







目录
为什么要使用ThreadLocal工具类去操控存取目标数据到Thread线程 ?
怎么样把一个目标数据,存储到某一线程的threadLocals(Map)中?
ThreadLocal中如何解决哈希冲突(哈希碰撞)的?线性探测
Netty优化方案之 FastThreadLocal
前言
Netty的FastThreadLocal和JDK的ThreadLocal都是一个"工具类"。
为什么说是工具类呢?
二者都是把目标数据存储到Thread线程对象中的一个属性threadLocals中的,该属性是一个Map类型。该Map的key就是当前ThreadLocal对象,Value就是目标数据。
这样就做到了把目标数据和线程对象绑定,从而也就做到了目标数据的线程独享!
但是Netty的FastThreadLocal做的要比ThreadLocal要更地道,更优化,更优秀。但是总结FastThreadLocal之前,先总结一下ThreadLocal。
ThreadLocal
ThreadLocal是干什么的?
"前言"中说过了
为什么要使用ThreadLocal工具类去操控存取目标数据到Thread线程 ?
1.ThreadLocal实现了线程独享,解决了很多线程安全问题
2.减少参数污染
如果不使用ThreadLocal,在web开发中,每一个请求对应一个线程,我们通过request.getParameter获取到参数后,进行controller-service-dao三层传递参数,但是这样就污染了至少三个方法的参数传递。
如果使用ThreadLocal,我们通过ThreadLocal这个工具类把目标参数数据存储到Thread线程对象中的threadLocals这个Map中,我们只需在需要该参数数据的位置方法再通过ThreadLocal这个工具类获取即可
ThreadLocal的使用场景
1.分页的应用下,使用ThreadLocal存储页号
2.鉴权认证,验证登录
3.存储事务id(等价于存储Connection连接对象)
4.存储用户id
目标数据存储到Thread线程对象的哪里?
先说结论:
ThreadLocal把目标数据存储到Thread线程对象中的一个属性threadLocals中的,该属性是一个Map类型。该Map的key就是当前ThreadLocal对象,Value就是目标数据。
分析过程:
线程是操作系统层面真实存在创建的一个东西,它是CPU调度的最小单元,线程是进程在面对时代潮流多核CPU发展时匮乏的产物。
虽然说是在操作系统层面产生线程,但是对应到Java层面上,会有一个Thread.java这个java类对应着。对应着操作系统层面产生的线程!
在java对象层面,你如何存储一个未知的"目标数据"呢?肯定需要通过一个属性来存储!"目标数据"类型是未知的,啥类型都可能。所以肯定是Object类型。
但是你知道存储多少"目标数据"到Thread线程中吗?你能保证所有的目标数据都是一样的类型或值吗?不能吧。你可能存储一个用户id,也有可能存储一个Connection数据库连接对象代表事务。所以必须使用集合类型来存储"目标数据"!
集合类型有很多:Map,List,Set,对于存取效率最高的集合类型肯定是Map类型!所以选取Map作为存储目标数据的属性类型。
如图所示:
Thread.java线程对象就采用threadLocals这一Map类型作为存储目标数据的属性类型。说具体点:就是ThreadLocal这个类的内部类ThreadLocalMap!

怎么样把一个目标数据,存储到某一线程的threadLocals(Map)中?
如果不采用任何工具,我们单纯通过编码的话,步骤如下:
1.首先获取到当前想要操控的Thread线程对象:Thread t = Thread.currentThread()
2.通过第一步得到的线程对象t 去操控threadLocals属性去存储目标数据即可
但是这么简单的编码,JDK怎么可能没帮我们做
JDK怎么帮我们封装的?答案早已说过,就是通过ThreadLocal这一工具类为我们封装的。JDK就是封装了一个ThreadLocal工具类给我们开发者去使用,只需要简单的调用set 或 get方法,我们就可以去操控线程里面的threadLocals属性,去存或取出线程独享的目标数据!
再说一点:threadLocals这个属性是一个Map,Map肯定是key-value键值对类型,那么问题来了,key是什么数据类型?value又是什么类型?
毫无疑问,value肯定是目标数据,你目标数据是啥,那么value就存啥。key键值呢?key键值就是当前你操控threadLocals这个属性的ThreadLocal对象!
接下来,我们看看ThreadLocal类的set 和 get方法:
set方法:

以下是对set方法的所调用到的方法的解析:




table = new Entry[INITIAL_CAPACITY];
创建table数组,初始化大小为16。table数组就是存储所有Key-Value键值对的容器。初始化值设为16,如果加入的元素数据过多,当超过扩容因子Threadshold后,就会扩容。但是注意:无论扩容到多大,table数组的大小永远为2的n次方。
为什么要为2的n次方?1.使得存储到table数组的元素散列均匀 2.能够把取模转换成位运算,效率高。
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
firstKey.threadLocalHashCode:获取到当前Key键值所对应的哈希值,其实就是一个CAS的原子累加操作,每一次都累加一个哈希增长值!然后得到一个当前Key键值对应的哈希值。

计算出哈希值后,就开始&运算求出:把当前Key-Value这一Entry元素加入到Map中的索引下标位置!
table[i] = new Entry(firstKey, firstValue);
根据索引下标,插入创建的第一个Entry对象。
size = 1;
初始化长度为1,代表加入了一个Entry啦
setThreshold(INITIAL_CAPACITY);
设置扩容因子为当前table数组长度的三分之二

get方法:


- debug测试一下
package com.messi.netty_source_03.Test15;
/**
* @Description TODO
* @Author etcEriksen
* @Date 2024/2/6 22:49
* @Version 1.0
*/
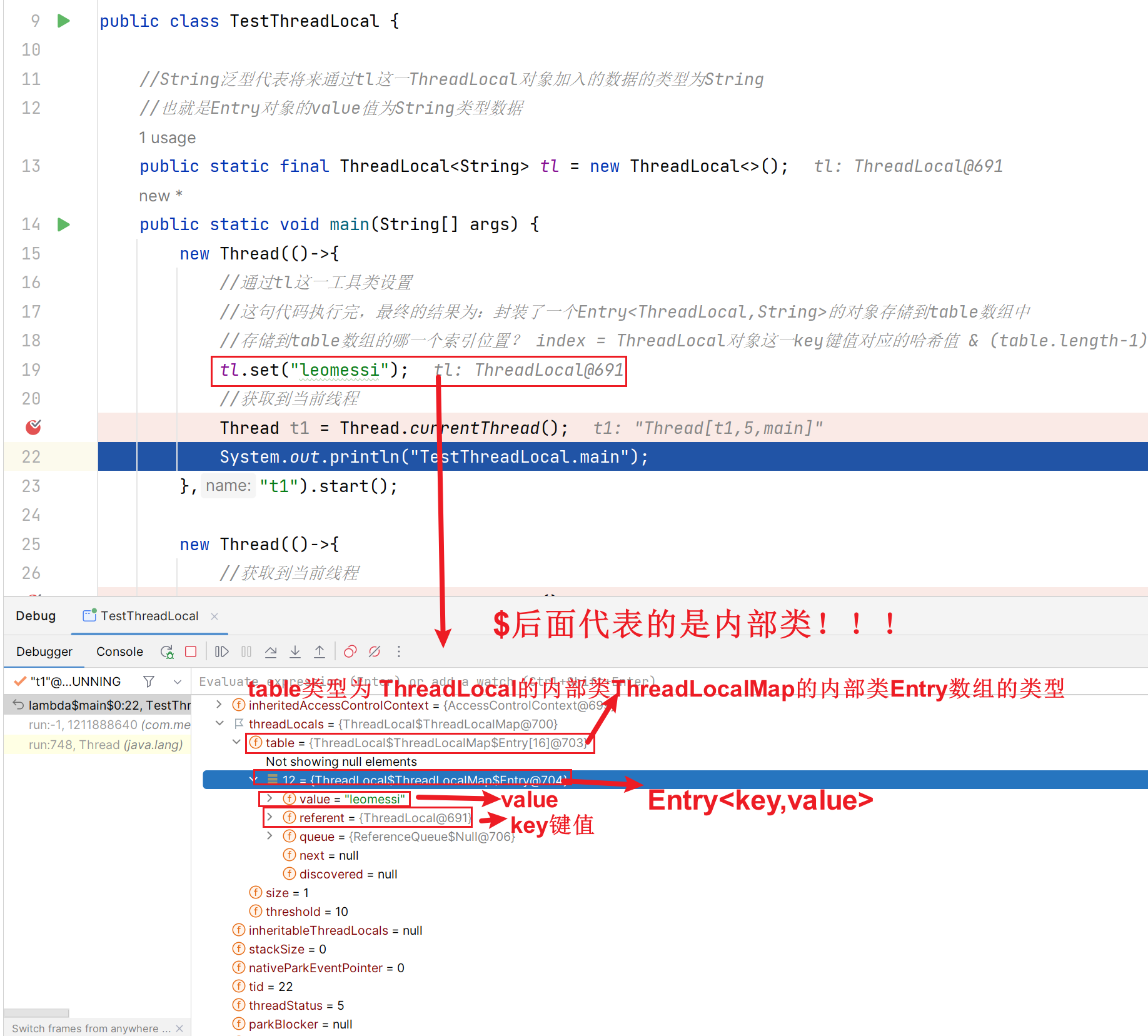
public class TestThreadLocal {
//String泛型代表将来通过tl这一ThreadLocal对象加入的数据的类型为String
//也就是Entry对象的value值为String类型数据
public static final ThreadLocal<String> tl = new ThreadLocal<>();
public static void main(String[] args) {
new Thread(()->{
//通过tl这一工具类设置
//这句代码执行完,最终的结果为:封装了一个Entry<ThreadLocal,String>的对象存储到table数组中
//存储到table数组的哪一个索引位置? index = ThreadLocal对象这一key键值对应的哈希值 & (table.length-1)
tl.set("leomessi");
//获取到当前线程
Thread t1 = Thread.currentThread();
System.out.println("TestThreadLocal.main");
},"t1").start();
new Thread(()->{
//获取到当前线程
Thread t2 = Thread.currentThread();
System.out.println("TestThreadLocal.main");
},"t2").start();
}
}1.

