







去噪扩散模型DDPM去年开始在各种视觉任务取得惊人的效果,变化检测领域也不例外,本文介绍两篇关于如何使用扩散模型实现变化检测的论文。第一篇做法较为自然,先利用遥感数据预训练DDPM,然后将预训练好的网络当作变化检测任务的特征提取器;第二篇则更有意思,不再进行像素分类,而是直接利用扩散模型生成变化图。
- DDPM-CD: Denoising Diffusion Probabilistic Models as Feature Extractors for Change Detection, arXiv 2206
- GCD-DDPM: A Generative Change Detection Model Based on Difference-Feature Guided DDPM, TGRS 2024
DDPM-CD: Denoising Diffusion Probabilistic Models as Feature Extractors for Change Detection, arXiv 2206
论文:https://arxiv.org/abs/2206.11892
代码:https://github.com/wgcban/ddpm-cd
引言
动机:通过预训练的方式将扩散模型引进到变化检测任务当中。通过预训练去噪扩散概率模型DDPM,再将其用作变化检测应用的特征提取器。
贡献:
- 提出了一种新的遥感图像自监督表示学习方法,该方法从ddpm的扩散过程中学习鲁棒特征。
- ddpm可以从遥感图像中生成鲁棒和判别表示。
- 在从预训练的DDPM获得的多尺度特征表示的基础上微调轻量级变化检测分类器对于变化检测非常有效。
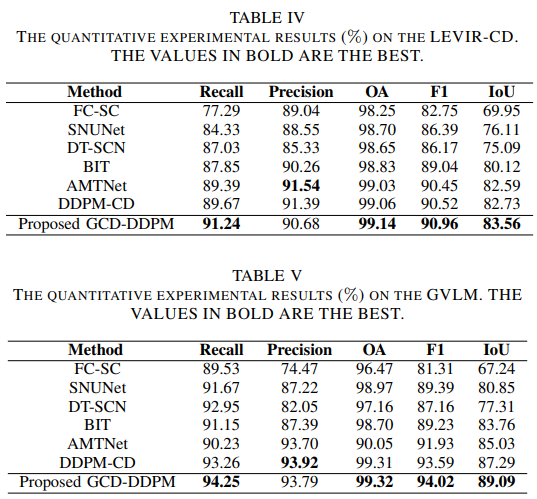
- 在LEVIR-CD、WHU-CD、DSIFN-CD和CDD四个变化检测数据集上取得好结果。
方法
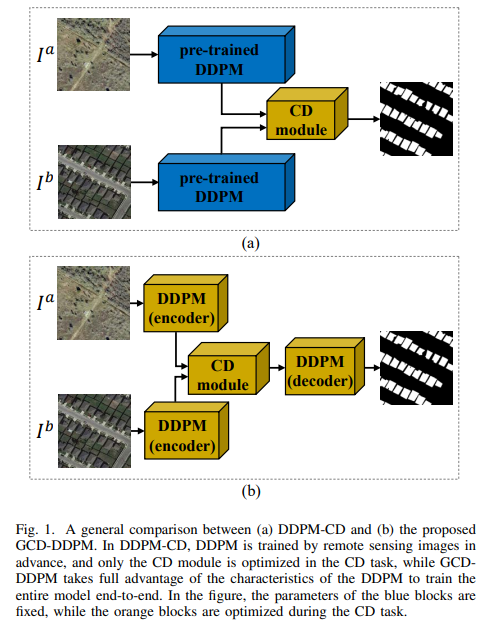
DDPM-CD包括两个阶段:
- DDPM在大量未标记遥感图像上的自监督预训练。这一阶段的目的是在不依赖标记信息的情况下,从航拍图像中学习关键语义。
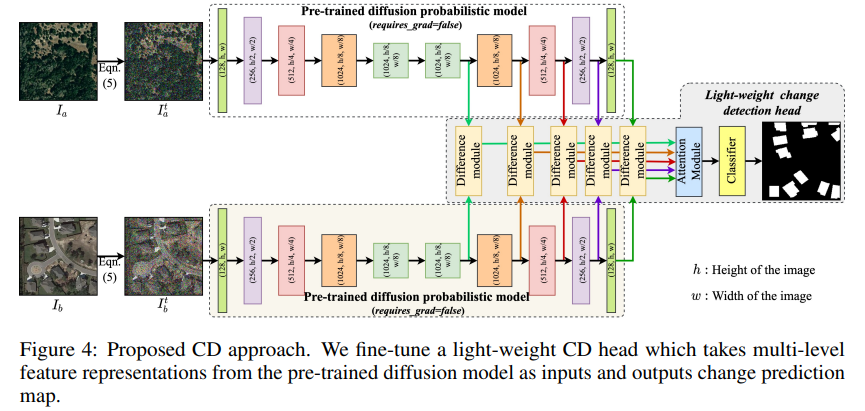
- 利用预训练的DDPM进行变化检测涉及对具有监督变化标签的CD分类器进行微调。该分类器利用从预训练DDPM的解码器中提取的预变化和后变化图像的深度特征表示,并输出变化概率图。

