







序
既然jdk已经有ThreadLocal,为何netty还要自己造个FastThreadLocal?FastThreadLocal快在哪里?这需要从jdk ThreadLocal的本身说起。在java线程中,每个线程都有一个ThreadLocalMap实例变量(如果不使用ThreadLocal,不会创建这个Map,一个线程第一次访问某个ThreadLocal变量时,才会创建)。该Map是使用线性探测的方式解决hash冲突的问题,如果没有找到空闲的slot,就不断往后尝试,直到找到一个空闲的位置,插入entry,这种方式在经常遇到hash冲突时,影响效率。
ThreadLocal 源码解析
在分析FastThreadLocal源码之前,先来分析ThreadLocal的源码。而分析ThreadLocal源码,在分析ThreadLocal源码之前,先来回顾一下ThreadLocal的使用。
ThreadLocal<Integer> threadLocal = new ThreadLocal<>(); threadLocal.set(1); threadLocal.get(); threadLocal.remove();
上面是不是我们正常使用ThreadLocal方式,既然知道使用,那底层的原理是什么呢?先来看ThreadLocal<Integer> threadLocal = new ThreadLocal<>();这一行代码 。
public ThreadLocal() {
}
遗憾的是,什么也没有做,就是普通的构造函数调用 。 接下来看set()方法的调用。
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
set()方法的原理也很简单,通过当前线程获取一个ThreadLocalMap对象,如果获取到了,则设置当前值,如果没有获取到 ThreadLocalMap,则创建ThreadLocalMap,并且设置ThreadLocalMap,但是这里需要注意一点,先来看ThreadLocalMap 的结构 。 
结果发现,当调用set方法,实际上是创建了一个Entry对象,存储于ThreadLocalMap的Entry[] table数组中。

但是发现Entry继承了WeakReference类,这样做的用意是什么呢?Entry为什么要继承一个弱引用呢?网上有一篇博客 threadLocalMap 为啥用弱引用 :为了让threadlocal的回收逻辑与使用该threadlocal的线程的回收逻辑相独立

ThreadLocal 举例来说可以作为一个对象中的引用,比如这个对象回收了,但线程是复用的(比如线程池)如果entry是强引用,就会引起threadlocal一直不回收。
为了防止类似情况发生,采用的弱引用。
有人说我平时都是用静态变量啊?如下

会将threadLocal变量声明为static的。但同样,我们也可以这样使用。
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
methodThreadLocal();
}
}
public static void methodThreadLocal() {
ThreadLocal<LargeObject> threadLocalLargeObject = new ThreadLocal<>();
User user = new User();
threadLocal.set(new LargeObject());
threadLocal.get();
}
每次methodThreadLocal()方法调用都创建一个threadLocalLargeObject对象,每个线程中所有的ThreadLocal对象共用一下ThreadLocal.ThreadLocalMap,而在ThreadLocalMap中有一个Entry[] table属性,每个Entry对应一个ThreadLocal对象,Entry是一个key ,value 结构,key 存储了ThreadLocal对象,value存储了用户threadLocal.set(new LargeObject()) set 的业务值,这里value是 LargeObject 对象,在上例中当方法调用完,user 对象会被JVM回收掉,假如Entry的key(也就是ThreadLocal对象)属于强引用,而ThreadLocal.ThreadLocalMap是Thread对象的一个属性,它的生命周期和线程一样,而 Entry[] table又是ThreadLocalMap的属性,因此ThreadLocal.ThreadLocalMap.table.key(也就是ThreadLocal对象)一直是被强引用着,直到线程销毁,一直存在于内存中,对应的Entry对象在线程销毁前也一直不能被销毁,如果value是一个大对象,那么对象内存是一个极大的浪费,如果将 ThreadLocal 对象存储于弱引用对象中,那是什么样的情景呢?
先来看弱引用的定义和说明
【定义】
弱引用是使用WeakReference创建的引用,弱引用也是用来描述非必需对象的,它是比软引用更弱的引用类型。在发生GC时,只要发现弱引用,不管系统堆空间是否足够,都会将对象进行回收。
【说明】
弱引用,从名字来看就很弱嘛,这种引用指向的对象,一旦在GC时被扫描到,就逃脱不了被回收的命运。
在方法的内部,threadLocalLargeObject对象属于强引用,当方法调用结束,Entry中的key (也就是threadLocalLargeObject对象),Entry对它属于弱引用,因此随时可能被GC回收掉,而在后面ThreadLocal源码阅读中,时刻记住这一点,不然很多的代码感觉莫名其妙。
当然在实际开发中,静态变量会导致Threadlocal一直被强引用指着,ThreadlocalMap中的弱引用强引用并没有什么区别,刚刚提到的只有Threadlocal对象作为对象中的成员变量时,与线程做了分割。
接下来看ThreadLocal的set方法。
public void set(T value) {
Thread t = Thread.currentThread();
// 从当前线程中获取threadLocals对象,如果没有,则创建一个ThreadLocalMap对象
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
上面代码也没有什么逻辑,如果当前线程ThreadLocalMap对象已经创建好,则直接返回,并调用其set()方法,如果ThreadLocalMap为空,则调用createMap()方法创建ThreadLocalMap对象。 接下来看createMap()方法的实现。
void createMap(Thread t, T firstValue) { t.threadLocals = new ThreadLocalMap(this, firstValue); } ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) { // INITIAL_CAPACITY的默认值为16 table = new Entry[INITIAL_CAPACITY]; int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1); table[i] = new Entry(firstKey, firstValue); size = 1; setThreshold(INITIAL_CAPACITY); } private void setThreshold(int len) { threshold = len * 2 / 3; }
上面这些代码,看上去简单,但有几点需要注意,首先创建了一个长度为16的Entry数组,其次firstKey.threadLocalHashCode & (16 - 1);是这一行代码,每个ThreadLocal变量都对应一个threadLocalHashCode哈希值,firstKey.threadLocalHashCode & 15的意思再明白不过了,也就是通过firstKey.threadLocalHashCode对15取余,从而计算ThreadLocal应该存储在table数组的索引值,这一点和HashMap很像。 阅读过HashMap的源码肯定觉得threshold变量很熟悉,不就是负载因子嘛 ,比如HashMap的初始化长度为16,如果负载因子为0.8,则当HashMap的容量为(16*0.8=10)时,需要对HashMap进行扩容,这里的threshold值的含义也是一样,如table的初始化长度为16,threshold = (16 *2 ) /3 = 10 。 当然这里仍然需要注意firstKey.threadLocalHashCode 的HashCode,还有其他隐藏的信息吗?

我们来做一个实验。
public class ThreadLocalTest2 {
private final int threadLocalHashCode = nextHashCode();
private static AtomicInteger nextHashCode =
new AtomicInteger();
private static final int HASH_INCREMENT = 0x61c88647;
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
public static void main(String[] args) {
for (int i = 0; i < 35; i++) {
ThreadLocalTest2 threadLocalTest2 = new ThreadLocalTest2();
int b = threadLocalTest2.threadLocalHashCode;
System.out.println(b & (16 - 1));
}
}
}
执行结果

大家发现规率没有,当数组长度为16时,计数出的数组索引值总是在下面这些值中循环。
0
7
14
5
12
3
10
1
8
15
6
13
4
11
2
9
而且table[16]的数组中,0~15的值没有出现重复,感兴趣的小伙伴可以将数组长度设置为32,则计算出的索引值也只会在0 ~ 31之间,并且不会重复,如果数组长度大于10时,则会进行数组扩容,如果我们定义的所有ThreadLocal都是static变量,则不会出现哈希冲突,但如果在方法中定义了ThreadLocal变量时,此时就会出现哈希冲突了。
public class ThreadLocal5 {
public static void main(String[] args) throws Exception {
ThreadLocal<LargeObject> threadLocal1 = new ThreadLocal<>();
int threadLocal1HashCode = getFieldValue(threadLocal1);
threadLocal1.set(new LargeObject());
System.out.println("threadLocal1的索引值为:" + (threadLocal1HashCode & 15 ));
for (int i = 0; i < 15; i++) {
methodThreadLocal();
}
ThreadLocal<LargeObject> threadLocal2 = new ThreadLocal<>();
int threadLocal2HashCode = getFieldValue(threadLocal2);
System.out.println("threadLocal2的索引值为:" + (threadLocal2HashCode & 15 ));
}
public static void methodThreadLocal() {
ThreadLocal<LargeObject> threadLocal = new ThreadLocal<>();
threadLocal.set(new LargeObject());
threadLocal.get();
}
public static int getFieldValue(ThreadLocal threadLocal) throws Exception{
Field field = ThreadLocal.class.getDeclaredField("threadLocalHashCode");
field.setAccessible(true);
return (int)field.get(threadLocal);
}
}
结果输出threadLocal1和threadLocal2的索引值都为3 。