2.
- 如果在存储目标数据的过程中,如果发生哈希冲突了,怎么办?
如何计算最终封装的Entry对象应该加入到hash数组哪一个位置?
ThreadLocal对象的哈希值 % 数组长度
数组长度设置成2的n次方的目的为:【之前HashedWheelTimer详细总结过】
1.可以转换成&运算 效率高 2.使得加入到数组的多个Entry的位置散列更加均匀
哈希冲突是啥?
哈希冲突也就是在散列表中,下一个要存储的元素的位置已经有元素,这时则发生冲突。哈希冲突说白了,也就是多个数据存储在相同的位置!
哈希冲突发生的原因:
先说结论:(1)hashcode值不同,一定是不同的对象 (2) 可能存在不同的对象,但是hashcode值相同。
情况1:
在加入的key(对象)过多时,可能会发生多个不同的key(对象)通过hashcode函数计算出相同的哈希值,导致最终计算出加入的索引位置相同。
eg:以Object类的hashcode()为例
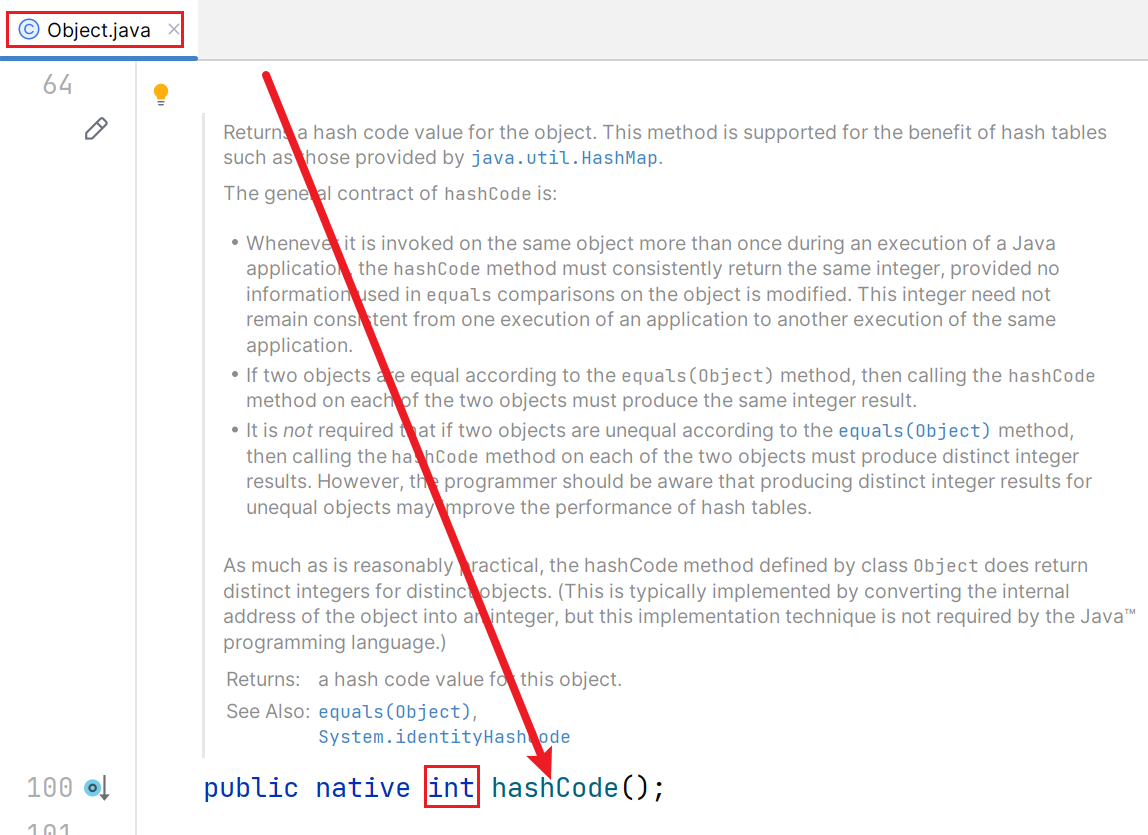
首先看hashCode方法的返回值类型,类型为int,范围为:0到2^31-1,也就是说对象调用hashCode方法的返回值结果最大为2^31-1。如果按照每一个对象均分1的情况的话,最大可用加入2^31-1个对象。
但是假设说加入的Object对象有2^31个,此时已经超过了2^31-1个对象,那么第2^31这一个对象需要取前面2^31-1对象的其中之一的hashCode()函数值来作为自己的哈希值。这不就是出现:不同对象,但是哈希值可能相同。
情况2:
单纯是因为通过key键值的哈希值 % 数组长度的结果是相同的,比如说:1%8==1,9%8==1,这不就是单纯的是不同数据存储到相同的索引位置了。
如果发生了哈希冲突,如何解决?
1.链表的方式(HashedWheelTimer,jdk1.7的HashMap)
2.红黑树 (jdk1.8的HashMap引入红黑树,链表链接到一定程度后,会树化成红黑树,提升搜索效率)
3.线性探测(ThreadLocal所对应的ThreadLocalMap)
JDK的ThreadLocal就是通过线性探测的方法解决ThreadLocalMap存储多个Entry时,发生哈希冲突的问题。但是这种解决哈希冲突的方式过于简单粗暴了,所以Netty的FastThreadLocal解决了这一问题,不再使用线性探测的方式解决哈希冲突的问题。
ThreadLocal中如何解决哈希冲突(哈希碰撞)的?线性探测
什么是线性探测?
如果当前int i = key.threadLocalHashCode & (len-1);计算出的索引位置i已经存储了Entry元素,此时发生哈希冲突!那么此时ThreadLocal会触发线性探测来解决哈希冲突这个问题。线性探测法会从索引i开始向后找下一个未存储Entry的位置继续插入。
但是寻找的过程中,可能遇见的情况有很多,如下举例。
我拿四个例子来说明即可:
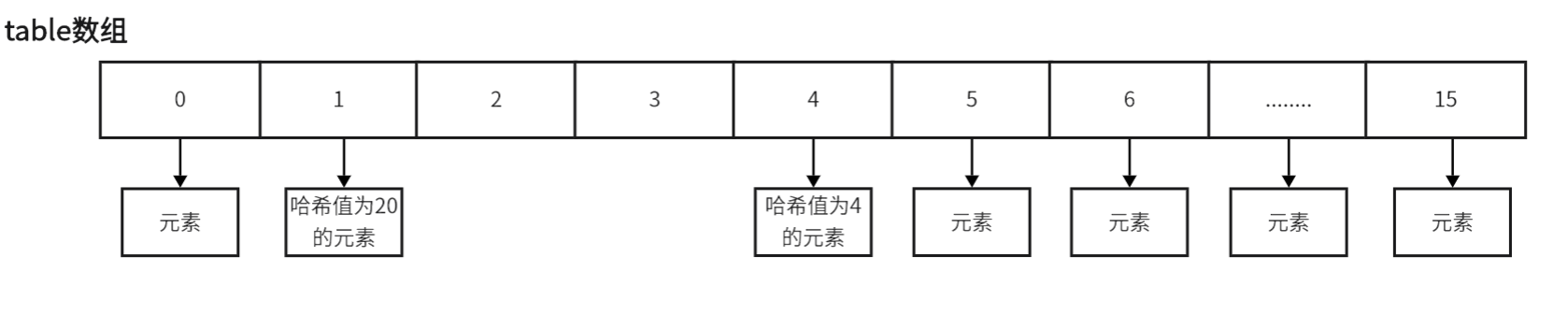
前提条件:数组长度为16,此时已经插入了哈希值为4的Entry元素,下一个待插入的是哈希值为20的Entry元素。通过计算:int 索引下标 = 对象哈希值 & (数组长度 - 1)
哈希值为4的Entry:int i = 4 & (16-1) = 4
哈希值为20的Entry:int i = 20 & (16-1) = 4
此时发生哈希冲突,如果使用链表法 ,那么直接接在哈希值为4的Entry后面即可。在JDK1.8的hashMap中引入了红黑树,当链表链接的数量达到一定程度后,会树化为红黑树,提升搜索效率。
但是我们ThreadLoccal采用的是线性探测法。下面就分四个可能发生的情况来分析。
情况1:如果索引下标4的下一个位置,索引下标5的位置没有元素,那么直接在索引5插入哈希值为20的Entry元素

情况2:如果索引下标4的下一个位置,索引下标5的位置有元素,那么会向后搜索下一个没有存储Entry元素的索引位置,最终找到索引6,在索引6插入哈希值为20的Entry元素

