






文章目录
词法分析+语法分析理论算法实现
完整代码分享见底部
一、正规式转NFA
1.1 思路
如何构造NFA?需要使用MYT算法,构造状态。
MYT算法要求的输入是什么?是后缀表达式,便于处理。
初始输入一般是中缀表达式,要先转成后缀表达式。
什么是中缀表达式?例如 a+b*c 对应的后缀表达式是 abc*+
从原先的有优先级,就变成了无优先级,只需要压栈,遇到操作符号弹出两个操作数即可。
以上说的是标准的数学运算,±*\
对于正则表达式实际上要处理的符号是()*|
还有一个隐藏的符号,即连接符,例如ab代表a后边跟着b,可使用a.b 进行显式表示,便于后续的转后缀和转NFA的处理。
1.2 正规式检验
确保输入的正则表达式合规,进行正则表达式的检验
要求:
- 由a-z和A-Z的字母构成
- 左右括号要匹配
- 操作符为|,*
1.3 中缀转后缀
1.3.1 隐式连接符添加
若当前字符为操作数或左括号,且前一个字符为操作数或右括号或*,则插入连接运算符.
(a|b)*abb —>(a|b)*.a.b.b
1.3.2 整体转后缀(逆波兰式)
在这里的*与乘法的*不同,乘法*是双目运算法,意味着前一个数乘以后一个数,
但是这里的*是对前面一个数整体的进行闭包运算,是单目运算符。
故在处理的时候需要对弹幕运算符进行单独考虑,而对于双目运算符|,正常压栈即可。
处理过程如下,(优先级从低到高为:|,显示连接符.,闭包运算*,)
- 若是操作数,输出。
- 若是(,压入栈。
- 若是),将栈顶元素依次输出,直至(。
- 若是双目运算符|或者.,将栈顶元素依次弹出输出,直至哪个栈顶元素的优先级小于该运算符。然后将该运算符压入。(若不存在比该运算符优先级高的运算,则直接压入栈即可)
- 若是弹幕运算符*,与操作数相同,压入栈。
- 输出完后,将栈顶元素依次弹出。
(a|b)*.a.b.b —> ab|*a.b.b.
1.4 后缀转NFA
在获得后缀表达式之后,对其字符串进行遍历,并作如下操作:
- 如遇到字符(‘a’-‘z’|‘A’-‘Z’),则按照Thompson算法初始化一个NFA节点,将节点压入栈中。其次,检查转换字符集中是否有当前字符,若没有则加入。
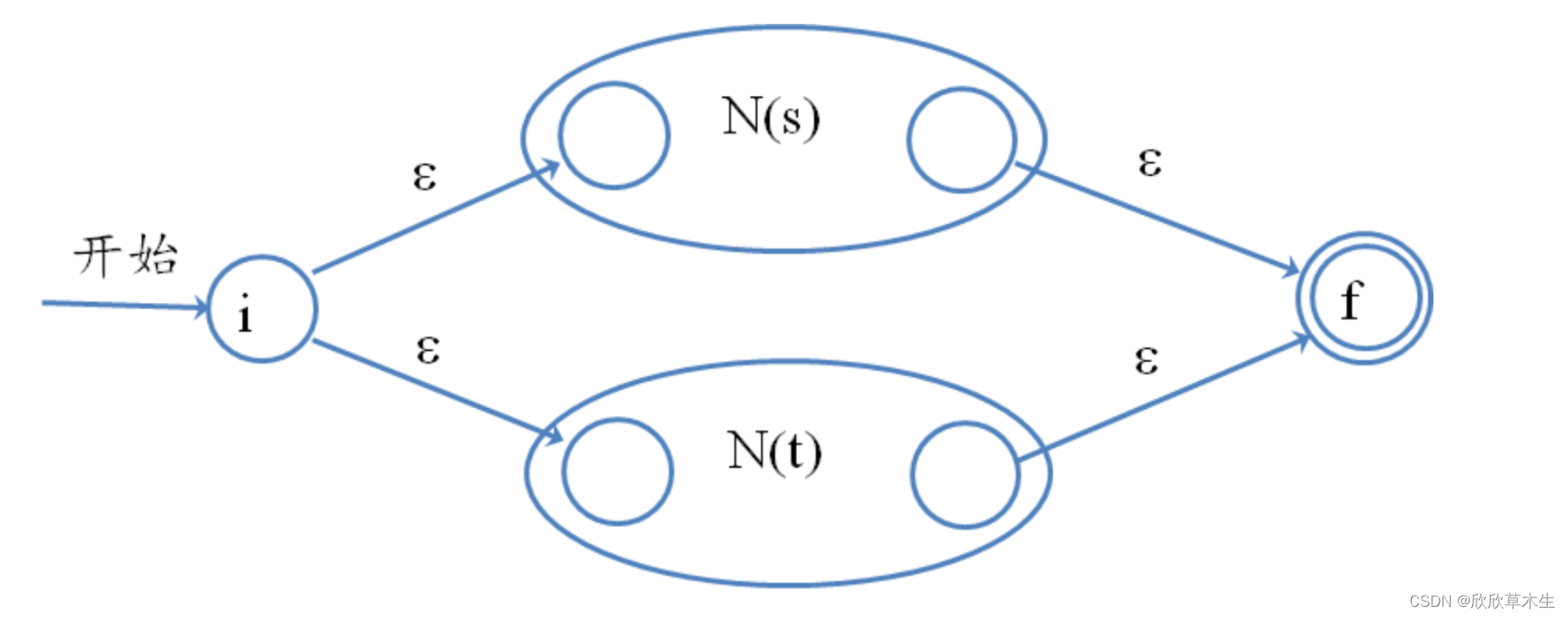
- 如遇到双目运算符|或者.,则从栈中弹出2个nfa,并按照Thompson算法进行修改,将修改结果压入栈中。
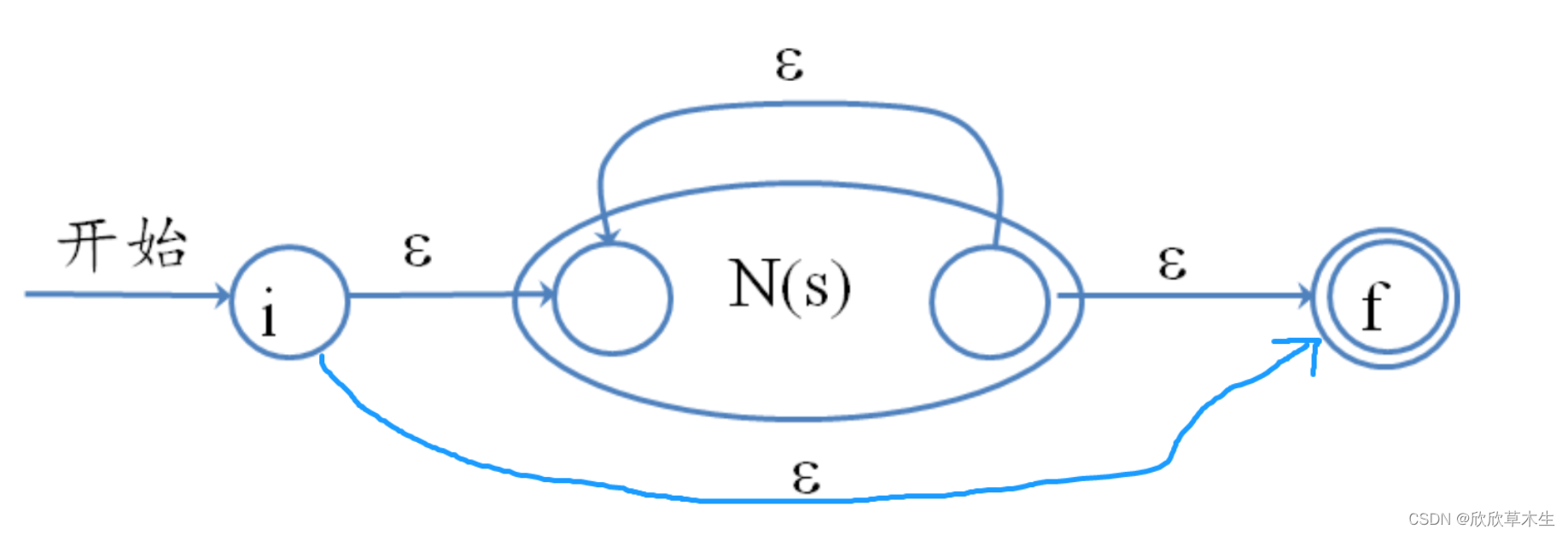
