






redis的主从架构无法实现master和slave角色的自动切换,当master节点故障down机时,主从复制无法实现自动的故障转移,即将slave节点提升为新的master,而是需要手动修改环境配置,才能切换到redis服务器,而sentinel哨兵机制就核心的解决了因master节点故障down机,自动提升节点的问题,另外单台redis服务器性能无法满足业务写入需求的时候,也无法横向扩展redis服务的并行写入性能。
在主从节点搭建之后,一主多从,访问时并不知道访问的是哪个节点,之前需加代理,现在哨兵机制就可以解决这个问题,也就是说不需要关注连接的是哪个节点,只需要连接哨兵机制,哨兵机制本身就是一个代理,通过连接哨兵机制,它会自动返回一个你可以访问的节点,所以当redis的节点数不够多,性能不佳,可以添加一个新的或者多个redis,哨兵机制会自动把新添加的redis节点加入到sentinel列表里,将来新的用户发起连接,它就可以把这些用户的请求转发到新的redis节点上去。
当redis实现哨兵机制之后,可以自动监控master节点的故障,mster节点一旦有问题,哨兵机制就可以自动解决,工作原理类似MHA工作机制,哨兵机制本身是一套独立的软件,和redis的主从是隔离的,当然sentinel也为了避免单点失败问题,也需要多个节点,sentinel的节点个数应该为三个或三个以上且最好为奇数,因为sentinel集群是通过投票的方式来选举新主节点,票数要高于二分之一,才能选出新的master,如果是偶数节点,票数半半,容易形成脑裂。
假如有两组主从,可以针对这两组主从架构搭建sentinel集群,这个集群可以自动监控多组主从,其中任何一组主从中的master出现故障,sentinel会及时发现问题并且提升这组主从中的某一个slave节点成为新主,所以一套sentinel可以解决多套主从的高可用。
此外,sentinel不仅可以提供高可用的问题这么简单,如果客户端连接的redis写的就是master节点的ip地址,当master节点故障时仍然还会连接故障的master节点,就不太合理,客户端应该连接的是提升的新主,但是客户端连接的master节点的ip是提前在它的应用程序里写好的,即使提升了新主也相当于不起作用,改程序效率太低,所以,为了解决这个问题,我们可以不需要让客户端直接连接redis集群,而是连接sentinel,以sentinel为媒介,让客户端通过sentinel去访问redis集群,sentinel返回一个可用的节点让客户端去连接。
sentinel实现故障转移步骤
- 多个sentinel发现并确认mster故障
- 选举出一个sentinel作为领导
- 选出一个slave作为master
- 通知其余的slave节点成为新主的slave节点
- 通知客户端主从变化
- 等待曾经down机的master节点成为新主的slave节点
sentinel中的三个定时任务
1.每10秒每个sentinel对master和slave执行info(判断是否故障,随时做好故障转移准备)
发现slave节点
确认主从关系
2.每两秒每个sentinel通过master节点的channel交换信息(pub/sub)
通过sentinel_:hello频道交互(发布者,订阅者,生产者,消费者消息队列机制 ,其中发布者和订阅者中的可以获取共同信息的频道,通过频道的消息队列机制来互相了解交换信息,交互对节点的“看法”和自身信息,判断odown或者sdown)
3.每一秒每个sentinel对其他sentinel和redis执行ping
sentinel哨兵机制架构部署
主机准备
10.0.0.8 master(centos8 redis5.0.3)
10.0.0.18 slave1(centos8 redis5.0.3)
10.0.0.28 slave2(centos8 redis5.0.3)
准备主从环境,所有主从节点的redis.conf中关键配置
[17:19:00 root@master ~]$vim /etc/redis.conf