为什么索引值是3 ,而不是0呢?通过这一行代码threadLocal1.set(new LargeObject());打断点进入。


因此在线程启动运行到threadLocal1.set(new LargeObject());这一行代码时。 ThreadLocalMap的table对象中已经存储过

table[0],table[7],table[14],table[5],table[12]的对象了,只不过table[0],table[5],table[12]已经被gc回收掉了,上述代码比较麻烦,在代码中打断点和不打断点进行调试时,得出的结果不一样。因此重新写了一个例子。
public class ThreadLocal5 {
public static void main(String[] args) throws Exception {
ThreadLocal<LargeObject> threadLocal1 = new ThreadLocal<>();
int threadLocal1HashCode = (int) getFieldValue(threadLocal1, "threadLocalHashCode");
System.out.println("threadLocal1的索引值为:" + (threadLocal1HashCode & (getTableLength() -1 )));
for (int i = 0; i < 15; i++) {
methodThreadLocal();
}
ThreadLocal<LargeObject> threadLocal2 = new ThreadLocal<>();
int threadLocal2HashCode = (int) getFieldValue(threadLocal2, "threadLocalHashCode");
System.out.println("threadLocal2的索引值为:" + (threadLocal2HashCode & (getTableLength() -1 )));
}
public static int getTableLength() throws Exception{
Object threadLocals = getFieldValue(Thread.currentThread(), "threadLocals");
Object ob[] = (Object[]) getFieldValue(threadLocals, "table");
System.out.println("ThreadLocalMap.table[]长度是" + ob.length);
return ob.length;
}
public static void methodThreadLocal() {
ThreadLocal<LargeObject> threadLocal = new ThreadLocal<>();
threadLocal.set(new LargeObject());
threadLocal.get();
// 【注意】:模拟系统gc
int threadLocal1HashCode = (int) getFieldValue(threadLocal, "threadLocalHashCode");
Object threadLocals = getFieldValue(Thread.currentThread(), "threadLocals");
Object ob[] = (Object[]) getFieldValue(threadLocals, "table");
Object entry= ob[threadLocal1HashCode & (ob.length-1)];
Field field = entry.getClass().getSuperclass().getSuperclass().getDeclaredField("referent");
field.setAccessible(true);
field.set(entry,null);
}
public static Object getFieldValue(Object threadLocal, String fieldName) throws Exception {
Field field = threadLocal.getClass().getDeclaredField(fieldName);
field.setAccessible(true);
return field.get(threadLocal);
}
}
由于打断点,不打断点,机器本身的配置,JVM参数都会影响System.gc(),弱引用指向的对象也并不一定就马上会被回收,如果弱引用对象较大,直接进到了老年代,那么就可以苟且偷生到Full GC触发前,所以弱引用对象也可能存在较长的一段时间,因此测试比较麻烦,而系统gc的最终目的是,将Entry的referent属性回收掉,也就是调用Entry的get方法将返回null,因此使用加粗代码模拟System.gc(),通过获取ThreadLocal对象对应的Entry的referent值,将他设置为空,而JVM回收弱引用也是将referent设置为空,当ThreadLocal及时被JVM回收,table的length将不会超过负载因子10 ,因此就不会出现扩容,当第一个ThreadLocal对象的threadLocalHashCode & (16 -1 ) 和第17个ThreadLocal变量的threadLocalHashCode & (16 -1) 的值会相等,此时就会出现Hash值的冲突问题。

打印结果,ThreadLocal变量1和ThreadLocal变量2的threadLocal2的索引值为都为3,当然这些基础知识对于后面理解ThreadLocal源码有重要作用 。 接下来,继续看set()方法 。
private void set(ThreadLocal<?> key, Object value) { // We don't use a fast path as with get() because it is at // least as common to use set() to create new entries as // it is to replace existing ones, in which case, a fast // path would fail more often than not. Entry[] tab = table; int len = tab.length; // 计算当前变量value应该存储在table[i]桶的位置 int i = key.threadLocalHashCode & (len-1); for (Entry e = tab[i]; e != null; // 每一次i = i ++ ,如果i > len -1 ,则i = 0 // 相当于循环遍历table[i]数组 e = tab[i = nextIndex(i, len)]) { // 如果table[i] 并不为空,会存在如下两种情况 ThreadLocal<?> k = e.get(); // 第一种情况 // ThreadLocal threadLocal = new ThreadLocal<>(); // threadLocal.set(1); // threadLocal.set(2); // 第二次对threadLocal变量赋值时,此时两次传入的ThreadLocal变量相等 // 则直接用整形 2 覆盖掉 1 的值即可 if (k == key) { e.value = value; return; } // 进入下面代码块会存在两种情况 // 第一种情况,如i的值为3,当第17个ThreadLocal的计算出的索引值也为3 // ,当然table[]数组没有扩容,并且索引值 2~16 的table[i] 被JVM 回收的情况 // 就会出现第1个和第17个ThreadLocal变量的哈希值都为3的情况 // 此时假如 第一个ThreadLocal已经被JVM回收,k则为空 // 第二种情况,当然table[]数组没有扩容,并且索引值 2~16 的table[i] 被JVM 回收的情况 // 就会出现第1个和第17个ThreadLocal变量的哈希值都为3的情况 // 假如第一个ThreadLocal变量并没有被JVM 回收,因为for 循环会查找下一个索引的 // k 值,如果k为空 if (k == null) { replaceStaleEntry(key, value, i); return; } } // 如果table[i] == null ,则直接创建Entry对象,并填充table[i] tab[i] = new Entry(key, value); int sz = ++size; // 如果并没有从table数组中扫描到entry的referent为空 // 也就是说,并没有找到被JVM 回收的ThreadLocal,但此时数组的长度大于 // 等于负载因子threshold,则需要对table进行扩容处理 if (!cleanSomeSlots(i, sz) && sz >= threshold) // 对table[]数组扩容 rehash(); } /** * Increment i modulo len. */ private static int nextIndex(int i, int len) { return ((i + 1 < len) ? i + 1 : 0); } /** * Decrement i modulo len. */ private static int prevIndex(int i, int len) { return ((i - 1 >= 0) ? i - 1 : len - 1); }
先看下图 。

我们看图理解set()方法中的for()循环代码,如果此时ThreadLocal的对应的索引值是3 ,则取出table[3],如果table[3]为空,则直接table[3] = new Entry(key, value) ,如果此时table[i]不为空,则分两种情况,第一种情况table[i]的key值和当前ThreadLocal相等,当前ThreadLocal对象之前调用过set()方法并设置过值,此时直接将当前值覆盖掉之前的值即可,如果table[i]的key值和当前ThreadLocal又分为两种情况,第一种情况,table[i]的key值为空,table[i]的key值已经被JVM回收掉,第二种情况table[i]的key值不为空,外层for循环继续调用nextIndex(i, len) 方法查找下一个i,如 table[3].key != 当前ThreadLocal,则会查找table[4] ,table[5],table[6] … ,直到查找到table[i].key为空或table[i]为空为止, 有人会说,万一查找完 整个table[i]数组,都没有查找到满足table[i].key为空或者table[i]为空的条件会怎么办呢?这个你不用操心,每次向table数组中添加成功一个元素时,都会判断当前数组的长度 大于 threshold 没有,而threshold 肯定小于 table.length的,因此无论何时,table[] 数组总有空闲的位置,大家有没有发现问题,如果table[3] 已经被占用用,会继续查找table[i],直到table[i]或table[i].key为空,如果存在哈希值冲突比较多时,是不是插入和查找元素对性能带来影响 。 接下来看当table[i]的key为空时,则调用replaceStaleEntry()方法来处理。
private void replaceStaleEntry(ThreadLocal<?> key, Object value, int staleSlot) { Entry[] tab = table; int len = tab.length; Entry e; // Back up to check for prior stale entry in current run. // We clean out whole runs at a time to avoid continual // incremental rehashing due to garbage collector freeing // up refs in bunches (i.e., whenever the collector runs). int slotToExpunge = staleSlot; for (int i = prevIndex(staleSlot, len); (e = tab[i]) != null; i = prevIndex(i, len)) if (e.get() == null) slotToExpunge = i; // Find either the key or trailing null slot of run, whichever // occurs first for (int i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { ThreadLocal<?> k = e.get(); // If we find key, then we need to swap it // with the stale entry to maintain hash table order. // The newly stale slot, or any other stale slot // encountered above it, can then be sent to expungeStaleEntry // to remove or rehash all of the other entries in run. if (k == key) { e.value = value; tab[i] = tab[staleSlot]; tab[staleSlot] = e; // Start expunge at preceding stale entry if it exists if (slotToExpunge == staleSlot) slotToExpunge = i; cleanSomeSlots(expungeStaleEntry(slotToExpunge), len); return; } // If we didn't find stale entry on backward scan, the // first stale entry seen while scanning for key is the // first still present in the run. if (k == null && slotToExpunge == staleSlot) slotToExpunge = i; } // If key not found, put new entry in stale slot tab[staleSlot].value = null; tab[staleSlot] = new Entry(key, value); // If there are any other stale entries in run, expunge them if (slotToExpunge != staleSlot) cleanSomeSlots(expungeStaleEntry(slotToExpunge), len); }
一看上面代码,其实也是一头晕,什么东西,这么多,但你不用担心,我会一行一行代码给你解释,先来看这一段代码 。
int slotToExpunge = staleSlot; for (int i = prevIndex(staleSlot, len); (e = tab[i]) != null; i = prevIndex(i, len)) if (e.get() == null) slotToExpunge = i;
还是看图说话 。

