






本文将简要介绍现代密码学中的一项关键技术: 安全性证明. 任何一个现代密码算法或协议都需要先经过完整的安全性证明, 才能去讨论其理论和应用价值.
如果一个密码方案无法做到可证明安全, 那么它声称的各种能力都将只是空中楼阁.
然而, 刚开始阅读现代密码学论文的时候, 很容易被其中占据了大量篇幅的安全性证明章节给吓住. 因此本文将简单地对这一主题进行介绍,
在保持简明的同时尽可能体现其核心逻辑. 在阅读本文前, 具备以下背景知识可极大提升阅读体验:
- 现代密码学是一门什么样的学科 ?
- 如何理解 P P P 问题, N P NP NP 问题 ?
- 现代密码学中的安全模型一般有哪些 ?
安全性"证明"?
与从小到大学习的各种数学证明类似, 在密码学的安全性证明中, 也需要明确证明的命题 , 以及命题中的假设 和待证明结论. 然而,
证明一个数学定律这件事是明确的, 比如我们都学习过的各种平面几何定理的证明, 就是要寻求不同线段, 角度, 图形之间的位置或数量规律.
可是我们该怎么用数学的语言 “证明” 一个方案的安全性呢? 也就是说, 一个方案安全与否, 如何用 形式化的数学语言 来证明呢 ?
在现代密码学发展早期, 人们"证明"方案的安全性就是去寻找是否存在有效的攻击 , 如果暂时找不到, 就认为这个方案是安全的. 显然, 在这种方式下,
密码学很难被认为是一门严肃的学科. 直到上世纪80年代-90年代, Goldwasser与Bellare才先后提出了密码学的可证明安全理论模型,
这也才让安全性证明具有了与一般数学证明相同的形式和框架. 那在安全性证明中, 假设、待证明结论以及用到的证明技术分别又是什么或代表什么意义呢 ?

安全假设
在理论计算机领域, 我们可以用** P 问题** , NP 问题和 NP-Hard 问题来描述所处理问题的求解"难度".
以密码学中的单向函数 (One-Way Function) 为例, 有如下观察来帮助大家理解密码学与 P P P vs. N P NP
NP之间的联系:
- 单向函数的正向计算就是一个 P 问题, 即可以在多项式时间内 (快速) 求解;
- 单向函数逆的求解好像是一个 NP 问题, 即直接求逆似乎是比较复杂的, 但可以在多项式时间内 (快速) 验证;
了解密码学的读者可能知道, 单向函数是几乎所有密码方案和理论的基础. 因此在密码学中, 对于那些具有多项式资源的敌手, 安全假设往往是从那些
可能是 NP 或 NP-Complete 的问题里来构造. 因为这些问题有计算复杂性理论作为支撑, 且能依赖 P P P vs. N P NP
NP 这一数学与计算机界都有研究共识的基础假设.
📢 可以看到, 目前整个密码学界研究的前提是 P ≠ N P P \neq NP P=NP 这一关键假设, 可如果 P = N P P = NP
P=NP了怎么办, 即所有NP问题, P问题和NP-Complete问题都是一样的. 注意到, P = N P P = NP
P=NP只是说明存在一种算法能快速求解原来的NP问题, 但这并不代表着我们就知道这种算法是什么, 因此即使 P = N P P = NP P=NP了,
留给密码学家们依然还有一定的余地.
📢 此处我们暂不考虑无条件安全性 (unconditional security)
待证明结论
对于要证明的"安全性", 一个朴素的理解就是敌手无法成功攻击嘛, 加密算法的安全性就是敌手恢复不出明文消息或密钥, 签名算法的安全性就是敌手伪造不出签名.
那我们该怎么刻画"无法攻击成功", “恢复不出”, "伪造不出"这些词语的本质内涵呢 ?
实际上, 如果用密码学的语义描述出来, 其实就是 不可区分性 (Indistinguishability), 不可伪造性 (Unforgeability)
等定义,
而基于这些定义所构建的各种安全模型如
IND-CPA, EUF-CMA就可以作为一个命题最终要证明的结论.
因此, 对于常见的密码学安全命题, 证明的目标就是说明这个算法 在一定安全假设下符合某个安全模型的要求 . 而在概率多项式时间 (PPT)
敌手的条件下, 这种"要求"一般是以敌手成功的概率上界的形式给出的.