情况3:同理情况2。但是有一点不太一样,因为一直找到最后一位元素位置发现还是没有找到,那么会重新循环到索引0的位置进行插入哈希值为20的元素。

情况4:同理情况2,情况3的分析。如果循环到第一个索引位置后,发现仍然已经存在了Entry元素。那么同理会继续向后寻找下一个空闲的索引位置即可。
还有一点很重要:
不需要担心数组够不够,我们设置了一个扩容因子(ThreadLocal设置的是数组大小的三分之二)
每当我们加入了一个元素Entry到table数组后,就会把数组中已经插入的元素数量和扩容因子threshold作比较。如果已经插入的元素数量大于或等于threshold,那么进行扩容操作。
多插一嘴:
HashMap中设置的扩容因子为数组大小的四分之三,先说结论:四分之三要好于三分之二。
线性探测有什么优势和劣势?
优势:适合小数据量存储,算法简单
分析:因为本身小数据量Entry的存储,发生哈希碰撞的几率就很低,就算发生了,我们采用线性探测的解决方法时,也不用线性遍历迭代很多元素,也就几个。
劣势:不适合大数据量的存储,线性搜索效率劣势展现的淋漓尽致
如果在大数据量Entry要存储到数组的情况下,同样的算法计算索引下标,但是发生哈希碰撞的概率相对小数据量就提升了,并且当发生的时候,我们采用线性探测,如果出现如情况4的情况,那么你线性搜索的效率真的很低。假设有数组中已存储的元素数量为1万,最坏情况下你可能需要线性探测1万次,你的搜索效率有多低?对吧,很简单的道理。Netty正是不满意这一点,所以FastThreadLocal应运而生
ThreadLocal源码中,线性探测的逻辑是怎样的?
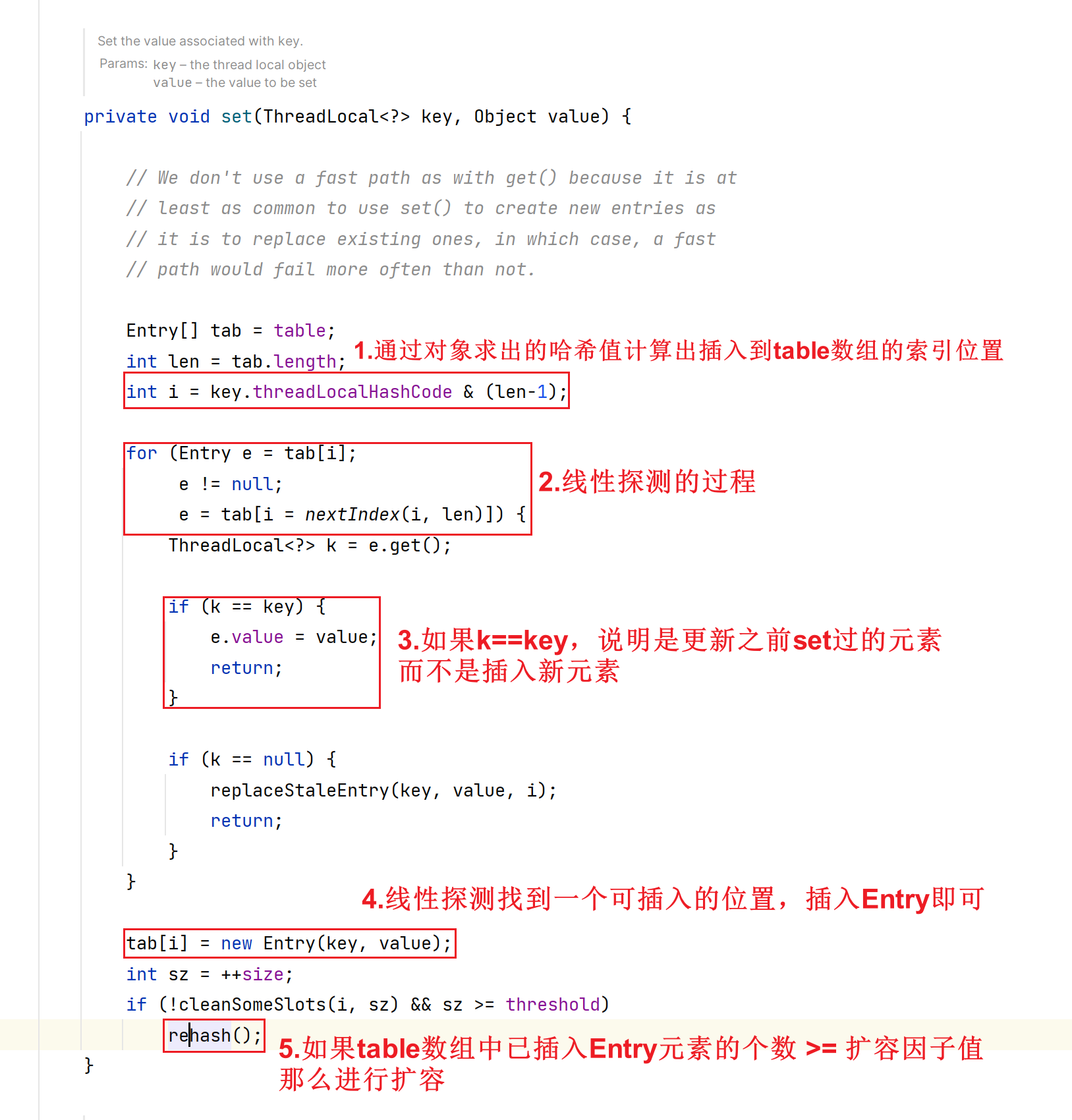
nextIndex方法:

Netty正是不满意这一点,所以FastThreadLocal应运而生
结合Web开发来说下ThreadLocal的作用
在日常的web开发过程中,我们都是客户端(浏览器)都是以"请求"的形式与服务端做交互的,客户端发给服务端的请求肯定会带有很多请求参数,面对客户端的请求,服务端需要处理,怎么处理?tomcat肯定会分配一个线程资源给对应的请求【当然,tomcat是有线程池的】,所以就有了"一个请求对应一个线程资源"的结论。当然,线程是可以复用的!
每一个请求都会携带自己独特的参数,可能这个参数为:请求分页的参数等等一系列该请求独自拥有的参数。此时,ThreadLocal这个工具类就排上用场了,ThreadLocal可以把这些请求(线程) 特殊独自拥有的参数设置到Thread线程对象的threadLocals属性中,threadLocals属性一个Map结构(ThreadLocal作为key,设置的数据值作为value)。
这样就解决了一个问题:多线程环境下,保证当前请求(线程)的所存储的参数数据值是当前线程独享的,其他线程不能访问到。
也解决了controller-service-dao 三层架构的方法参数传递过多的问题
ThreadLocal计算哈希值时的总结
- Hash冲突可用避免吗?
Hash冲突肯定是存在的。但是可以尽量避免,降低哈希冲突发生的概率。
如何尽量避免冲突?
在计算对象存储到table数组的索引位置时,要做到尽可能的散列均匀
什么是散列均匀?
散列均匀就是在元素数量远小于数组存储空间时,尽可能的去避免哈希冲突。为什么强调说是元素数量远小于数组存储空间呢?因为当元素数量接近于数组存储空间时,哈希冲突发生的概率就很大了,因为你可选的存储位置就少了,散列均匀所起到的作用就小了。
一个优秀的hash算法,也就是hashcode计算的好
在JDK的ThreadLocal设计的时候,就没有采取Object类的hashcode方法【int i=key.hashCode() & (len-1)】
而是采用int i=key.threadLocalHashCode & (len-1)
threadLocalHashCode的hash算法更好,更能保证计算的索引下标i的结果值更加散列均匀,减少hash冲突(hash碰撞)
eg:HashMap的hash算法求哈希值就是通过Object的hashCode()

就算出现了hash冲突,我们再使用各种方法解决它即可。【前面总结过】
- 探讨一下threadLocalHashCode的hash算法好在哪里?为什么更能保证计算的索引下标i的结果值更加散列均匀?
其实这两个问题可以视作同一个。
我们直接看源码来总结这个问题。
先看看set方法中如何计算一个数据存储【最终封装成的Entry对象】时,确定存储在数组的哪一个索引位置 i ?如下图:
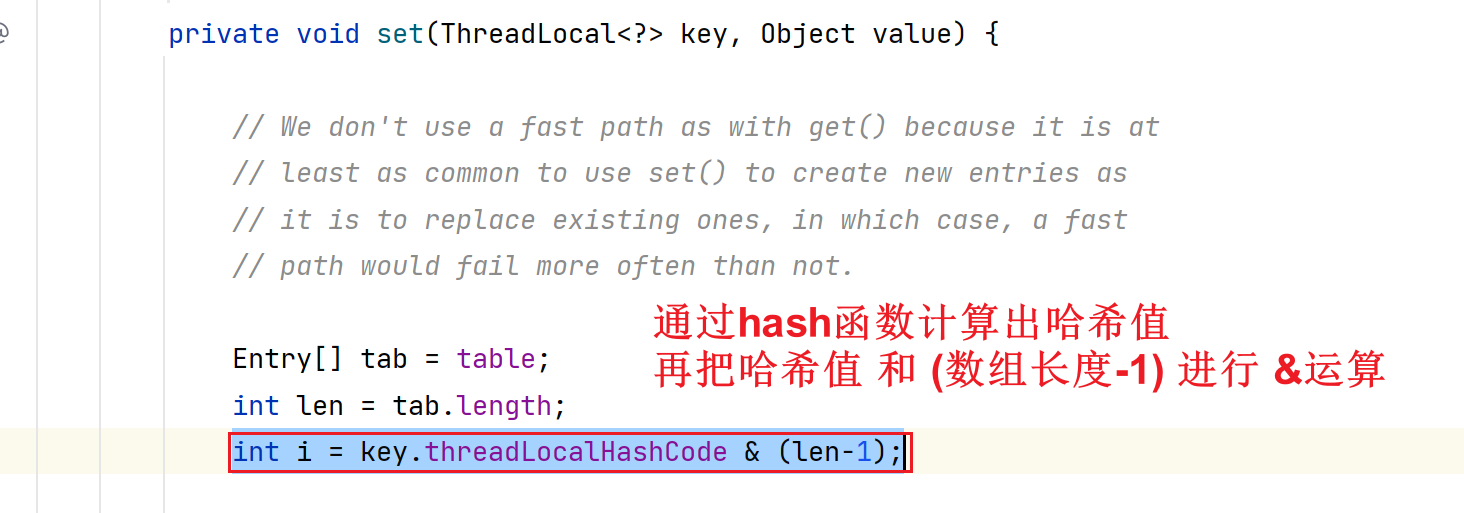
ThreadLocal没有使用Object类原生的hashCode(),而是使用自己重新设计的hash方法:nextHashCode()
在该方法中有一个关键字段:HASH_INCREMENT,正因为该字段值为0x61c88647,所以才使得该nextHashCode()这一hash方法所生成的hash码更加均匀,使得最终计算索引下标i时减少hash碰撞的可能。