如果table[3].key为空,此时向前查找会分几种情况 。
- 如果table[2].key为空,则slotToExpunge = 2
- 如果table[2].key不为空,而table[1].key为空,则slotToExpunge = 1
- 如果table[2] 为空,即使table[1].key 为空,slotToExpunge = 3
- 如果table[2],table[1],table[0]都不有空,且key也不为空,但table[15]不为空,但table[15].key为空,则slotToExpunge = 15 。
- 如果table[2],table[1],table[0]都不有空,且key也不为空,但table[15]为空,则slotToExpunge = 3。
我相信通过上述举例,你应该对上述代码块理解了。所以table[slotToExpunge]不为空,且table[slotToExpunge].key 被JVM回收掉了。 继续看后面的代码块。
接下来看下面这段代码块。
for (int i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
tab[i] = tab[staleSlot];
tab[staleSlot] = e;
if (slotToExpunge == staleSlot)
slotToExpunge = i;
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return;
}
if (k == null && slotToExpunge == staleSlot)
slotToExpunge = i;
}
依然是看图说话 。

已知table[3]不为空,但table[3].key为空,如果table[4]不为空,但table[4].key为空,此时分两种情况 。
- 如果从table[3]向前查找,查找到table[pre] 不为空,但table[pre].key为空的情况,此时slotToExpunge = pre 的值,slotToExpunge依然维持slotToExpunge = pre 。
- 像上面的第5种情况 5. 如果table[2],table[1],table[0]都不有空,且key也不为空,但table[15]为空,则slotToExpunge = 3,此时因为slotToExpunge = staleSlot = 3,而table[4].key为空,则slotToExpunge = 4 。
因此下面这段代码的意思是
...
for (int i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
...
if (k == null && slotToExpunge == staleSlot)
slotToExpunge = i;
}
如果从table[staleSlot]不为空,但table[staleSlot].key为空,如果向前查找,能查找到table[pre]不为空,但table[pre].key为空,则无论从table[staleSlot]向后查找的结果如何,slotToExpunge始终只会保存pre的值。 但如果向前查找没有查找到符合条件的值,则向后查找,查找到第一个table[next] 不为空,且table[next].key为空,则slotToExpunge保存next的值,如table[4],table[5]都不为空,而table[4].key和table[5].key都为空,则slotToExpunge始终等于4 。 接下来理解下面这段代码 。
for (int i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
tab[i] = tab[staleSlot];
tab[staleSlot] = e;
if (slotToExpunge == staleSlot)
slotToExpunge = i;
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return;
}
...
}
如果向后查找过程中,查找到key 等于当前ThreadLocal对象,则交换位置。如下图所示

已知table[3]为空,而当前ThreadLocal计算的索引值为3,此时向后查找,如果table[5].key 等于当前ThreadLocal变量,此时将table[3]和table[5]的位置交换,如果此时slotToExpunge=3 ,则修改slotToExpunge=5。 当然,如果向后查找过程中,直到table[next]为空了,依然没有查找到table[next].key值等于当前ThreadLocal时,则直接调用下面代码块即可。 当然 tab[staleSlot].value 是help gc操作
tab[staleSlot].value = null;
tab[staleSlot] = new Entry(key, value);
从ThreadLocalMap的table 存储特性可以得知,如果存在hash冲突,如table[3].key不为空,此时计算出相同索引值为3的ThreadLocal只能向后查找,找到一个空位,则将当前ThreadLocal保存进去,当下一次再次来设置当前ThreadLocal的值时,table[3].key可能被JVM回收掉了,此时不能直接将table[3] = new Entry(当前ThreadLocal, value) ; 而是需要向后查找,看有没有table[next].key = 当前ThreadLocal的,如果有,则需要将table[next] 和 当前table[3]的位置进行交换,这样也很好理解,如果当前ThreadLocal已经占用了其他槽位,而当前ThreadLocal计算出的槽位是table[3],为了提升查找性能,需要将当前ThreadLocal存储于table[3]上,但存储之前,需要看之前有没有存储过当前ThreadLocal相关的数据,如果存储过,则需要将其清理掉,不然,table数组中存储的数据就会重复。 当然,还需要考虑一个问题,为什么当查找到table[next] 为空时,依然没有查找到table[next].key 等于当前ThreadLocal时,就推断出table中肯定没有存储过当前ThreadLocal 相关的数据 ,就不再继续查找了呢?答案来源于expungeStaleEntry()方法,进入expungeStaleEntry方法的研究 。
private int expungeStaleEntry(int staleSlot) { Entry[] tab = table; int len = tab.length; table[staleSlot].key为空, // 设置table[staleSlot].value为空,帮助gc,同时table存储元素的个数减1 tab[staleSlot].value = null; tab[staleSlot] = null; size--; Entry e; int i; for (i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { ThreadLocal<?> k = e.get(); if (k == null) { e.value = null; tab[i] = null; size--; } else { int h = k.threadLocalHashCode & (len - 1); if (h != i) { tab[i] = null; while (tab[h] != null) h = nextIndex(h, len); tab[h] = e; } } } return i; }
结合replaceStaleEntry()方法来看expungeStaleEntry()方法,在expungeStaleEntry方法中的staleSlot参数实际上是replaceStaleEntry()方法中的slotToExpunge变量,也就是说table[slotToExpunge]不为空,且table[slotToExpunge].key的值为空,已经被JVM回收掉了。

场景是这样子的,之前ThreadLocal1对象存储位置对于table[5],而此时table[3].key已经被JVM回收为空,而table[4]不为空,但table[4].key为空,并且之前的table[3],table[4],table[5].table[6].table[7] 中ThreadLocal对应索引值都是3,只不过table[3],table[4].key已经被回收了,当然table[8]为空, 而在replaceStaleEntry()方法中,已经将table[3]和table[5]交换,假设table[3]之前的元素中并没有table[pre].key为空的情况, 因此slotToExpunge=4,此时再来理解expungeStaleEntry()方法,首先将table[4]的value值设置为空,再将table[4]=null,并且数组中存储元素size - 1 , 因为在replaceStaleEntry()方法中table[5]只是和table[3]交换位置,并没有将table[5]置空, 因此table[5]会走下面红框代码逻辑

此时再次遍历table[6] ,而table[3]已经被当前ThreadLocal占用,但table[4]和table[5] 已经被置空,而table[6]会走下面红框代码。

先查找table[3]有没有被占用,如果被占用,再查找table[4]有没有被占用,在前面已经将table[4]置空了,此时table[4] = table[6],并且将table[6] 置空,而i继续++,因为table[5]已经被
e.value = null;
tab[i] = null;
size–;
这段代码置空了,因此table[7]又会走table[6]地老路,table[5]=table[7],table[7] = null,而table[8]本身为空,则退出循环,返回i = 7 ,通过expungeStaleEntry()方法的调用,最终table[3],table[4],tab[5]被填充,table[6],table[7]被置空 ,大家发现没有,每一次expungeStaleEntry()方法调用,都会将table[next]放到其对应的索引位置i,或者table[i]后面的元素,如table[3] ,table[4],table[5] 对应的索引都为3,table[6]为空,table[3] 不为空,table[4]的key为空,table[5]的key不为空, 经过expungeStaleEntry()方法调用后,不可能出现table[3]不为空,table[4] 为空,table[5]不为空的情况,只会是table[3] 依然是原来的table[3] , table[4] = table[5] ,table[5] 为空,expungeStaleEntry()方法的目的是将table压紧实一点。 为什么从ThreadLocal Hash码对应的索引值向后查找,只要查找到table[next]为空还没有查找key为ThreadLocal的变量,则证明 table中没有存储过ThreadLocal对应的Entry呢?搜索ThreadLocal源码,发现只有expungeStaleEntry()方法中

才会将table[i] 置空,调用threadLocal的remove()方法,也只是将table[i].key置空,真正的将table[i]置空的代码还是在expungeStaleEntry()方法中,而expungeStaleEntry()方法不仅有将table压紧实的功能,还有重置table[i]位置的功能 ,具体代码在如下代码 。
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
tab[i] = null;
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
当k不为空,则通过k.threadLocalHashCode & (len - 1);计算出ThreadLocal应该的索引值 h ,计算出的索引值 和 当前 ThreadLocal 存储的索引值不相等,则从 h向后一个一个查找,如果不幸运的话,依然可能ThreadLocal还是放回到原来的位置 。依然是看图说话 。

当table[2].key 为空,table[3]的索引值为3,table[4]的索引值为4,table[4]的索引值为5 ,table[6]的索引值为3 ,则expungeStaleEntry()方法中,table[2] 被置空,当 table[6]计算出索引值为3,但table[4],table[4],table[5]都不为空,因此table[6] 依然还是放回到原来的位置 。
好像还是没有说明白,为什么从ThreadLocal Hash码对应的索引值向后查找,只要查找到table[next]为空还没有查找key为ThreadLocal的变量,则证明 table中没有存储过ThreadLocal对应的Entry对象?那我们从另外一个理论上来分析 。