常见的安全假设与结论
下面我们介绍几个常见的密码学安全证明命题来感觉一下密码学中的可证明安全画风:
- 如果DDH问题是困难的 (安全假设) ⇒ \Rightarrow ⇒ ElGamal算法是IND-CPA安全的 (待证明结论)
- 如果CDH问题是困难的 ∪ \cup ∪ 所用哈希函数 H H H 是一个Random Oracle (安全假设) ⇒ \Rightarrow ⇒ DHIES 算法是IND-CPA安全的 (待证明结论)
- 如果DL问题是困难的 (安全假设) ⇒ \Rightarrow ⇒ Schnorr 身份证明协议是UI-PA 安全的; (待证明结论)
- 如果 Schnorr 身份证明协议是UI-PA 安全的 ∪ \cup ∪ 所用哈希函数 H H H 是一个Random Oracle (安全假设) ⇒ \Rightarrow ⇒ Schnorr 签名算法是EUF-CMA安全的; (待证明结论)
- 如果 Decisional LEW问题是困难的 (安全假设) ⇒ \Rightarrow ⇒ Dual Regev 算法 (single bit) 是 IND-CPA 安全的 (待证明结论)
到现在, 相信读者对整个密码学安全性证明在直观上有了一定的理解, 那么万事具备, 只欠东风. 下面我们就正式开始介绍安全性证明中间的这最重要的一环:
证明技术.
安全性证明的一般技术——归约
核心思想
其实, 如果你知道了 证明逆否命题等价于证明原命题 这个数学公理, 那么恭喜你已经学会了安全性证明! 当然,
这需要用大量的时间在密码学的语义框架下去内化这一理解, 才能写出自己的证明. 以上一小节的第一个命题为例:
🔸 DDH问题是困难的 ⇒ \Rightarrow ⇒ ElGamal算法是IND-CPA安全的
这一命题的逆否命题相信大家都可以很容易地写出:
🔸 ElGamal算法不是IND-CPA安全的 ⇒ \Rightarrow ⇒ DDH问题可以被攻破
在密码学的框架下, 上面这个逆否命题实际上表达了这样的一个含义:
🔸 如果存在一个PPT敌手在 CPA 模型下攻破了ElGamal算法的不可区分性, 那么敌手也就能解决DDH问题
有了这一观察, 我们该如何证明呢 ? 谜底就在谜面上, 即我们假设真的存在这么一个敌手 A \mathcal{A} A, 它只要 CPA
模型下接受到了合适的输入, A \mathcal{A} A 就能返回它对ElGamal加密不可区分游戏的结果; 那么我们可以根据 A
\mathcal{A} A 构造另外一个敌手 B \mathcal{B} B, B \mathcal{B} B 的目标是解决 DDH 问题, 在 B
\mathcal{B} B被给予了DDH问题的输入后, 我们设法将 B \mathcal{B} B 的难题嵌入 到 A \mathcal{A} A
的输入中, 并将 A \mathcal{A} A 当作是一个子程序 (subroutine) 来调用. 此时, 只要 A \mathcal{A} A
顺利地解决了ElGamal的不可区分性问题, B \mathcal{B} B 根据 A \mathcal{A} A 的输出就能顺利解决自己的DDH问题.
上面这一大段话可以总结为: 将 ElGamal算法的IND-CPA安全性 归约 (Reduce) 到 DDH问题的困难性上.
示意图如下图所示:

步骤分解
可能上面那段话看起来有些云里雾里的, 下面我们就将其按步骤分解一下.
Step 1: 我真的有一头牛
证明的整体策略是去证明原命题的逆否命题, 因此原来的目标就成了现在的条件 (反了一下), 所以既然原命题的目标是要证明某个算法是安全的,
那么在逆否命题中就认为攻破这个算法的敌手是存在的.
唯一的要求是, 这个敌手要切实符合之前的假设, 即只有在正确的安全模型下交互才能攻破这个算法, 那这里正确 的安全模型该如何理解呢 ? 以IND-
CPA为例:
- 敌手能力: 在IND-CPA模型中, 敌手可被允许提交明文 m m m 并获得密文 c c c, 即CPA. 这是应当给予敌手的能力;
- 交互方式: 在IND-CPA模型中, 敌手与其挑战者先经过 q q q 次提交 m m m 获得 c c c 的查询交互过程, 之后敌手提交 ( m 0 , m 1 ) (m_{0}, m_{1}) (m0,m1), 挑战者返回 c ∗ c^{*} c∗, 敌手输出猜测结果. 整个过程应当由 q q q 次查询, 1次敌手提交, 1次挑战者输出这些交互组成, 最终敌手可输出攻击结果;
- 输出结果: 在IND-CPA模型中, 敌手在给予上述能力, 经过上述交互后, 会输出一个结果比特 b ∈ { 0 , 1 } b\in\{0, 1\} b∈{0,1}, 来指代密文 c ∗ c^{*} c∗对应的是哪个明文.

因此, 在上面那一段话里, 所谓的构造一个IND-CPA的敌手 A \mathcal{A} A , 就是要全方位地模拟出这样一个IND-CPA的环境,
为这个环境中的 A \mathcal{A} A 赋予其恰当的能力, 配合其交互, 最终接收它的输出结果. 按照预期, 如果 A \mathcal{A} A
能解决这个问题, 那么应该就能通过某种方法解决原命题中的困难问题.
Step 2: 究竟要解决什么问题 ?
在确认我们真的有一头牛之后, 下面先来看看最终的目标是什么, 对于上面的例子而言也就是去解决DDH问题. 说白了, 我们的目标就是根据已有的敌手 A
\mathcal{A} A 去构造 出另外一个敌手 B \mathcal{B} B, 并且让它能解决DDH问题.
