









《本文件系统默认linux文件系统》
一、文件系统基本概念
- 文件系统是操作系统中负责存取和管理信息的模块,它用统一的方式管理用户和系统信息的存储、检索、更新、共享和保护,并为用户提供一整套方便有效的文件使用和操作方法
- 文件系统是操作系统中管理文件的机构,提供文件存储和访问功能。
- 目录是由文件说明索引组成的用于文件检索的特殊文件。
二、文件系统基本组成

1、文件系统的作用
为应用程序提供逻辑抽象(虚拟机)
为磁盘空间提供管理机制(资源管理器)
2、磁盘格式化三区域
超级块:存储文件系统详细信息。如块大小、块个数、空闲块等。
索引节点区:存储索引节点。
数据块区:存储文件或目录数据。
三区域数据加载至内存时机:文件系统挂载时加载超级块;访问数据时加载索引节点,数据。
3、磁盘中文件存储
磁盘读写最小单位:扇区,512B; 文件系统读写最小单位:数据块,4KB; 也就是读取文件系统的一个数据块,在磁盘上对应的就是读取8个扇区。 一个数据块对应着8个扇区目的就是提高文件读取效率。
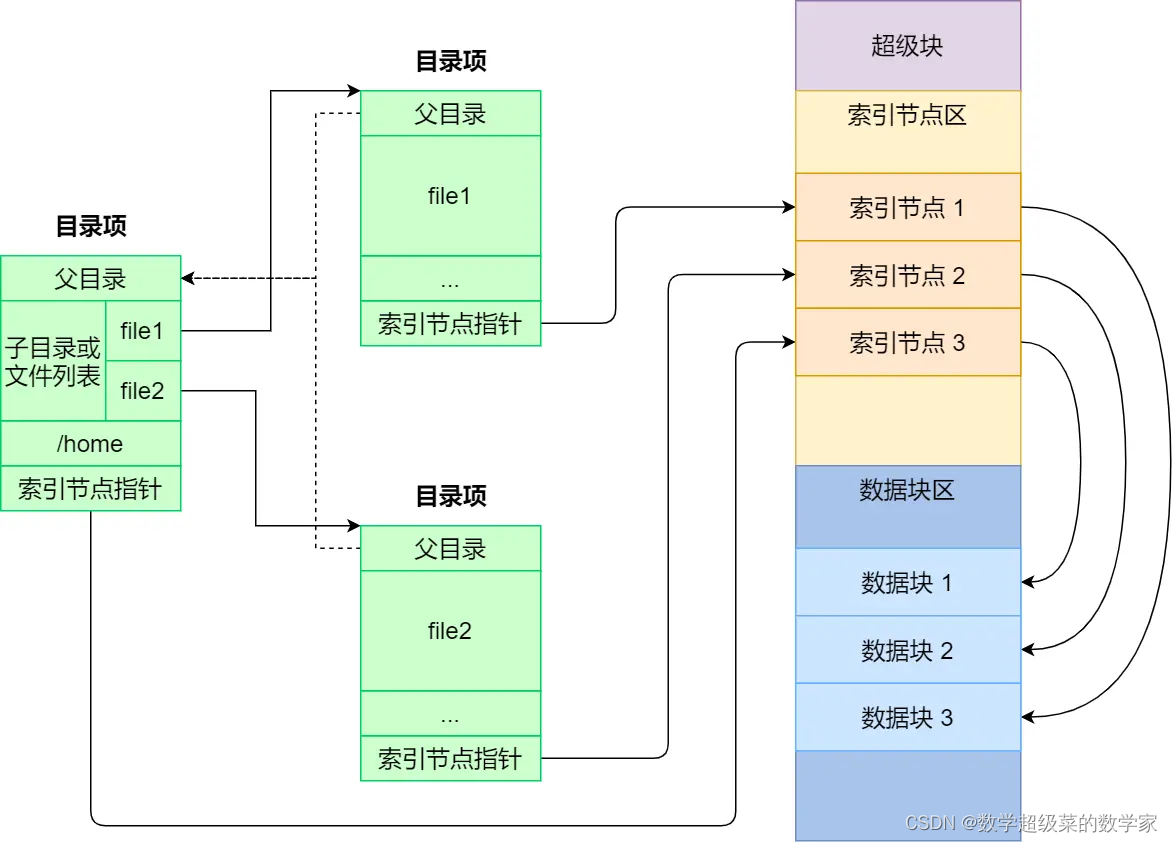
4、文件俩数据结构
Linux 文件系统会为每个文件分配两个数据结构:索引节点(index node)和目录项(directory entry),它们主要用来记录文件的元信息和目录层次结构。
索引节点(inode):(文件唯一标识)记录文件的元信息。如 inode 编号、文件大小、访问权限、创建时间、修改时间、数据在磁盘的位置等。存储在磁盘内。
目录项(dentry):用来记录文件的名字、索引节点指针以及与其他目录项的层级关联关系。多个目录项关联起来,就会形成目录结构,但它与索引节点不同的是,目录项是由内核维护的一个数据结构,缓存在内存。
联系 & 区别
索引节点标示唯一的文件,一个文件有多个名字,故索引节点与目录项为一对多关系。硬链接的实现就是多个目录项中的索引节点指向同一个文件。
目录与目录项
目录是个文件,永久保存在磁盘内;目录项是内核维护的数据结构,存储在内存。
目录存储在磁盘,为提高查询目录效率,内核将已访问过的目录用数据结构-目录项缓存在内存。再次查询目录时直接在内存查找目录项即可。
5、三大类文件系统
- 磁盘文件系统,它是直接把数据存储在磁盘中,比如 Ext 2/3/4、XFS 等都是这类文件系统。
- 内存文件系统,这类文件系统的数据不是存储在硬盘的,而是占用内存空间,我们经常用到的
/proc和/sys文件系统都属于这一类,读写这类文件,实际上是读写内核中相关的数据。 - 网络文件系统,用来访问其他计算机主机数据的文件系统,比如 NFS、SMB 等等。
文件系统首先要先挂载到某个目录才可以正常使用,比如 Linux 系统在启动时,会把文件系统挂载到根目录。
三、虚拟文件系统
虚拟文件系统(Virtual File System,VFS)定义一组所有文件系统都支持的数据结构和标准接口
由于文件系统众多,采用VFS可不用理解文件系统原理,只需要掌握VFS即可针对文件系统操作。
 作用类比 JDBC:Java通过JDBC 操作各种关系数据库
作用类比 JDBC:Java通过JDBC 操作各种关系数据库
四、文件的使用
文件打开关闭基本方式:系统调用。