- 如遇到双目运算符*,则从栈中弹出1个nfa,并按照Thompson算法进行修改,将修改结果压入栈中。
- 重复1、2、3,直到遍历结束。
单字符:
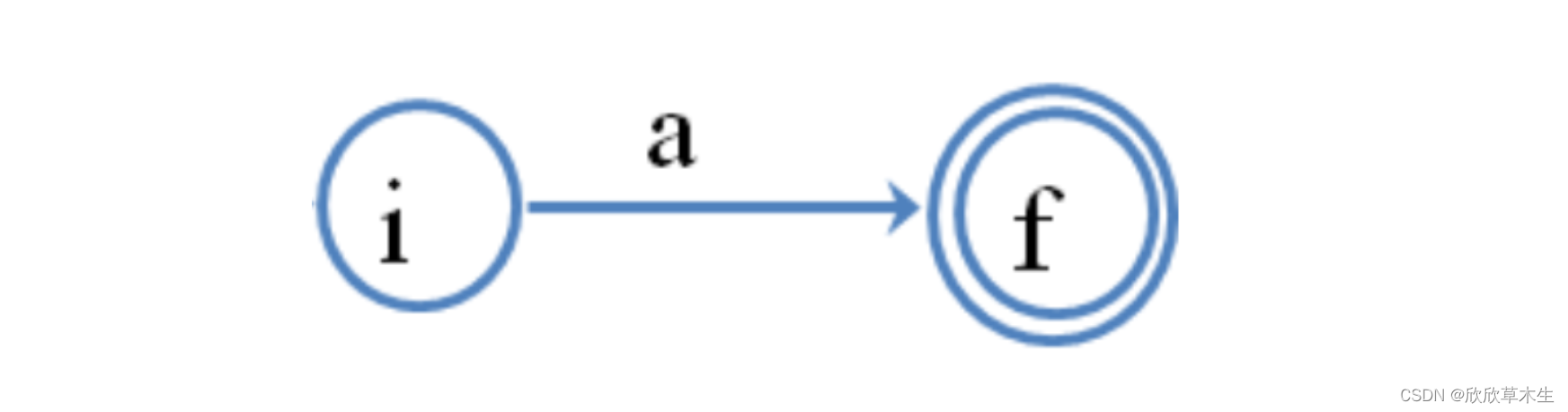
|运算:
*运算:
1.5 可运行代码
def infix_to_postfix(expression):
precedence = {'|': 1,'.':2,'*':3,"+":3,"?":3}
digits = {'0','1','2','3','4','5','6','7','8','9'}
chars = [chr(i) for i in range(65,91)]
chars1 = [chr(i) for i in range(97,123)]
chars.extend(chars1)
chars.extend('*')
output_stack = []
operator_stack = []
for token in expression:
# print(token)
# print('---')
if token in digits or token in chars: # 假设操作数为单个数字
output_stack.append(token)
elif token == '(':
operator_stack.append(token)
elif token == ')':
while operator_stack and operator_stack[-1] != '(':
# print(operator_stack[-1])
output_stack.append(operator_stack.pop())
operator_stack.pop() # 弹出 '('
else: # 运算符
while operator_stack and operator_stack[-1] != '(' and \
precedence[operator_stack[-1]] >= precedence[token]:
# print(operator_stack[-1])
output_stack.append(operator_stack.pop())
operator_stack.append(token)
while operator_stack:
# print(operator_stack[-1])
output_stack.append(operator_stack.pop())
return ''.join(output_stack)