📢 DDH问题: 挑战者给定敌手 g x , g y , T b g^{x}, g^{y}, T_{b} gx,gy,Tb, 其中 b ∈ { 0 ,
1 } b\in\{0, 1\} b∈{0,1}, T 0 T_{0} T0为群上的随机元素, T 1 = g x y
T_{1}=g^{xy} T1=gxy, 敌手输出 b ∗ = b b^{*}=b b∗=b则问题解决.
这时你也许发现了, 这个Step 2和刚才的Step 1好像挺类似? 没错, Step 1是我们已经 构造出的敌手, 而Step
2是我们想要 构造出的敌手. 不论我们是已经构造还是想要构造, 都要给予两个敌手正确的环境, 也就是所谓的敌手能力、交互方式与输出结果. 类似的有:
- 敌手能力: 在DDH问题中, 敌手可被允许尝试多次问题求解, 即多次接受挑战者的输入.
- 交互方式: 在DDH问题中, 挑战者首先固定 b ∈ { 0 , 1 } b\in \{0, 1\} b∈{0,1}, 之后 (可多次) 生成元组 g x , g y , T b g^{x}, g^{y}, T_{b} gx,gy,Tb给敌手,
- 输出结果: 在DDH问题中, 敌手在给予上述能力, 经过上述交互后, 输出一个结果比特 b ∗ b^{} b∗. 若 b ∗ b^{} b∗与最开始挑战者选定的 b b b相等, 那么敌手成功.

目前, 我们已经定义好了已经有的敌手 A \mathcal{A} A, 以及要构造的敌手 B \mathcal{B} B, 那下面就来到最关键的一步,
即如何将两个敌手联系起来, 构建它们之间的逻辑关系, 来让我们要证的那个逆否命题成立.
Step 3: 搭建彼此间的桥梁
要实现这一步, 就需要从算法本身的运算结构出发, 尝试将 B \mathcal{B} B要解决的任务嵌入 A \mathcal{A} A的输入中.
ElGamal公钥加密算法的完整过程如下图所示:

目前我们知道:
- 对于敌手 B \mathcal{B} B, 它的输入为 ( g x , g y , T b ) (g^{x}, g^{y}, T_{b}) (gx,gy,Tb), 它的目标是区分 T b T_{b} Tb 是 g x y g^{xy} gxy 还是 群上的一个随机元素;
- 对于敌手 A \mathcal{A} A, 它的输入为 ( c ∗ ) (c^{}) (c∗), 即ElGamal的挑战密文, 它的能力是区分 c ∗ c^{} c∗ 是 m 0 m_{0} m0 还是 m 1 m_{1} m1 对应的密文.
乍一看可以发现, B \mathcal{B} B 自己的那一组DDH输入与ElGamal 算法中 公钥, 密文等元素在计算方式上有着高度的
相似之处 , 因此, 这里就是 B \mathcal{B} B 进行问题嵌入的切入点. 注意, 敌手 A \mathcal{A} A 在
IND-CPA 交互中刚开始的几次密文查询可以直接由敌手 B \mathcal{B} B 使用公钥 g x g^{x} gx 完成,
因此让我们把目光聚焦到 B \mathcal{B} B收到 A \mathcal{A} A发来的 ( m 0 , m 1 ) (m_{0}, m_{1})
(m0,m1)这一特殊时刻, 因为这里就是我们真正要实现归约的地方, 接下来 B \mathcal{B} B会这样做:
- 选择一个bit b ′ ∈ { 0 , 1 } b^{‘} \in \{0, 1\} b′∈{0,1}以挑选 m b ′ m_{b^{’}} mb′, 并将自己收到的挑战元素 T b T_{b} Tb 乘以 m b ′ m_{b^{‘}} mb′ 得到 T b ⋅ m b ′ T_{b} \cdot m_{b^{’}} Tb⋅mb′;
- B \mathcal{B} B 令 Elgamal密文 c 2 = T b ⋅ m b ′ c_{2}=T_{b} \cdot m_{b^{'}} c2=Tb⋅mb′ 并发送 ( c 1 , c 2 ) (c_{1}, c_{2}) (c1,c2) 给 A \mathcal{A} A 作为挑战密文 c ∗ c^{*} c∗;
- 如果 A \mathcal{A} A能以超过 1 2 \frac{1}{2} 21的概率成功输出一个bit b ′ b^{‘} b′ 等于 B \mathcal{B} B 自己选择的 b ′ b^{’} b′, 那么 B \mathcal{B} B就认为 T b = g x y T_{b}=g^{xy} Tb=gxy, 否则 B \mathcal{B} B 认为 T b T_{b} Tb 只是群上的一个随机元素.
