








 哈希表的缺点就是在于占用的空间内存比较多 :
哈希表的缺点就是在于占用的空间内存比较多 :
举个例子:有可能存储2个元素 最后哈希表使用了十个数组空间的大小
因为它是为了减少哈希冲突而把空间搞大一点
但是时间复杂度较低
———————————————————————————————————————————




查询元素是否存在:
第一条:如果有一个位置哈希函数生成索引位置对应的值是不为1的 那么这个元素肯定不存在
第二条:因为有可能这个索引位置对应的值:这个1不一定是同一个元素生成的
有可能是A 生成的1 后来B也指向这里,,,,,

布隆过滤器一般用在数据规模特别大的地方 公式等价于下面
 一般吧实现删除 特别的麻烦 为了实现查询的高效 我们不实现删除
一般吧实现删除 特别的麻烦 为了实现查询的高效 我们不实现删除
如果要删除A 我们把所指向索引处的值改为0 但是有可能别的元素也可能在利用指向这个地方
因此我们不易删除

细节语法:Java当中的语法问题 ln2

一个亿怎么表示?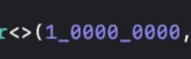

bitSize表示要装的比特位数 但是这样计算可能不太准确
我们常用的公式:

我们知道数据量:n,并且知道每一页所要显示的数据量 :pageSize
那么我们可以通过这个算出需要多少页:pageCount=(n+pageSize-1)/pageSize
代码: 省略______



跳表:

由于我们的链表和数组不一样 它不可以随机直接跳转到指定位置去

 因为红黑树实现起来真的是太难了。。。。
因为红黑树实现起来真的是太难了。。。。

在链表的基础上,增加了跳跃的功能。每间隔一个 ,跳跃一个
越上面的路线它是走的越快的
如图:(doge)
查找18是否存在的过程如图:::-------------------------------------------------------
1.先从最高处进行查找,发现21大于18 那么就退回上一步
2.从上一步的下一层开始找 以此类推的找即可
3.最好发现找到地下了 还是找不到 所以18不存在,,,,,

——————————————————————————————————————————
Node<K,V>[ ] nexts;表示是一个节点数组
first.nexts[ ]表示指向节点


添加删除

删除:

添加:

源码如下:
package 数据结构与算法.图.跳表;
public class SkipList<K,V> {
private static final int Max_value=32;
private static final double P=0.25;
private int size;
private Comparable<K> comparactor;
/**
* 也可以不传比较器
*/
public SkipList() {
this(null);
}
/**
* 先不存放任何的K,V
*/
private Node<K,V> first;
public SkipList(Comparable<K> comparactor) {
this.comparactor = comparactor;
/**
* 第一个节点创建 :即为first节点
*/
first=new Node<>(null,null,Max_value);
/**
* 第一个节点的下一个指向的范围大小区间为Max_value
*
* 第一个节点应该搞为最高
*/
first.nexts=new Node[Max_value];
}
/**
* 有效层数
*/
private int level;
private int size(){
return size;
}
public boolean isEmpty(){
return size==0;
}
/**
*当我们创建一个 添加一个新节点的时候 通常是采用抛硬币的做法
* 当P<0.25时 我们level++
*/
private int randomlevel(int level){
while (Math.random()<P&&level<=Max_value){
level++;
}
return level;
}
/**
*添加元素
* 先找要添加的元素是否已经存在:
* 1.如果存在 直接覆盖
* 2。不存在时 找到该插入的位置 更换线条指向
*/
public V put(K key,V value){
checkNull(key);
Node<K,V> node=first;
Node<K,V>[] prevs=new Node[level];
for (int i =level-1; i>=0 ; i++) {
int cmp=-1;
while (node.nexts!=null&&(cmp=comparable(key,node.nexts[i].key))>0){
node=node.nexts[i];
}
/**
* 本来就存在 那么就要覆盖这个值
*/
if(cmp==0){
V oldvalue=node.nexts[i].value;
node.nexts[i].value=value;
return oldvalue;//返回旧节点的value
}
/**
* 记录前驱 到这里的node肯定要往下走 那么就是前驱
*/
prevs[i]=node;
}
//添加新节点随机生成的高度
int newnodelevel=randomlevel(level);
Node<K,V> newnode=new Node<>(key,value,newnodelevel);
for (int i = 0; i <newnodelevel ; i++) {
//level表示新添加节点的前一个节点的高度
if(newnodelevel>=level){
//更新前驱
first.nexts[i]=newnode;
//后继默认是空的 因此可省略 newnode.nexts[i]=null
} else {
//更新前驱
newnode.nexts[i]=prevs[i].nexts[i];
//更新后继
prevs[i].nexts[i]=newnode;
}
}
size++;
/**
* 更新高度 原来的有效高度就是除了first节点(这个Max_value高度)之外的最高高度值
*原来的有效高度和新节点的高度最大值
*/
level=Math.max(level,newnodelevel);
return null;
}
/**
* 通过key拿到value
*
* get的思路:从最上面一层的有效层(level)开始 往右边去找
*/
public V get(K key){
checkNull(key);
Node<K,V> node=first;
for (int i =level-1; i>=0 ; i++) {
int cmp=-1;
while (node.nexts[i]!=null&&(cmp=comparable(key,node.nexts[i].key))>0){
node=node.nexts[i];
}
if(cmp==0){
return node.nexts[i].value;
}
}
return null;
}
/**
* 删除
*
* 和添加思路差不多 找不动直接return即可
* 找到时则删除
*/
//返回的是要删除节点的value值
public V remove(K key){
checkNull(key);
Node<K,V> node=first;
Node<K,V>[] prevs=new Node[level];
boolean falg=false;
for (int i =level-1; i>=0;i--) {
int cmp=-1;
while (((cmp=comparable(key,node.nexts[i].key))>0)&&node.nexts[i]!=null){
node=node.nexts[i];
}
prevs[i]=node;
/**
* 如果存在这个节点 那么改变这个取值
*/
if(cmp==0){
falg=true;
}
}
/**
* 如果不存在要删除的这个节点 那么直接返回null
*/
if(!falg){
return null;
}
//需要被删除的节点至少存在第一层
Node<K,V> removenode=node.nexts[0];
//更改后继
for (int i = 0; i <removenode.nexts.length ; i++) {
prevs[i].nexts[i]=removenode.nexts[i];
}
/**
* 更新跳表的高度
*/
int newlevel=level;
while (--newlevel>=0&&first.nexts[level]==null){
level=newlevel;
}
return removenode.value;
}
private void checkNull(K key){
if(key==null){
throw new IllegalArgumentException("that not null");
}
}
public int comparable(K k1,K k2){
return comparactor!=null?comparable(k1,k2)
:((Comparable<K>)k1).compareTo(k2);
}
private static class Node<K,V>{
/**
* 节点的成员变量属性
* 省去了访问修饰限定符
*/
K key;
V value;
/**
* 因为在跳表中 一个节点的next可能会有很多个 他应该被搞出来一个数组nexts 存放下一个指向的地址
*/
Node<K,V>[] nexts;
/**
*节点的构造器
*/
public Node(K key,V value,int level){
this.key=key;
this.value=value;
Node<K,V>[] nexts=new Node[level];//这一句话等价于nexts=new Node[level];
}
}
}















 520
520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