# 增加隐式连接字符.
# 若当前字符为操作数或左括号,且前一个字符为操作数或右括号或*,则插入连接运算符.
def add_implicit_concatenation_operator(regex):
output = ""
chars = [chr(i) for i in range(65,91)]
chars1 = [chr(i) for i in range(97,123)]
chars.extend(chars1)
operate_num = set(chars)
for i, char in enumerate(regex):
if i > 0 and (char in operate_num or char in '(') and (regex[i - 1] in operate_num or regex[i - 1] in ')*'):
output += '.' # 插入连接运算符
output += char
return output
# 示例
regex = "a(b|c)*d"
regex = "(a|b)*abb"
# regex = "ab*|ab"
output1 = (add_implicit_concatenation_operator(regex))
print(output1)
output2 = infix_to_postfix(list(add_implicit_concatenation_operator(regex)))
print(output2)
# 打印栈便于调试
def print_stack(stack):
for nfa in stack:
for (start, symbol), ends in nfa.transitions.items():
for end in ends:
print(f" {start} --{symbol}--> {end}")
class NFA:
# 状态集、字母表、初始状态、结束状态、映射
def __init__(self):
self.states = set()
self.alphabet = set()
self.transitions = {} # 字典,键为 (state, symbol),值为状态集合
self.start_state = None
self.accept_states = set()
def add_transition(self, start, symbol, end):
# 若不在则添加该集合
if (start, symbol) not in self.transitions:
self.transitions[(start, symbol)] = set()
self.transitions[(start, symbol)].add(end)
# 复制添加
def add_nfa1_to_nfa(nfa,nfa1):
nfa.alphabet.update(nfa1.alphabet)
nfa.states.update(nfa1.states)
for (start1, symbol1), ends1 in nfa1.transitions.items():
for end1 in ends1:
nfa.add_transition(start1, symbol1, end1)
return nfa
def regex_to_nfa(pattern):
now_num = 0
stack = []
# 初始化一个空栈,用于存储处理正则表达式过程中的中间 NFA。
# 遍历字符
for char in pattern:
if char == '*':
# print("*")
# 闭包操作
nfa1 = stack.pop()
start = now_num
end = start + 1
now_num+=2
nfa = NFA()
nfa = add_nfa1_to_nfa(nfa,nfa1)
nfa.states.update({start, end})
for s in nfa1.accept_states:
nfa.add_transition(s, '', end)
nfa.add_transition(s, '', nfa1.start_state)
nfa.add_transition(start, '', end)
nfa.add_transition(start, '', nfa1.start_state)
nfa.start_state = start
nfa.accept_states = {end}
stack.append(nfa)
elif char == '|':
# print("|")
# 选择操作
# print("lenstack")
# print(len(stack))
nfa2 = stack.pop()
# print(nfa2.start_state)
# print(len(stack))
nfa1 = stack.pop()
# print(nfa1.start_state)
start = now_num
end = start + 1
now_num+=2
nfa = NFA()
nfa = add_nfa1_to_nfa(nfa,nfa1)
nfa = add_nfa1_to_nfa(nfa,nfa2)
# nfa.alphabet.update(nfa1.alphabet)
# nfa.alphabet.update(nfa2.alphabet)
# nfa.states.update(nfa1.states)
# nfa.states.update(nfa2.states)
nfa.states.update({start, end})
nfa.add_transition(start, '', nfa1.start_state)
nfa.add_transition(start, '', nfa2.start_state)
for s in nfa1.accept_states:
nfa.add_transition(s, '', end)
for s in nfa2.accept_states:
nfa.add_transition(s, '', end)
nfa.start_state = start
nfa.accept_states = {end}
stack.append(nfa)
# print_stack(stack)
# print_stack(stack)
elif char == '.':
# print(".")
# 连接操作
nfa2 = stack.pop()
nfa1 = stack.pop()
nfa = NFA()
nfa = add_nfa1_to_nfa(nfa,nfa1)
nfa = add_nfa1_to_nfa(nfa,nfa2)
nfa.states.update({start, end})
for (start1, symbol1), ends1 in nfa1.transitions.items():
for end1 in ends1:
# print(f" {start} --{symbol}--> {end}")
nfa.add_transition(start1, symbol1, end1)
for (start1, symbol1), ends1 in nfa2.transitions.items():
for end1 in ends1:
nfa.add_transition(start1, symbol1, end1)
for s in nfa1.accept_states:
nfa.add_transition(s, '', nfa2.start_state)
nfa.start_state = nfa1.start_state
nfa.accept_states = nfa2.accept_states
stack.append(nfa)
print('.后的zhan')
print_stack(stack)
else:
# print('base char')
# 基础字符
start = now_num
end = start + 1
now_num+=2
nfa1 = NFA()
nfa1.alphabet.add(char)
nfa1.states.update({start, end})
nfa1.add_transition(start, char, end)
nfa1.start_state = start
nfa1.accept_states = {end}
stack.append(nfa1)
# print("现在加入的nfa")
# print(nfa.start_state)
print("dangqian char")
print_stack(stack)
# print(now_num)
# print_stack(stack)
print(len(stack))
return stack[0]
regex = "(a|b)*abb"
# regex = "b*"
# regex = "abb"
postfix = infix_to_postfix(list(add_implicit_concatenation_operator(regex)))
print(postfix)
nfa = regex_to_nfa(postfix)
def print_nfa(nfa):
print("States:", nfa.states)