为什么可以这样做呢 ? 假如给 B \mathcal{B} B 的就是 T = g x y T=g^{xy} T=gxy, 那么 B
\mathcal{B} B 为 A \mathcal{A} A 构造的Elgamal环境就跟真实的Elgamal算法完全相同, 即此时敌手 A
\mathcal{A} A 处于正确的环境中 , 那么 A \mathcal{A} A 就当然可以发挥它的能力, 为我们输出一个正确的比特.
反之, 如果 B \mathcal{B} B 的输入 T T T 是一个随机挑选的元素, 那么经过乘法后, c 2 c_{2} c2
的分布也将是随机分布. 此时, 将不满足 A \mathcal{A} A 对环境的要求, 因此 A \mathcal{A} A
也就无法以压倒性概率输出正确的比特 b ′ b^{'} b′ 了.

❓ 这里读者也许会有疑问: 明明Elgamal算法里的 y y y 也是随机选取的, 那为啥 A \mathcal{A} A 也能正确输出呢 ?
我们这里并不真的关心 y y y 以及 g y g^{y} gy的分布, 而是关注 B \mathcal{B} B
所构造的Elgamal算法的输出密文, 究竟是否按照真实的Elgamal加密算法计算得到. A \mathcal{A} A
的能力就是在计算过程出了偏差时, 敏感 地作出反应, 即只有严格按照Elgamal算法输出的密文, 它才能以压倒性地成功概率输出结果. 至于 A
\mathcal{A} A的这种"火眼金睛"是怎么来的, 我们就不用管了, 因为这本身就是假设的一部分.
进一步地, 我们甚至可以计算 B \mathcal{B} B 成功的概率. 下面分情况讨论:
- 当 b = 0 b=0 b=0 即 T b = T 0 = g x y T_{b}=T_{0}=g^{xy} Tb=T0=gxy 时, A \mathcal{A} A 能成功恢复, 即此时 A \mathcal{A} A 输出正确的概率 P r [ A = b ′ ] = 1 2 + λ \mathrm{Pr}[\mathcal{A}=b^{'}] = \frac{1}{2} + \lambda Pr[A=b′]=21+λ, 其中 λ \lambda λ 为一个不可忽略的概率;
- 当 b = 1 b=1 b=1 即 T b T_{b} Tb 为一群上的随机元素时, A \mathcal{A} A 不能成功恢复, 即此时 P r [ A = b ′ ] = 1 2 \mathrm{Pr}[\mathcal{A}=b^{'}] = \frac{1}{2} Pr[A=b′]=21.
那么敌手 B \mathcal{B} B 的优势有:
A d v B D D H = ∣ P r [ B = b ] − 1 2 ∣ = ∣ 1 2 P r [ B = 1 ∣ b = 1 ] + 1 2 P r [ B = 0 ∣ b = 0 ] − 1 2 ∣ = ∣ 1 2 P r [ B = 1 ∣ b = 1 ] + 1 2 ( 1 − P r [ B = 1 ∣ b = 0 ] ) − 1 2 ∣ = 1 2 ∣ P r [ B = 1 ∣ b = 0 ] − P r [ B = 1 ∣ b = 1 ] ∣ = 1 2 ∣ ( 1 − P r [ A = b ′ ] ) − 1 2 ∣ = 1 2 λ \begin{aligned} \mathrm{Adv}_{\mathcal{B}}^{DDH} = & |\mathrm{Pr}[\mathcal{B}=b]-\frac{1}{2}| \\ = &|\frac{1}{2}\mathrm{Pr}[\mathcal{B}=1 | b = 1] + \frac{1}{2}\mathrm{Pr}[\mathcal{B}=0 | b = 0] - \frac{1}{2}| \\ = & |\frac{1}{2}\mathrm{Pr}[\mathcal{B}=1 | b = 1] + \frac{1}{2}(1 - \mathrm{Pr}[\mathcal{B}=1 | b = 0]) - \frac{1}{2}| \\ = & \frac{1}{2}|\mathrm{Pr}[\mathcal{B}=1 | b = 0] - \mathrm{Pr}[\mathcal{B}=1 | b = 1]| \\ = & \frac{1}{2}|(1 - \mathrm{Pr}[\mathcal{A}=b^{'}]) - \frac{1}{2}| \\ = & \frac{1}{2} \lambda \\ \end{aligned} AdvBDDH======∣Pr[B=b]−21∣∣21Pr[B=1∣b=1]+21Pr[B=0∣b=0]−21∣∣21Pr[B=1∣b=1]+21(1−Pr[B=1∣b=0])−21∣21∣Pr[B=1∣b=0]−Pr[B=1∣b=1]∣21∣(1−Pr[A=b′])−21∣21λ
可以看到, 如果 A \mathcal{A} A 的优势是不可忽略的, 那么敌手 B \mathcal{B} B 的优势也是不可忽略的, 并且上界为 1
2 λ \frac{1}{2} \lambda 21λ, 即 A \mathcal{A} A 优势的一半.
通过观察算法与安全假设之间的共通之处, 找到相同的运算结构, 就可以思考如何将已知敌手的能力运用于解决目标敌手的问题,
从而能将所谓的困难问题或安全假设嵌入 到已知敌手的求解过程中, 进而成功搭建两个敌手之间的桥梁.