比如当前ThreadLocal计算出索引值为3,如果当前ThreadLocal 存储在table[3]这个位置,第一次通过k.threadLocalHashCode & (len - 1) = 3 计算索引,就能立刻查找到它,但当前ThreadLocal 不存储在table[3],那么只可能存储在table[4] … 之后的位置,假如存储的位置为table[i],ThreadLocal.set()方法的特性就决定了 3 ~ i之间的table元素肯定不为空,当3 ~i 之间的元素需要置空时,则会调用expungeStaleEntry()方法,而expungeStaleEntry()方法中的for循环肯定会遍历3 ~ i 元素,甚至是i 之后的元素,因为for循环的条件就是 ,
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len))
e[i]不等于空时,将一直循环下去,因此当 i 将被下面
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
tab[i] = null;
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
这段代码处理,如果 table[3]为空,并且3 ~i 之间没有索引值为3的ThreadLocal,table[3]将被table[i] 替换,如果table[3] 不为空,此时会从索引值为3向后遍历,直到找到一个空位为止,假如是 j ,那么3 ~ j 之间的元素肯定都不为空,因此在查找时,只要table[next] == null 时依然没有查找到当前ThreadLocal对应的Entry,则证明table中没有存储当前ThreadLocal对应的Entry。我相信现在你总对expungeStaleEntry()方法理解了吧。接下来看cleanSomeSlots()方法 。
private boolean cleanSomeSlots(int i, int n) { boolean removed = false; Entry[] tab = table; int len = tab.length; do { i = nextIndex(i, len); Entry e = tab[i]; if (e != null && e.get() == null) { n = len; removed = true; i = expungeStaleEntry(i); } } while ( (n >>>= 1) != 0); return removed; }
其实cleanSomeSlots()这个方法可以用佛系的思维来理解,首先table[i]肯定为空,看cleanSomeSlots()方法有三个地方调用,


在expungeStaleEntry()方法返回值i , table[i]肯定为空,而set()方法中,table[i] 等于新插入的值,在cleanSomeSlots()方法中,table[i]是不能动的。 先来模拟测试一下cleanSomeSlots()方法。

假如table 数组的长度为16,默认情况下,如果table[i + 1] ,table[i + 2 ] ,table[i + 3 ] ,table[i + 4 ] ,table[ i + 5 ] 没有key 为空的元素,则退出循环, i + 1 ~ i + 5 之间有任意一个元素的key值为null,则会调用expungeStaleEntry()方法,开始清理元素,假如table [i + 1 ] ~ table[ i + 5] 之间的元素中,table[i + 4] 为空, table[i+6] 不为空,table[i + 7] 为空,此时调用expungeStaleEntry()方法,将table[i+4]设置为空,假如table[i +5] 和table[i +6] 的ThreadLocal HashCode的索引值和table[i + 4]相同,则table[i + 4] 将被table[i + 5]或table[i + 6] 覆盖掉,此时table[i + 7] 为空,则此时expungeStaleEntry()方法将返回i + 7,因此在cleanSomeSlots方法中i = i + 7 ,并且设置remove为true,这个有什么用呢? 在set()方法中,如果向table中添加了元素,此时调用cleanSomeSlots()方法返回true,则证明移除元素成功,则不需要进行扩容判断,如果调用expungeStaleEntry方法返回 i = i + 7 ,则此时在cleanSomeSlots()方法while循环判断table[i + 8 ] ~ table[ i + 12 ] 有没有元素的key值为空,重复上面i + 1的操作,当然称它比较佛系,是因为从i + 1 开始查找,如果查找log2(table.length)次都没有找到key为空的元素,则放弃查找。 假如table[i + 1 ] ~ table[i + 5] 的key都不为空,但table[i +6] 的key值为空,而此时刚好table中存储的元素个数大于等于 10,即使table[i +6]的key为空,也会导致table扩容。 既然这里涉及到table[]扩容处理,接下来分析table[]扩容代码 。 rehash()函数实现。
private void rehash() { expungeStaleEntries(); // 如果当前table的元素个数大于等于 threshold - threshold / 4,则重新进行hash值的计算 if (size >= threshold - threshold / 4) resize(); }
先调用expungeStaleEntries()函数,如果此时size的值仍然大于threshold - threshold / 4,则对数组进行扩容,先来看expungeStaleEntries()代码,再来分析扩容机制。
private void expungeStaleEntries() {
Entry[] tab = table;
int len = tab.length;
for (int j = 0; j < len; j++) {
Entry e = tab[j];
if (e != null && e.get() == null)
expungeStaleEntry(j);
}
}
上面这段代码的理解很简单,就是遍历整个table数组,将table[i].key为空的table[i]元素置空掉。再结合rehash()函数来看,如果清空掉所有的table[i].key为空的元素之后,此时数组的长度仍然大于等于threshold - threshold / 4,则对数组进行扩容,这里需要注意一点,假如数组长度为16,则threshold = 16 * 2 / 3 = 10 ,而当 10 - 10/4 = 8 ,这下好理解了,当table中元素个数大于等于10个时,此时会触发rehash,而rehash方法中,先遍历整个table数组,清除掉table[i].key为空的元素,也就是ThreadLocal已经被JVM回收的Entry元素,此时若剩下的元素个数仍然大于等于8,则需要对table数组扩容了。接下来看table数组的扩容逻辑。
private void resize() { Entry[] oldTab = table; int oldLen = oldTab.length; int newLen = oldLen * 2; // 数组长度扩容为原来的两倍 Entry[] newTab = new Entry[newLen]; int count = 0; for (int j = 0; j < oldLen; ++j) { Entry e = oldTab[j]; if (e != null) { ThreadLocal<?> k = e.get(); // 如果扩容过程中,table[j].key已经被JVM回收了 // 先将e.value设置为空,有助于GC if (k == null) { e.value = null; // Help the GC } else { // 重新计算table[j]的ThreadLocal的hash值对应的索引 int h = k.threadLocalHashCode & (newLen - 1); // 如果索引位置已经存储了其他元素,则h ++ // 直到table[h+i] == null为止,此时k对应Entry 存储于table[h+i]中 while (newTab[h] != null) h = nextIndex(h, newLen); newTab[h] = e; // 记录table[]数组中存储的元素个数 count++; } } } // 重新设置负载因子 setThreshold(newLen); size = count; table = newTab; }
resize()方法的逻辑也很简单,但需要注意的时,在进行数组拷贝时,仍然有table[j].key被jvm回收的可能,其他的就容易了,因为数组的长度变为原来的两倍,当然每个元素的key对应在table中的索引也需要重新计算,计算出来的索引所在位置如果已经被其他元素占用,依次向后查找,直到找到空位,将table[j]放入进去。 当然在最后,就是重新设置负载因子,数组中存储的有效元素个数,以及用新的table替换掉原来的table。 当然有人会想,这样扩容,会不会存在并发问题,聪明的读者肯定想到了,在同一个线程中,假如ThreadLocal1.set()方法触发扩容,即使此时调用ThreadLocal2.set()方法,也需要当ThreadLocal1.set()方法调用完后,才会触发ThreadLocal2.set()调用,因为ThreadLocal相关的所有操作都在同一个线程中执行,因此上述扩容不存在并发问题。
接下来看ThreadLocal的get()方法调用 。
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
当ThreadLocalMap不存在时,此时会调用setInitialValue()方法初始化ThreadLocalMap,
private T setInitialValue() { T value = initialValue(); Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) map.set(this, value); else createMap(t, value); return value; } protected T initialValue() { return null; }
setInitialValue()方法和set()方法很相似,调用setInitialValue()方法的好处是什么呢?虽然初始化当前ThreadLocal的value值为null,但提前调用get()方法,能使得当前ThreadLocal先去table数组中占领一个槽位,当下次再使用时,能尽快的查找到当前ThreadLocal所对应的槽位,一定程度上提升了当前ThreadLocal的使用速度 。当然如果已经存在了ThreadLocalMap,则会调用其getEntry()获取Entry,如果Entry对象不为空,则返回Entry的value值 。 接下来进入getEntry()方法的阅读 。
private Entry getEntry(ThreadLocal<?> key) { int i = key.threadLocalHashCode & (table.length - 1); Entry e = table[i]; if (e != null && e.get() == key) return e; else return getEntryAfterMiss(key, i, e); }
这里分为两种情况,先通过ThreadLocal的threadLocalHashCode值计算出在table数组中的位置,如果table[i].get() == 当前ThreadLocal,则直接返回table[i]对应的Entry即可,但如果table[i]被其他的ThreadLocal占用了,此时需要调用getEntryAfterMiss()方法进一步查找当前ThreadLocal对应的Entry。在之前的源码中知道,在调用set()方法时,如果table[i]被其他元素占用,则会从table[i+1]开始向后查找,直到找到一个空位table[i +j]为止,再将当前ThreadLocal封装成Entry存储于空位的table[i +j]中。我们来看第二种情况 。
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) { Entry[] tab = table; int len = tab.length; while (e != null) { ThreadLocal<?> k = e.get(); if (k == key) return e; if (k == null) expungeStaleEntry(i); else i = nextIndex(i, len); e = tab[i]; } return null; }
上述代码中也很好理解,从 i 开始向后查找,如果table[i].key的值等于当前线程,则说明找到了对应的Entry了,如果table[i + j ] == null 还没有找到有key值和当前ThreadLocal相等的Entry,说明此table中没有存储ThreadLocal对应的Entry,如果从table[i]向后查找过程中,发现table中的元素key值为空,说明此元素可以被清理,因此会调用expungeStaleEntry()方法清除被JVM回收的元素。虽然上述代码看上去简单,但依然有两处代码暗藏杀机。
-
为什么在getEntry()方法中已经判断过e == null || e.get() != key ,才会调用getEntryAfterMiss()方法,e == null 调用getEntryAfterMiss()方法很好理解,直接返回null即可,根本不会进入while()循环,但e !=null && e.get() != key 时调用getEntryAfterMiss()方法,此时i 为什么不从 i + 1 开始判断,在getEntry()方法中已经确定了e !=null && e.get() != key ,在while()循环内部还进行 if (k == key) 判断不是多此一举吗?聪明的读者肯定看到了if (k == null) 这一行代码,显然对于 e !=null && e.get() != key 这种情况,k == key 一定为false,但会进入到if (k == null) 这一行的判断,因为在getEntry()方法中判断时, e.get() 是不为空的,但在getEntryAfterMiss()方法调用时,e.get()可能就被JVM回收掉了,所以存在e.get()==null的情况,如果e.get()==null ,则将table[i] 对应的e 置空掉,所以在getEntryAfterMiss()方法中对table[i]的处理并不是多此一举,一定程序上优化程序的性能,节省内存空间。
-
另外一个疑问,在expungeStaleEntry(i) 调用时,此时 i 并没有 + 1 ,为什么呢?而是当expungeStaleEntry(i);调用完成时,依然从获取table[i]的值进行判断,之前阅读expungeStaleEntry(i)的源码时就已经知道,expungeStaleEntry()方法有两个功能,第一,压缩清理table[i],第二,重置table中元素的索引。 还是以之前的例子来分析,假如table[3],table[4],table[5] ,table[6]4个元素,table[3],的索引为3,table[4]的索引为4,table[5]的索引为3,table[6]为空值,当前ThreadLocal对应的Entry存储于table[5],但此时table[3].key被JVM回收掉,此时i = 3 ,调用expungeStaleEntry()方法,expungeStaleEntry()方法的内部,先将table[3] 置空,此时会向后查找到table[4],而table[4]的索引为4,依然将table[4]放在原来的位置,此时table[5]就是当前ThreadLocal对应的元素,并且table[5]对应的索引为3,此时会将table[3] = table[5], table[5]置空,因此在调用完expungeStaleEntry()方法后,table[3] 中存储了当前ThreadLocal对应的Entry,因此当发现i 的key为空时,调用expungeStaleEntry(i) 方法后,查找位置依然只能从i 开始,不能从i +1 开始,在expungeStaleEntry()方法的处理过程中,可能会将i 后面的元素移动到table[i]上来,如果i + 1 ,则会漏掉table[i]元素的比对 。
虽然get()方法看上去简单,但是也暗藏着上述两处细节,希望细心的读者能够发现 。
接下来看ThreadLocal的remove()方法 。
private void remove(ThreadLocal<?> key) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
if (e.get() == key) {
e.clear();
expungeStaleEntry(i);
return;
}
}
}
public void clear() {
this.referent = null;
}
remove()方法的原理就很简单了, 先通过 key.threadLocalHashCode计算出key对应在table中的位置,然后从 i 开始向后逐个查找,如果查找到当前ThreadLocal对应的Entry元素,则将Entry的key设置为空,再调用expungeStaleEntry()方法,清理,压缩,移动元素 。
ThreadLocal源码总结:
有人说ThreadLocal性能真心差,但我觉得ThreadLocal的设计还是有很多值得学习的地方,也为我们考虑了很多,ThreadLocal性能真心差吗?不好说,如果项目中都是使用全局static变量来使用ThreadLocal,则不可能存在hash冲突,性能无与伦比,当大量在方法内部使用ThreadLocal时,这种情况可能就会出现hash冲突,但每次在set,get()元素的过程中,都会存在重置ThreadLocal的位置可能,在设置和查找过程中,性能真的那么差吗?也不好说,只是在极端情况下,才会出现比较多的依次查找的情况,当然FastThreadLocal 是后面开发和设计的,它肯定是发现了ThreadLocal可能存在的风险,从而规避了这些性能差的风险,真正意义上的达到完美。接下来将分析 FastThreadLocal源码 。
在研究FastThreadLocal源码之前,依然是看一个例子。
public class FastThreadLocalTest2 {
public static void main(String[] args) {
final FastThreadLocal<String> threadLocal = new FastThreadLocal<String>();
threadLocal.set("1");
System.out.println(threadLocal.get());
threadLocal.remove();
FastThreadLocal.removeAll();
}
}
从这个例子中,依然关注4个方法,FastThreadLocal()的构造方法,set()方法,get()方法, remove()方法,removeAll()方法。
先来看FastThreadLocal的构造函数。
private static final int variablesToRemoveIndex = InternalThreadLocalMap.nextVariableIndex();
private final int index;
public FastThreadLocal() {
index = InternalThreadLocalMap.nextVariableIndex();
}
这里引用了InternalThreadLocalMap的nextVariableIndex()方法,接下来看nextVariableIndex()方法。
public static int nextVariableIndex() { int index = nextIndex.getAndIncrement(); if (index < 0) { nextIndex.decrementAndGet(); throw new IllegalStateException("too many thread-local indexed variables"); } return index; }
这里又用到了一个变量nextIndex,而nextIndex变量又是InternalThreadLocalMap类的父类,他们之间的关系是父子关系。