print("Alphabet:", nfa.alphabet)
print("Transitions:")
for (start, symbol), ends in nfa.transitions.items():
for end in ends:
print(f" {start} --{symbol}--> {end}")
print("Start state:", nfa.start_state)
print("Accept states:", nfa.accept_states)
print_nfa(nfa)
def visual_nfa(nfa):
import graphviz
from graphviz import Digraph
dot = Digraph(comment='The Round Table')
dot.attr(rankdir='LR', size='8,5')
dot.attr('node', shape='doublecircle')
for i in nfa.accept_states:
dot.node(str(i))
dot.attr('node', shape='circle')
for (start, symbol), ends in nfa.transitions.items():
for end in ends:
dot.edge(str(start), str(end), label=symbol)
# dot.view()
# dot.render('nfa_graph', format='png', cleanup=True)
return dot
visual_nfa(nfa)
print_nfa(nfa)
二、NFA转DFA
2.1 两个算法核心介绍
运算1 epsilon_closure:计算state可以通过空边到达的集合state_epsilon
运算2 move:计算state通过某字符symbol可以到达的下一状态next_state
2.2 初始操作
找出初始状态,对该状态进行epsilon_closure运算,得出initial_closure
将initial_closure压入队列
2.3 循环
重复以下:
-
弹出队列头元素current_dfa_state
-
遍历字符集
2.1 计算epsilon_closure的通过该字符的下一状态next_state
2.2 计算next_state的epsilon_closure,若该epsilon_closure不在状态列表中出现过,则将其压入队列尾部。如果出现过则不压入。
直至队列为空
2.4 可运行代码
class DFA:
def __init__(self):
self.states = set()
self.alphabet = set()
self.transitions = {} # Dictionary with (state, symbol) as key and a single state as value
self.start_state = None
self.accept_states = set()
def add_state(self, state):
self.states.add(state)
def add_transition(self, start, symbol, end):
self.transitions[(start, symbol)] = end
def add_accept_state(self, state):
self.accept_states.add(state)
def epsilon_closure(nfa, states):
closure = set(states)
for state in states:
for end in nfa.transitions.get((state, ''), set()):
if end not in closure:
closure |= epsilon_closure(nfa, [end])
return closure
def move(nfa, states, symbol):
next_states = set()
for state in states:
next_states |= nfa.transitions.get((state, symbol), set())
return next_states
def convert_nfa_to_dfa(nfa):
dfa = DFA()
dfa.alphabet = nfa.alphabet - {''}
initial_closure = epsilon_closure(nfa, [nfa.start_state])
# print('initial_closure')
# print(initial_closure)
dfa.add_state(frozenset(initial_closure))
dfa.start_state = frozenset(initial_closure)
unmarked_states = [dfa.start_state]
# 弹出队列首元素 直至队列空
while unmarked_states:
current_dfa_state = unmarked_states.pop(0)
for symbol in dfa.alphabet:
next_closure = epsilon_closure(nfa, move(nfa, current_dfa_state, symbol))
dfa_state = frozenset(next_closure)
if dfa_state not in dfa.states:
dfa.add_state(dfa_state)
unmarked_states.append(dfa_state)
dfa.add_transition(current_dfa_state, symbol, dfa_state)
# 修改接受状态
for state in dfa.states:
if any(sub_state in nfa.accept_states for sub_state in state):
dfa.add_accept_state(state)
return dfa
def print_dfa(dfa:DFA()):
print("States:", dfa.states)
print("Alphabet:", dfa.alphabet)
print("Transitions:")
for (start, symbol), ends in dfa.transitions.items():
print(f" {start} --{symbol}--> {ends}")
print("Start state:", dfa.start_state)
print("Accept states:", dfa.accept_states)
dfa = convert_nfa_to_dfa(nfa)
print_dfa(dfa)
三、检验字符串匹配DFA
3.1 分析
如果要检验字符串str是否符合该DFA,只需遍历字符串,按照字符进行状态转移(DFA中)。
若当前状态没有该字符的next_state,错误。
遍历完字符后的状态处在接受状态中,return true。
def is_accepted_by_dfa(dfa, string):
current_state = dfa.start_state
for symbol in string:
current_state = dfa.transitions.get((current_state, symbol))
if current_state is None:
return False # 没有有效的转换
return current_state in dfa.accept_states
3.2 可运行代码
def is_accepted_by_dfa(dfa, string):
current_state = dfa.start_state
for symbol in string:
# if symbol not in dfa.alphabet:
# return False # 字符不在 DFA 的字母表中
current_state = dfa.transitions.get((current_state, symbol))
if current_state is None:
return False # 没有有效的转换
return current_state in dfa.accept_states
result = is_accepted_by_dfa(dfa, "aaabb")
print("String accepted by DFA" if result else "String not accepted by DFA")
result = is_accepted_by_dfa(dfa, "aaab")
print("String accepted by DFA" if result else "String not accepted by DFA")
四、消除左递归
4.1 消除直接左递归
A->Aα|β
容易得到,该产生式是以β开头的,后边跟着若干个α(0个或者多个)的字符串。
A->βA’
A’->αA’|ε
