









可参考博客
推荐系统 - 随笔分类 - 深度机器学习 - 博客园 (cnblogs.com)
SIGIR 2022 | 推荐系统相关论文分类整理 - 知乎 (zhihu.com)
推荐系统
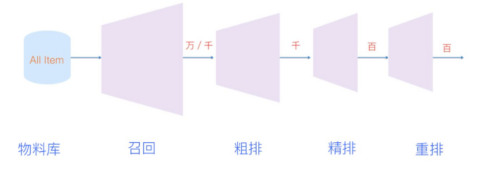
一般来说推荐系统分为以下几个主要模块:
- 推荐池:一般会基于一些规则,从整体物料库(可能会有几十亿甚至百亿规模)中选择一些item进入推荐池,再通过汰换规则定期进行更新。比如电商平台可以基于近30天成交量、商品在所属类目价格档位等构建推荐池,短视频平台可以基于发布时间、近7天播放量等构建推荐池。推荐池一般定期离线构建好就可以了。
- 召回:从推荐池中选取几千上万的item,送给后续的排序模块。由于召回面对的候选集十分大,且一般需要在线输出,故召回模块必须轻量快速低延迟。由于后续还有排序模块作为保障,召回不需要十分准确,但不可遗漏(特别是搜索系统中的召回模块)。目前基本上采用多路召回解决范式,分为非个性化召回和个性化召回。个性化召回又有content-based、behavior-based、feature-based等多种方式。
- 粗排:获取召回模块结果,从中选择上千item送给精排模块。粗排可以理解为精排前的一轮过滤机制,减轻精排模块的压力。粗排介于召回和精排之间,要同时兼顾精准性和低延迟。一般模型也不能过于复杂。