实验
训练细节


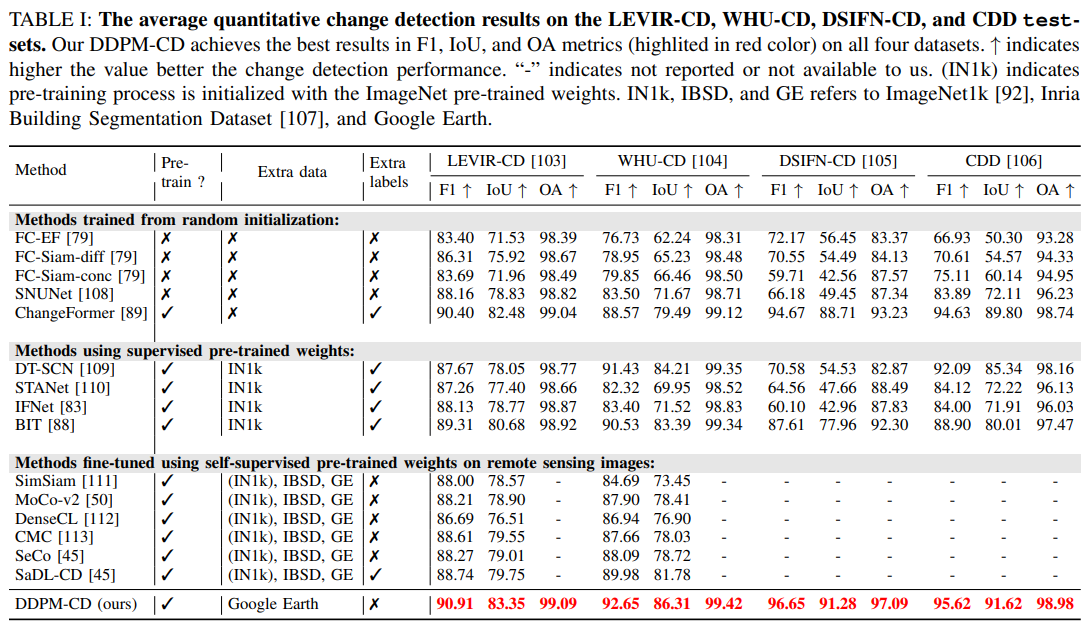
对比实验
可视化结果


消融实验
不同时间步t的消融实验:
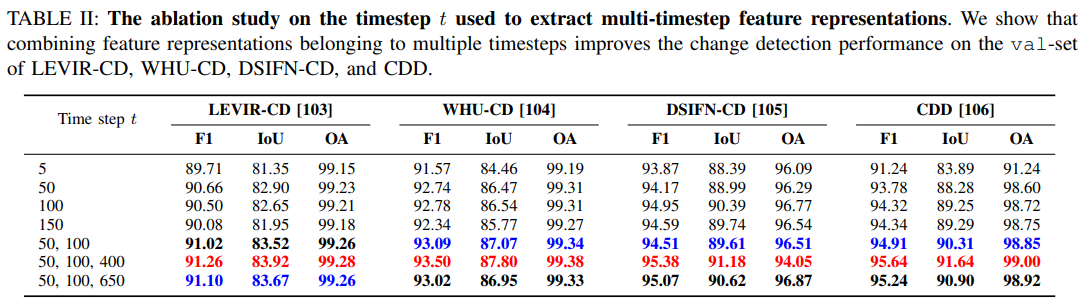
计算复杂度
GCD-DDPM: A Generative Change Detection Model Based on Difference-Feature Guided DDPM, TGRS 2024
论文:https://ieeexplore.ieee.org/abstract/document/10479050
https://arxiv.org/abs/2306.03424
代码:https://github.com/udrs/GCD
翻译:遥感论文 | TGRS | GCD-DDPM:一种生成式遥感图像变化检测方法,代码已开源! - 知乎 (zhihu.com)
引言
动机:
基于CNN或Transformer的CD方法通过判别像素来识别变化,本文结合diffusion提出一种生成变化检测模型GCD-DDPM,能够直接生成变化图,不用再进行像素分类。
贡献:
本工作提出了一个名为GCD-DDPM的生成变化检测模型,
- 通过利用去噪扩散概率模型(DDPM)直接生成变化图,而不是将每个像素分类为变化或未变化类别。
