功的,本质是把混乱的样本分割成一个清晰的样本。
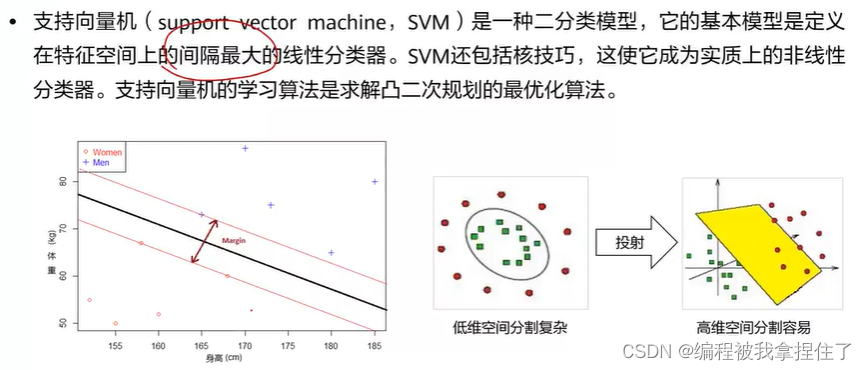
 支持向量机:
支持向量机:
定义在特征空间上的间隔最大的线性分类器。
包含的数学知识:拉格朗日乘子->对偶问题->KKT条件
硬间隔->过拟合(不允许错分,对噪声影响大);软间隔->(防止过拟合)允许错分样本。
核函数->映射到高维空间使得数据变得线性可分。(核函数使得低维空间和高维空间的内积相同)
K近邻算法:近朱者赤近墨者黑。

朴素贝叶斯:

我的理解:在我知道先验概率的情况下,然后计算后验概率。其实就是倒推的过程。
但是必须得假设特征之间是相互独立的
集成学习:多个学习模型组合起来来解决同一个问题。 前提是模型之间尽可能地数据分布的差异性大,让每个基分类器学到不同的特征,那么最后总和预测结果就会更好。
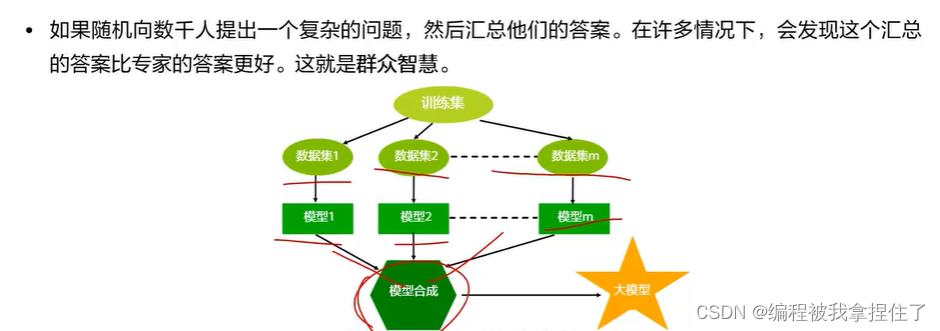
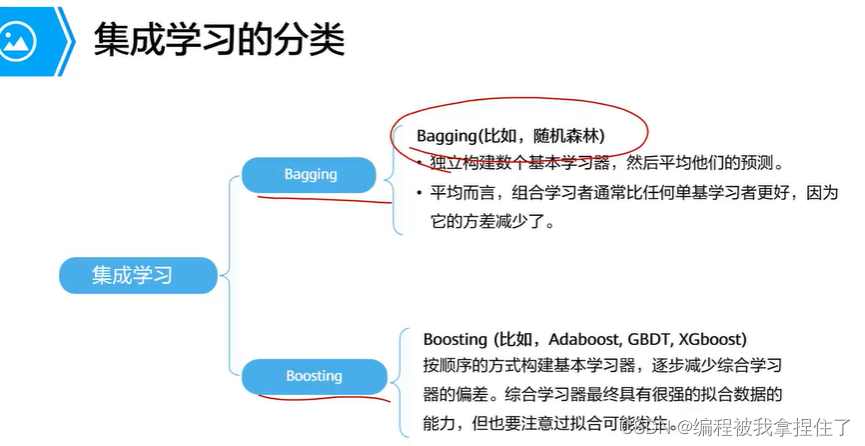
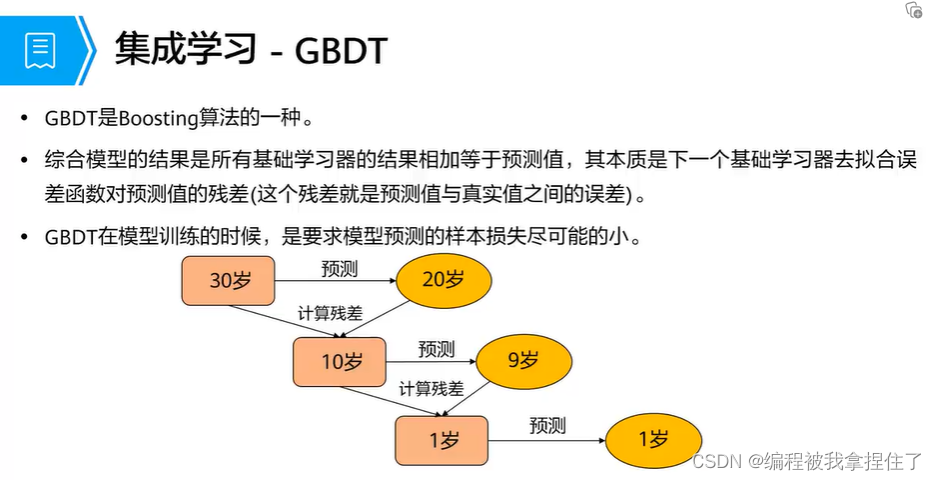
上面这个梯度提升决策树很有用,还有梯度提升决策树,总体的思想是,分步拟合,计算残差;然后继续 再拟合再计算残差....其实很容易过拟合。
K-Means,层次聚类....
直接代码实现把:(我使用的jupyter notebook)
代码实现:
1.线性回归:
from sklearn.linear_model import LinearRegression#导入线性回归模型 import matplotlib.pyplot as plt#绘图库 import numpy as np x = np.array([121, 125, 131, 141, 152, 161]).reshape(-1,1)#x 是房屋面积,作为特征 y = np.array([300, 350, 425, 405,496,517])#y 是房屋的 plt.scatter(x,y) plt.xlabel("area")#添加横坐标面积 plt.ylabel("price")#添加纵坐标价格 lr = LinearRegression()#将线性回归模型封装为对象 lr.fit(x,y)#模型在数据上训练 w = lr.coef_#存储模型的斜率 b = lr.intercept_#存储模型的截距 print('斜率:',w) print('截距:',b) plt.scatter(x,y) plt.xlabel("area")#添加横坐标面积 plt.ylabel("price")#添加纵坐标价格 plt.plot([x[0],x[-1]],[x[0]*w+b,x[-1]*w+b]) testX = np.array([[130]])#测试样本,面积为 130 lr.predict(testX)运行结果:
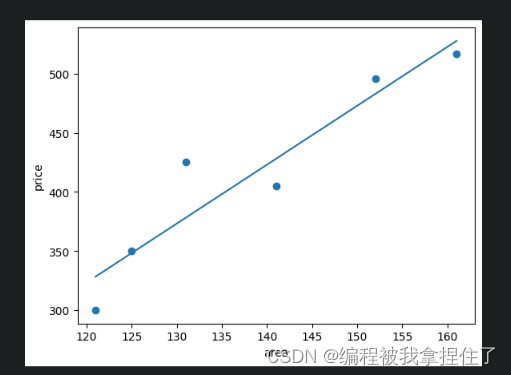
2. 手撕线性回归
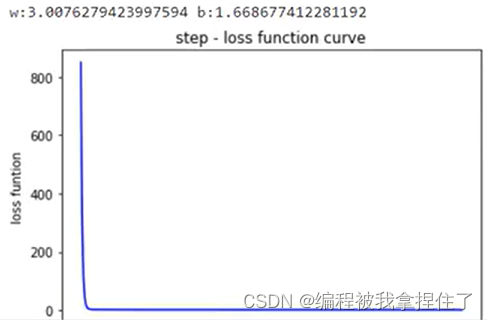
3.逻辑回归s