先来看一下UnpaddedInternalThreadLocalMap的类结构。

从UnpaddedInternalThreadLocalMap的类结构中可以看出nextIndex是一个静态final变量,当然还有ThreadLocal<InternalThreadLocalMap> slowThreadLocalMap这个变量也值得注意,存储数据的数组当然是Object[] indexedVariables,当然slowThreadLocalMap,nextIndex,indexedVariables 这三个变量有什么用呢?根据FastThreadLocal的源码来分析nextIndex变量。在FastThreadLocal的构造函数中, 初始化了一个变量index,并且index 的值声明为了final类型,因此每个FastThreadLocal都有唯一一个index与之对应 。 同时FastThreadLocal中也有一个variablesToRemoveIndex变量,这个变量也是值得注意的。 这个变量被声明为private static final int variablesToRemoveIndex = InternalThreadLocalMap.nextVariableIndex();
同样variablesToRemoveIndex也属于一个索引值,这个索引值位置的存储了一个 Set<FastThreadLocal<?>>集合,而这个Set集合中的元素也就是InternalThreadLocalMap的indexedVariables数组中存储的元素 。

看图说话 ,在整个程序启动过程中,第一次创建FastThreadLocal会初始化variablesToRemoveIndex变量,一般情况下variablesToRemoveIndex的值为0。而indexedVariables[variablesToRemoveIndex] 这个位置存储了一个Set<FastThreadLocal<?>>集合,在后面源码阅读的过程中,你会发现他是Collections.SetFromMap对象 。 看一下其结构,后面使用到再来分析 。