小结
目前为止, 证明一个密码学安全命题的基本范式想必读者已经了解了. 整体的思路就是, 在假设成立的前提下, 通过某种方法, 将要证的敌手目标转 (shuǎi)
移 (guō) 给假设成立的敌手. 这里面最困难, 也是最精妙的地方就在于如何去转移. 这就需要对要证算法的运算结构以及假设的本质有足够的理解.
而像上面举例的这种归约方法, 在计算复杂性上属于Cook Reduction, 归约的结果说明"至少一样难".
对应到例子中就是只要构造出破解Elgamal的算法, 就可以构造出破解DDH问题的算法, 即前者至少和后者一样难.
一个算法安全性证明的示例
下面我们再用一个关于构造算法的安全性证明示例巩固下上面的流程, 给出要证明的安全性命题如下:
🔸 要证: 在哈希函数H是抗碰撞的前提下, 令 S = ( K G e n , S i g n , V r f y )
\mathcal{S}=(\mathtt{KGen}, \mathtt{Sign}, \mathtt{Vrfy}) S=(KGen,Sign,Vrfy)
为一EUF-CMA安全的签名算法, 那么基于 S \mathcal{S} S 构造的另一签名方案 S ′ = ( K G e n ′ , S i g
n ′ , V r f y ′ ) \mathcal{S’}=(\mathtt{KGen}‘, \mathtt{Sign}’,
\mathtt{Vrfy}‘) S′=(KGen′,Sign′,Vrfy′) 也是EUF-CMA安全的**, 其中二者有关系 S i g n ′ (
m ) = S i g n ( H ( m ) ) \mathtt{Sign}’(m) = \mathtt{Sign}(H(m))
Sign′(m)=Sign(H(m)).
这里没用另外一个具体的算法而是用抽象的方案, 这样更能加深对证明内涵的理解, 而不拘泥于算法形式. 那么按照之前的步骤,
在证明开始前先看看逆否命题长什么样:
🔸 即证: 在哈希函数H是抗碰撞的前提下, 如果签名方案 S ′ \mathcal{S’} S′ 不是EUF-CMA安全的, 那么 S
\mathcal{S} S 也不是EUF-CMA的.
构造敌手A
对于Step 1, 我们构造一个能攻破 S ′ \mathcal{S’} S′ 签名方案 EUF-CMA 安全性的敌手 A \mathcal{A} A,
示意图如下所示:

该敌手的能力可以归结为以下几点:
- 向实现了 S ′ \mathcal{S’} S′ 的签名oracle提交消息 m m m, 并获得对应的签名 σ \sigma σ
- 在重复该过程 q q q 次后, 该敌手 A \mathcal{A} A 能输出一个 ( m ∗ , σ ∗ ) (m^{}, \sigma^{}) (m∗,σ∗), 且 V r f y ( m ∗ , σ ∗ ) = 1 \mathtt{Vrfy}(m^{}, \sigma^{})=1 Vrfy(m∗,σ∗)=1, 而且 m ∗ m^{*} m∗ 从未被 A \mathcal{A} A 提交过.
这样就构造好了我们假设存在的敌手了. 因为我们这里不涉及任何具体的算法描述, 所以上述能力描述其实适用于绝大多数签名算法. 那么, 对于 B
\mathcal{B} B, 它的能力描述也是类似的.
构造敌手B
对于Step 2, 我们构造一个目标是攻破 S \mathcal{S} S 签名方案 EUF-CMA 安全性的敌手 B \mathcal{B} B,
与敌手 A \mathcal{A} A 类似, 其示意图如下所示.

而该敌手的能力可以归结为:
- 向实现了 S \mathcal{S} S 的签名oracle提交消息 m m m, 并获得对应的签名 σ \sigma σ
- 在重复该过程 q q q 次后, 该敌手 B \mathcal{B} B 能输出一个 ( m ∗ , σ ∗ ) (m^{}, \sigma^{}) (m∗,σ∗), 且 V r f y ( m ∗ , σ ∗ ) = 1 \mathtt{Vrfy}(m^{}, \sigma^{})=1 Vrfy(m∗,σ∗)=1, 而且 m ∗ m^{*} m∗ 从未被 B \mathcal{B} B 提交过.
归约
对于Step 3, 由于我们假设了敌手 A \mathcal{A} A 能攻破方案 S ′ \mathcal{S’} S′, 因此 B
\mathcal{B} B 可将 A \mathcal{A} A 作为子程序 调用, 来为 A \mathcal{A} A 模拟方案 S ′
\mathcal{S’} S′:
- A \mathcal{A} A 面对着 B \mathcal{B} B 为它模拟出的方案 S ′ \mathcal{S’} S′ 的交互环境; 因此 A \mathcal{A} A 提交 m m m 给模拟出的签名oracle S i g n ′ \mathtt{Sign’} Sign′;
- B \mathcal{B} B 收到 m m m 后, 使用哈希函数 H H H 计算 h m = H ( m ) hm=H(m) hm=H(m), 并提交 h m hm hm 给它自己挑战者提供的 S \mathcal{S} S 的签名oracle S i g n \mathtt{Sign} Sign;
- 当 B \mathcal{B} B的挑战者返回签名后的消息 σ \sigma σ后, 敌手 B \mathcal{B} B毫无保留地直接 将 σ \sigma σ传给敌手 A \mathcal{A} A, 来作为其以为的方案 S ′ \mathcal{S’} S′对应的签名.