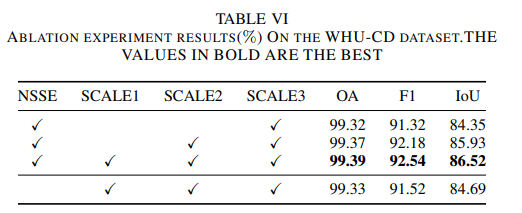
- 设计了差异条件编码器(DCE),通过利用多级差异特征来指导变化图的生成。利用变分推理(VI)过程,GCD-DDPM可以通过迭代推理过程自适应地重新校准CD结果,同时准确地区分多样化场景中的微妙和不规则变化。
- 特别设计了基于噪声抑制的语义增强器(NSSE),用于减轻CD编码器当前步骤的变化感知特征表示中的噪声。
在CDD、LEVIR-CD、WHU-CD和GVLM四个CD数据集上取得优异性能。
现有方法的局限性:
- 信息保留的挑战:现有的基于CNN的变化检测方法在连续下采样操作中丢失了精确的详细信息,特别是在保留变化区域的细节方面存在不足。
- 全局交互与局部信息的平衡:尽管注意力机制的引入有助于捕获长距离依赖性,但现有模型仍难以同时有效利用局部空间信息,尤其是在描述变化边界和边缘细节方面。
- 生成能力的提升:与判别模型相比,生成模型在变化检测中的应用较少,需要开发能够直接生成变化检测图的方法,以利用生成模型的逐渐细化和迭代改进的能力。
- 噪声抑制与精度提升:在变化检测的特征表示中,噪声的存在会影响模型的性能,需要特别设计的方法来减轻噪声并提高变化检测的准确性。
- 模型的自适应校准:现有的CD模型大多采用单次前向传播,缺乏对生成结果进行迭代改进的机制。
方法
GCD-DDPM是一个生成模型,包括两个阶段,即前向扩散阶段和反向扩散阶段。