为什么0x61c88647这个值有这么牛逼的效果呢?
见StackOverflow文章:
optimization - What is the meaning of 0x61C88647 constant in ThreadLocal.java - Stack Overflow
翻译一下大佬的解释:
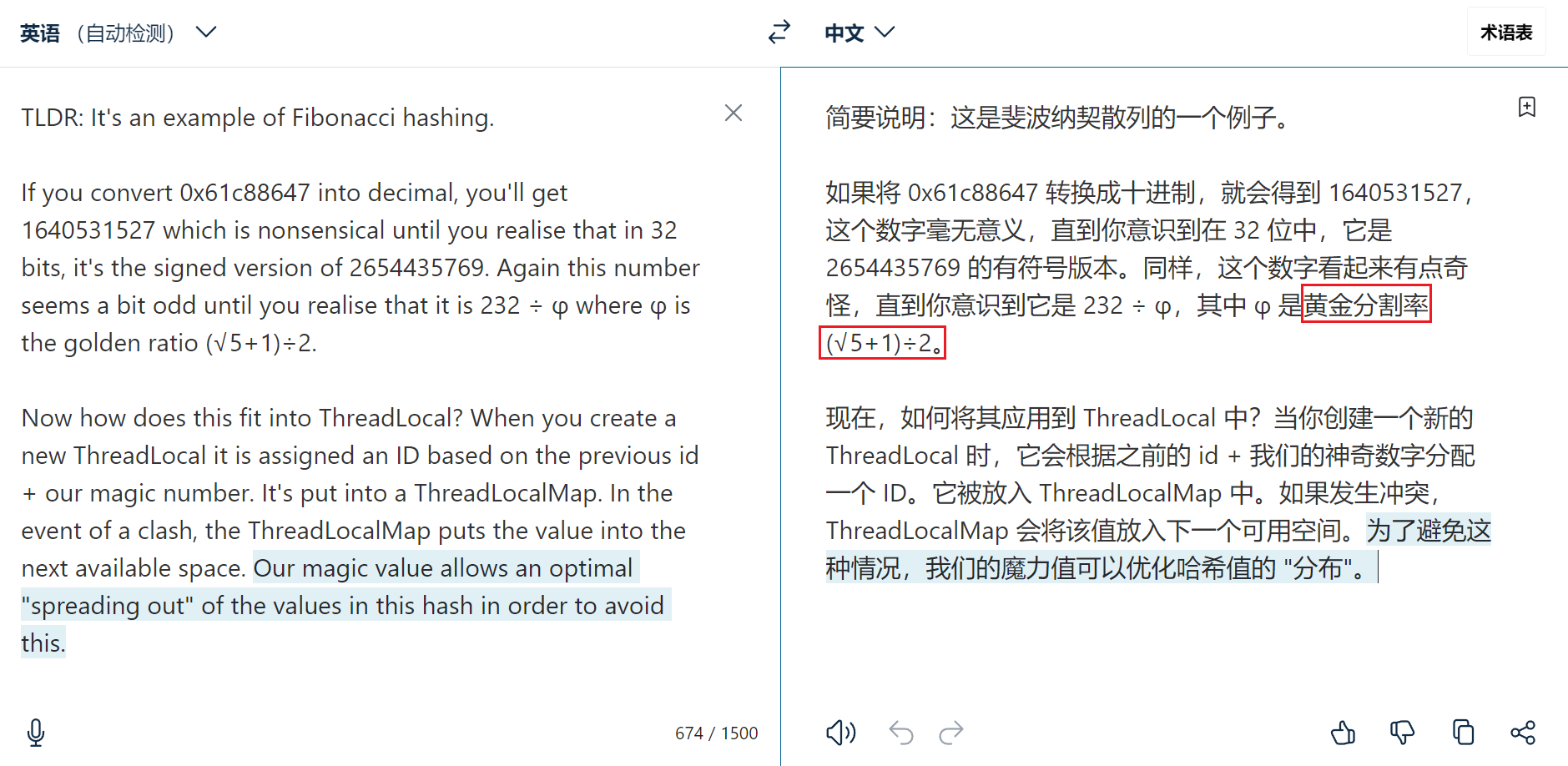
HASH_INCREMENT 是来自斐波那契Hash散列的一个黄金数。每一次原子性的递增该字段值所求出的hash值可以保证散列更加均匀。这是一个最优的设计。
如果想看数学证明过程,见如下链接文章:
https://web.archive.org/web/20161121124236/http://brpreiss.com/books/opus4/html/page214.html
多补充一点:
HashMap的扩容因子为什么取0.75?
这个证明也是通过数学证明,是泊松分布。
为什么Netty选用FastThreadLocal?
正因为ThreadLocal种种原因:哈希冲突问题 以及解决哈希冲突时ThreadLocal选用的线性探测法的效率低下【特别是数据量特别大时】,所以Netty拥抱自研设计FastThreadLocal,抛弃JDK原生的ThreadLocal
FastThreadLocal
顾名思义,Fast!FastThreadLocal就是比JDK原生的ThreadLocal要快。
为什么原始的ThreadLocal要慢?
因为如果出现了Hash冲突(碰撞)时,使用线性探测法解决Hash冲突的方式,时间效率低下,慢【时间复杂度大】。底层是Thread.java,ThreadLocalMap.java ,ThreadLocalMap$Entry[table数组]。特别是在数据量特别多的情况下,ThreadLocal的线性探测法解决哈希冲突的弊端就愈发明显,时间效率的弊端就越严重啦!
而Netty作为通信框架的牛逼产品,你感觉Netty不能做到在海量数据下低延迟存或取数据到线程对象?之前都是为了面对海量任务的存储 执行,我们抛弃JDK原生的Timer,Netty自研的HashedWheelTimer应运而生。FastThreadLocal和HashedWheelTimer一样,都是Netty新开发的一个新类型,就是为了在海量数据要存储到线程对象中。
于是我们研发一款工具类产品:FastThreadLocal来代替JDK原生的ThreadLocal。
这个FastThreadLocal工具类提供给我们用户的接口和原生ThreadLocal一致,get 或 set方法。但是FastThreadLocal它调用set方法进行存储数据到线程对象中时,时间效率更高。调用get方法去获取线程对象中对应存储的数据时,它也更快响应。
从宏观上总结FastThreadLocal
1.FastThreadLocal
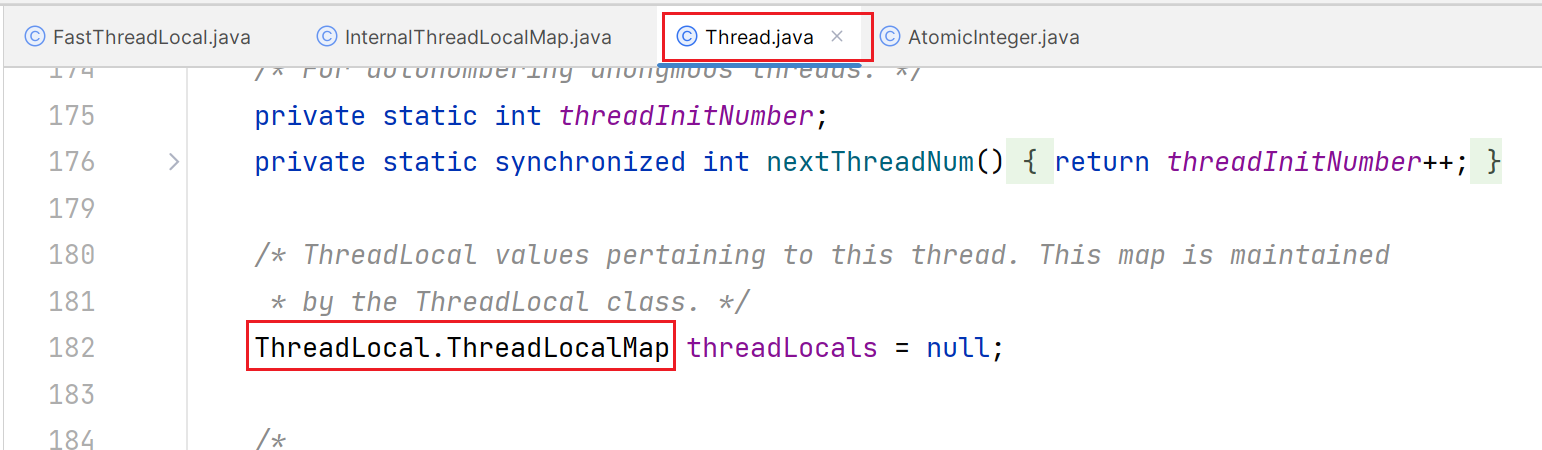
每一个FastThreadLocal对象都会生成一个JVM层面的唯一标识:index。index值原子递增,从1开始递增。所以第一个加入的FastThreadLocal对应标识为index=1,第二个为index=2