对于 A → A α 1 ∣ A α 2 ∣ . . . ∣ A α m ∣ β 1 ∣ β 2 ∣ . . . ∣ β n \mathrm{A\to A\alpha_1|A\alpha_2|...|A\alpha_m|\beta_1|\beta_2|...|\beta_n} A→Aα1∣Aα2∣...∣Aαm∣β1∣β2∣...∣βn
可以转变成
A → ( B 1 ∣ β 2 ∣ … ∣ β n ) A ′ \mathrm{A\to(B_1|\beta_2|\ldots|\beta_n)A^{\prime}} A→(B1∣β2∣…∣βn)A′
$\mathsf{A’}{\operatorname*{\to}}(\mathfrak{\alpha}_1|\mathfrak{\alpha}_2|\ldots|\mathfrak{\alpha}_m)\text{A’}|\varepsilon $
4.2 消除间接左递归
-
按照某个顺序,将产生式排序为A1,A2,…,An(一般将开始符号放在最后,因为接下来的步骤是将排在上面的符号带入下面的产生式,将开始符号放在最后,最终的结果就是开始符号→…)
-
从上到下考察每一个产生式Ai(i∈[i,n]),将之前的非终结符号Aj(j∈[1,i-1])带入Ai(如果可以的话)。然后,可以得到Ai的一个产生式,如果存在直接左递归,则消除,否则,开始新的一轮循环,考察Ai+1。
-
消除多余产生式

4.3 可运行代码
def eliminate_left_recursion(rules):
new_rules = {}
for lhs, rhs_list in rules.items():
# 分离含左递归和不含左递归的产生式
direct_recursion = [rhs for rhs in rhs_list if rhs.startswith(lhs)]
non_recursion = [rhs for rhs in rhs_list if not rhs.startswith(lhs)]
if direct_recursion:
# 引入新的非终结符
new_lhs = lhs + "'"
new_rhs = [rhs[len(lhs):] + new_lhs for rhs in direct_recursion]
new_rhs.append('ε') # 添加空(epsilon)产生式
# 更新规则
new_rules[lhs] = [rhs + new_lhs for rhs in non_recursion]
new_rules[new_lhs] = new_rhs
else:
new_rules[lhs] = rhs_list
return new_rules
# 示例文法
grammar = {
"A": ["Aa","Ab","c", "v"]
}
# 消除左递归
new_grammar = eliminate_left_recursion(grammar)
# print(new_grammar)
def print_rules(rules):
for lhs, rhs_list in rules.items():
print(lhs+"->",end='')
print(('|').join(rhs_list))
print_rules(new_grammar)
def eliminate_indirect_left_recursion(rules):
non_terminals = list(rules.keys())
# 对非终结符进行排序
for i in range(len(non_terminals)):
for j in range(i):
# 替换产生式
Ai = non_terminals[i]
Aj = non_terminals[j]
new_productions = []
for production in rules[Ai]:
if production.startswith(Aj):
# 替换 Aj 为 Aj 的产生式
for Aj_prod in rules[Aj]:
new_productions.append(Aj_prod + production[1:])
else:
new_productions.append(production)
rules[Ai] = new_productions
# 消除直接左递归
rules = eliminate_direct_left_recursion(rules, non_terminals[i])
return rules
def eliminate_direct_left_recursion(rules, non_terminal):
rhs_list = rules[non_terminal]
direct_recursion = [rhs for rhs in rhs_list if rhs.startswith(non_terminal)]
non_recursion = [rhs for rhs in rhs_list if not rhs.startswith(non_terminal)]
if direct_recursion:
new_lhs = non_terminal + "'"
new_rhs = [rhs[len(non_terminal):] + new_lhs for rhs in direct_recursion]
new_rhs.append('ε') # 添加空(epsilon)产生式
rules[non_terminal] = [rhs + new_lhs for rhs in non_recursion]
rules[new_lhs] = new_rhs
return rules
# 示例文法
grammar = {
"A": ["Ba", "c"],
"B": ["Ca", "b"],
"C": ["Aa", "a"]
}
# 消除间接左递归
new_grammar = eliminate_indirect_left_recursion(grammar)
# print(new_grammar)
print_rules(new_grammar)
五、提取左公共因子
5.1 理论分析
并不如网上说的很简单,涉及到递归调用
理论上处理前:

理论上处理后:

但是编码实现中,遇到的却是:
A->bbba|bba|bb|b|a|aa|aac|d
可能存在多个公共因子,因此,笔者的做法是,每次只处理一个因子。比如在这里,先处理b。
生成两条规则
A->bZ|a|aa|aac|d
Z->bba|ba|b|ε
再对每条规则进行公共因子的判断和处理。
5.2 伪代码
# 伪代码
# 计算由一条规则产生的新规则
def one_rule_extract_left_common_factor_resursion(rule):
if no common_char:
return rule
new_rules = {}
rule1 = {lhs:[common_char + new_char if(demo[0]==prefix) else demo for demo in rhs_list]}
rule2 = {new_char:[demo[1:] if(len(demo[1:])>=1) else 'ε' for demo in rhss]}
new_rule1_recursion=one_rule_extract_left_common_factor_resursion(new_rule1)
new_rule2_recursion=one_rule_extract_left_common_factor_resursion(new_rule2)
new_rules = merge(new_rules,rule1,rule2,new_rule1_recursion,new_rule2_recursion)
return new_rules
# 计算由多条规则产生的新规则
def rules_extract_left_common_factor_resursion(rules):
new_rules = {}
for rule in rules:
new_rules = merge(new_rules,one_rule_extract_left_common_factor_resursion(rule))
return new_rules
5.3 可运行代码
# 判断一个rule是否有公共因子
def one_rule_if_have_common_prefix(rule):
# 其实就一个rule
for lhs, rhss in rule.items():
prefix_map = {}
# prefix_map是一个字典 key是首字符 values是以key为首字符的rhs构成的列表
for rhs in rhss:
if rhs!='': # 确保产生式不为空
first_symbol = list(rhs)[0]
prefix_map.setdefault(first_symbol, []).append(rhs)
if len(prefix_map[first_symbol])>1:
return True
return False
rule = {
"B": ["b","a","d",'f','aa']
}
print(one_rule_if_have_common_prefix(rule))
import copy
NEW_CHARS_ORIGINAL = [chr(i) for i in range(90,64,-1)]
NEW_CHARS = copy.deepcopy(NEW_CHARS_ORIGINAL)