- 精排:获取粗排模块的结果,对候选集进行打分和排序。精排需要在最大时延允许的情况下,保证打分的精准性,是整个系统中至关重要的一个模块,也是最复杂,研究最多的一个模块。精排系统构建一般需要涉及样本、特征、模型三部分。
- 重排:获取精排的排序结果,基于运营策略、多样性、context上下文等,重新进行一个微调。比如三八节对美妆类目商品提权,类目打散、同图打散、同卖家打散等保证用户体验措施。重排中规则比较多,但目前也有不少基于模型来提升重排效果的方案。
- 混排:多个业务线都想在Feeds流中获取曝光,则需要对它们的结果进行混排。比如推荐流中插入广告、视频流中插入图文和banner等。可以基于规则策略(如广告定坑)和强化学习来实现。
召回
召回模块面对几百上千万的推荐池物料规模,候选集十分庞大。由于后续有排序模块作为保障,故不需要十分准确,但必须保证不要遗漏和低延迟。
详细解读!推荐算法架构——召回 - 腾讯云开发者社区-腾讯云 (tencent.com)
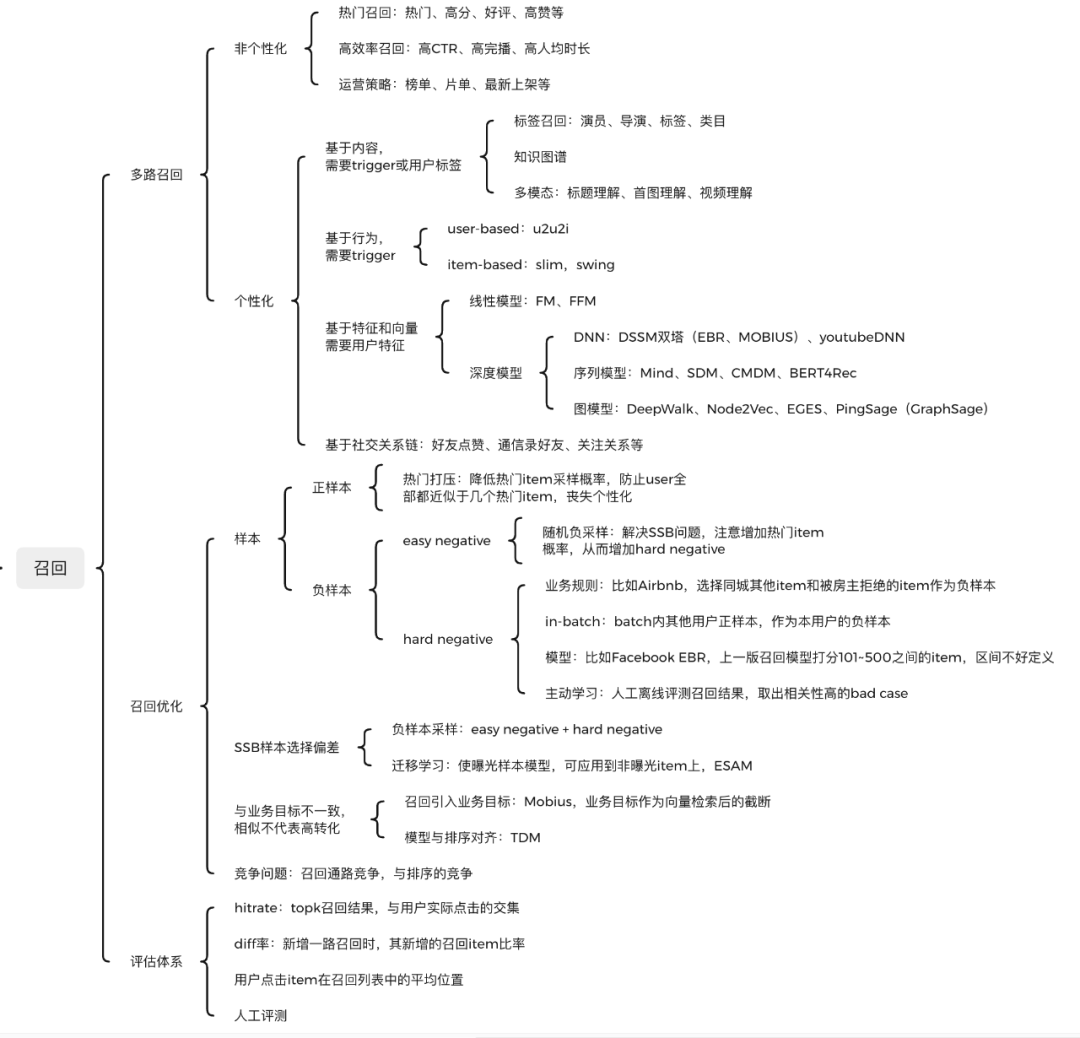
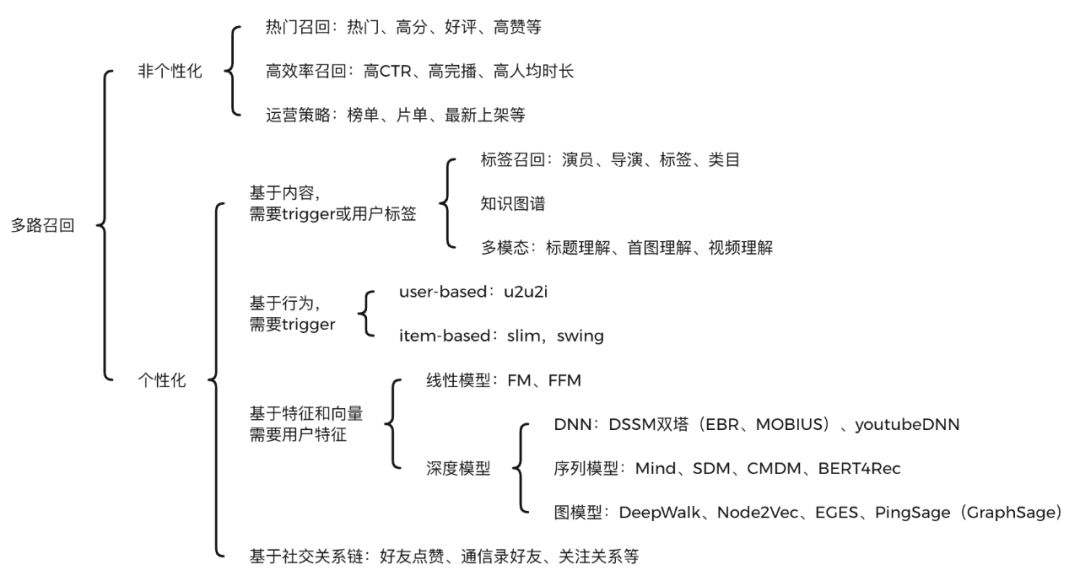
目前主要通过多路召回来实现,一方面各路可以并行计算,另一方面取长补短。召回通路主要有非个性化和个性化两大类。
- 非个性化召回与用户无关,可以离线构建好。
- 个性化召回与用户相关,千人千面。
召回中主要有哪些问题呢,主要有:
- 负样本构建问题:召回是样本的艺术,排序是特征的艺术,这句话说的很对。召回正样本可以选择曝光点击的样本,但负样本怎么选呢?选择曝光未点击的样本吗,肯定不行。