2.InternalThreadLocalMap
使用FastThreadLocal对象进行调用set方法设置目标数据到线程对象时,线程对象使用InternalThreadLocalMap这一集合对象进行存储维护成线程对象的一个属性以此来存储目标数据到线程对象中,实现线程独享。
但是InternalThreadLocalMap底层真正实现存储目标数据时,使用的是一个Object数组,初始大小为32。
该数组第一个位置是一个Set集合类型,存储所有的FastThreadLocal对象,其余的位置都用来存储目标数据。
当Object数组空间不够用时,会按照下标进行扩容。
反观ThreadLocal:
ThreadLocal是通过ThreadLocal$ThreadLocalMap进行存储目标数据的,维护成一个属性到线程对象中,以此实现存储目标数据到线程对象。
但是ThreadLocalMap底层是一个Entry[] table实现真正的数据存储的。
当table数组空间不够用时,会按照扩容因子(数组大小的2/3)来进行扩容。
对比二者:
由于FastThreadLocal的存储结构InternalThreadLocalMap的底层抛弃了table数组存储目标数据,而是采用Object[32]数组存储,由于目标数据在Object[32]中是一一对应存储的,所以FastThreadLocal没有哈希冲突问题,自然也就没有哈希冲突导致时间搜索性能下降的问题

3.FastThreadLocalThread
使用FastThreadLocal时,使用的是FastThreadLocalThread,而不是JDK元素的Thread。
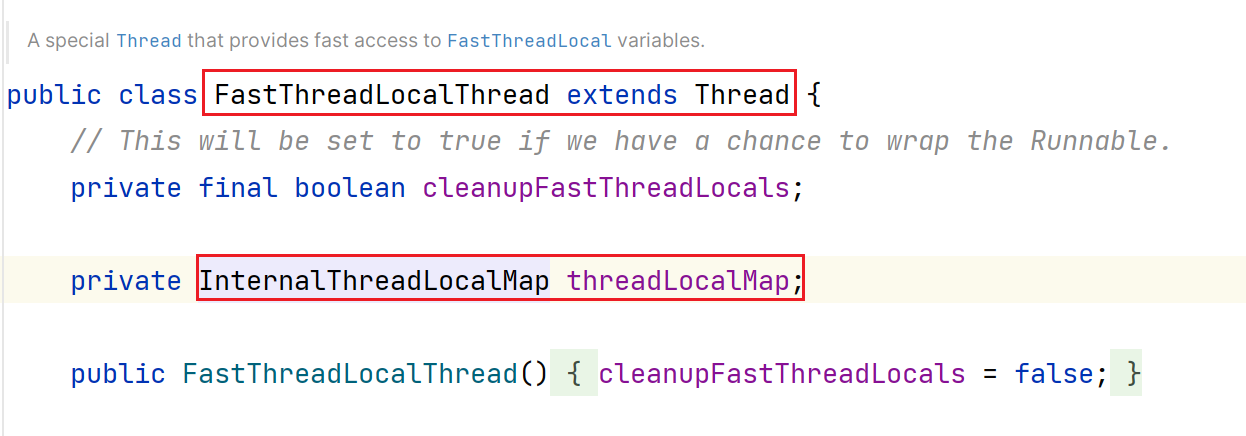
为什么这样重新设计一个FastThreadLocalThread?
如图所示:
因为我们不能直接:ThreadLocal.ThreadLocalMap threadLocals = new InternalThreadLocalMap()
因为InternalThreadLocalMap和ThreadLocal.ThreadLocalMap之间没有继承关系
FastThreadLocalThread继承Thread,在FastThreadLocalThread增加属性:
private InternalThreadLocalMap threadLocalMap
4.总结
所以以后开发使用FastThreadLocal时,三位一体:
FastThreadLocal + InternalThreadLocalMap + FastThreadLocalThread
- 举例debug验证
package com.messi.netty_source_03.Test15;
import io.netty.util.concurrent.FastThreadLocal;
import io.netty.util.concurrent.FastThreadLocalThread;
/**
* @Description TODO
* @Author etcEriksen
* @Date 2024/2/8 22:20
* @Version 1.0
*/
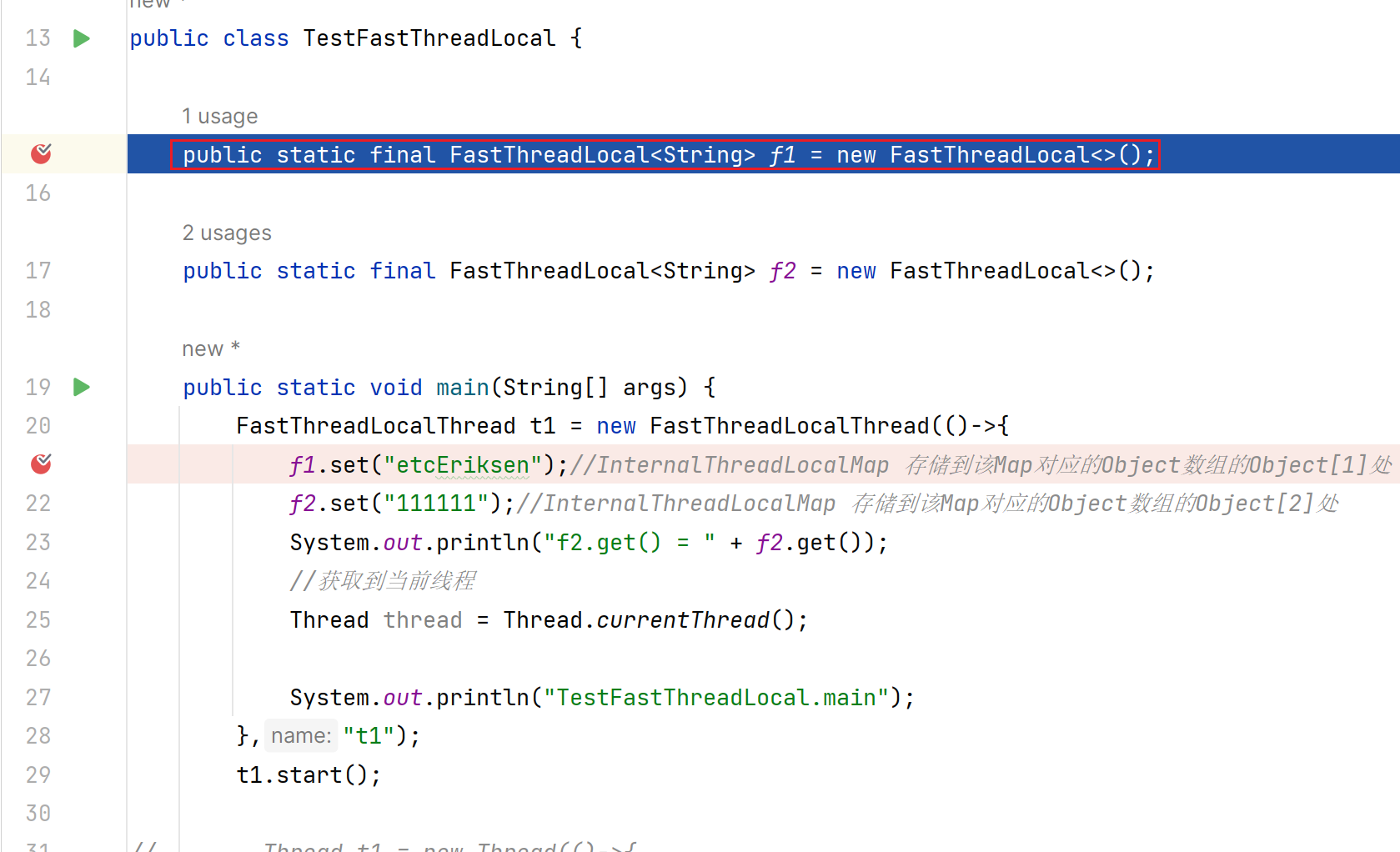
public class TestFastThreadLocal {
public static final FastThreadLocal<String> f1 = new FastThreadLocal<>();
public static final FastThreadLocal<String> f2 = new FastThreadLocal<>();
public static void main(String[] args) {
FastThreadLocalThread t1 = new FastThreadLocalThread(()->{
f1.set("etcEriksen");//InternalThreadLocalMap 存储到该Map对应的Object数组的Object[1]处
f2.set("111111");//InternalThreadLocalMap 存储到该Map对应的Object数组的Object[2]处
//获取到当前线程
Thread thread = Thread.currentThread();
System.out.println("TestFastThreadLocal.main");
},"t1");
t1.start();
}
}debug结果:

- 画图测试代码的结果
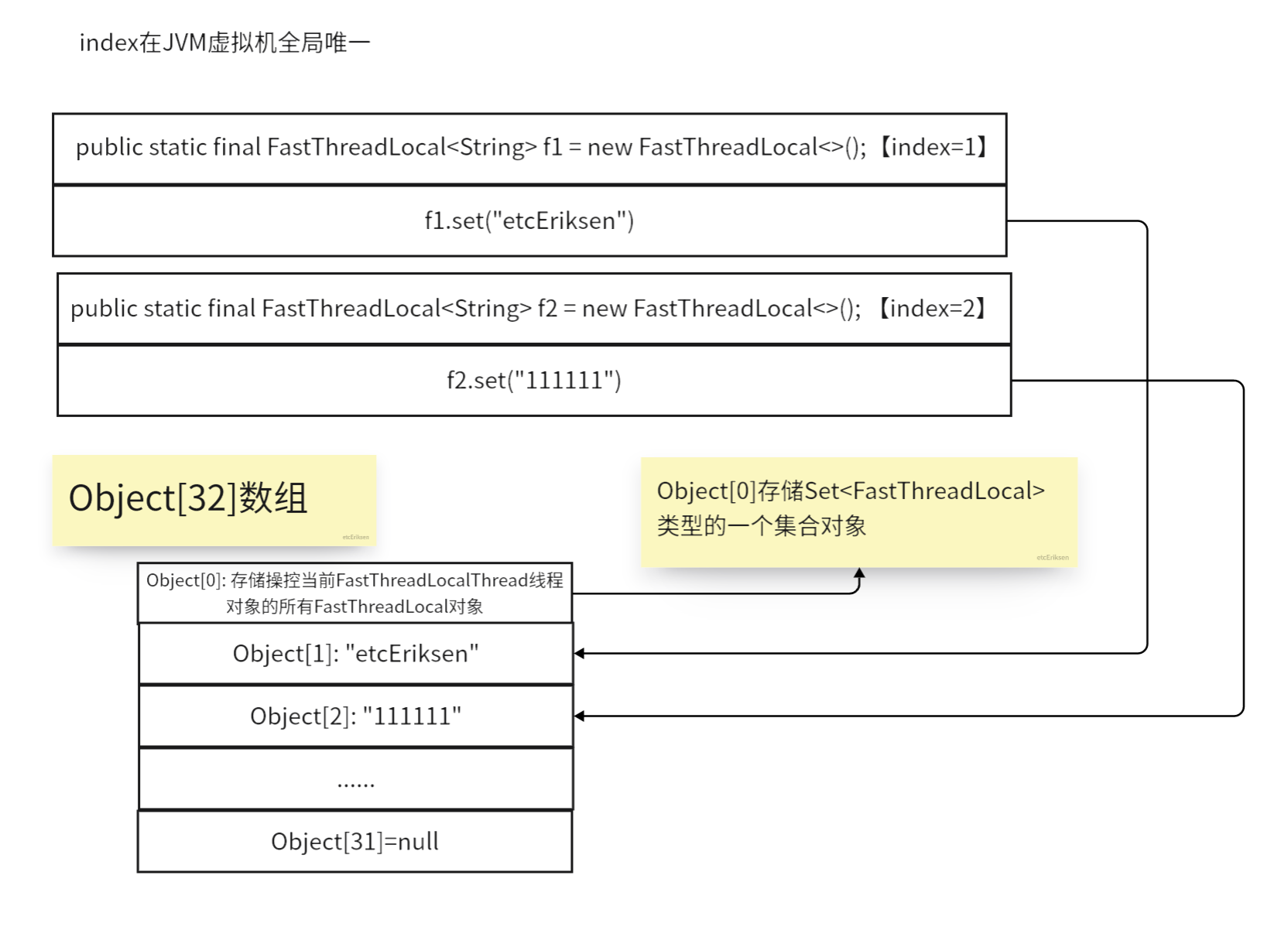
每当创建一个FastThreadLocal对象后,在虚拟机中就会生成一个唯一的index值作为标识。
如果第一次创建FastThreadLocal,那么index=1。
并且我们set设置数据的时候,是把数据存储到一个初始值为32的Object数组中,如果第一次存储数据,那么存放到Object数组索引为1的位置。如果调用get方法获取数据时,我们是通过index值去获取的,比如:调用f1.get(),f1对应的index值为1,那么通过index=1找到Object数组索引为1的位置,获取到对应存储的数据
Object数组索引为0的位置用来干什么的?
Set<FastThreadLocal>,存储所有的FastThreadLocal,每当JVM中新创建一个FastThreadLocal,首先会存储到Object数组索引0的位置的Set<FastThreadLocal>中。
所以可见,FastThreadLocal没有哈希冲突的问题,没有ThreadLocal线性查找的问题,所以它快。因为都index唯一标识存储数据了,怎么可能冲突。他又不是HashMap底层或ThreadLocal底层的table数组,hash-table数组肯定会有哈希冲突的
从微观源码层面总结FastThreadLocal
- 测试代码
package com.messi.netty_source_03.Test15;
import io.netty.util.concurrent.FastThreadLocal;
import io.netty.util.concurrent.FastThreadLocalThread;
import io.netty.util.internal.InternalThreadLocalMap;
/**
* @Description TODO
* @Author etcEriksen
* @Date 2024/2/8 22:20
* @Version 1.0
*/
public class TestFastThreadLocal {
public static final FastThreadLocal<String> f1 = new FastThreadLocal<>();
public static final FastThreadLocal<String> f2 = new FastThreadLocal<>();
public static void main(String[] args) {
FastThreadLocalThread t1 = new FastThreadLocalThread(()->{
f1.set("etcEriksen");//InternalThreadLocalMap 存储到该Map对应的Object数组的Object[1]处
f2.set("111111");//InternalThreadLocalMap 存储到该Map对应的Object数组的Object[2]处
System.out.println("f2.get() = " + f2.get());
//获取到当前线程
Thread thread = Thread.currentThread();
System.out.println("TestFastThreadLocal.main");
},"t1");
t1.start();
// Thread t1 = new Thread(()->{
// f1.set("etcEriksen");//InternalThreadLocalMap 存储到该Map对应的Object数组的Object[1]处
// f2.set("111111");//InternalThreadLocalMap 存储到该Map对应的Object数组的Object[2]处
// f2.set(null);
//
// System.out.println("f2.get() = " + f2.get());
//
// //获取到当前线程
// Thread thread = Thread.currentThread();
//
// System.out.println("TestFastThreadLocal.main");
// },"t1");
// t1.start();
// FastThreadLocal f3 = new FastThreadLocal(){
// @Override
// protected Object initialValue() throws Exception {
// return "is defaultValue";
// }
// };
f3.set("llll");
// Object o = f3.get();
// System.out.println("o = " + o);
}
}
1.构建FastThreadLocal对象
构建FastThreadLocal的过程中,完成很多工作:
1.静态常量variablesToRemoveIndex的初始化,赋值为0

2.静态常量slowThreadLocalMap的初始化
这个常量用于后续slowGet()方法中的使用。为了使得Thread+FastThreadLocal开发时依旧可以使用InternalThreadLocalMap进行存储数据!
所以这里创建了ThreadLocal<InternalThreadLocalMap> slowThreadLocalMap ;


3.完成FastThreadLocal-index的原子赋值,第一个FastThreadLocal的index=1,第二个为index=2,以此类推。
2.FastThreadLocal#set方法
1.

2.InternalThreadLocalMap.get():

获取到当前线程中的InternalThreadLocalMap,便于后续存储数据到该Map集合中

slowGet():


构建的是slowThreadLocalMap,每一个线程独享一份该对象。这是为了解决Thread+FastThreadLocal的情况下依旧可以使用InternalThreadLocalMap进行存储数据的需求。
但是这种存储结构比较嵌套低效:

如果使用slowGet()获取到的InternalThreadLocalMap进行存储数据的话,可能这个效率还没有原生ThreadLocal的效率高。因为ThreadLocalMap的某一个Entry位置存储InternalThreadLocalMap,同一线程中无论有多少FastThreadLocal都会存储到这一位置所对应的InterThreadLocalMap-Object数组中,很低效
3.setKnownNotUnset方法:

threadLocalMap.setIndexedVariable(index, value):
关于返回值return oldValue==UNSET的用法:
如果return true,说明是第一次在该index下set数据值,那么addToVariablesToRemove会调用把FastThreadLocal加入到Set<>
如果return false,则不会调用addToVariablesToRemove,说明已经不是第一次在该index索引处set设置数据
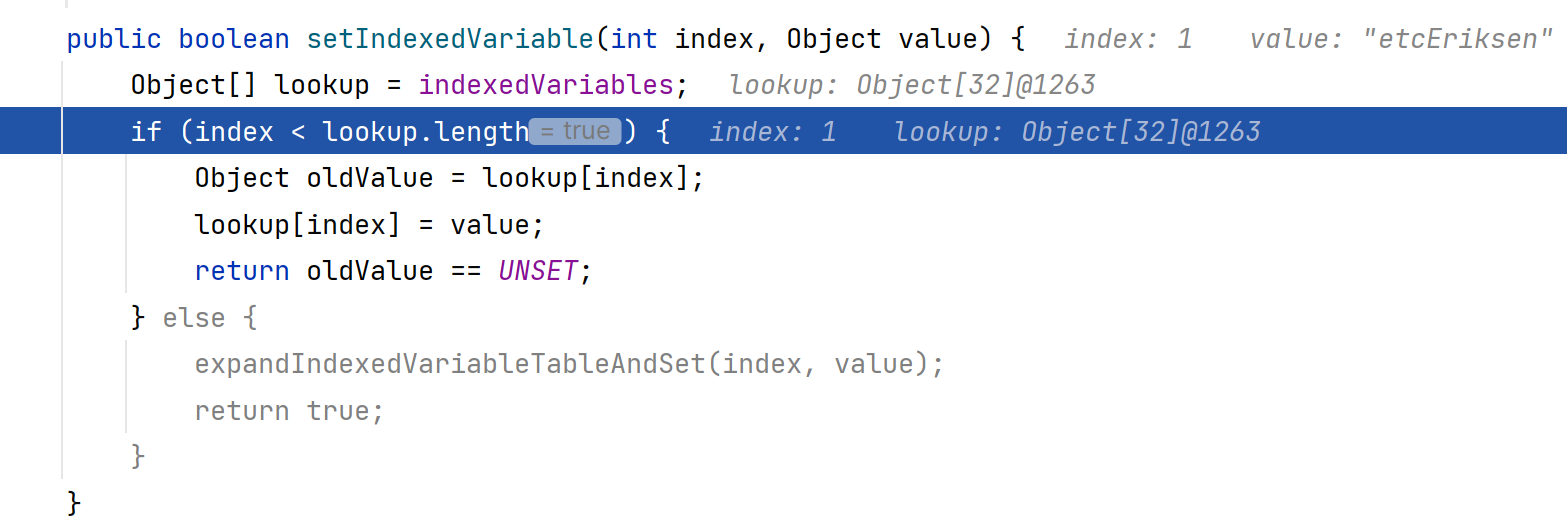
情况1:如果index没有超过Object数组大小的话,那么直接更新index对应的元素值
情况2:如果index超过Object数组大小的话,那么要expand扩容
扩容的机制和HashMap扩容的机制一致,保证数组大小为2的n次方,即扩容到第一个大于index值的2的n次方