# 思路?递归调用 将一条规则转化成多条规则
# new_rules = {}
# 一条规则提取后转成两条规则
# 将两条规则加入new_rules
# 将两条规则的递归后的规则加入new_rules
# 终止条件:不存在公共prefix
def one_rule_extract_left_common_factor_resursion(rule):
global NEW_CHARS
if not one_rule_if_have_common_prefix(rule):
return rule
new_rules = {}
# 分析这句产生式的首字符对应的rhs们
for lhs, rhs_list in rule.items():
prefix_map = {}
for rhs in rhs_list:
if rhs!='': # 确保产生式不为空
first_symbol = list(rhs)[0]
prefix_map.setdefault(first_symbol, []).append(rhs)
# 一定存在多于一个的以相同符号开头的产生式 所以遇到了直接break就行
for prefix, rhss in prefix_map.items():
if len(rhss) > 1:
# print(NEW_CHARS)
# "b": ["bbba", "bba", "bb"]
# 两条新规则
lhs1 =lhs
lhs2 = NEW_CHARS[0]
# 取出字符后要后移一个
NEW_CHARS = NEW_CHARS[1:]
rhss1 = [prefix+lhs2 if(demo[0]==prefix) else demo for demo in rhs_list]
rhss1 = list(set(rhss1))
rhss2 = [demo[1:] if(len(demo[1:])>=1) else 'ε' for demo in rhss]
new_rule1 = {lhs1:rhss1}
new_rule2 = {lhs2:rhss2}
new_rule1_recursion=one_rule_extract_left_common_factor_resursion(new_rule1)
new_rule2_recursion=one_rule_extract_left_common_factor_resursion(new_rule2)
new_rules = {**new_rules,**new_rule1,**new_rule2,**new_rule1_recursion,**new_rule2_recursion}
break
return new_rules
def rules_extract_left_common_factor_resursion(rules):
new_rules = {}
for lhs, rhs_list in rules.items():
new_rules = {**new_rules,**one_rule_extract_left_common_factor_resursion({lhs:rhs_list})}
return new_rules
# 示例文法
rules = {
"A": ["bbba", "bba", "bb",'b','a','aa','ccc','ca','ac','h'],
"B": ["bbba", "bba", "bb",'ε']
}
# 提取左公共因子
new_rules = rules_extract_left_common_factor_resursion(rules)
# print_rules(new_rules)
new_rules
六、first集
6.1 抽象算法内容
(下边需要自己做了才能理解)
不断应用下列规则,直到没有新的终结符或&可以被加入到任何FIRST集合中为止
- 如果X是一个终结符,那么FIRST(X)={X}
- 如果X是一个非终结符,且 X->Y1…Yk(k>=1),那么如果对于某个i,a在FIRST(Yi) 中且ε在所有的FIRST(Y1),…,FIRST(Yi-1)中(即Y1…Yi-1->ε),就把a加入到FIRST(X)中。如果对于所有的 j= 1,2,…,k,ε在FIRST(Yj)中,那么将ε加入到FIRST(X)
- 如果X->ε,那么将加入到FIRST(X)中
6.2 实际算法实现
定义一个函数first_of_lhs(lhs),用于实现计算单个符号symbol的FIRST集
-
如果symbol是终结符,则return symbol(终结符的First集是自身)
-
如果symbol是非终结符,需要根据以symbol为开头的产生式来计算symbol的First集。
以E->TG为例
遍历TG,记录遍历到的字符为X
2.1 result = merge (first_of_lhs(X) - {‘ε’})
2.2 如果first_of_lhs(X)不含有’ε’,则退出循环,否则继续遍历
2.3 如果遍历了所有的字符(意味着所有字符的First集都有’ε’),则将’ε’添加到result集中
对于所有的非终结符反复调用1,2,直至first集不发生变化,停止。
6.3 可运行代码
# 可运行代码
# 输入 rules 输出 firsts
def compute_first_sets(rules):
first = {lhs: set() for lhs in rules}
# 计算单个符号的FIRST集 递归调用
def first_of_lhs(lhs):
if lhs not in rules: # 如果是终结符
return {lhs}
result = set()
for rhss in rules[lhs]:
for rhs in rhss:
lhs_first = first_of_lhs(rhs)
result |= (lhs_first - {'ε'})
# 到第一个不含有epsilon的产生式就停止
if 'ε' not in lhs_first:
break
else:# 与第二个for循环匹配 当for循环内break未发生时候执行该操作
result.add('ε')
return result
flag = 1
while flag==1:
flag = 0
for non_terminal in rules:
# 对于每个非终结符计算FIRST集
length1 = len(first[non_terminal])
first[non_terminal] |= first_of_lhs(non_terminal)
length2 = len(first[non_terminal])
if length1 != length2:
flag = 1
return first
# 示例文法
grammar = {
"E": ["TG"],
"G": ["+TG", "ε"],
"T": ["FH"],
"H": ["*FH", "ε"],
"F": ["(E)", "a"]
}
first_sets = compute_first_sets(grammar)
first_sets
'''
输出如下
{'E': {'(', 'a'},
'G': {'+', 'ε'},
'T': {'(', 'a'},
'H': {'*', 'ε'},
'F': {'(', 'a'}}
'''
七、follow集
follow集需要调用first集
7.1 抽象算法内容
- 对于文法开始符号s,将# (作用: 结束标记) 加入FOLLOW(S)。
- 若有A→αBβ,则FIRST(β)-{ε}加入FOLLOW(B)。
- 若有A→αB, 或A→αBβ且ε ∈ FIRST(β),则将FOLLOW(A) 加入FOLLOW(B)中。
7.2 实际算法实现
初始化:首先对于文法开始符号S, 将#(作用:结束标记)加入FOLLOW(S)。
后续循环:对于每条产生式A->BCDef,遍历右侧字符,记录当前字符为X,X的后一个字符为Y,仅对X为非终结符时进行以下操作,若X为终结符则跳过
-
若X是最后一个字符,将follow(A)加到follow(X)
-
若X不是最后一个字符,遍历X后边的所有字符,记录遍历到的字符为Z
2.1 将(first(Z)- {ε})加到follow(X)(每次加入的都去除ε,因此FOLLOW集合中没有 ε)
2.2 若ε不在first(Z)中,则退出循环
直至:所有的follow集不发生变化,退出循环
7.3 可运行代码
def compute_follow_sets(rules):
first_sets = compute_first_sets(rules)
follow = {non_terminal: set() for non_terminal in rules}
start_symbol = next(iter(rules)) # 第一个非终结符是开始符号
follow[start_symbol].add('$')
# print(first_sets)
# 原先的first集计算只返回了非终结符的first集,在这里增加上终结符的first集(即本身)
for lhs,rhss in rules.items():
# print(lhs)
# print(rhss)
for rhs in rhss:
for symbol in rhs:
if symbol not in rules:
first_sets[symbol]=set()