- 曝光未点击样本,能从已有召回、粗排、精排模块中竞争出来,说明其item质量和相关性都还是不错的,作为召回负样本肯定不合适。
- SSB问题,召回面向的全体推荐池,但能得到曝光的item只是其中很小的子集,这样构建负样本会导致十分严重的SSB(sample selection bias)问题,使得模型严重偏离实际。

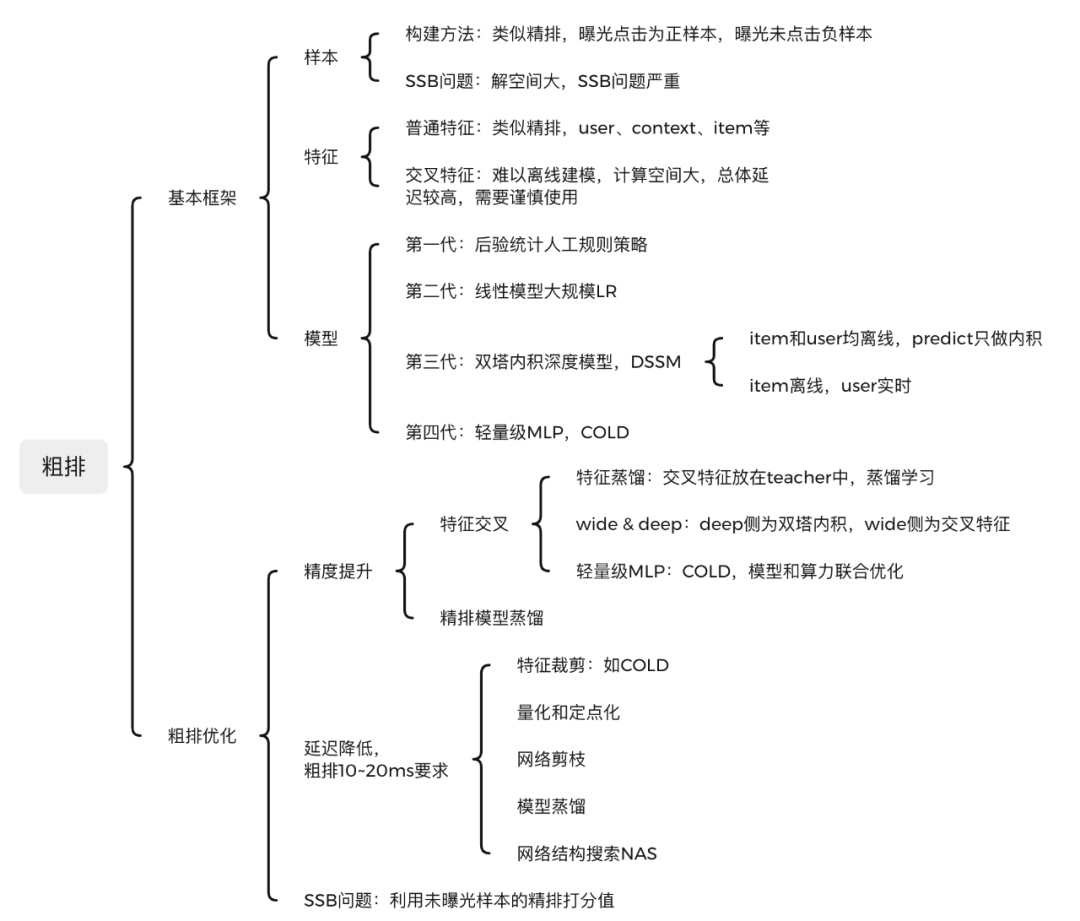
粗排
粗排是介于召回和精排之间的一个模块。它从召回获取上万的候选item,输出几百上千的item给精排,是典型的精度与性能之间trade-off的产物。目前粗排一般模型化了,基本框架也是包括数据样本、特征工程、深度模型三部分。
粗排的几个主要问题:
- 精度和特征交叉问题:经典的DSSM模型优点很多,目前在粗排上广泛应用,其最核心的缺点就是缺乏特征交叉能力。正所谓成也萧何败萧何,正是由于user和item分离,使得DSSM性能很高。但反过来也是由于二者缺乏交叉,导致模型表达能力不足,精度下降。典型的精度和性能之间的trade-off。
- 低延迟要求:粗排延迟要求高,一般只有10ms~20ms,远低于精排的要求。
- SSB问题:粗排解空间比精排大很多,和精排一样只使用曝光样本,导致严重的样本选择偏差问题。
图文并茂!推荐算法架构——粗排 - 腾讯云开发者社区-腾讯云 (tencent.com)
精排