以下代码表示读取文件的过程:
fd = open(name, flag); # 用open系统调用打开文件,参数为文件名,路径名
...
write(fd,...); # 用write写数据,参数包含open返回的 文件描述符
...
close(fd); # 文件使用完毕,使用close系统调用关闭文件,避免资源泄露
进程打开文件,操作系统为每个进程维护一个 文件打开表,其每一项为 文件描述符
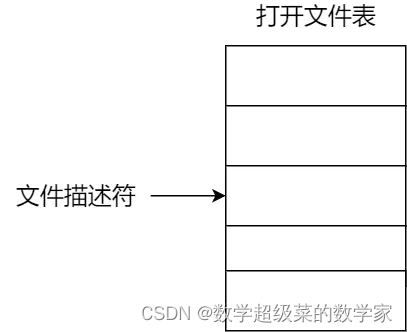
打开文件表中维护着打开的文件的状态和信息:
包括:文件指针,文件打开计数器、文件磁盘位置、访问权限。
用户习惯以字节的方式读写文件,而操作系统则是以数据块来读写文件,那屏蔽掉这种差异的工作就是文件系统。文件系统的基本操作单位是数据块。
五、文件的存储
1、文件与数据区别
数据就是可被计算机处理的符号总称。
文件是存储在某种长期储存设备上的一段数据流。
2、连续存储
文件存放在磁盘内连续的物理空间中。
文件头 包含文件 起始位置 和 大小。
优点:读写效率高,一次磁盘寻道可读出全部文件。
缺点:产生磁盘空间碎片;文件长度不易扩展。
3、非连续存储
链表方式
隐式链表:每个node分为指针区与数据区,各节点通过指针连接。
缺点:一旦某个节点指针丢失,则无法寻址。
显式链表:直接将指针存放到内存中的链接表(文件分配表FAT)中, 每个表项中存放链接指针,指向下一个数据块号。
优缺点:减少访问磁盘提高检索速度。但是不适用于大磁盘,FAT要占用内存!
索引方式
每个文件创建一个 <索引数据块>,存放着指向文件数据块的指针列表。
文件头 需只想索引数据块的 指针。这样通过文件头 可以知道 索引数据块位置,再通过索引数据块内的指针,找到文件数据块。
索引的方式优点在于:
易扩展;无空间碎片;可顺序读也可随机读。
六、空闲空间管理
目的:快速找到空闲空间存放数据。
1、空闲表法
适用于建立连续文件;适合空闲空间个数少的。
为所有空闲空间建立空闲表,表内容包含空闲区第一个块号及空闲区块个数。
2、空闲链表法
每个空闲块里的指针指向下一个空闲块
优缺点:其特点是简单,但不能随机访问,工作效率低,因为每当在链上增加或移动空闲块时需要做很多 I/O 操作,同时数据块的指针消耗了一定的存储空间。
空闲表法和空闲链表法都不适合用于大型文件系统,因为这会使空闲表或空闲链表太大。
3、最好的 -> 位图法
位图是利用二进制的一位来表示磁盘中一个盘块的使用情况。
当值为 0 时,表示对应的盘块空闲,值为 1 时,表示对应的盘块已分配。
七、文件系统的结构
文件系统由大量 块组 构成