first_sets[symbol].add(symbol)
# print(first_sets)
# 针对非终结符
# 把后边的First加到前边的Follow
# 看后边的所有字符的First是否有空 有空的话 把左边的follow加到右边的follow
flag = 1
while flag:
flag = 0
for lhs, rhss in rules.items():
for rhs in rhss:
# A->BaC
# lhs->rhs
length = len(rhs)
for i in range(length-1, -1, -1):
symbol = rhs[i]
if symbol in rules:
length1 = len(follow[symbol])
if(i==length-1):
follow[symbol]|=follow[lhs]
else:
follow[symbol]|=(first_sets[rhs[i+1]]-{'ε'})
for demo_first in rhs[i+1:]:
if 'ε' not in first_sets[demo_first]:
break
else:
follow[symbol]|=follow[lhs]
if len(follow[symbol]) != length1:
flag = 1
return follow
# 示例文法
rules = {
"E": ["TG"],
"G": ["+TG", "ε"],
"T": ["FH"],
"H": ["*FH", "ε"],
"F": ["(E)", "a"]
}
follow_sets = compute_follow_sets(rules)
follow_sets
'''
输出如下
{'E': {'$', ')'},
'G': {'$', ')'},
'T': {'$', ')', '+'},
'H': {'$', ')', '+'},
'F': {'$', ')', '*', '+'}}
'''
八、select集
8.1 如何计算select集
以下来自GPT




8.2 产生式的展开
# 展开前
{
"E": ["TG"],
"G": ["+TG", "ε"],
"T": ["FH"],
"H": ["*FH", "ε"],
"F": ["(E)", "a"]
}
# 展开后
{
'E': [['T', 'G']],
'G': [['+', 'T', 'G'], ['ε']],
'T': [['F', 'H']],
'H': [['*', 'F', 'H'], ['ε']],
'F': [['(', 'E', ')'], ['a']]
}
# 其实就是变了下数据格式,便于后边的处理
# 理论上应该变成的形式,但是字典中不能存在相同的键,所以将相同键的值合并了
{
'E': ['T', 'G'],
'G': ['+', 'T', 'G'],
'G': ['ε'],
'T': ['F', 'H'],
'H': ['*', 'F', 'H'],
'H': ['ε'],
'F': ['(', 'E', ')'],
'F': ['a']
}
8.3 产生式遍历解析
函数:get_generalized_first(lhs,rhs)
lhs->rhs的select集就是rhs的first集
广义的first集计算(在之前提到的first集都是针对单symbol的first集,这里拓展成多个symbols的first集)
对于A→α β
他的select集就是α β的first集
α β的first集就是{α的first集-ε},如果α 的first集包含ε,那么first集还要并上β的first集,以此类推
# 传入参数为一个rhs 多个symbols 输出整体rhs的first集
def get_generalized_first(lhs,rhs):
ans = set()
for i in range(len(rhs)):
# 若当前符号的FIRST集不含空,则停止
if 'ε' in first_sets[rhs[i]]:
ans |= (first_sets[rhs[i]] - {'ε'})
else:
# print('break')
ans |= first_sets[rhs[i]]
break
else:
ans|= follow_sets[lhs]
return ans
遍历产生式,将拓展first集加到select集中
for lhs,rhsss in new_rules.items():
for rhss in rhsss:
rhs = str(''.join(rhss))
selects[lhs][rhs].append(get_generalized_first(lhs,rhs))
8.4 可运行代码
# 构造select只需遍历一遍rules
# 首先需要将rules解析成单个的 对于为rhs为epsilon的产生式删除
# 对每个rule都构造状态即可
def parse_rules(rules):
parse_rules = {}
for lhs, rhss in rules.items():
for rhs in rhss:
# if rhs!='ε':
parse_rules.setdefault(lhs, []).append(list(rhs))
return parse_rules
rules = {
"E": ["TG"],
"G": ["+TG", "ε"],
"T": ["FH"],
"H": ["*FH", "ε"],
"F": ["(E)", "a"]
}
parse_rules(rules)
def compute_select_sets(rules):
first_sets = compute_first_sets(rules)
follow_sets = compute_follow_sets(rules)
non_terminals = list(first_sets.keys())
terminal_symbols = set()
for keyy, valuee in follow_sets.items():
for valueee in valuee:
terminal_symbols.add(valueee)
terminal_symbols = list(terminal_symbols)
# print(first_sets)
# print(follow_sets)
# print(non_terminals)
# print(terminal_symbols)
# 传入参数为一个rhs 多个symbols 输出整体rhs的first集
def get_generalized_first(lhs,rhs):
ans = set()
for i in range(len(rhs)):
# 若当前符号的FIRST集不含空,则停止
if 'ε' in first_sets[rhs[i]]:
ans |= (first_sets[rhs[i]] - {'ε'})
else:
# print('break')
ans |= first_sets[rhs[i]]
break
else:
ans|= follow_sets[lhs]
return ans
# print(get_generalized_first('TG'))
# 在first集中加上终结符的first集
for lhs,rhss in rules.items():
for rhs in rhss:
for symbol in rhs:
if symbol not in rules:
first_sets[symbol]=set()
first_sets[symbol].add(symbol)
# 将rules拆开
new_rules = parse_rules(rules)
# key中不加epsilon 添加判断即可
selects = {}
for lhs,rhss in new_rules.items():
selects[lhs]={}
for rhs in rhss:
# print(rhs)
# if rhs!=['ε']:
rhs_join = str(''.join(rhs))
selects[lhs][rhs_join]=[]
# print(lhs,rhs_join)
print(selects)
for lhs,rhsss in new_rules.items():
# print(lhs,rhsss)
for rhss in rhsss:
# print(lhs,rhss)
rhs = str(''.join(rhss))
# print(lhs,rhs)
selects[lhs][rhs]=get_generalized_first(lhs,rhs)
return selects
# 示例文法
rules = {
"E": ["TG"],
"G": ["+TG", "ε"],
"T": ["FH"],
"H": ["*FH", "ε"],
"F": ["(E)", "a"]
}
selects = compute_select_sets(rules)
# first_sets
selects
九、预测分析表构造
9.1 分析
根据select集构造预测分析表,如下:

该表对应的产生式是
rules = {
"A": ["aG"],
"G": ["ABe", "ε"],
"B": ["dH"],
"H": ["bH", "ε"],
}
如何将select集转成分析表?