[17:24:02 root@slave1 ~]$vim /etc/redis.conf
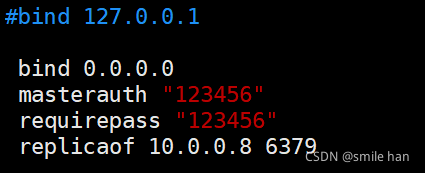
[17:24:19 root@slave2 ~]$vim /etc/redis.conf
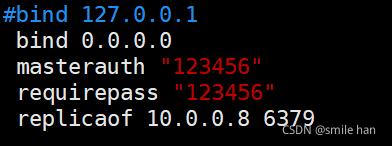
所有节点redis服务设为开机启动并立即启动
systemctl enable --now redis



master服务器状态
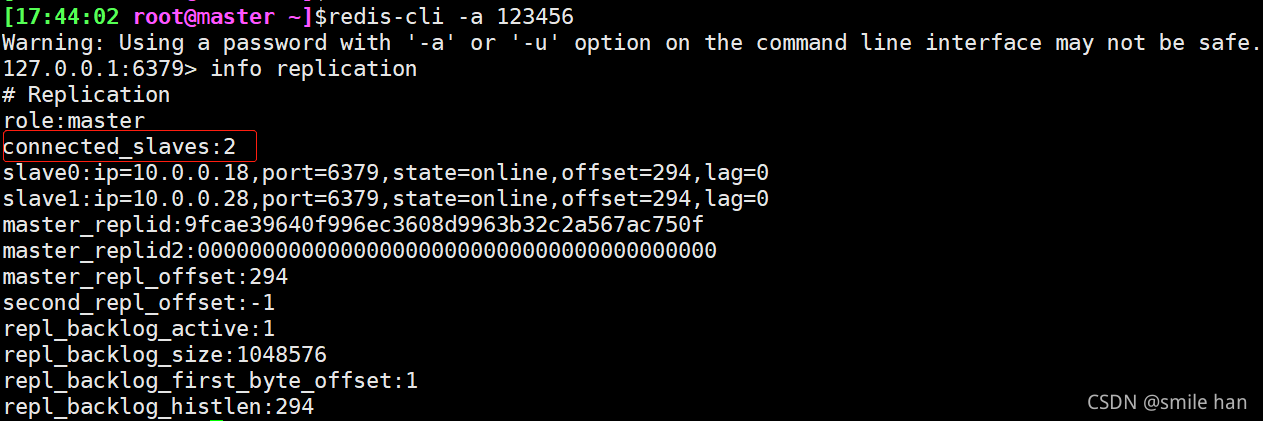
配置slave1
[17:41:32 root@slave1 ~]$redis-cli -a 123456
127.0.0.1:6379> replicaof 10.0.0.8 6379
127.0.0.1:6379> config set masterauth "123456"

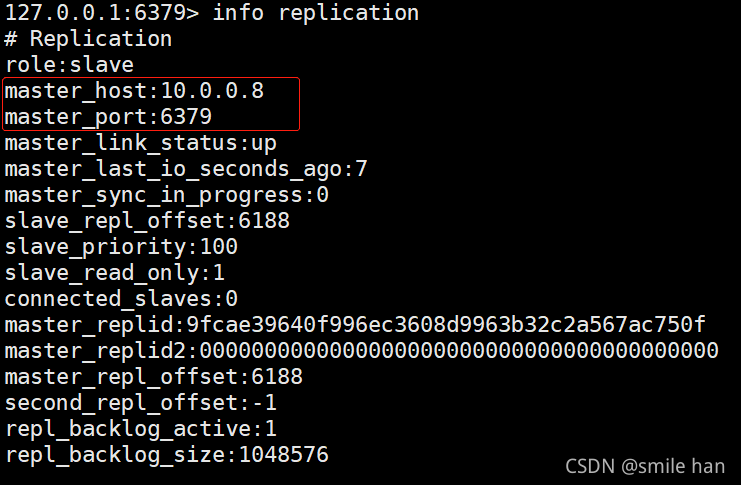
127.0.0.1:6379> info replication
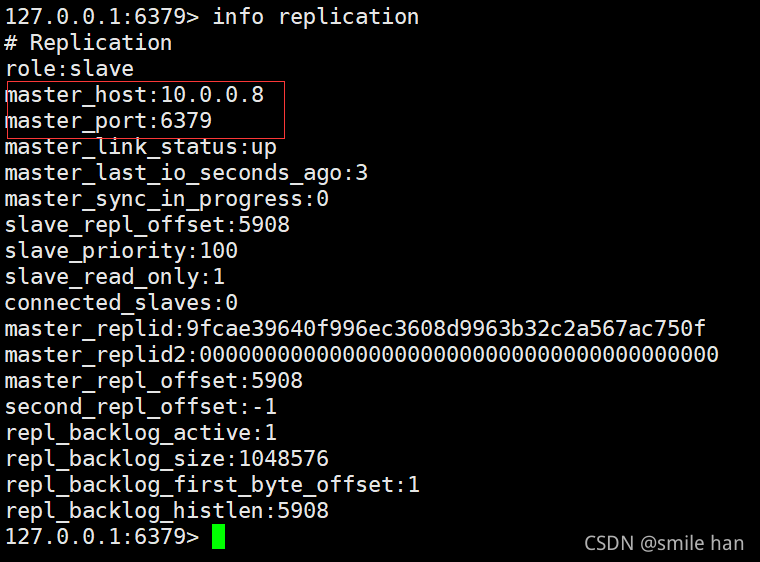
配置slave2
[17:41:37 root@slave2 ~]$redis-cli -a 123456
127.0.0.1:6379> replicaof 10.0.0.8 6379
127.0.0.1:6379> config set masterauth "123456"