因为 σ = S i g n ( H ( m ) ) = S i g n ′ ( m )
\sigma=\mathtt{Sign}(H(m))=\mathtt{Sign’}(m) σ=Sign(H(m))=Sign′(m), 所以敌手 B
\mathcal{B} B 为敌手 A \mathcal{A} A 营造出的方案 S ′ \mathcal{S’} S′ 的Oracle与真实的 S
′ \mathcal{S’} S′ 是相同的. 也就是对于每次返回的签名 σ \sigma σ, A \mathcal{A} A 都有 V r f y
′ ( m , σ ) = 1 \mathtt{Vrfy’}(m, \sigma)=1 Vrfy′(m,σ)=1 !
上述步骤重复若干次 (比如 q q q 次) 后, 根据假设, A \mathcal{A} A 应该能正确输出一对 ( m ∗ , σ ∗ )
(m^{}, \sigma^{}) (m∗,σ∗) 使得 V r f y ( m ∗ , σ ∗ ) = 1 \mathtt{Vrfy}(m^{},
\sigma^{})=1 Vrfy(m∗,σ∗)=1. 那么, B \mathcal{B} B 在捕捉到该输出后, 直接计算 h m ∗ = H (
m ∗ ) hm{*}=H(m{}) hm∗=H(m∗), 并输出 ( h m ∗ , σ ∗ ) (hm^{}, \sigma^{})
(hm∗,σ∗). (这里的 σ ∗ \sigma^{} σ∗ 就是 A \mathcal{A} A 的输出). 根据 S ′
\mathcal{S’} S′ 与 S \mathcal{S} S 二者之间的关系, 同样也有 V r f y ( h m ∗ , σ ∗ ) = 1
\mathtt{Vrfy}(hm^{}, \sigma^{})=1 Vrfy(hm∗,σ∗)=1. 最终, B \mathcal{B} B 根据 A
\mathcal{A} A 的能力成功地伪造了方案 S \mathcal{S} S 的签名, 也就是成功地将方案 S ′ \mathcal{S’} S′
的安全性归约到了 S \mathcal{S} S 的安全性上!
🔑 为了突出重点, 上述步骤没有包含 S \mathcal{S} S 与 S ′ \mathcal{S’} S′ 公私钥的生成与分配, 实际上模拟
S ′ \mathcal{S’} S′ 的签名私钥可由B任意选取, S \mathcal{S} S 的私钥则由B的挑战者选取.
至此, 相信你已经基本明白密码学可证明安全中的归约技术是怎么一回事了. 尽管在现有密码学研究中可证明安全理论也在日益发展,
但其核心思想都逃不过归约这种基础的证明范式. 究其根源, 也在于密码学里的安全性证明本就是建立在开头提到的 N P ≠ P NP \neq P NP=P
问题上, 证明时也只能基于单个假设来证明具体的安全能力.
基于模拟的安全性证明
目前, 我们给出的例子都是在讲解如何证明一个密码算法的安全性, 可问题来了, 密码学方案里并非只有密码算法, 还有各种巧妙有趣的密码协议
(Protocol), 比如零知识证明 (Zero Knowledge Proof), 秘密共享 (Secret Sharing), 安全多方计算
(Multi-Party Computation) 等. 那这些方案的安全性该如何证明呢 ?
协议的安全性证明一般是基于模拟 (Simulation) 的思想, 而模拟这一词在上面其实已经出现过了. 在上面的例子中, 敌手 B
\mathcal{B} B 为敌手 A \mathcal{A} A 所创造出的方案 S ′ \mathcal{S’} S′ 交互环境, 实际上就是 B
\mathcal{B} B 为 A \mathcal{A} A 模拟 出来的.

这也就是说, 敌手 A \mathcal{A} A 此时并不是在现实世界 (real world) 中与方案 S ′ \mathcal{S’} S′
交互, 而是在 B \mathcal{B} B 为其打造的一个理想世界 (ideal world) 中. 通过恰当的手段, B \mathcal{B}
B 就能将这一理想世界变得对 A \mathcal{A} A 而言无法与现实世界区分. 在密码协议中也是如此,
下面通过一个小例子来进一步解释模拟这个概念.
一个小例子
我们还是使用熟悉的密码算法来介绍, 来现有一对称加密方案 π = ( G , E , D ) \pi=(\mathcal{G}, \mathcal{E},
\mathcal{D}) π=(G,E,D), 其中 G ( 1 n ) \mathcal{G}(1^{n}) G(1n) 是密钥生成算法, E , D
\mathcal{E, D} E,D 分别是加解密算法. 我们以下定理为基础, 介绍模拟是怎么一回事.
