







 通过对健身平台2019年至2020年的订单数据进行分析,揭示了用户消费特征、用户分层、用户质量等方面。发现用户整体消费趋势在19年8月后出现异常波动,用户消费集中在小额,高消费用户占比较少。通过RFM模型,了解到20%的用户贡献了80%的消费额。用户购买周期平均为4天,用户生命周期平均为32天,反映出用户粘性不高。复购率和回购率显示,需要加强用户再次消费和持续性消费的引导策略。
通过对健身平台2019年至2020年的订单数据进行分析,揭示了用户消费特征、用户分层、用户质量等方面。发现用户整体消费趋势在19年8月后出现异常波动,用户消费集中在小额,高消费用户占比较少。通过RFM模型,了解到20%的用户贡献了80%的消费额。用户购买周期平均为4天,用户生命周期平均为32天,反映出用户粘性不高。复购率和回购率显示,需要加强用户再次消费和持续性消费的引导策略。
目录
一、项目及数据集介绍
1. 项目背景
为了让健身平台创造出更多的价值,找到最适合自己的经营、营销策略,我们使用该平台2019年3月至2020年2月12个月的订单数据进行相关分析,并根据复购率、回购率、高消费用户等指标模型进行针对性的客户管理与维护。
2. 数据集介绍
数据集'Gym.xls'来源于[和鲸社区]。
数据集包含了某健身平台2019年3月至2020年2月用户消费购买行为的所有订单数据,总计2013条数据,数据集中所有数据均为脱敏数据。
该数据集一共包含4个字段:用户id(user_id)、购买日期(order_dt)、购买数量(order_products)和购买金额(order_amount),是最典型的消费行为数据集。
二、需求分析
1. 业务化分析思路
大致思路如下图所示:
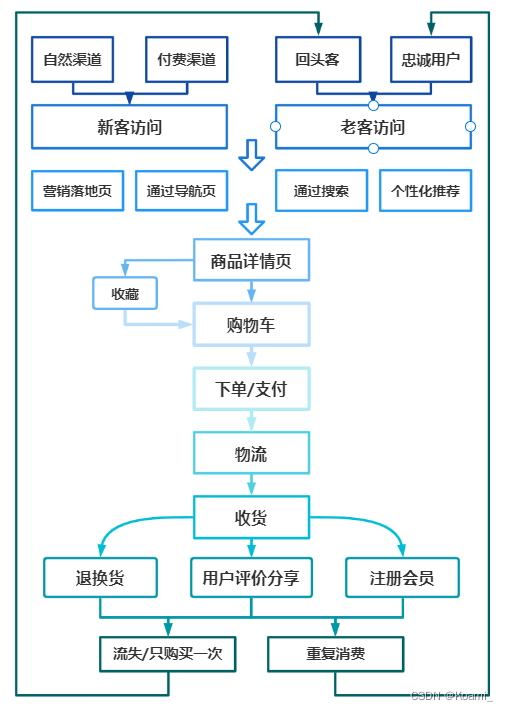
2. 需求分析
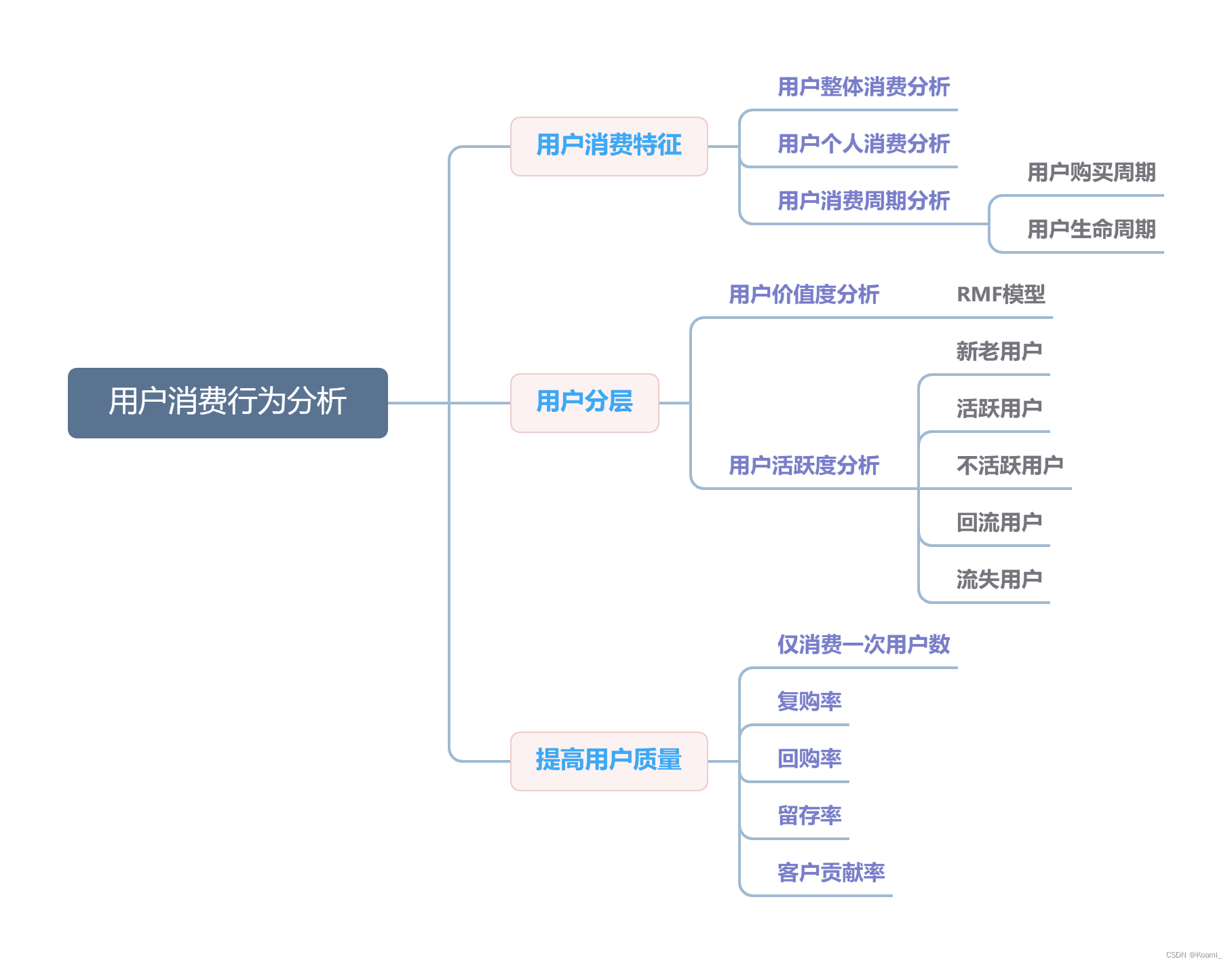
用户消费行为特征一般分为三个部分:用户消费特征、用户分层、用户质量。
第一个维度:用户消费特征。主要包括三个部分。第一,用户整体消费分析,即分析所有客户他的一个行为习惯;第二,用户个体消费分析,即按照用户的订单ID或用户ID分析他/她的行为习惯;第三,用户消费周期,包含购买周期和生命周期两个部分,用户购买周期即用户再次购买商品的时间间隔,而用户生命周期是指用户从首次消费到完全离开商品的一个过程,通过这两个指标可以推断用户的存活和流失周期。