在整个JVM 运行过程中,每创建一个FastThreadLocal对象,FastThreadLocal的index属性值就会加1,因此每个FastThreadLocal都有唯一一个index与之对应,这就带来另外一个问题,如上图中线程1 创建的3个FastThreadLocal,其索引值分别是1,4,5 ,而线程2创建的4个FastThreadLocal对应的索引值分别是2,3,6,7。 不同的线程创建的FastThreadLocal的索引值不会重复。 当然啦, 如果index的值大于Integer.MAX_VALUE时,会抛出异常,就是JVM 整个运行中,创建FastThreadLocal对象个数大于 Integer.MAX_VALUE,再次创建FastThreadLocal时,将抛出too many thread-local indexed variables 异常。
public static int nextVariableIndex() {
int index = nextIndex.getAndIncrement();
if (index < 0) {
nextIndex.decrementAndGet();
throw new IllegalStateException("too many thread-local indexed variables");
}
return index;
}
因为index的值是不能重复的,而每个线程中存储FastThreadLocal数据是一个数组,也就是UnpaddedInternalThreadLocalMap中的indexedVariables属性,而数组是需要提前申请内存空间的,如上图中,因为2,3,6,7槽位被线程2占用了,因此线程1只能将它填充为一个Object 对象的引用,从而来达到节省内存空间,虽然空间的浪费,但换来了性能的提升,任何get(),set()操作都只需indexedVariables[index]就能定位到FastThreadLocal。查找虽然方便了,如果没有 Set<FastThreadLocal<?>> 保存FastThreadLocal的引用,在清理indexedVariables就变得异常麻烦,只能遍历整个indexedVariables数组,显然这样操作性能低下,也是 Netty 所不能容忍的,因此每个线程创建了一个Set<FastThreadLocal<?>> 集合来存储线程中所有FastThreadLocal的引用,当需要removeAll()时,只需要从Set<FastThreadLocal<?>> 中取出FastThreadLocal对象,再从FastThreadLocal对象中取出索引值index,再清除掉indexedVariables[index] 即可。 先来看两个例子,证实上面的代码。
- variablesToRemoveIndex 并不一定是从0开始的,而是在整个JVM运行中,第一次创建FastThreadLocal对象初始化variablesToRemoveIndex变量,先看一个测试用例。
public class FastThreadLocalTest4 {
public static void main(String[] args) throws Exception {
InternalThreadLocalMap.nextVariableIndex();
InternalThreadLocalMap.nextVariableIndex();
InternalThreadLocalMap.nextVariableIndex();
InternalThreadLocalMap.nextVariableIndex();
FastThreadLocal fastThreadLocal = new FastThreadLocal();
System.out.println("variablesToRemoveIndex = "+getFieldValue(fastThreadLocal , "variablesToRemoveIndex"));
fastThreadLocal.set(10);
System.out.println("index = " + getFieldValue(fastThreadLocal , "index"));
}
public static Object getFieldValue(Object threadLocal, String fieldName) {
try {
Field field = threadLocal.getClass().getDeclaredField(fieldName);
field.setAccessible(true);
return field.get(threadLocal);
} catch (NoSuchFieldException e) {
e.printStackTrace();
} catch (SecurityException e) {
e.printStackTrace();
} catch (IllegalArgumentException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
return null;
}
}
结果输出:
variablesToRemoveIndex = 4
index = 5
分析,每一次InternalThreadLocalMap.nextVariableIndex()调用,都会触使UnpaddedInternalThreadLocalMap的nextIndex ++,因此在前面4次调用nextVariableIndex()方法,0,1,2,3 已经被占用,当new FastThreadLocal()时,此时variablesToRemoveIndex的值被第一次初始化,因此值为4, 而FastThreadLocal本身的索引值也就是5了。
- 接下来看另外一个例子,如果索引值被其他线程占用了,那些占用的索引位置真的只能填充Object()对象的引用吗?不能使用吗?答案是肯定的。 再来看一个例子。
public class FastThreadLocalTest3 {
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
new Thread(new Runnable() {
@Override
public void run() {
FastThreadLocal fastThreadLocal0 = new FastThreadLocal();
System.out.println(Thread.currentThread().getName() + ":" + getFieldValue(fastThreadLocal0, "variablesToRemoveIndex"));
fastThreadLocal0.set(10);
System.out.println(Thread.currentThread().getName() + ":" + getFieldValue(fastThreadLocal0, "index"));
FastThreadLocal fastThreadLocal2 = new FastThreadLocal();
System.out.println(Thread.currentThread().getName() + ":" + getFieldValue(fastThreadLocal2, "variablesToRemoveIndex"));
fastThreadLocal2.set(20);
System.out.println(Thread.currentThread().getName() + ":" + getFieldValue(fastThreadLocal2, "index"));
FastThreadLocal fastThreadLocal3 = new FastThreadLocal();
System.out.println(Thread.currentThread().getName() + ":" + getFieldValue(fastThreadLocal3, "variablesToRemoveIndex"));
fastThreadLocal3.set(20);
System.out.println(Thread.currentThread().getName() + ":" + getFieldValue(fastThreadLocal3, "index"));
FastThreadLocal fastThreadLocal4 = new FastThreadLocal();
System.out.println(Thread.currentThread().getName() + ":" + getFieldValue(fastThreadLocal4, "variablesToRemoveIndex"));
fastThreadLocal4.set(20);
System.out.println(Thread.currentThread().getName() + ":" + getFieldValue(fastThreadLocal4, "index"));
}
}).start();
}
try {
Thread.sleep(1000);
FastThreadLocal fastThreadLocal = new FastThreadLocal();
System.out.println(Thread.currentThread().getName() + ":" + getFieldValue(fastThreadLocal, "variablesToRemoveIndex"));
fastThreadLocal.set(10);
System.out.println("========" + Thread.currentThread().getName() + ":" + getFieldValue(fastThreadLocal, "index"));
InternalThreadLocalMap internalThreadLocalMap = InternalThreadLocalMap.get();
Field field = InternalThreadLocalMap.class.getSuperclass().getDeclaredField("indexedVariables");
field.setAccessible(true);
Object[] indexedVariables = (Object[]) field.get(internalThreadLocalMap);
System.out.println(indexedVariables);
} catch (Exception e) {
e.printStackTrace();
}
}
public static Object getFieldValue(Object threadLocal, String fieldName) {
try {
Field field = threadLocal.getClass().getDeclaredField(fieldName);
field.setAccessible(true);
return field.get(threadLocal);
} catch (NoSuchFieldException e) {
e.printStackTrace();
} catch (SecurityException e) {
e.printStackTrace();
} catch (IllegalArgumentException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
return null;
}
}
在前面创建了10个线程,每个线程都创建了4个FastThreadLocal,因为第0个位置被Set<FastThreadLocal<?>>占用,因此前面10个线程总共占有的索引应该是0~40,当主线程睡眠1秒后,他所能分到的索引值是41

再来看,真的indexedVariables数组前面40个槽位是空闲的吗?

从演示效果上来看,确实如我们猜想的那样。
接下来继续看FastThreadLocal的set()方法 。
public final void set(V value) {
if (value != InternalThreadLocalMap.UNSET) {
InternalThreadLocalMap threadLocalMap = InternalThreadLocalMap.get();
setKnownNotUnset(threadLocalMap, value);
} else {
// 传入的值为InternalThreadLocalMap.UNSET,相当于FastThreadLocal.remove() 方法调用
remove();
}
}
在set()方法调用过程中分两种情况,每一种,当设置的value值为InternalThreadLocalMap.UNSET,第二种,当设置的value值不是InternalThreadLocalMap.UNSET时。 因此,先来看value == InternalThreadLocalMap.UNSET 的情况 。先来看 InternalThreadLocalMap.get()这一行代码 。
public static InternalThreadLocalMap get() { Thread thread = Thread.currentThread(); // 如果thread是FastThreadLocalThread if (thread instanceof FastThreadLocalThread) { return fastGet((FastThreadLocalThread) thread); } else { return slowGet(); } } private static InternalThreadLocalMap fastGet(FastThreadLocalThread thread) { InternalThreadLocalMap threadLocalMap = thread.threadLocalMap(); if (threadLocalMap == null) { thread.setThreadLocalMap(threadLocalMap = new InternalThreadLocalMap()); } return threadLocalMap; }
从上述代码来看, 获取InternalThreadLocalMap分两种情况,如果获取到的InternalThreadLocalMap为空,则会调用new InternalThreadLocalMap()初始化threadLocalMap,当然,一个线程只有一个threadLocalMap。 InternalThreadLocalMap没有什么特殊的属性,因此在后面的分析过程中,再来分析具体的方法 ,已知的InternalThreadLocalMap继承UnpaddedInternalThreadLocalMap类,并且拥有Object[] indexedVariables 属性,实际上线程中的所有FastThreadLocal都存储于这个属性中。 接着继续看set()方法,InternalThreadLocalMap.get()方法调用,一定会返回一个InternalThreadLocalMap对象。再调用setKnownNotUnset()方法处理,那setKnownNotUnset()这个方法做了哪些事情呢?
private void setKnownNotUnset(InternalThreadLocalMap threadLocalMap, V value) { if (threadLocalMap.setIndexedVariable(index, value)) { addToVariablesToRemove(threadLocalMap, this); } }
当然设置value的过程中分为两步,第一步将value保存到InternalThreadLocalMap的indexedVariables变量中,第二步, 将新创建的FastThreadLocal记录到Set<FastThreadLocal<?>> ,方便后面removeAll() 方法移除线程中所有的FastThreadLocal,先看setIndexedVariable()方法实现。
public boolean setIndexedVariable(int index, Object value) { Object[] lookup = indexedVariables; if (index < lookup.length) { Object oldValue = lookup[index]; lookup[index] = value; return oldValue == UNSET; } else { expandIndexedVariableTableAndSet(index, value); return true; } }
当然setIndexedVariable()又分为两种情况,如果当前索引值小于 indexedVariables数组长度,则直接将value覆盖掉indexedVariables[index]位置的值即可,如果index的值大于indexedVariables的长度时,则需要对数组进行扩容,接下来看indexedVariables扩容处理。
private void expandIndexedVariableTableAndSet(int index, Object value) { Object[] oldArray = indexedVariables; final int oldCapacity = oldArray.length; int newCapacity = index; newCapacity |= newCapacity >>> 1; newCapacity |= newCapacity >>> 2; newCapacity |= newCapacity >>> 4; newCapacity |= newCapacity >>> 8; newCapacity |= newCapacity >>> 16; newCapacity ++; Object[] newArray = Arrays.copyOf(oldArray, newCapacity); Arrays.fill(newArray, oldCapacity, newArray.length, UNSET); newArray[index] = value; indexedVariables = newArray; } public static void fill(Object[] a, int fromIndex, int toIndex, Object val) { rangeCheck(a.length, fromIndex, toIndex); for (int i = fromIndex; i < toIndex; i++) a[i] = val; }
关于新数组长度的代码,还是看个例子来看得明白 。
public class FastThreadLocalTest5 {
public static void main(String[] args) {
for(int i = 1;i <= 35 ;i ++){
System.out.println("i = " + i + ", newCapacity = " + (newCapacity(i)));
}
}
public static int newCapacity(int newCapacity) {
newCapacity |= newCapacity >>> 1;
newCapacity |= newCapacity >>> 2;
newCapacity |= newCapacity >>> 4;
newCapacity |= newCapacity >>> 8;
newCapacity |= newCapacity >>> 16;
newCapacity++;
return newCapacity;
}
}
假如index值从1~35之间,那么新生成数组的容量如下 。