观察一下求解出来的select集:
{ 'A': {'aG': {'a'}},
'G': {'ABe': {'a'}, 'ε': {'$', 'd'}},
'B': {'dH': {'d'}},
'H': {'bH': {'b'}, 'ε': {'e'}}
}
与分析表的区别其实只是变换了键值,只需改一下select集的二级字典的结构即可,不赘述
9.2 可运行代码
# 输出预测分析表并打印出预测分析表同时判断是否是ll1文法
def print_parsing_table_and_judge(rules):
select_sets = compute_select_sets(rules)
ans_change = {}
judgement = True
non_terminals = list(select_sets.keys())
terminal_symbols = set()
for state1, state2_and_convertchar in select_sets.items():
for state2,convertchar in state2_and_convertchar.items():
terminal_symbols|=(convertchar)
terminal_symbols = list(terminal_symbols)
# print(terminal_symbols)
for i in non_terminals:
ans_change[i] ={}
for j in terminal_symbols:
ans_change[i][j]=[]
for state1, state2_and_convertchars in select_sets.items():
for state2,convertchars in state2_and_convertchars.items():
for convertchar in convertchars:
# print(state1,state2,convertchar)
ans_change[state1][convertchar].append(state1+'->'+state2)
print("%12s"%(''),end = ' ')
for j in terminal_symbols:
print("%12s"%(j),end = '')
for i in non_terminals:
for j in terminal_symbols:
if len(ans_change[i][j])>1:
judgement = False
break
for i in non_terminals:
for j in terminal_symbols:
if len(ans_change[i][j])==0:
# print(ans_change[i][j])
ans_change[i][j].append('error')
for i in non_terminals:
print()
print("%12s"%(i),end = '')
for j in terminal_symbols:
print("%12s"%(ans_change[i][j]),end = ' ')
return ans_change,judgement
rules = {
"A": ["aG"],
"G": ["ABe", "ε"],
"B": ["dH"],
"H": ["bH", "ε"],
}
selects_convert,judgement = print_parsing_table_and_judge(rules)
# selects_convert,judgement
'''
a e $ d b
A ['A->aG'] ['error'] ['error'] ['error'] ['error']
G ['G->ABe'] ['error'] ['G->ε'] ['G->ε'] ['error']
B ['error'] ['error'] ['error'] ['B->dH'] ['error']
H ['error'] ['H->ε'] ['error'] ['error'] ['H->bH']
'''
十、检验字符串匹配预测分析表
使用一个栈来存储跟踪待处理的符号,并逐个字符地遍历输入字符串。根据栈顶符号和当前输入字符,在预测分析表中查找相应的产生式进行处理。如果遇到匹配的终结符,它们会从栈和输入中同时被移除。如果栈顶是非终结符,则根据预测分析表中的规则将其替换。直到栈为空或遇到无法解析的情况。
10.1 实际算法实现
-
初始化:将$和开始字符压入栈,将字符串末尾补充上$
-
当栈非空时:四个判断
2.1 top == $ 并且 current_char==$ 代表匹配完毕,return true
2.2 top == current_char 弹出栈顶元素,current_char后移
2.3 top 为非终结符并且 curren_char 在终结符中:查找分析表是否存在parse_table[top][current_char]
若不存在则return false,若存在则弹出栈顶元素并将该value(非ε)逆序压入栈中
2.4 else:return false
10.2 可运行代码
def predictive_parse(input_string, start_symbol, parse_table):
stack = ['$']
stack.append(start_symbol)
input_string += '$' #给输入字符串末尾增加结束符
idx = 0
while stack:
print(f"栈:{stack}, 输入:{input_string[idx:]}")
top = stack[-1]
current_char = input_string[idx]
if top == '$' and current_char == '$':
print("acc:输入字符串被成功分析。")
return True
elif top == current_char: # 栈顶元素与当前输入字符匹配则弹出栈顶元素,移动字符
stack.pop()
idx += 1
# 前提:非终结符和终结符为表的key 将value反向压入栈
elif top in parse_table and current_char in parse_table[top]:
production = parse_table[top][current_char][0]
if production == 'error':
print("无法解析")
return False
stack.pop() # 弹出栈顶元素
# 将产生式右边的符号逆序压入栈(跳过产生式的箭头和左边的非终结符)
for symbol in reversed(production.split('->')[1]):
if symbol != 'ε': # 忽略空字符
stack.append(symbol)
else:
print(f"错误:无法从栈顶符号 '{top}' 和输入字符 '{current_char}' 中恢复。")
return False
rules = {
"A": ["aG"],
"G": ["ABe", "ε"],
"B": ["dH"],
"H": ["bH", "ε"],
}
selects_convert,judgement = print_parsing_table_and_judge(rules)
input_string = "aade"
start_symbol = 'A'
selects = compute_select_sets(rules)
print(predictive_parse(input_string, start_symbol, selects_convert))
print(selects)
'''
栈的过程如下:
栈:['$', 'A'], 输入:aade$
栈:['$', 'G', 'a'], 输入:aade$
栈:['$', 'G'], 输入:ade$
栈:['$', 'e', 'B', 'A'], 输入:ade$
栈:['$', 'e', 'B', 'G', 'a'], 输入:ade$
栈:['$', 'e', 'B', 'G'], 输入:de$
栈:['$', 'e', 'B'], 输入:de$
栈:['$', 'e', 'H', 'd'], 输入:de$
栈:['$', 'e', 'H'], 输入:e$
栈:['$', 'e'], 输入:e$
栈:['$'], 输入:$
acc:输入字符串被成功分析。
'''
完整代码分享
链接: https://pan.baidu.com/s/1KwbBDCf3NEcapnyx63jFHw?pwd=zhuy 提取码: zhuy 复制这段内容后打开百度网盘手机App,操作更方便哦
















 513
513











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