- 前向扩散阶段,变化检测标签x0逐渐加入高斯噪声,通过一系列步骤T实现。
- 反向扩散阶段,训练一个神经网络作为噪声预测器来逆转噪声过程,并随后恢复原始数据。
前向过程
前向扩散过程,会依据初始数据分布 ,逐步添加高斯噪声,生成一系列数据点
。数学公式表示如下:
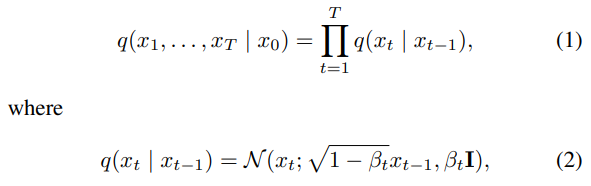
递归公式可表达为一个高斯分布:均值为,方差为
。
进一步,与
之间的数学关系可表述为
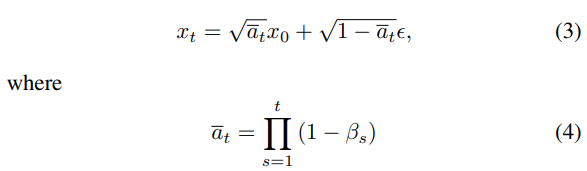
为符合
的随机高斯噪声。
反向过程
反向过程涉及将潜变量分布转换为参数化
的数据分布
。这种转换由一个马尔可夫链定义,其中学习到的高斯转移以初始分布建模为标准正态分布。
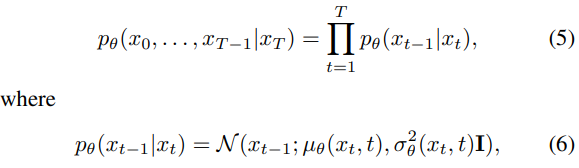
- 在训练阶段,基于变分推理(VI),目标是优化这些参数
,使得反向扩散过程能够准确地近似原始数据分布。为此,引入了一个基于神经网络的噪声预测器
预测噪声,并利用均方误差损失
,以减小所添加噪声
和所预测噪声
之间的差异。
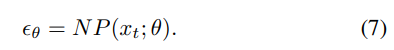
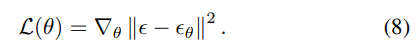