精排是整个推荐算法中比较重要的一个模块,目前基本都是基于模型来实现,涉及样本、特征、模型三部分。
图文解读:推荐算法架构——精排! - 腾讯云开发者社区-腾讯云 (tencent.com)
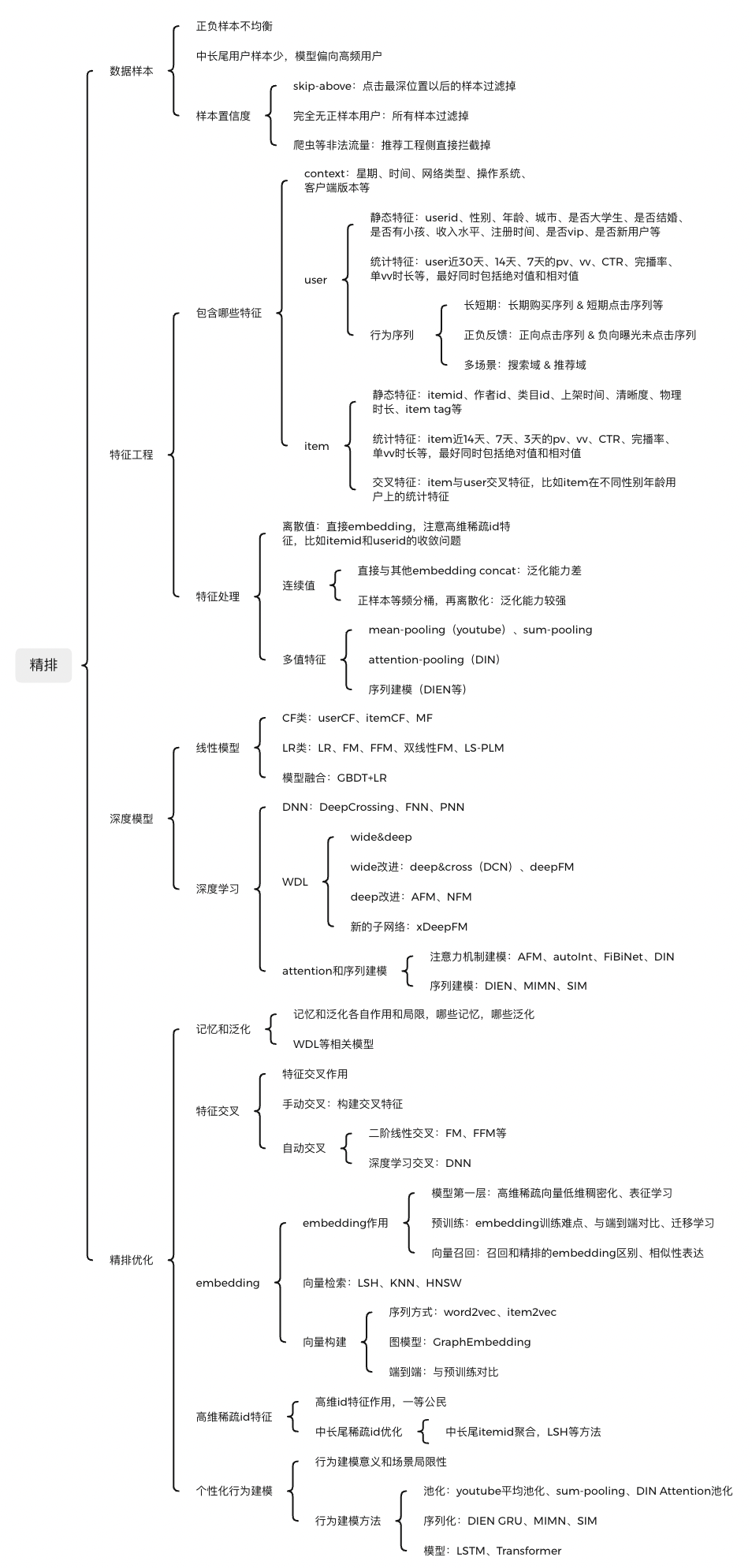
样本是模型的粮食,以CTR任务为例,一般用曝光点击作为正样本,曝光未点击作为负样本。样本方面主要问题有:
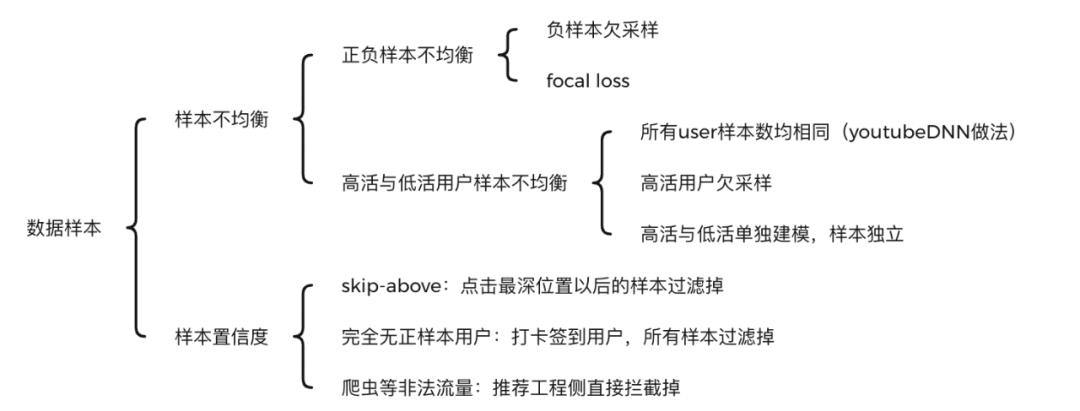
精排是特征的艺术,虽然特征工程远远没有深度模型那么fancy,但在实际业务中,基于特征工程优化,比基于模型更稳定可靠,且效果往往不比优化模型低。特征工程一定要结合业务理解,在具体业务场景上,想象自己就是一个实际用户,会有哪些特征对你是否点击、是否转化有比较大的影响。一般来说,可以枚举如下特征:
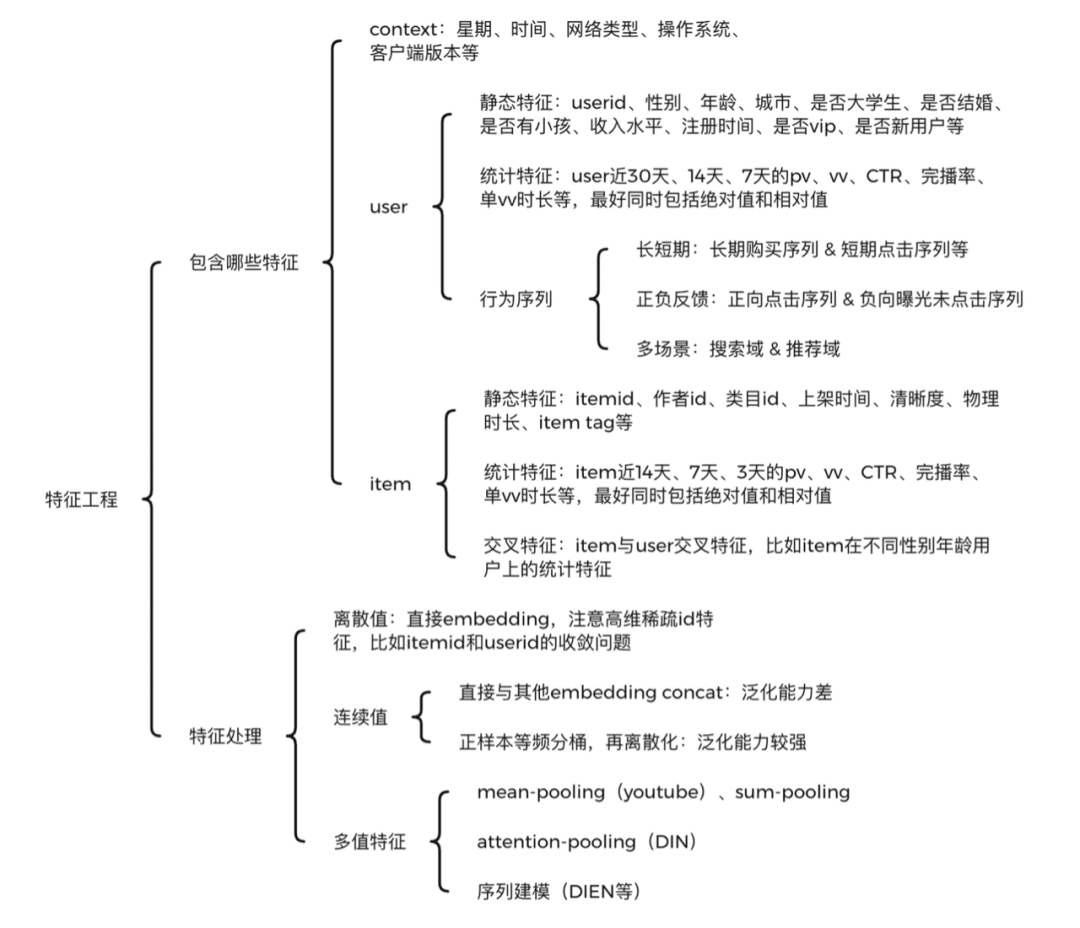
精排模型发展历程
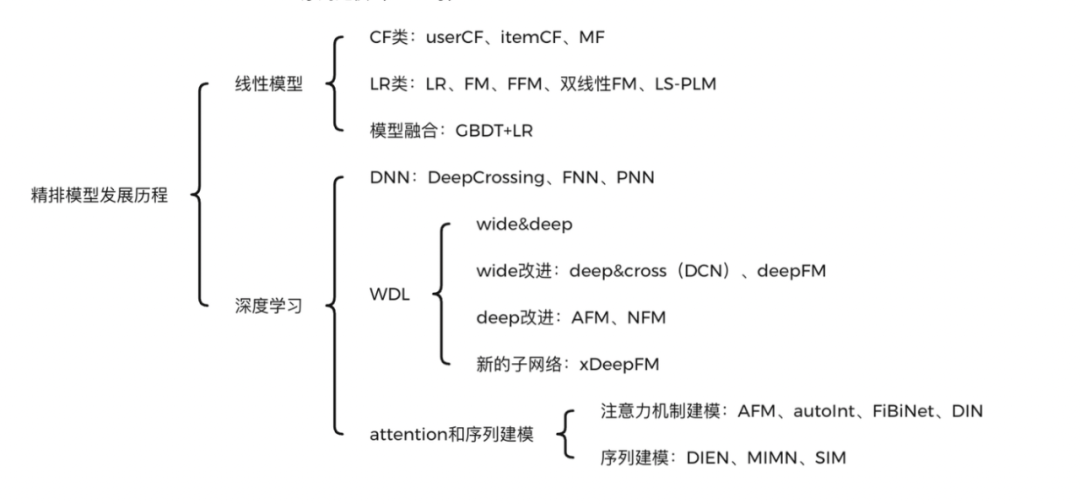
精排模型发展历程——线性模型
精排模型从线性时代,已经完全步入深度学习时代。线性时代主要有三大类:
- CF协同过滤类:比如userCF、itemCF、MF等。
- LR逻辑回归类:LR、FM、FFM、双线性FM、LS-PLM等。
- 多模型融合类:GBDT+LR。
- CF协同过滤类
精排模型发展历程——深度模型
主要分为三种范式:
- DNN类:DeepCrossing、FNN、PNN等
- Wide&Deep异构模型类:优化记忆和泛化问题,主要包括四大类:
- wide&deep:开启了异构模型时代,优化记忆和泛化问题。
- wide侧改进:deep&cross(DCN)、deepFM等。
- deep侧改进:AFM、NFM等。
- 加入新的子网络:xDeepFM等。
- Attention和序列建模类:
- 注意力机制建模:AFM、autoInt、FiBiNet、DIN等。
- 序列建模:DIEN、MIMN、SIM等。
- DNN类
- DeepCrossing
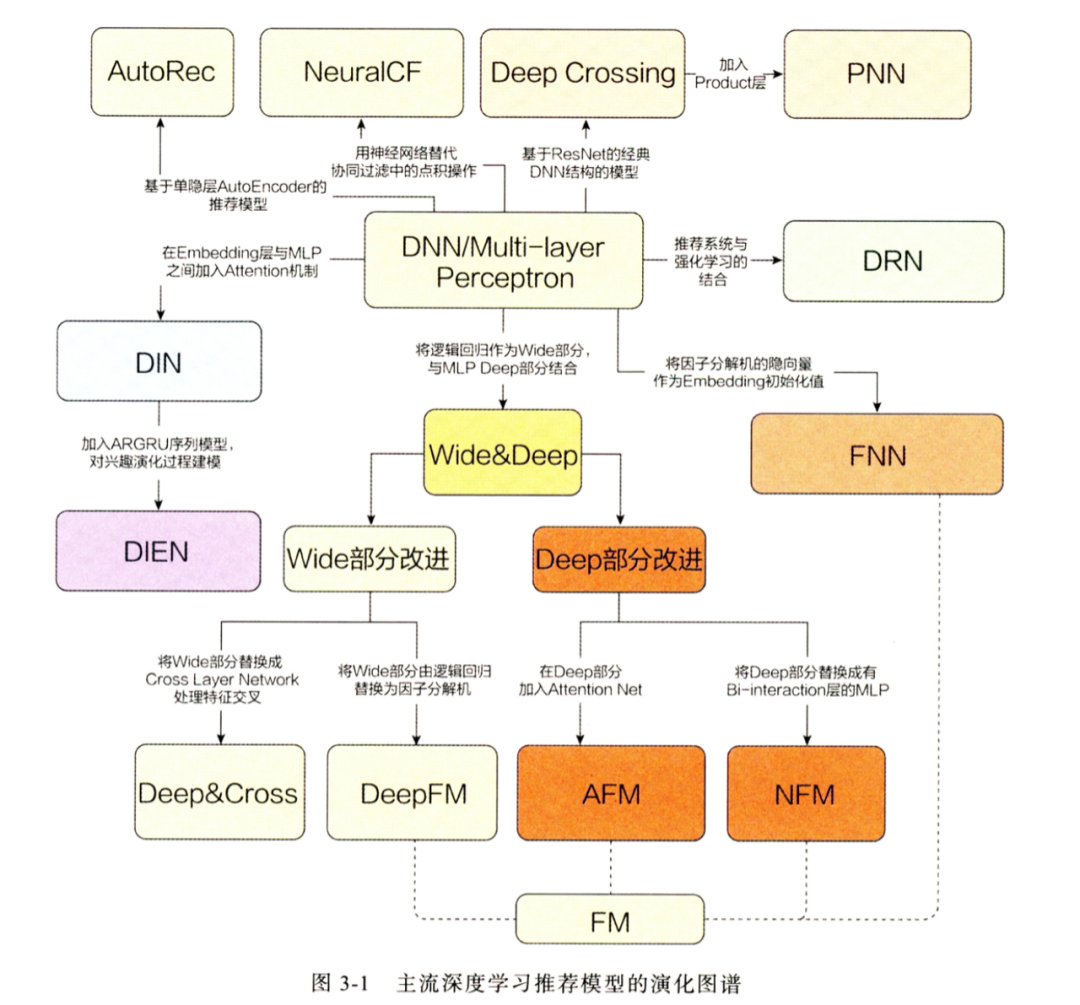
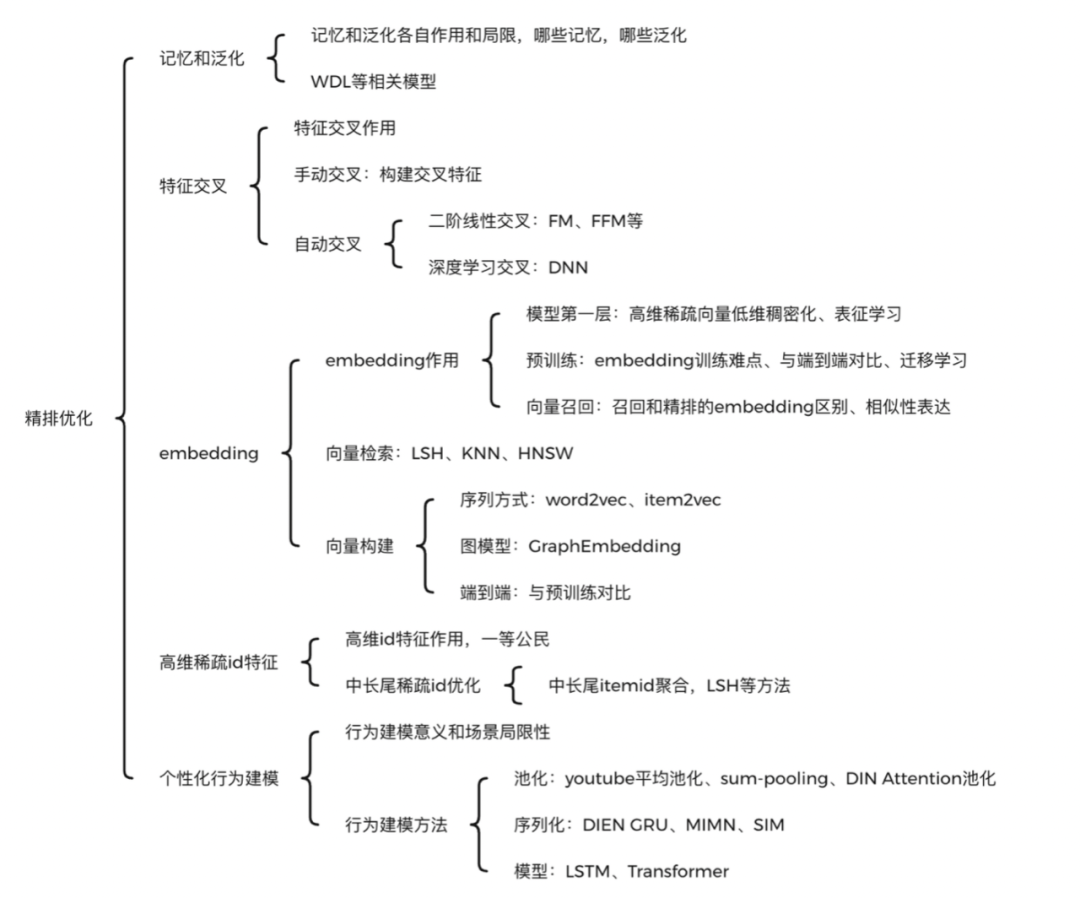
精排优化的方法和论文很多,一定要有一个全局架构认知,从而知晓每篇论文主要针对精排什么地方做的改进,类似的改进方案有哪些,各有什么优缺点。我认为万变不离其宗,主要就是五个方面的问题:
- 记忆和泛化:高频靠记忆,低频靠泛化,WDL类的异构模型主要就是为了解决这个问题。
- 特征交叉:包括手动交叉和自动交叉两类。特征工程中手动构造user和item交叉统计特征,就是手动交叉的典范,目前这种方法仍然使用很普遍。而自动交叉则可分为线性和深度模型两种。线性模型就是FM、FFM这种,深度模型则采用DNN进行特征交叉。
- embedding:embedding实现了高维稀疏向量的低维稠密化,作为精排模型的第一层,已经成为了基本范式。
