









https://www.cnblogs.com/pprp/p/14975419.html
讲的很好的一个博客。
现往你的.py文件上打上以下代码:
import torch
import numpy as np
from torch.optim import SGD
from torch.optim import lr_scheduler
from torch.nn.parameter import Parameter
model = [Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, lr=0.1)然后在最后的循环打上以下代码:
epochs=100
for epoch in (1,epochs+1):
train()
test()
lr_schedulers.step()这里的train和test是你的训练和测试调用的函数。
学习率参数很难调节,针对图像分类任务,一般使用的是:
1.阶梯型衰减,
就是在指定的批次上降低指定倍数,比如如果100个epoch,设置在1/3和3/4处学习率减小一倍,这种有两种实现方式:
方式一:
lr_schedulers=lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)方式二:
epochs=100
for epoch in (1,epochs+1):
if epoch%30 == 0:
lr = lr*0.1
train()
test()
lr_schedulers.step()2.MultiStepLR:多个不同速率的衰减
方式一:
scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=[30,80], gamma=0.5)方式二:
for epoch in (1,epochs+1):
if epoch == 30:
lr = lr*0.1
if epoch == 40:
lr = lr*0.5
train()
test()
lr_schedulers.step()3.指数型下降的学习率调节器
公式:
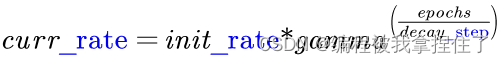
curr_rate:当前的学习率
init_rate:初始的学习率
gamma:衰减系数
epochs:计数器,从0计数到训练的迭代次数
decay_step:控制衰减速度
公式表达的含义其实很明显,gamma衰减系数代表的就是衰减函数的形状,>1学习率就增长了,<1学习率就衰减了。代码实现:
X = []
Y = []
# 初始学习率
learning_rate = 0.1
# 衰减系数
decay_rate = 0.1
# decay_steps控制衰减速度
# 如果decay_steps大一些,(global_step / decay_steps)就会增长缓慢一些
# 从而指数衰减学习率decayed_learning_rate就会衰减得慢一些
# 否则学习率很快就会衰减为趋近于0
decay_steps = 60
# 迭代轮数
global_steps = 120
# 指数学习率衰减过程
for global_step in range(0,global_steps):
decayed_learning_rate = learning_rate * decay_rate**(global_step / decay_steps)
