







一、为什么要有垃圾回收机制?
我们由C语言中的动态内存管理来引入,malloc申请内存,free释放内存。
此处用 malloc 申请到的内存,生命周期是跟随整个进程的。这一点对于服务器程序非常不友好。服务器每个请求都去 malloc 一块内存,如果不 free 释放,就会使申请到的内存越来越多,后续想要申请内存就没有内存可申请了,这就是内存泄漏问题。
实际开发中,很容易出现 free 不小心就忘记调用了,或者因为一些情况没有执行到(函数中间存在 if -> return 或者 抛出异常了)。
那能否让释放内存的操作,由程序自动负责完成呢?
java 就属于早期就支持 垃圾回收 的语言了。引入垃圾回收机制之后,就不需要靠手动来释放内存了,程序会自动判定某个内存是否会继续使用,如果后续不再使用了,就会自动释放掉。
二、垃圾回收的主要内存区域
垃圾回收,就是回收内存 。
我们之前有说到内存区域划分,JVM中的内存分为好几块:
- 程序计数器:不需要垃圾回收(GC)
- 栈:不需要GC,局部变量都是在代码块执行结束后自动销毁(栈自身的特点,和垃圾回收没关系)
- 元数据区/方法区:一般不需要GC
- 堆:GC的主要“战场”
所以说,垃圾回收 回收的主要是 堆 这块内存区域。
三、垃圾回收过程
垃圾回收需要:
- 识别出垃圾:哪些对象是垃圾(不再使用),哪些对象不是垃圾
- 把标记为垃圾的对象的内存空间进行释放
1、识别出垃圾
判定这个对象后续是否还要继续使用。
在Java中,使用对象一定是要通过引用的方式来使用(例外,匿名对象,如 new MyThread().start(); 但是,当这行代码执行完,对应的MyThread对象就会被当做垃圾)。
如果一个对象没有任何引用指向它,就视为是无法被代码中使用,就可以作为垃圾了。
举例:
void func() {
Test t = new Test();
}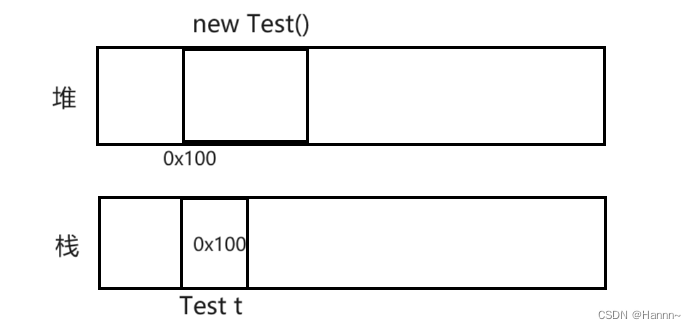
上述代码通过 new Test() 在堆上创建了对象,存储在 栈 中的局部变量 t 保存了对象的地址。当代码执行到最后的 } 之后,局部变量 t 就直接释放了,上述 new Test() 对象也就没有引用再指向它,此时,这个代码就无法访问使用这个对象了,该对象就是垃圾了。
如果代码更复杂些,如:
Test t1 = new Test();
Test t2 = t1;
Test t3 = t2;
Test t4 = t3;
此时就会有很多的引用指向new Test()对象。此时通过任意的引用都能访问到该对象,需要确保所有的指向该对象的引用都销毁了,才能把 Test 对象是为垃圾。
1.1 引用计数算法
这种思想方法,给每个对象安排一个额外的空间,空间里要保存当前这个对象有几个引用。此时垃圾回收机制,有专门的扫描线程,去获取到当前每个对象的引用计数情况,发现对象的引用计数为0,说明这个对象就可以被视为垃圾,进行释放了。
例子:
Test a = new Test();
Test b = a;
a = null;
b = null;当执行完这4行代码,堆栈的情况如下:
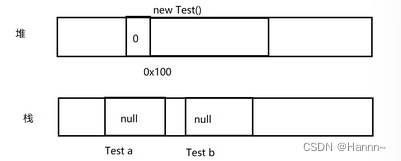
此时 Test 对象的引用计数为 0,就可被视为垃圾。
引用计数算法是一个简单有效的算法,但存在两个关键问题:
问题一:消耗额外的内存空间
要给每个对象都安排一个计数器。如果计数器按照 2 个字节来算,整个程序中的对象数目很多的话,总的消耗的空间也会非常多。 尤其是如果每个对象的体积比较小(假设每个对象 4 个字节),那么此时计数器消耗的空间,已经达到了对象的空间的一半。
问题二:引用计数可能会产生 “循环引用” 问题,此时引用计数算法就无法正确工作了
如下代码:
class Test{
Test t;
}
Test a = new Test();
Test b = new Test();
a.t = b;
b.t = a;
a = null;
b = null;执行完上述几行代码之后,堆栈情况:

可见两个对象的引用计数都不为0,不能被垃圾回收机制回收掉!但是这两个对象又无法使用了。这就是引用计数存在的问题。
1.2 可达性分析算法
JVM自身知道一共有哪些对象,通过可达性分析的遍历(JVM中存在扫描线程,会不停地尝试对代码中已有的这些变量,进行遍历,尽可能多的去访问到对象),把可达的对象都标记出来,剩下的自然就是不可达的。
我们通过构造一个二叉树来理解:
class Node{
char val;
Node left;
Node right;
}
Node buildTree() {
Node a = new Node();
Node b = new Node();
Node c = new Node();
Node d = new Node();
Node e = new Node();
Node f = new Node();
Node g = new Node();
a.left = b;
a.right = c;
b.left = d;
b.right = e;
e.left = g;
c.right = f;
return a;
}
Node root = bulidTree();这个代码中只有一个 root 这样的引用,但实际上上述七个节点对象都是“可达”的。

上述代码,如果执行这个代码:root. right.right = null; 此时 f 这个对象就被“孤立”了。按照上述从 root 出发进行遍历的操作,就无法访问到 f 了,f 这个节点就是“不可达”的了。
如果代码中出现: root.right = null; 此时 c 就不可达了,而 f 的访问必须通过 c ,因此 c 不可达也导致了 f 的不可达,此时节点 c 和 f 都是垃圾了。
2、 垃圾回收算法
通过上面介绍,我们已经知道了如何判断出对象是否为垃圾,下面我们就来看看识别出这些垃圾之后,如何回收它们( 将垃圾对象的内存空间进行释放)。
2.1 标记-清除算法
- 效率问题 : 标记和清除这两个过程的效率都不高
- 空间问题 : 标记清除后会产生大量不连续的内存碎片,空间碎片太多可能会导致以后在程序运行中需要分配较大对象时,无法找到足够连续内存而不得不提前触发另一次垃圾收集。

2.2 复制算法
"复制"算法是为了解决"标记-清理"的效率问题。它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这块内存需要进行垃圾回收时,会将此区域还存活着的对象复制到另一块上面,然后再把已经使用过的内存区域一次清理掉。
这样做的好处是每次都是对整个半区进行内存回收,内存分配时也就不需要考虑内存碎片等复杂情况,只需要移动堆顶指针,按顺序分配即可。此算法实现简单,运行高效。

复制算法的不足之处:
- 总的可用内存变少了,因为将可用内存按容量划分为大小相等的两块,每次只使用其中的一块
- 如果每次要复制的对象比较多,此时复制开销也就大了
对于大部分对象需要释放,少数对象存活的情况适合复制算法。
2.3 标记-整理算法
这种思想类似于顺序表删除中间元素,后面要进行搬运。

2.4 分代回收算法
哪些对象会进入新生代?哪些对象会进入老年代?
- 新生代:⼀般创建的对象都会进入新生代;
- 老年代:大对象和经历了 N 次(⼀般情况默认是 15 次)垃圾回收依然存活下来的对象会从新生代移动到老年代。
下面我们引入对象的年龄,来理解分代算法: JVM中有专门的线程负责周期性扫描,一个对象如果被线程扫描了一次,就说明是可达的,年龄就加 1 (初始年龄为0)。JVM根据对象年龄的差异,把整个堆内存分为两大部分:新生代和老年代。

- 当代码中 new 出来一个新的对象,该对象就是被创建在伊甸区的,伊甸区中就会有很多对象。 伊甸区中的对象大部分是活不过第一轮GC的,它们的生命周期非常短。
- 第一轮 GC 扫描完成之后,少数伊甸区中幸存的对象,就会通过复制算法,拷贝到生存区。后续 GC 的扫描线程还会持续进行扫描,不仅要扫描伊甸区的对象,还要扫描生存区对象。生存区中的大部分对象也会在扫描中被标记为垃圾,少数存活的,就会继续用复制算法,拷贝到另一个生存区。每经过一轮GC 扫描,对象的年龄都会加 1 。
- 如果这个对象在生存区中,经历了若干轮 GC ,仍然健在,JVM 就会认为这个对象的生命周期大概率很长,就把这个对象从生存区拷贝到老年代了。
- 老年代的对象也要被 GC 进行扫描,但是扫描的频次就大大降低了。
- 对象在老年代成为垃圾之后,JVM 就会按照标记-清除 或 标记-整理的方式释放内存。
Minor GC和Full GC,这两种GC有什么不⼀样?
- Minor GC,又称为新生代GC : 指的是发生在新生代的垃圾收集。因为Java对象大多都具备朝生夕灭的特性,因此Minor GC(采用复制算法)非常频繁,⼀般回收速度也比较快。
- Full GC,又称为老年代GC或者Major GC : 指发生在老年代的垃圾收集。出现了Major GC,经常会伴随至少一次的Minor GC(并非绝对,在Parallel Scavenge收集器中就有直接进行Full GC的策略选择过程)。Major GC的速度⼀般会比Minor GC慢10倍以上。
四、垃圾回收器
垃圾收集器的作用:垃圾收集器是为了保证程序能够正常、持久运行的⼀种技术,它是将程序中不用 的死亡对象也就是垃圾对象进行清除,从而保证了新对象能够正常申请到内存空间。
以下这些收集器是 HotSpot 虚拟机随着不同版本推出的重要的垃圾收集器:

这里对于垃圾收集器就不多介绍了。














 4668
4668











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