关于扩容,举一个例子:

addToVariablesToRemove(threadLocalMap, this):把当前FastThreadLocal对象存储到Set<FastThreadLocal>集合中,如果第一次存储时,Object[0]没有Set<FastThreadLocal>,那么需要在Object[0]位置进行初始化创建Set集合。

4.remove():
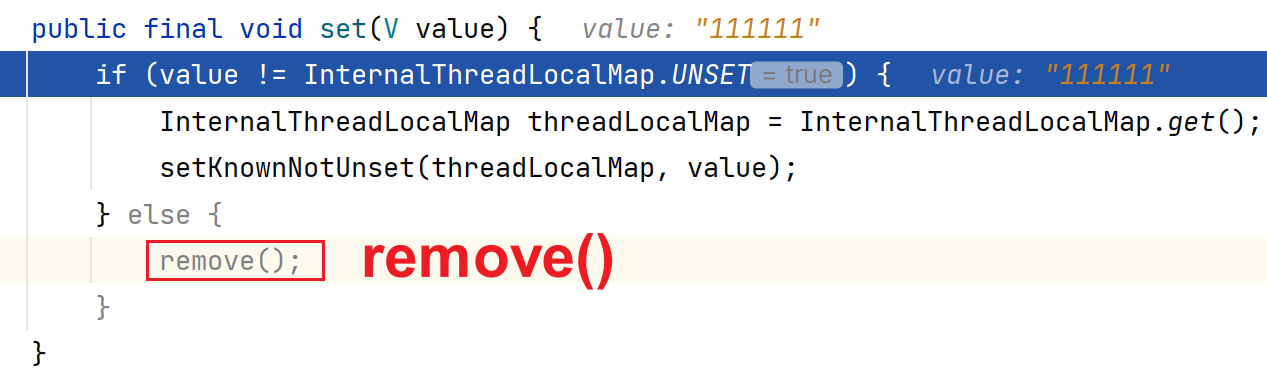

getIfSet():无论是Thread+FastThreadLocal 还是FastThreadLocalThread+FastThreadLocal,都要获取到对应的InternalThreadLocalMap


Object v = threadLocalMap.removeIndexedVariable(index):
删除Object[]数组对应位置的元素,置为UNSET

removeFromVariablesToRemove(threadLocalMap, this):
删除Object[0]-Set<FastThreadLocal>中当前对应的FastThreadLocal对象

onRemoval方法:
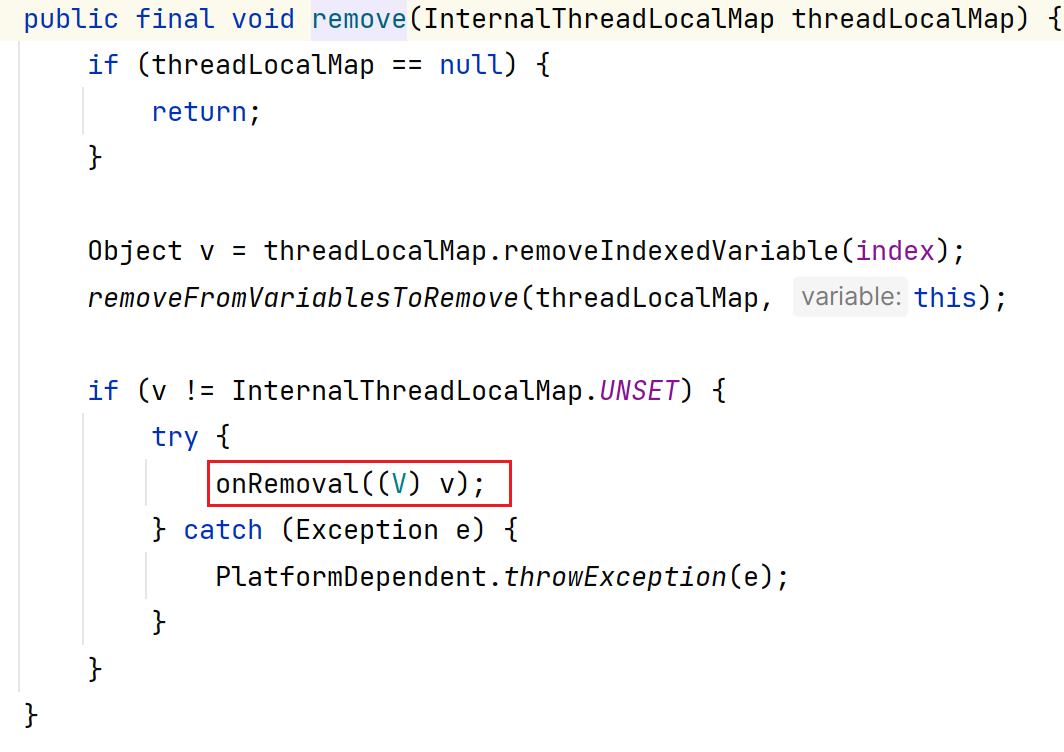
当我们从InternalThreadLocalMap中回收删除对应的连接Connection对象,那么我们就可以重写onRemoval方法写一些逻辑(Connection#close()方法),然后进行把连接Connection对象回收放到Connection连接池中。

3.FastThreadLocal#get方法

initialize方法:
把回调initialValue()的结果值set设置给InternalThreadLocalMap-Object[index]位置的数据值
并且确定是否增加当前FastThreadLocal到Set<>中!如果第一次set,那么需要加。如果不是第一次set,不需要加,之前已经加过啦。

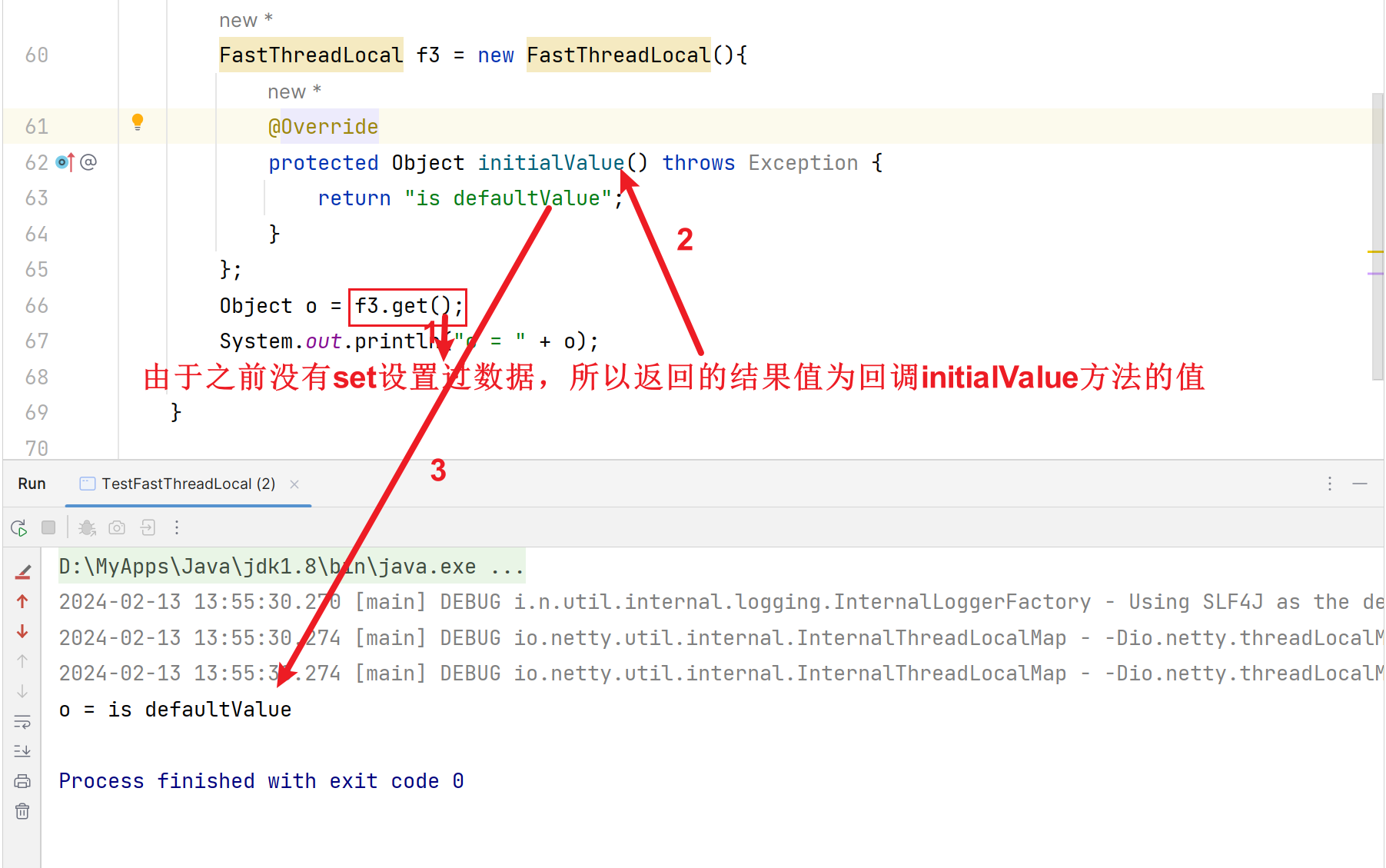
initialValue()这个回调方法可以自定义重写实现:
默认return null!
FastThreadLocal类的