# 从 sklearn.preprocessing 里导入 StandardScaler。 from sklearn.preprocessing import StandardScaler # 从 sklearn.linear_model 里导入 LogisticRegression from sklearn.linear_model import LogisticRegression # X:每一项表示租金和面积 # y:表示是否租赁该房间(0:不租,1:租) X=[[2200,15],[2750,20],[5000,40],[4000,20],[3300,20],[2000,10],[2500,12],[12000,80], [2880,10],[2300,15],[1500,10],[3000,8],[2000,14],[2000,10],[2150,8],[3400,20], [5000,20],[4000,10],[3300,15],[2000,12],[2500,14],[10000,100],[3150,10], [2950,15],[1500,5],[3000,18],[8000,12],[2220,14],[6000,100],[3050,10] ] y=[1,1,0,0,1,1,1,1,0,1,1,0,1,1,0,1,0,0,0,1,1,1,0,1,0,1,0,1,1,0] ss = StandardScaler() # 标准化数据集,均值为0,方差为1 X_train = ss.fit_transform(X) #调用 Lr 中的 fit 模块训练模型参数 lr = LogisticRegression() lr.fit(X_train, y) testX = [[2000,8]] X_test = ss.transform(testX) print("待预测的值:",X_test) label = lr.predict(X_test) print("predicted label = ", label) #输出预测概率 prob = lr.predict_proba(X_test) print("probability = ",prob)
输出结果:
待预测的值: [[-0.68911581 -0.57680534]]
predicted label = [1]
probability = [[0.41886952 0.58113048]]
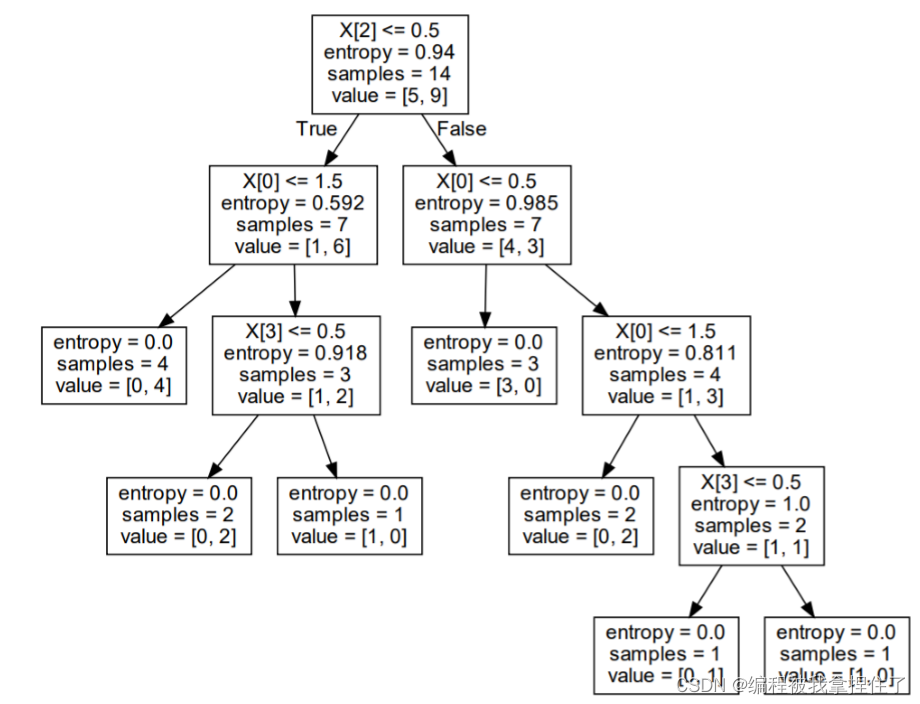
4.决策树
import pandas as pd import numpy as np from sklearn import tree import pydotplus #生成决策树 def createTree(trainingData): data = trainingData.iloc[:, :-1] # 特征矩阵 labels = trainingData.iloc[:, -1] # 标签 trainedTree = tree.DecisionTreeClassifier(criterion="entropy") # 分类决策树 trainedTree.fit(data, labels) # 训练 return trainedTree def showtree2pdf(trainedTree,finename): dot_data = tree.export_graphviz(trainedTree, out_file=None) #将树导出为 Graphviz 格式 graph = pydotplus.graph_from_dot_data(dot_data) graph.write_pdf(finename) #保存树图到本地,格式为 pdf # 定义函数,用于生成向量化数据 def data2vectoc(data): names = data.columns[:-1] for i in names: col = pd.Categorical(data[i]) data[i] = col.codes