看过HashMap源码的对上述扩容操作肯定不陌生,这么做的目的就是为了保证数组的长度一定是2的倍数。 那expandIndexedVariableTableAndSet()接下来的步骤就简单多了, 将旧数组复制到新数组,初始化新数组未填充的槽位为InternalThreadLocalMap.UNSET, 再调用newArray[index] = value,将值保存到新数组中,接着indexedVariables 指向新数组。都很简单,这里就不深入了。 当然值设置好后,调用addToVariablesToRemove()方法,将当前FastThreadLocal变量记录到 Set<FastThreadLocal<?>>中,看其代码实现。
private static void addToVariablesToRemove(InternalThreadLocalMap threadLocalMap, FastThreadLocal<?> variable) { Object v = threadLocalMap.indexedVariable(variablesToRemoveIndex); Set<FastThreadLocal<?>> variablesToRemove; if (v == InternalThreadLocalMap.UNSET || v == null) { variablesToRemove = Collections.newSetFromMap(new IdentityHashMap<FastThreadLocal<?>, Boolean>()); threadLocalMap.setIndexedVariable(variablesToRemoveIndex, variablesToRemove); } else { variablesToRemove = (Set<FastThreadLocal<?>>) v; } variablesToRemove.add(variable); }
当然啦,如果没有初始化Set<FastThreadLocal<?>> ,则会调用Collections.newSetFromMap(new IdentityHashMap<FastThreadLocal<?>, Boolean>());初始化variablesToRemove,并将初始化好的值设置到threadLocalMap的indexedVariables[variablesToRemoveIndex]位置,如果已经存储,则直接调用add()方法,将FastThreadLocal记录到variablesToRemove即可。为什么用IdentityHashMap,而不用HashMap,IdentityHashMap有哪些特性呢?
IdentityHashMap特性。
- IdentityHashMap中的 key 允许重复
- IdentityHashMap使用的是 == 比较 key 的值(比较内存地址),而 HashMap 使用的是 equals()(比较存储值)
- IdentityHashMap使用的是 System.identityHashCode(object) 查找位置,HashMap 使用的是 hashCode() 查找位置
- IdentityHashMap理论上来说速度要比 HashMap 快一点
我猜使用IdentityHashMap也是Netty追求性能的极致体验吧。
还有一个比较好奇的是newSetFromMap内部做了哪些事情呢?
public static <E> Set<E> newSetFromMap(Map<E, Boolean> map) {
return new SetFromMap<>(map);
}
就创建了一个SetFromMap对象,什么都没有做,那SetFromMap的类结构是什么呢?
private static class SetFromMap<E> extends AbstractSet<E>
implements Set<E>, Serializable
{
private final Map<E, Boolean> m; // The backing map
private transient Set<E> s; // Its keySet
SetFromMap(Map<E, Boolean> map) {
if (!map.isEmpty())
throw new IllegalArgumentException("Map is non-empty");
m = map;
s = map.keySet();
}
public void clear() { m.clear(); }
public int size() { return m.size(); }
public boolean isEmpty() { return m.isEmpty(); }
public boolean contains(Object o) { return m.containsKey(o); }
public boolean remove(Object o) { return m.remove(o) != null; }
public boolean add(E e) { return m.put(e, Boolean.TRUE) == null; }
public Iterator<E> iterator() { return s.iterator(); }
public Object[] toArray() { return s.toArray(); }
public <T> T[] toArray(T[] a) { return s.toArray(a); }
public String toString() { return s.toString(); }
public int hashCode() { return s.hashCode(); }
public boolean equals(Object o) { return o == this || s.equals(o); }
public boolean containsAll(Collection<?> c) {return s.containsAll(c);}
public boolean removeAll(Collection<?> c) {return s.removeAll(c);}
public boolean retainAll(Collection<?> c) {return s.retainAll(c);}
// addAll is the only inherited implementation
// Override default methods in Collection
@Override
public void forEach(Consumer<? super E> action) {
s.forEach(action);
}
@Override
public boolean removeIf(Predicate<? super E> filter) {
return s.removeIf(filter);
}
@Override
public Spliterator<E> spliterator() {return s.spliterator();}
@Override
public Stream<E> stream() {return s.stream();}
@Override
public Stream<E> parallelStream() {return s.parallelStream();}
private static final long serialVersionUID = 2454657854757543876L;
private void readObject(java.io.ObjectInputStream stream)
throws IOException, ClassNotFoundException
{
stream.defaultReadObject();
s = m.keySet();
}
}
构造SetFromMap对象时,m 为传入的new IdentityHashMap<FastThreadLocal<?>, Boolean>(),而s 则是m key 的集合,而记录FastThreadLocal就是将FastThreadLocal作为key 添加到m中,而值用Boolean类型,我猜是为了节省存储空间吧。 先放到这里,以后用到时再来分析SetFromMap结构。 当然啦,在set()方法中有另外一种情况,如果设置的值是InternalThreadLocalMap.UNSET,相当于调用remove()方法,接下来看remove()方法的实现。
public final void remove() { remove(InternalThreadLocalMap.getIfSet()); } public final void remove(InternalThreadLocalMap threadLocalMap) { if (threadLocalMap == null) { return; } Object v = threadLocalMap.removeIndexedVariable(index); removeFromVariablesToRemove(threadLocalMap, this); if (v != InternalThreadLocalMap.UNSET) { try { onRemoval((V) v); } catch (Exception e) { PlatformDependent.throwException(e); } } } protected void onRemoval(@SuppressWarnings("UnusedParameters") V value) throws Exception { }
和set()方法原理一样,先将当前FastThreadLocal从threadLocalMap移除掉,再将当前FastThreadLocal从Set<FastThreadLocal<?>> 记录中移除掉。 当然啦,onRemoval()方法提供给子类实现。 先来看removeIndexedVariable()方法的实现。
public Object removeIndexedVariable(int index) { Object[] lookup = indexedVariables; if (index < lookup.length) { Object v = lookup[index]; lookup[index] = UNSET; return v; } else { return UNSET; } }
当然removeIndexedVariable()方法和setIndexedVariable()功能一样,直接设置indexedVariables[index]的值为UNSET即可。 接下来看removeFromVariablesToRemove()方法。