- 高维稀疏id特征:高维id特征区分度很大,对模型贡献高,但它们一般都比较稀疏,特别是中长尾的item和user样本少,加上其embedding维度高,比较难收敛。高维稀疏id特征的收敛问题也是一个待优化的关键问题。
- 个性化行为建模:基于用户历史行为进行个性化推荐,是目前推荐算法的一大热点。行为序列如何建模是一个关键问题,multi-head attention和序列模型给出了各自解决方案。同时序列过长会导致计算和存储压力很大,带来线上延迟,MIMN和SIM对这方面有一定优化。
重排
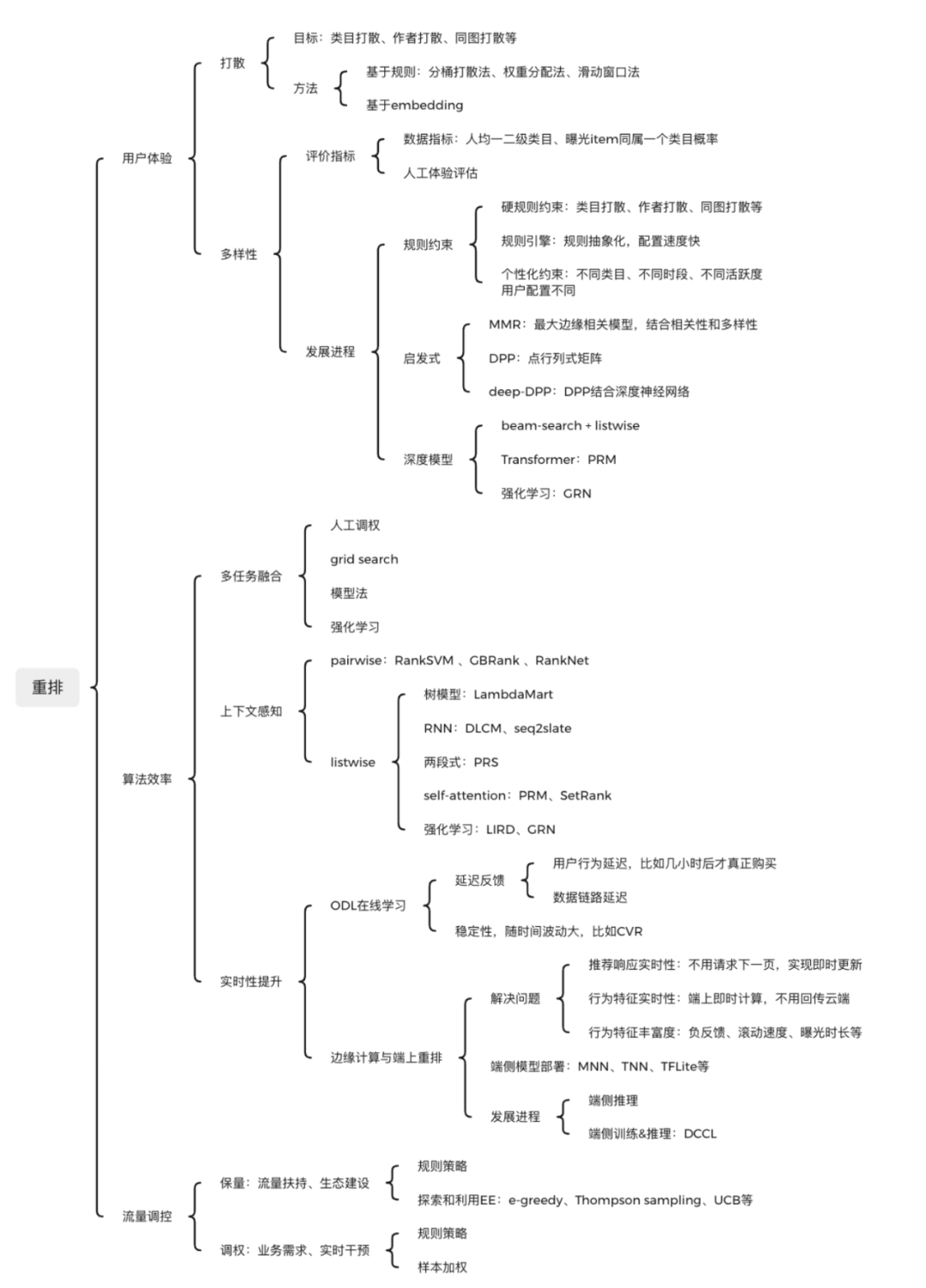
召回、精排、重排三个模块中,重排离最终的用户展现最近,所以也十分关键。重排的技术点也十分多,总结下来,个人认为重排主要是为了解决三大方面的问题:用户体验、算法效率、流量调控。
超强指南!推荐算法架构——重排 - 腾讯云开发者社区-腾讯云 (tencent.com)
用户体验
重排模块是推荐系统最后一个模块(可能还会有混排),离用户最近。作为最后一层兜底,用户体验十分重要。主要包括打散、多样性等内容。曝光过滤有时候也会放在重排中,但本质上完全可以在召回链路,对已充分曝光的短视频,或者刚刚已经购买过的商品,进行过滤,从而防止用户抵触。
打散:对同类目、同作者、相似封面图的item进行打散,可以有效防止用户疲劳和系统过度个性化,同时有利于探索和捕捉用户的潜在兴趣,对用户体验和长期目标都很关键。(分桶打散法、权重分配法)。