X.append(global_step / decay_steps)
Y.append(decayed_learning_rate)
if global_step==0 or global_step==global_steps-1:
print("global step: %d, learning rate: %f" % (global_step,decayed_learning_rate))
fig = plt.figure(1)
ax = fig.add_subplot(1,1,1)
curve = ax.plot(X,Y,'b',label="learning rate")
ax.legend()
ax.set_xlabel("epochs / decay_steps")
ax.set_ylabel("learning_rate")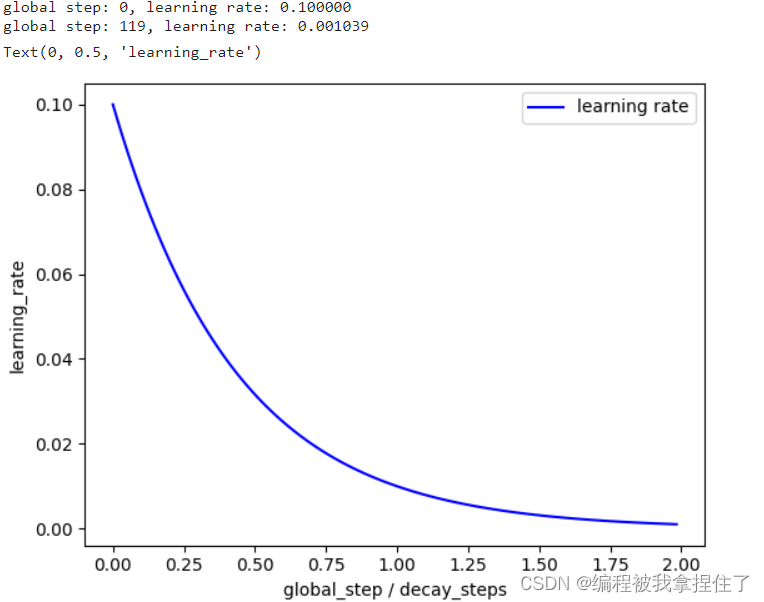
你通过设置初始学习率和最后想要下降到的学习率试着模拟一下。 效果还是不错的。
实现方式:
实质上pytorch里面有:
scheduler = lr_scheduler.ExponentialLR(optimizer, gamma=0.9)但是和上面的公式是有出入的,他的实现方式其实就是当前的学习率乘以gamma系数值,所以在最后学习率肯定会同样的衰减率torch里面下降的是比上面的快的,所以有两种策略,第一种调整gamma系数然后打印每次的学习率的数值调整到自己想要的学习率大小,即:
我i试了试改成0.96差不多就可以了。

第二种就是把上面的方式封装成一个函数,在for循环里每次调用他,封装成函数就可以使用
LambdaLR学习策略
了,它可以自定义函数,实现方式如下:
# 初始学习率
learning_rate = 0.1
# 衰减系数
decay_rate = 0.1
# decay_steps 控制衰减速度
decay_steps = 60
# 迭代轮数
global_steps = 120
# 自定义指数衰减函数
def exponential_decay(initial_lr, decay_rate, decay_steps, global_step):
return initial_lr * decay_rate**(global_step / decay_steps)
scheduler = LambdaLR(optimizer, lr_lambda=lambda step: exponential_decay(learning_rate, decay_rate, decay_steps, step))
# 记录学习率的变化
lr_history = []
# 模拟训练过程
for epoch in range(global_steps):
# 执行训练步骤
# ...
# 记录当前学习率
current_lr = optimizer.param_groups[0]['lr']
lr_history.append(current_lr)
# 更新学习率
scheduler.step()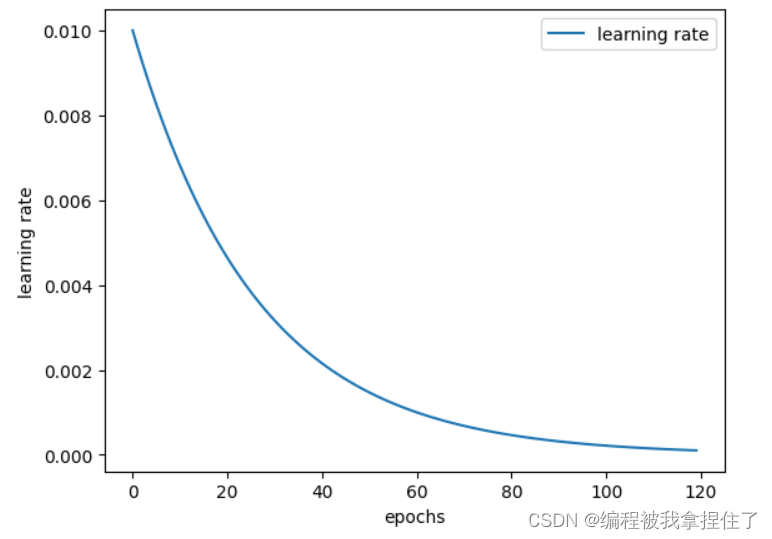
这个函数就非常的方便,像是上面的多阶段衰减也可以使用这个函数进行实现。
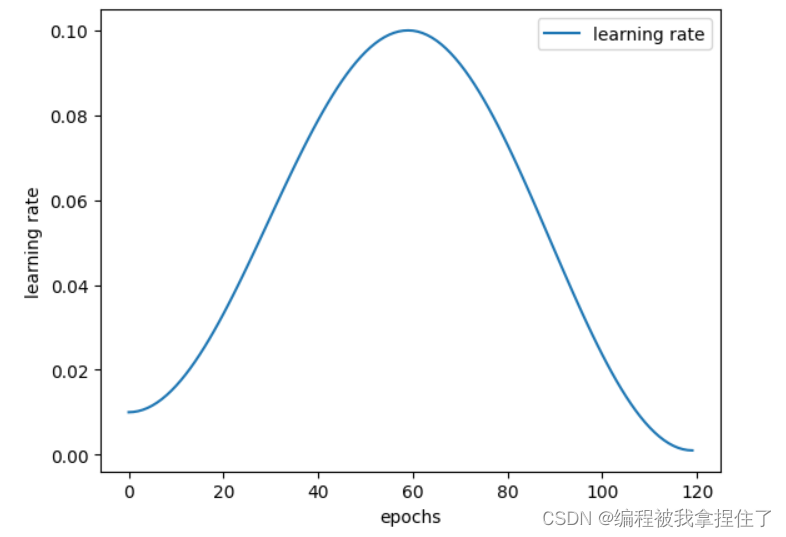
OneCycleLR