引导块,在系统启动时用于启用引导
八、目录的存储
目录文件的数据块里保存的是目录里面一项一项的文件信息(如文件名、 inode、文件类型等)。
目录文件的数据块内文件信息最简单格式:列表。缺点是查找效率低。
保存目录的格式:哈希表
对文件名进行哈希计算,把哈希值保存起来,如果我们要查找一个目录下面的文件名,可以通过名称取哈希。如果哈希能够匹配上,就说明这个文件的信息在相应的块里面。
目录存储在磁盘内,内核会维护数据结构目录项,将访问的目录存储在内存中,实现快速访问。
九、软链接和硬链接
作用:为解决文件的共享使用。还带来了隐藏文件路径、增加权限安全及节省存储等好处。
硬链接:多个目录项中的「索引节点」(inode)指向一个文件。

软链接:重新创建一个文件,这个文件有独立的 inode,但此文件的内容是另外一个文件的路径。

区别:
1、本质:
硬链接:多个目录项同一个inode,只是文件名字不同。
软链接:是不同的文件,inode不同。
2、跨分区
不同文件系统inode数据结构类型不同。硬链接无法跨分区、跨设备建立,软链接可以。
3、目录
硬链接无法创建目录硬链接,软链接可以
4、相互关系
硬链接没有主次之分,相互独立
软链接依赖于原文件,原文件被删除,软链接即不可用
5、链接数
硬链接会删除增加会影响链接数,软链接不会,因为inode不一样。
6、相对路径
硬链接创建时,原始文件路径是相对于当前路径。
软链接创建时,原始文件路径是 相对于软链接的路径
十、文件I/O
1、缓冲与非缓冲 I/O
判断标准:是否利用标准库缓冲。
- 缓冲 I/O:利用标准库的缓存实现文件的加速访问,而标准库再通过系统调用访问文件。
- 非缓冲 I/O:直接通过系统调用访问文件,不经过标准库缓存。
2、直接与非直接 I/O
判断标准:是否利用操作系统的缓存。
- 直接 I/O:直接经过文件系统访问磁盘。
- 非直接 I/O:读操作时,数据从内核缓存中拷贝给用户程序,写操作时,数据从用户程序拷贝给内核缓存,再由内核决定什么时候写入数据到磁盘。
缓存内数据写入磁盘时机:内存资源紧张;超时;用户主动调用 sync。
3、 阻塞与非阻塞 I/O VS 同步与异步 I/O
阻塞 I/O
当用户程序执行 read ,线程会被阻塞,一直等到内核数据准备好,并把数据从内核缓冲区拷贝到应用程序的缓冲区中,当拷贝过程完成,read 才会返回。
注意,阻塞等待的是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程。
非阻塞 I/O
非阻塞的 read 请求在数据未准备好的情况下立即返回,可继续往下执行,此时应用程序不断轮询内核,直到数据准备好,内核将数据拷贝到应用程序缓冲区,read 调用才可以获取到结果。
异步 I/O
「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程都不用等待。
总结
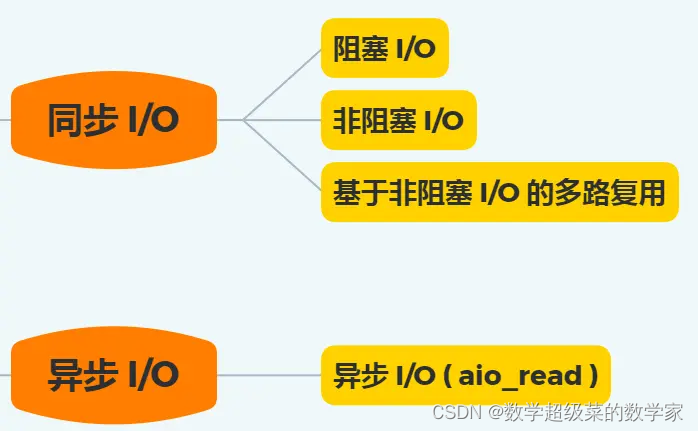
I/O 是分为两个过程的:
- 内核数据准备的过程
- 数据从内核空间拷贝到用户进程缓冲区的过程
阻塞 I/O 会阻塞在「过程 1 」和「过程 2」,而非阻塞 I/O 和基于非阻塞 I/O 的多路复用只会阻塞在「过程 2」,所以这三个都可以认为是同步 I/O。
异步 I/O 则不同,「过程 1 」和「过程 2 」都不会阻塞。
















 691
691











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