多样性:多样性会对用户体验、长期目标有比较关键的影响。
评价指标:1)数据指标分析:可以从user和item两个角度评估,比如平均每个用户的曝光一二级类目数,曝光item同属一个类目的概率等。可以从类目、作者、标签等多个维度进行数据分析和评价。2)人工评估:抽样进行人工体验,评估多样性。
发展进程:1)规则约束:基本都是基于规则,没有结合相关性来考虑多样性问题。2)启发式方法:多样性和相关性相结合的方法,充分保留相关性。3)深度模型:主要是加入了上下文感知,从而可以结合规则引擎实现多样性。
算法效率
重排对于提升算法准确率和效率,从而提升业务指标也十分关键。重排提升算法效率,主要分为三个方向:
- 多任务融合。精排输出的多个任务的分数,在重排阶段进行融合。可以基于人工调权、grid search、LTR或者强化学习。
- 上下文感知。精排由于计算性能因素,目前是基于point-wise的单点打分,没有考虑上下文因素。但其实序列中item的前后其他item,都对最终是否点击和转化有很大影响。context-aware的实现方式有pairwise、listwise、generative等多种方式。
- 实时性提升。重排比精排模型轻量化很多,也可以只对精排的topK重排,因此较容易实现在线学习(目前有一些团队甚至实现了精排在线学习)。实时性提升对于快速捕捉用户实时兴趣十分重要,能大大提升模型准确率和用户体验。通过ODL在线学习,实现重排模型实时更新,可以提升整体链路实时性。另外在端上部署模型,实现端上重排,也可以实现推荐的实时响应和特征的实时捕获。
流量调控
流量调控在推荐系统中也十分重要,重排在最后一环,责无旁贷。流量调控要兼顾实时性和准确性,二者之间需要达到平衡。流量调控的作用和方式主要有:
保量类:通过流量扶持,刺激生态建设。1)规则引擎:制订一定的策略规则,实现保量。这种方法简单易行,item也肯定能获得一定流量。但准确度较低,也较难实现个性化。流量容易不够或者超发。 2)探索和利用:通过e-greedy、Thompson sampling、UCB等EE类的方法,可以有效探索冷启item,同时利用已有item,保障效率折损最低。
调权类:一般是业务运营需求,需要快速实时干预。常见方法有:1) 规则引擎:直接在重排结果上,对于命中属性规则的item,加入一定的分数,使得最后可以透出,增加其流量。这种方法简单易行,实时性好。但调权准确率低,也较难个性化,可能造成较大的流量浪费和效率折损。适合某些时效要求高的场景。比如大促期间加权等。2)样本加权:对于命中调权规则的样本,增加其在loss中的权重,迫使模型偏向于对它们精准预估。这种方法可以实现个性化,对效率折损较低。但由于需要训练模型并重新上线,故实时性不高。适合某些长期性的调权场景。比如对大店、大V的加权等。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