private static void removeFromVariablesToRemove( InternalThreadLocalMap threadLocalMap, FastThreadLocal<?> variable) { Object v = threadLocalMap.indexedVariable(variablesToRemoveIndex); if (v == InternalThreadLocalMap.UNSET || v == null) { return; } @SuppressWarnings("unchecked") Set<FastThreadLocal<?>> variablesToRemove = (Set<FastThreadLocal<?>>) v; variablesToRemove.remove(variable); }
当然,removeFromVariablesToRemove()方法的原理也很简单,从indexedVariables中取出索引位置为variablesToRemoveIndex的值,如果存在,则调用其remove()方法。当然,remove() 方法和add()方法相对应,直接将 FastThreadLocal 从IdentityHashMap移除即可,是不是很简单,理论上比ThreadLocal的源码简单多了。
接下来看FastThreadLocal的get()方法 。
public final V get(InternalThreadLocalMap threadLocalMap) {
Object v = threadLocalMap.indexedVariable(index);
if (v != InternalThreadLocalMap.UNSET) {
return (V) v;
}
return initialize(threadLocalMap);
}
public Object indexedVariable(int index) {
Object[] lookup = indexedVariables;
return index < lookup.length? lookup[index] : UNSET;
}
private V initialize(InternalThreadLocalMap threadLocalMap) {
V v = null;
try {
v = initialValue();
} catch (Exception e) {
PlatformDependent.throwException(e);
}
threadLocalMap.setIndexedVariable(index, v);
addToVariablesToRemove(threadLocalMap, this);
return v;
}
protected V initialValue() throws Exception {
return null;
}
其实上面代码看是去一大堆,实现原理还是很简单的,在整个Java程序运行过程中每一个FastThreadLocal对应一个index,因此只需要根据当前index到indexedVariables数组中查找值即可,但有一点需要注意,如果FastThreadLocal之前没有set()保存过值,此时调用get()方法,会触发initialize(threadLocalMap)方法的调用,这做做的用意是什么呢?再来看一个例子。
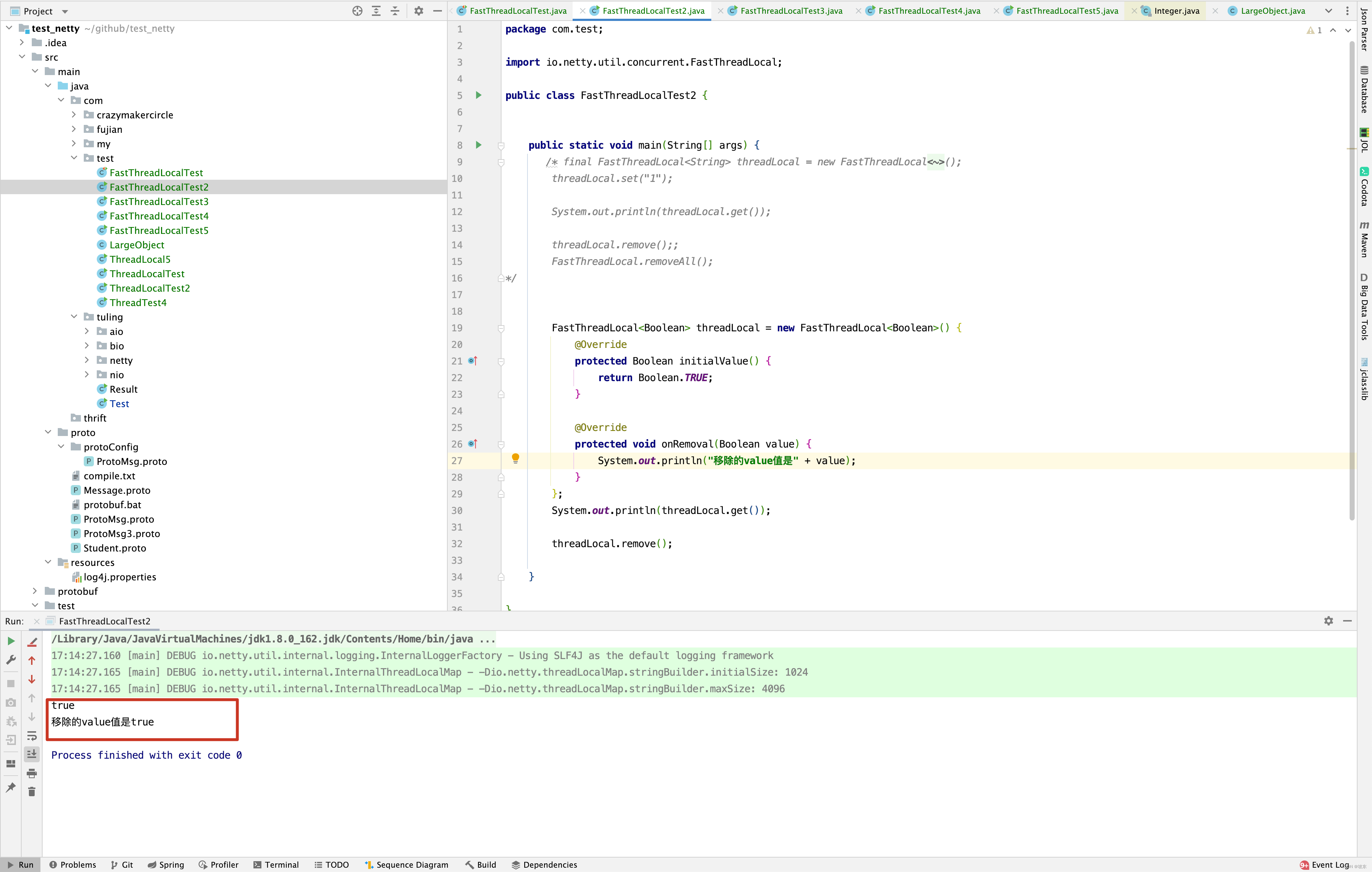
当调用get()方法时,如果此时FastThreadLocal并没有调用set()方法设置值,此时会触发initialValue()方法调用,默认的initialValue()方法返回null,如果FastThreadLocal重写了initialValue()方法,则返回重写initialValue()之后的方法返回值,并且将该值保存到indexedVariables[index]中,同时将当前FastThreadLocal记录到线程的Set<FastThreadLocal<?>> variablesToRemove 属性中。 remove()方法之前分析过了,现在只需要看removeAll()方法的实现。
public static void removeAll() {
InternalThreadLocalMap threadLocalMap = InternalThreadLocalMap.getIfSet();
if (threadLocalMap == null) {
return;
}
try {
Object v = threadLocalMap.indexedVariable(variablesToRemoveIndex);
if (v != null && v != InternalThreadLocalMap.UNSET) {
@SuppressWarnings("unchecked")
Set<FastThreadLocal<?>> variablesToRemove = (Set<FastThreadLocal<?>>) v;
// 将set 集合转化为数组,可能是提升性能的体现吧
FastThreadLocal<?>[] variablesToRemoveArray =
variablesToRemove.toArray(new FastThreadLocal[0]);
for (FastThreadLocal<?> tlv: variablesToRemoveArray) {
// 调用FastThreadLocal的remove方法
tlv.remove(threadLocalMap);
}
}
} finally {
InternalThreadLocalMap.remove();
}
}
大家需要注意,removeAll()方法是一个静态方法,因此调用时,直接用FastThreadLocal.removeAll()调用即可。 当然之前也简单的分析了一下removeAll()方法,这里继续来分析 。 第一步,通过variablesToRemoveIndex找到记录当前线程所有FastThreadLocal的Set集合。 如果不为空且不为InternalThreadLocalMap.UNSET,则证明 Set<FastThreadLocal<?>> variablesToRemove之前设置过值,很大可能有FastThreadLocal需要被清理。接下来看InternalThreadLocalMap的remove()方法 。
public static void remove() {
Thread thread = Thread.currentThread();
if (thread instanceof FastThreadLocalThread) {
((FastThreadLocalThread) thread).setThreadLocalMap(null);
} else {
slowThreadLocalMap.remove();
}
}
直接将线程的threadLocalMap设置为空即可,当然还有一种情况就是当前线程不是FastThreadLocalThread时,那所有的操作都是ThreadLocal的操作,之前分析过ThreadLocal源码这里就不深入分析了,关于FastThreadLocal的源码就分析到这里了。
总结
关于ThreadLocal ,FastThreadLocal和的源码就分析到这里了,他们谁更好呢?
- 从源码的角度上来看,你会发现ThreadLocal的源码要难得多,各种情况都考虑得比较全面,FastThreadLocal相对而言更加简单。
- 从性能上来看,FastThreadLocal的性能绝对的快,只需要从数组直接取出当前FastThreadLocal 对应的值即可,在使用static 情况下ThreadLocal的性能和FastThreadLocal一样,但如果在方法中大量使用本地ThreadLocal ,可能在插入和查找过程中,需要从索引处不断的向后查找,最坏情况可能需要查找(table.length * 2 / 3 )次,为什么是这个值呢?因为当table数组的元素个数大于等于这个值时,就可能触发扩容,对于 get()方法而言,在查找过程中,只需要查找到table[i] 为空时,如果还没有查找到ThreadLocal对应的Entry,就不再进行查找,对于set()方法而方,如果查找到table[i]为空时,就可以将当前ThreadLocal 设置到table[i]中,当然在插入,移除,和查找过程中,会触发table重置ThreadLocal的位置,也会带来性能损失,但空间利用率上,ThreadLocal显然比FastThreadLocal高得多,ThreadLocal在插入,移除,和查找过程中都会去移除被JVM回收的ThreadLocal及其值,table数组不会存在太多的内存浪费,但FastThreadLocal中完全是以空间换时间的方式,如果0~10000的index被其他FastThreadLocal用过,此时新使用的FastThreadLocal的数组长度就需要大于10000的长度,而之前所被其他FastThreadLocal使用过的槽位都只能指向一个InternalThreadLocalMap.UNSET ,一个空对象的引用,即使一个引用占4b ,那么 10000 * 4b = 40kb 的内存空间,当然啦,实际情况并不仅仅浪费那么多。如果前面10000个index都被其他FastThreadLocal,当前线程需要创建一个16384长度的数组来存储FastThreadLocal的value值,但实际情况真创建那么多吗?也不好说,因此FastThreadLocal相对于ThreadLocal是比较浪费空间的。
- 在使用上ThreadLocal肯定比FastThreadLocal使用简单,因为ThreadLocal即使没有手动remove(),系统也会帮你回收内存空间,但FastThreadLocal如果没有手动remove(),就可能出现内存泄漏了 。
因此综合上述,对于自己开发的框架,并且对内存占用不是很严苛场景,使用FastThreadLocal当然是好的,这样能极大的提升性能,将ThreadLocal可能导致的性能问题完全屏蔽掉,对于一个高并发程序来说是值得的,只要自己代码写得没有bug即可。 但对于开源让大家都来使用代码,还是建议使用ThreadLocal,因为ThreadLocal底层帮我们默默的做了很多优化的地方,同时使用起来也更加简单,很多程序员忘记调用ThreadLocal的remove()方法,也不会带来什么问题,如果使用FastThreadLocal来供所有开发人员使用的话,肯定会带来很多不必要的麻烦,因此ThreadLocal 更像放之四海而皆准的东西,而FastThreadLocal更像vip ,需要有一定素养,对FastThreadLocal底层比较了解的程序员才能使用。因此说谁好,谁不好,还是看具体的应用场景吧。
关于FastThreadLocal的使用,在后面具体的Netty 源码再来分析















 1021
1021











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