return data data = pd.read_table("tennis.txt",header=None,sep='\t') #读取训练数据 trainingvec=data2vectoc(data) #向量化数据 decisionTree=createTree(trainingvec) #创建决策树 showtree2pdf(decisionTree,"tennis.pdf") #图示决策树 testVec = [0,0,1,1] # 天气晴、气温冷、湿度高、风力强 print(decisionTree.predict(np.array(testVec).reshape(1,-1))) #预测输出:
否
其中,tennis.txt数据格式是这样的:

5.朴素贝叶斯
通过 jieba 文字分词库对邮件数据集的垃圾邮件和进行文本处理,提取特征。然后调用
sklearn 机器学习库中的朴素贝叶斯算法训练模型,最后推理测试集中邮件是否为垃圾邮件。from numpy import * from os import listdir import codecs #字符转换模块,用于文本的编码和解码 import jieba#中文分词库 import re from sklearn.naive_bayes import MultinomialNB from collections import Counter from itertools import chain #用于串联迭代对象 # 构建文本处理函数 def segment2word(doc: str): #从 stop_list.txt 文件中提取停用词,存储为列表 stop_words = codecs.open("./ML/04/stop_list.txt", "r", "UTF-8").read().splitlines() doc = re.sub('[\t\r\n]', ' ', doc)#去除邮件文本中的缩进,换行等 word_list = list(jieba.cut(doc.strip())) #用 jieba 进行分词 out_str = '' for word in word_list: #删去邮件文本中的停用词 if word == ' ' or word == '':# continue if word not in stop_words: out_str += word.strip() out_str += ' ' segments = out_str.strip().split(sep=' ') return segments # 构建文本读取函数 def getDatafromDir(data_dir): docLists = [] docLabels = [f for f in listdir(data_dir) if f.endswith('.txt')]#存储每一封邮件的名称 for doc in docLabels: try: filepath=data_dir + "/" + doc #对训练集的邮件进行文本处理 wordList = segment2word(codecs.open(filepath, "r", "UTF-8").read()) docLists.append(wordList)#整合训练集的邮件处理后的结果 except: print("handling file %s is error!!" %filepath) return docLists spamDocList=getDatafromDir("./ML/04/email/spam/") #对垃圾邮件进行文本处理 