scheduler=lr_scheduler.OneCycleLR(optimizer,max_lr=0.1,pct_start=0.5,total_steps=120,div_factor=10,final_div_factor=10)可视化 OneCycleLR:
import torch
from torch.optim.lr_scheduler import OneCycleLR
import matplotlib.pyplot as plt
# 定义神经网络和优化器
class SimpleNet(torch.nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc = torch.nn.Linear(10, 1)
def forward(self, x):
return self.fc(x)
net = SimpleNet()
optimizer = torch.optim.SGD(net.parameters(), lr=0.1)
# 定义 OneCycleLR 学习率调度器
scheduler = OneCycleLR(optimizer, max_lr=0.1, pct_start=0.5, total_steps=120, div_factor=10, final_div_factor=10)
# 记录学习率的变化
lr_history = []
# 模拟训练过程
for epoch in range(120):
# 执行训练步骤
# ...
# 记录当前学习率
current_lr = optimizer.param_groups[0]['lr']
lr_history.append(current_lr)
# 更新学习率
scheduler.step()
# 绘制学习率变化曲线
plt.plot(range(120), lr_history, label="learning rate")
plt.xlabel("epochs")
plt.ylabel("learning rate")
plt.legend()
plt.show()
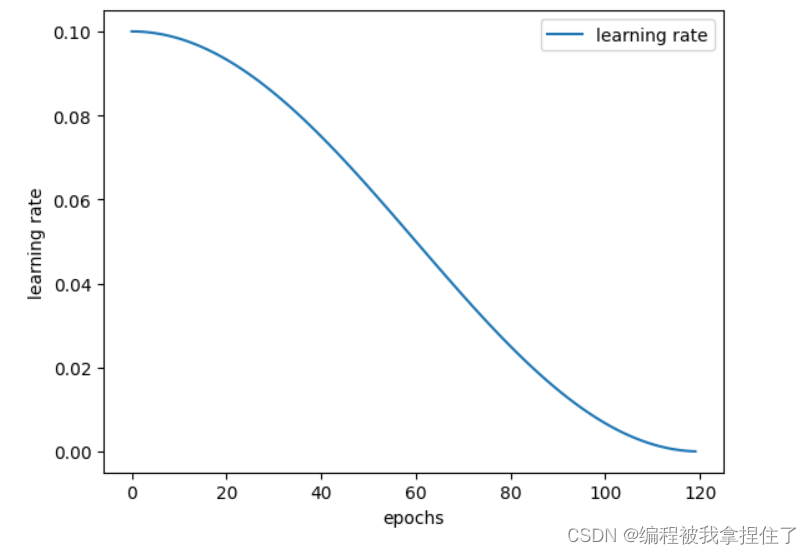
最后一个余弦退火学习率衰减CosineAnnealingLR
CosineAnnealingLR是余弦退火学习率,T_max是周期的一半,最大学习率在optimizer中指定,最小学习率为eta_min。这里同样能够帮助逃离鞍点。值得注意的是最大学习率不宜太大,否则loss可能出现和学习率相似周期的上下剧烈波动。
基本上的选择方式是选择1/4个余弦函数的周期。
可视化:
这里官方文档的公式说明讲的很清晰,自行学习吧:
Parameters 参数
-
optimizer (Optimizer) - 包装优化器。
-
T_max (int) - 最大迭代次数。
-
eta_min (float) - 最低学习率。默认值:0。
-
last_epoch (int) - 上一个纪元的索引。默认值:-1。
-
verbose (bool) – 如果
True,则在每次更新时向 stdout 打印一条消息。默认值:False.
今天的学习就到这里,散会!
ps:最近心情有点糟糕,六级+期末考试+实验出了些问题,好累,今晚好好睡一觉吧,晚安各位。
















 7521
7521











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