测试:
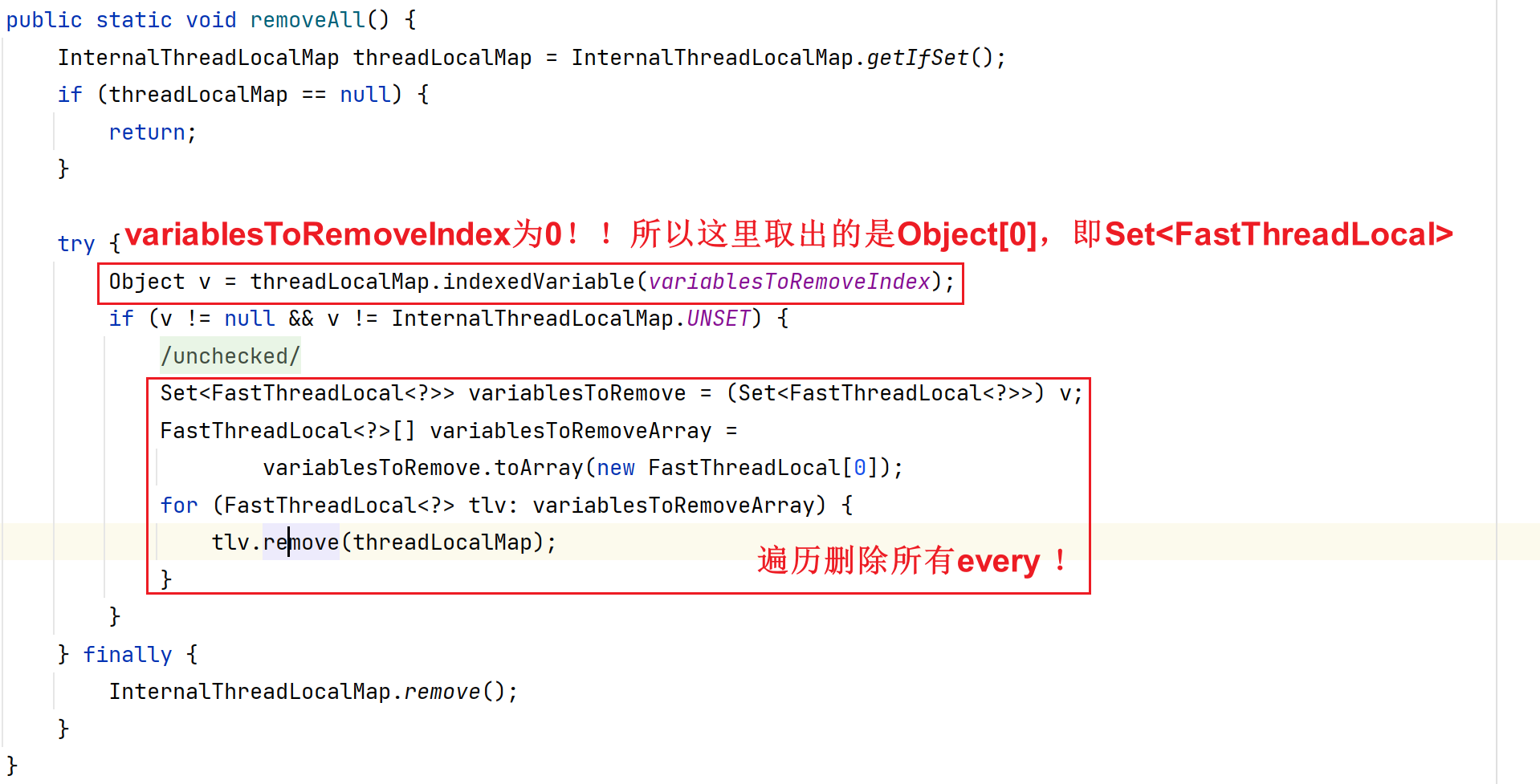
- 补充:为什么要在Object[0]去存储一个Set<FastThreadLocal>集合呢?
为了在删除所有元素的时候,一下子取出所有的FastThreadLocal进行删除。
删除的是所有,即删除Set<FastThreadLocal>中所有的FastThreadLocal,Object[]中存储的所有的数据

- 为什么转换成数组?而不是直接使用Set?
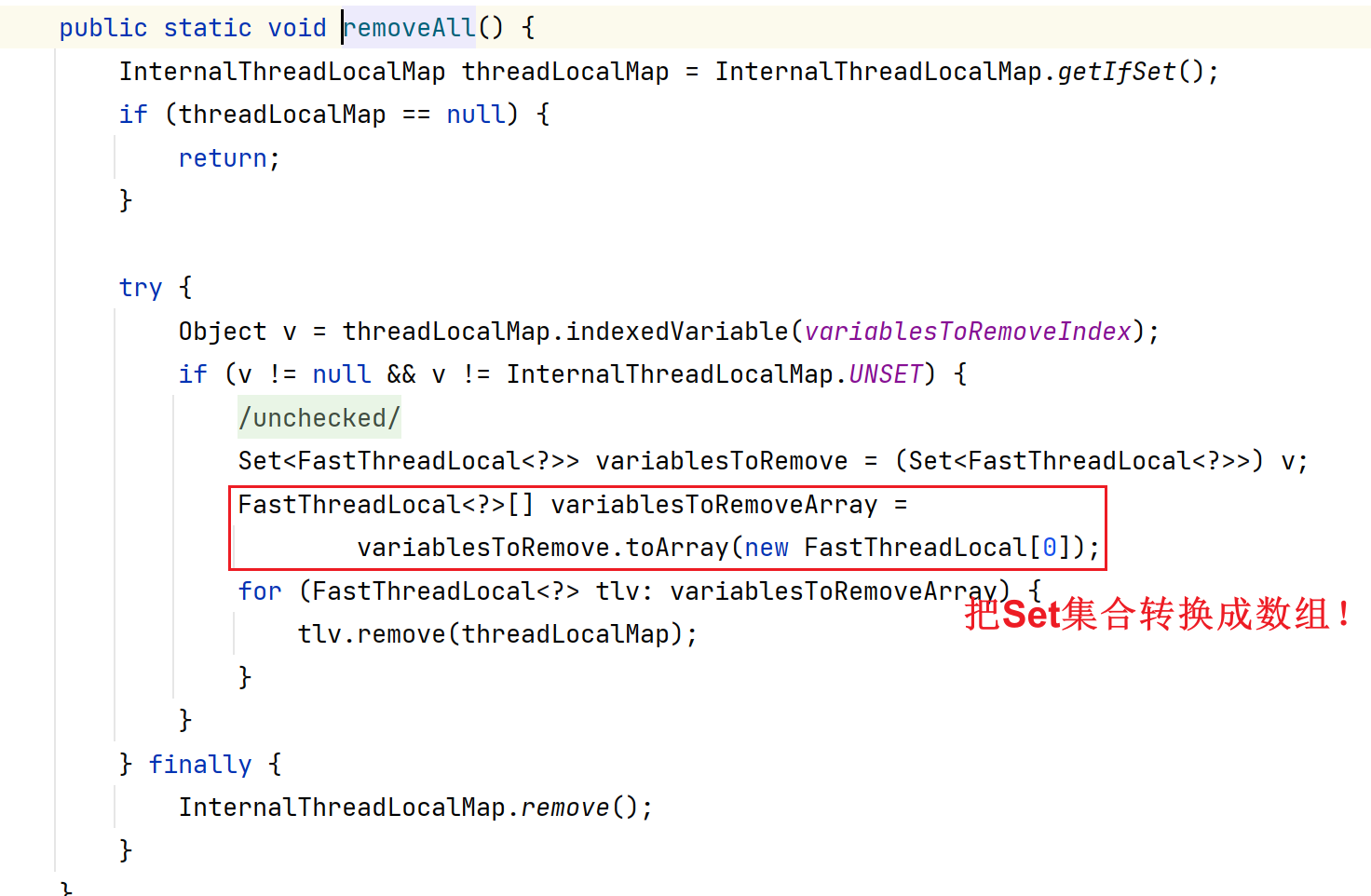
因为数组遍历性能要优于Set!
思考一下之前为什么Netty要优化SelectionKey的存储?从最原始的Set<SelectionKey>优化成Netty体系的SelectionKey[]。其实就是为了利用数组的遍历性能快这一特点!














 673
673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