hamDocList = getDatafromDir("./ML/04/email/ham/") #对正常邮件进行文本处理 fullDocList = spamDocList + hamDocList#储存邮件的特征 # 添加标签,垃圾邮件标记为 1,正常邮件标记为 0 classList = array([1]*len(spamDocList)+[0]*len(hamDocList)) frequencyDic = Counter(chain(*fullDocList)) # 生成词频映射词典 topWords = [w[0] for w in frequencyDic.most_common(500)] #获取前 500 个最频繁的热词。 vector = [] for docList in fullDocList: #统计每封邮件中每个热词出现的频率 topwords_list = list(map(lambda x: docList.count(x), topWords)) vector.append(topwords_list) #生成 vector 作为数据特征 vector = array(vector) # 开始训练 model = MultinomialNB() #选取多项式贝叶斯为训练模型 model.fit(vector, classList) #vector 为特征,classlist 为标签,训练贝叶斯模型 # 模型预测· #存储每一封训练集邮件的名称 dataList=[] test_dir = "./ML/04/email/spam/" docLabels = [f for f in listdir(test_dir) if f.endswith('.txt')] #模型推理 for doc in docLabels: try: filepath = test_dir + "/" + doc dataList = segment2word(codecs.open(filepath, "r", "UTF-8").read()) except: print("handling file %s is error!!" % filepath) #统计测试集邮件中的热词的词频,提取特征 testVector = array(tuple(map(lambda x: dataList.count(x), topWords))) testVector_reshape = testVector.reshape(1,-1) #特征传入模型进行推理 predicted_label = model.predict(testVector.reshape(1, -1)) if(predicted_label == 1): print("%s is spam mail" %doc) else: print("%s is NOT spam mail" % doc)输出:
ham134.txt is NOT spam mail
ham148.txt is NOT spam mail
ham22.txt is NOT spam mail
ham5.txt is NOT spam mail
spam017.txt is NOT spam mail
spam07.txt is spam mail
spam117.txt is spam mail
spam3.txt is spam mail
spam32.txt is spam mail
spam79.txt is spam mail
6.K-Mean