如果对于任意PPT敌手 A \mathcal{A} A, 都存在另外一个PPT敌手 A ′ \mathcal{A’} A′, 如果下式成立的话,
则称方案 π \pi π 是语义安全的:
P r [ A ( 1 n , E k ( ⋅ ) , h ( 1 n ) ) = f ( 1 n ) ] < P r [ A ′ ( 1 n , h (
1 n ) ) = f ( 1 n ) ] + ϵ ( n ) \mathrm{Pr}\left[\mathcal{A}(1^{n},
E_{k}(\cdot), h(1^{n})) = f(1^{n})\right] <
\mathrm{Pr}\left[\mathcal{A’}(1^{n}, h(1^{n})) = f(1^{n})\right] + \epsilon(n)
Pr[A(1n,Ek(⋅),h(1n))=f(1n)]<Pr[A′(1n,h(1n))=f(1n)]+ϵ(n)
其中,
- E k ( ⋅ ) E_{k}(\cdot) Ek(⋅) 表示使用加密算法 E E E 与密钥 k k k 得到的一真实密文
- h ( 1 n ) h(1^{n}) h(1n) 表示泄露给外界的加密明文的冗余信息, 比如这条明文被发了几次, 从哪里发送的等等. 注意冗余信息 h h h并不包含明文本身的内容.
- f ( 1 n ) f(1^{n}) f(1n) 表示关于明文的某个函数, 比如通过 f f f就能知道任意明文第几位是0还是1, 第一字节的汉明重量等等. f f f表示了能从明文中获取的除了冗余信息与明文长度之外的其他任意信息.
这个定理也就是说, 如果一个加密方案是语义安全的, 那么这里的敌手 A \mathcal{A} A 无法比 A ′ \mathcal{A’} A′
获取更多的信息, 即密文不会泄露关于明文的其他任何信息. 那么, 我们该如何通过模拟的手段证明一个加密方案 π \pi π 是满足这个定理的呢 ?
实际上, 这里两个敌手的设定已经暗含了模拟的思想. 下面我们直接给出基于模拟的证明思路. 令一 Simulator (模拟器) A ′
\mathcal{A’} A′ 收到安全参数 1 n 1^{n} 1n 后, 按步骤运行以下算法
- A ′ \mathcal{A’} A′ 运行密钥生成算法 G \mathcal{G} G 获得密钥 k k k;
- A ′ \mathcal{A’} A′ 计算 c = E k ( 0 n ) c=\mathcal{E}_{k}(0^{n}) c=Ek(0n), 即明文 0 n 0^{n} 0n 对应的密文
- A ′ \mathcal{A’} A′ 将 A \mathcal{A} A 作为子程序调用, 即运行 A ( 1 n , c , h ( 1 n ) ) \mathcal{A}(1^{n}, c, h(1^{n})) A(1n,c,h(1n))
诶这个结构我们是不是刚在上一节的归约那里见过 ? 没错, 只不过这里我们并不强调二者间的归约关系, 而是侧重模拟器 A ′ \mathcal{A’} A′
是否能为 A \mathcal{A} A 完美模拟出一个算法环境. 这里答案当然是不能的. 因为 A ′ \mathcal{A’} A′
返回的并不是真实明文对应的密文嘛, 而是始终都返回 0 n 0^{n} 0n 对应的密文.
因此, 如果 A \mathcal{A} A 有能力区分输出 “garbage text” (即 E k ( 0 n )
\mathcal{E}{k}(0^{n}) Ek(0n) ) 与真实密文, 那也就说明 A \mathcal{A} A 并不会在给予 c c c
时输出 f ( 1 n ) f(1^{n}) f(1n) (因为并不是完美地模拟); 而如果 A \mathcal{A} A 无法区分, 那么它输出
f ( 1 n ) f(1^{n}) f(1n) 的概率应该在跟给予 c c c 或 E k ( ⋅ ) E{k}(\cdot) Ek(⋅)
时是一样的. 依据这种概率上的差异, Simulator 通过观察在模拟出的方案执行过程中的敌手输出, 就能得出方案安全性假设的结论, 最终完成证明.
而最后证明的那一步其实也是采取了归约的思路, 但这里是在模拟 的设定下进行了归约. 也就是说,
基于模拟的证明需要小心仔细地设计如何构造一个模拟的环境 , 而归约只是证明过程最后的临门一脚.
设计整个模拟的环境才是基于模拟的安全性证明中最重要的地方.