- 在推理阶段,首先从标准高斯分布中采样。以
为起始点,根据由等式(5)和(6)定义的学习转移模型,递归地采样后续数据点
。
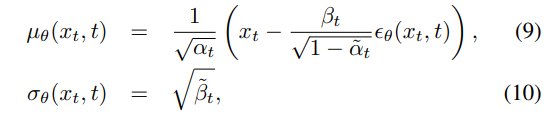
该过程迭代应用于重建噪声图像,最终在推理阶段产生清晰的分割。
GCD-DDPM网络结构
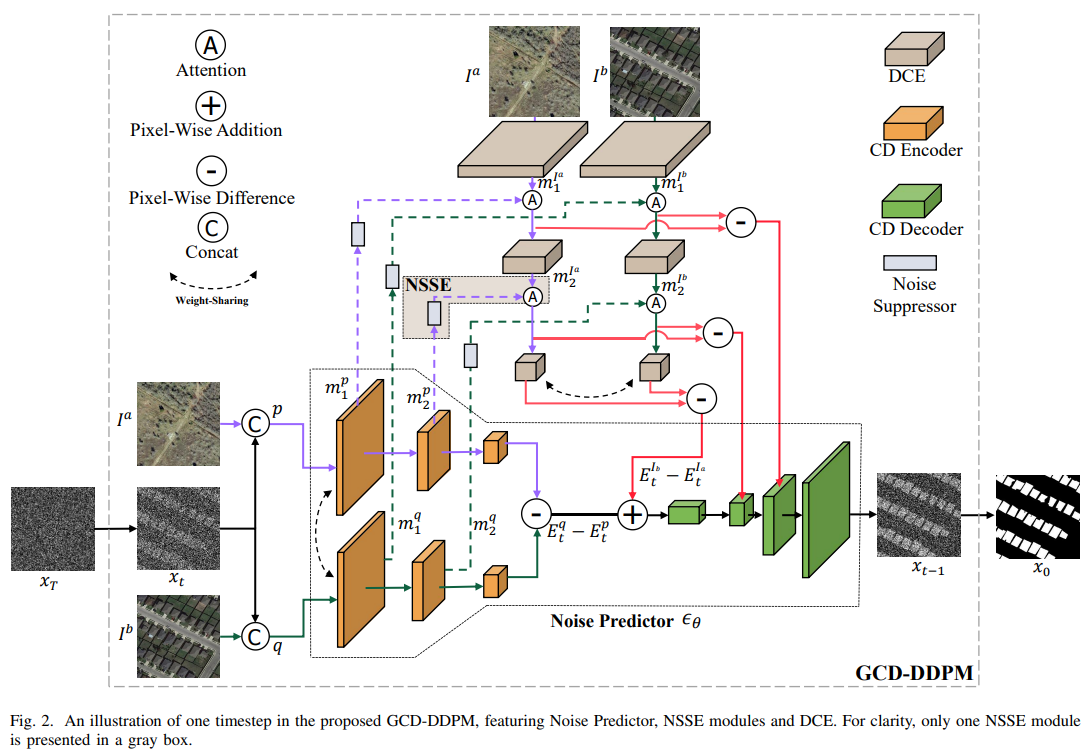
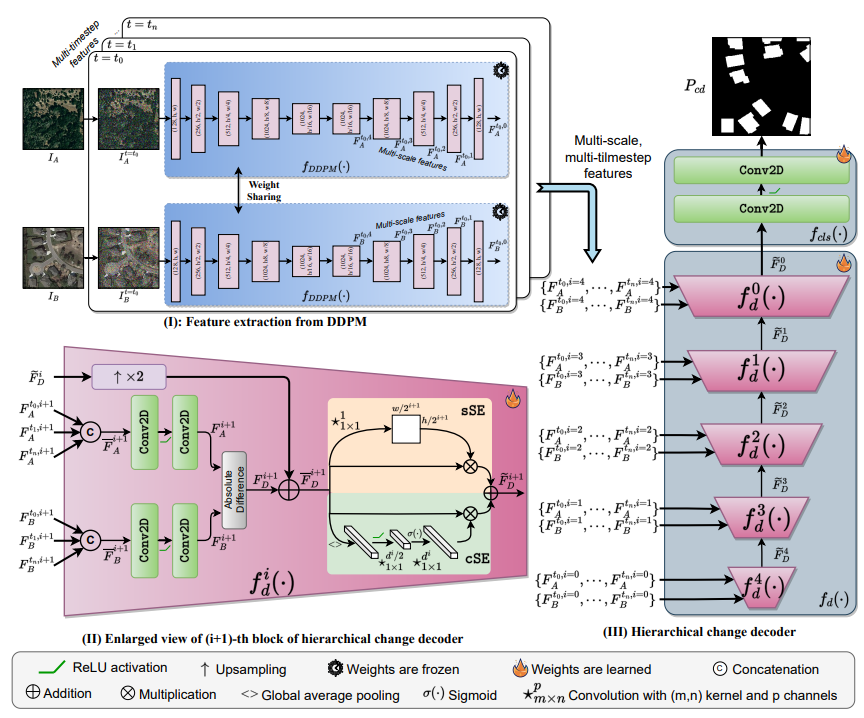
该方法直接通过端到端训练来生成高质量的变化图,而不需要对扩散模型进行额外的训练。包括两个关键组件:基于encoder-decoder架构的噪声预测器,差分条件编码器(DCE)。
- 噪声预测器中的CD编码器用于估计噪声特征。
- 基于噪声抑制的语义增强器NSSE,增强CD编码器的当前步CD噪声特征。
- 通过逐像素加法和CD解码器中的的跳接,将来自DCE的多尺度变化图与当前步CD噪声特征融合,以获得当前步CD相关噪声,这些噪声将作为下一步迭代的先验信息。
GCD-DDPM算法通过对高斯噪声进行迭代采样,通过准确表征输入图像之间的差异,逐步提高生成变化图的精度。
Noise Predictor 噪声预测器
噪声预测器,是一个包含CD编码器和CD解码器的U-Net。
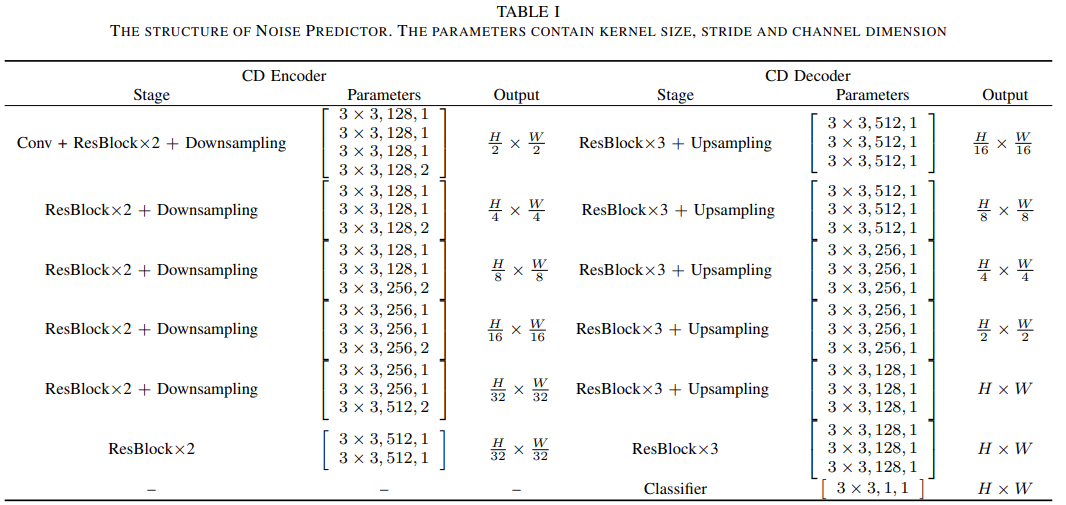