from sklearn.datasets import make_blobs import matplotlib.pyplot as plt from sklearn.cluster import KMeans X, y = make_blobs(n_samples=500,n_features=2,centers=4,random_state=1) print("X 的维度为:{}".format(X.shape)) print("y 的维度为:{}".format(y.shape)) # 绘制图 fig, ax1 = plt.subplots(1) ax1.scatter(X[:, 0], X[:, 1] ,marker='o' # 设置点的形状为圆形 ,s=8 # 设置点的大小 ) plt.show() # 根据标签绘制不同颜色 color = ["red","pink","orange","green"] fig, ax1 = plt.subplots(1) for i in range(4): ax1.scatter(X[y==i, 0], X[y==i, 1] # 根据每个点的标签绘制 ,marker='o' # 设置点的形状为圆形 ,s=8 # 设置点的大小 ,c=color[i]) plt.show() # 模型 n_clusters = 3 cluster1 = KMeans(n_clusters=n_clusters,random_state=0).fit(X) # 打印每个簇的质心(中心坐标) centroid1 = cluster1.cluster_centers_ y_pred1 = cluster1.labels_ print(y_pred1) color = ["red","pink","orange","gray"] fig, ax1 = plt.subplots(1) for i in range(n_clusters): ax1.scatter(X[y_pred1==i, 0], X[y_pred1==i, 1] ,marker='o' #点的形状 ,s=8 #点的大小 ,c=color[i] ) ax1.scatter(centroid1[:,0],centroid1[:,1] ,marker="x" ,s=15 ,c="black") plt.show() #选择4类 n_clusters = 4 cluster2 = KMeans(n_clusters=n_clusters,random_state=0).fit(X) y_pred2 = cluster2.labels_ centroid2 = cluster2.cluster_centers_ print("质心:{}".format(centroid2)) color = ["red","pink","orange","green"] fig, ax1 = plt.subplots(1) for i in range(n_clusters): ax1.scatter(X[y_pred2==i, 0], X[y_pred2==i, 1] ,marker='o' #点的形状 ,s=8 #点的大小 ,c=color[i] ) ax1.scatter(centroid2[:,0],centroid2[:,1] ,marker="x" ,s=15 ,c="black") plt.show()
















 195
195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