第二个维度:用户分层。在这一版块,我们需要对用户的价值和活跃度两部分进行分析。在用户价值分析中,需要利用当今企业较为广泛应用的RMF模型来进行相应的计算与分析;而用户活跃度,我们一般从新老用户、活跃用户、不活跃用户、回流用户与流失用户这几个层面展开分析。
第三个维度:用户质量。主要针对如何提高用户质量进行展开。包括用户复购率、回购率、留存率、消费频率、客户贡献率等,通过这些数据,我们可以直观清晰地看出平台目前的用户质量,并根据当前的状况对现有客户进行针对性的管理与维护,并做出最合适的调整,改变现有的经营方式,完善营销策略,从而达到增加营收的目的。
下图为上述用户消费行为分析的思维导图:
三、数据探查
1. 导入常用库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.style.use('ggplot')2. 导入数据
df = pd.read_excel('gym.xls')
df.head()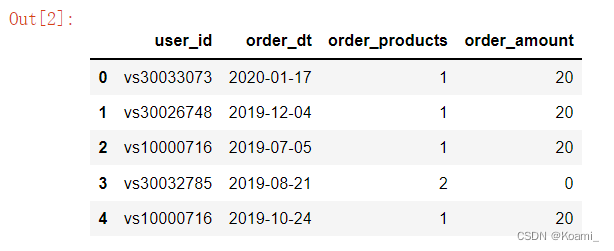
读取前5行数据并检查,数据已被成功导入。
3. 查看数据基本信息
df.info()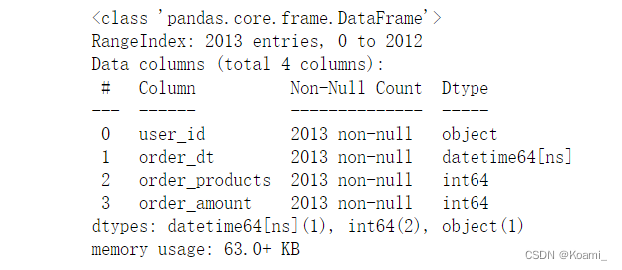
查看数据概括:
- 从基本信息可以看出,该数据集共包含2013条数据,数据量充足,能够在该数据集的基础上进行相关数据分析;
- 从数据类型来看,用户id、购买日期、购买数量、购买金额的数据类型分别为:object、datetime64[ns]、int、int数据类型没有问题,无需进行转换;
- 从每一列的数据统计来看,数据集没有缺失项,数据干净,无需清洗。
4. 数据预处理
从前面的数据基本信息可以看出,该数据集的数据干净规范,无需进行过多调整。为方便后续的数据分析,我们先在原数据的基础上加一列月份列,并对数据进行一定的分组。
4.1 添加月份列
df['month'] = df['order_dt'].values.astype('datetime64[M]')
df.head()
读取前5行数据并检查,月份列已被成功添加。
4.2 按用户进行分组
user_grouped = df.groupby('user_id').sum()