在GCD-DDPM的噪声预测器的CD编码器中,
- 输入图像通过一系列灵活的残差块(ResBlocks)进行处理,并进行下采样操作。
- 然后,CD解码器通过ResBlocks和上采样层将特征升级到原始空间尺寸,并通过跳过连接将它们与DCE模块的输出集成。
- 在此过程中,来自DCE模块相应层级的特征被合并,以增强特征的细节和质量。
- CD解码器的最终输出是详细的单通道CD相关的噪声
DCE 差分条件编码器
DCE模块的开发旨在从扩散模型框架内的每个样本中提取变化信息。
和
分别表示第k个块中获取的变化前图像和变化后图像的条件特征图。
- 通过从多层噪声特征中提取信息,将当前步骤的变化图信息整合到DCE中。具体来说,将DCE中提取的多层条件特征与噪声预测器中的当前步骤相应的噪声特征相结合。
因此,提出NSSE模块来增强和校准条件嵌入特征。
NSSE 噪声抑制的语义增强器
NSSE包含一个噪声抑制器模块,旨在通过使用参数化的注意力图消除高频噪声来抑制固有的噪声。

- 第k层噪声特征
,由初始噪声特征通过CD编码器架构中的相应卷积块获得。
- 使用二维快速傅里叶变换(FFT)沿着空间维度转换为频域噪声特征
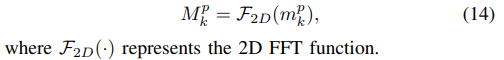
- 然后,将
与参数化的注意力图
相乘,再使用逆二维快速傅里叶变换(Inverse 2D FFT)转换回空间域。 通过全局调整滤波频率来学习约束高频分量进行自适应集成。

- 从噪声特征 p 中提取的 CD 特征
被输入到两个独立的卷积层。继而,计算增强嵌入。

训练和推理过程的算法


实验
训练细节

对比实验
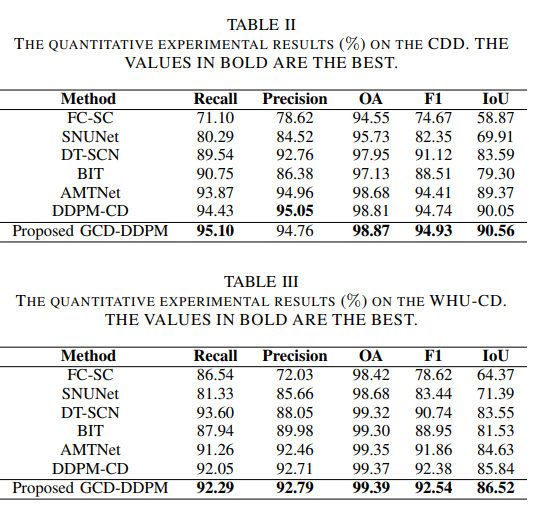
CDD、WHU-CD、LEVIR-CD、GVLM数据集上的实验结果:
可视化结果




热力图:

消融实验
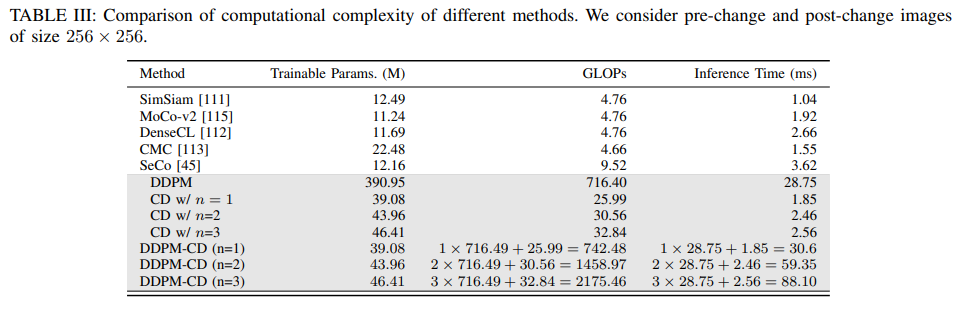
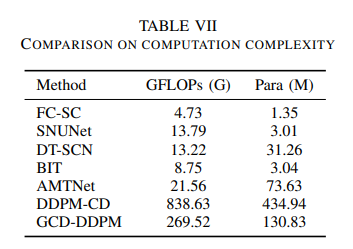
计算效率对比















 737
737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