😳 这一节只是简单介绍模拟的思想, 并没有结合具体的密码协议介绍模拟技术, 因为这需要引入新的敌手模型 (诚实, 半诚实, 恶意) 与 协议类型
(两方/多方下的不经意传输, 承诺, 零知识证明等). 有兴趣的读者可以阅读 Lindell
关于模拟技术的Tutorial
安全性证明技术分类
至此我们初步介绍了基于归约和基于模拟的安全证明技术的原理. 在整个密码学安全证明领域, 其实还有不少技术, 下面进行简单总结:
- 归约 (Reduction) 证明
- 模拟 (Simulation) 证明
- 基于若干交互游戏的证明 (Game-based Proof)
- 通用可组合证明 (Universally Composable, UC)
- H H H-coefficient 技术 (区分随机变量)
- χ 2 \chi^{2} χ2 技术 (信息论不可区分性)
这里罗列的这些技术之间在证明逻辑上互有交叉重叠, 例如UC证明其实就相当于传统模拟证明的升级版. 而我们最需要理解和掌握的就是前面两种最基本的证明技术,
在学习了相关数学工具和抽象方法后, 其他证明技术也能很快理解.
总结
本文初步介绍了密码学中的可证明安全技术, 阐述了安全性证明的基本逻辑, 并针对基于归约和基于模拟的证明技术给出了三个示例.
本文仅仅是可证明安全这一话题的初步介绍, 作为一个有严肃数学理论和计算复杂性理论支撑的细分领域, 如果需要真正掌握并运用这些证明技术,
依然需要从各种经典与前沿论文出发, 不断学习和推演.
以上就是本文的全部内容, 感谢你的阅读, 欢迎你的建议 ! 最后以一句歌词作为结束:
“惊天动地只可惜天地亦无情,不敢有风不敢有声,这爱情无人证” ——陈奕迅《无人之境》
学习计划安排
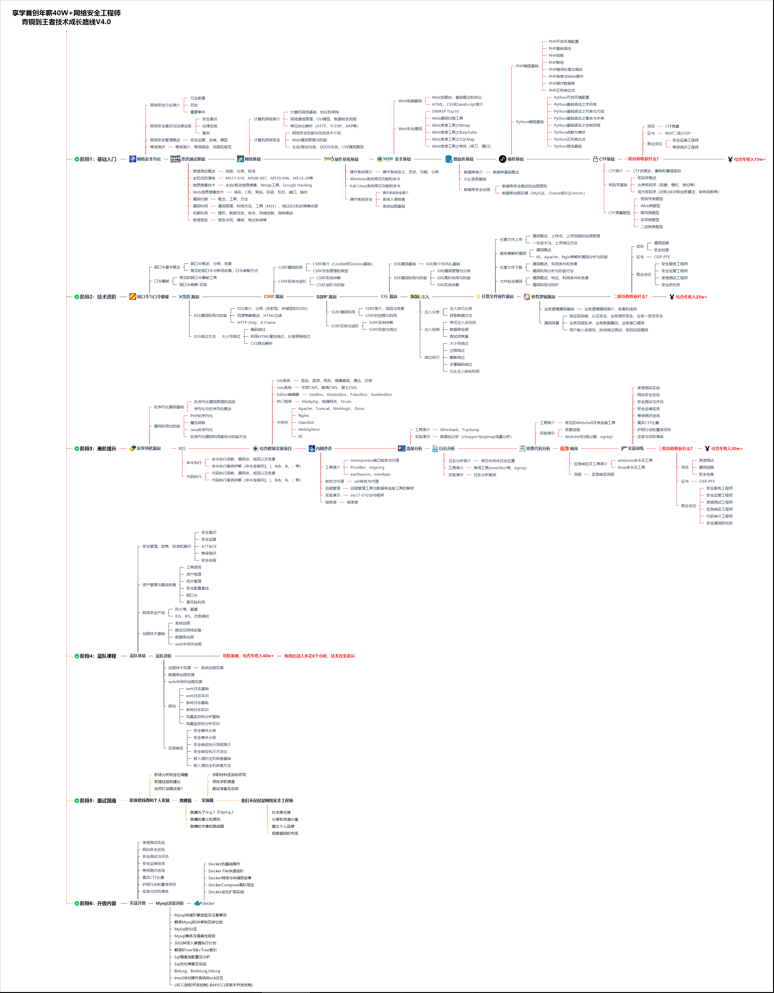
我一共划分了六个阶段,但并不是说你得学完全部才能上手工作,对于一些初级岗位,学到第三四个阶段就足矣~
这里我整合并且整理成了一份【282G】的网络安全从零基础入门到进阶资料包,需要的小伙伴可以扫描下方CSDN官方合作二维码免费领取哦,无偿分享!!!
如果你对网络安全入门感兴趣,那么你需要的话可以
点击这里👉网络安全重磅福利:入门&进阶全套282G学习资源包免费分享!
①网络安全学习路线
②上百份渗透测试电子书
③安全攻防357页笔记
④50份安全攻防面试指南
⑤安全红队渗透工具包
⑥HW护网行动经验总结
⑦100个漏洞实战案例
⑧安全大厂内部视频资源
⑨历年CTF夺旗赛题解析
















 882
882











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