user_grouped.head()
读取前5行数据并检查,数据已被成功分组。
4.3 按月份进行分组
# 按月分组-用户购买数量
month_grouped_p = df.groupby('month')['order_products'].sum()
month_grouped_p.head()
# 按月分组-用户购买金额
month_grouped_a = df.groupby('month')['order_amount'].sum()
month_grouped_a.head()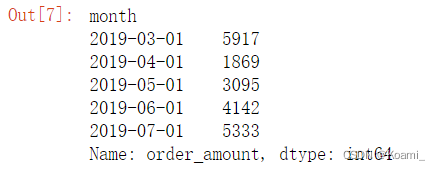
# 按月分组-用户
month_grouped_i = df.groupby('month')['user_id'].count()
month_grouped_i.head(5)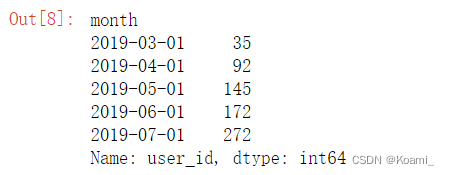
分别读取前5行数据并检查,数据已被成功分组。
5. 数据统计
df.describe()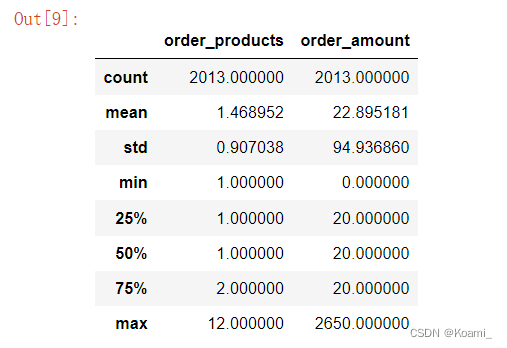
观察订单的数据统计:
- 按每笔订单来统计分布,平均每笔订单购买1.47个商品,标准差为0.91,波动较小。中位数在1.00,0.75分位数为2.00,可以看出绝大多数用户的购买力不强;
- 订单金额与购买数量情况相差不多,大部分的订单都集中在小额,0.25分位数与0.75分位数均为20,而最大值有2650,且均值>中位数,数据整体右偏,长尾效应严重,符合消费类数据的特质;
- 大部分订单都是小额,然而极小部分订单贡献了收入的大头,俗称二八法则。
四、用户整体消费趋势(按月)
plt.figure(figsize=(20,15))
plt.subplot(221)
month_grouped_p.plot(kind='line',color='r',fontsize=20)
plt.xlabel('月份')
plt.ylabel('购买数量')
plt.titl 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2933
2933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