127.0.0.1:6379> info replication
sentinel配置
sentinel实际上是一个特殊的redis服务器,有些redis指令支持,但很多指令并不支持,默认监听在26379/tcp端口。
哨兵机制可以不和redis服务器部署在一起,但一般部署在一起,节约成本。
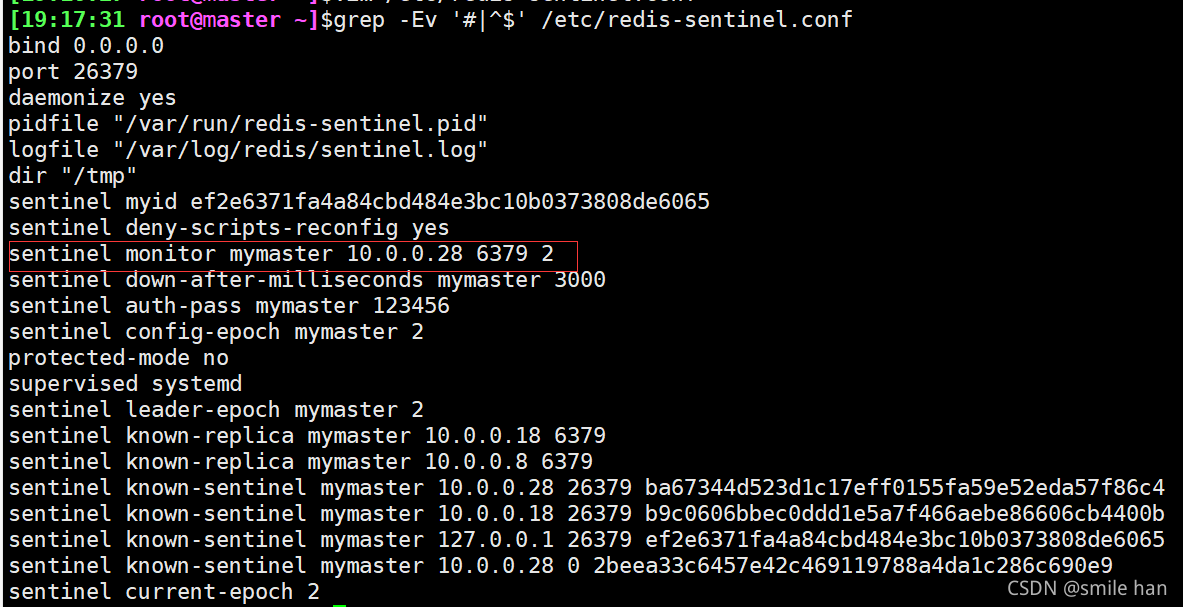
[19:12:53 root@master ~]$vim /etc/redis-sentinel.conf
mymaster是主从组合名字(区分多组主从)
10.0.0.8主节点ip地址,用来连接主节点获取slave的信息用于将来master down机修改slave配置信息提升新新主,并且更改另外一个slave节点信息指向新主
端口号6379
法定人数限制,即有几个sentinel认为有master down机了就进行故障转移,一般此值是所有sentinel节点的一半以上的整数值,总数是3,一半以上取整为2,是master的odown客观下线的依据

Sentinel auth-pass mymaster 123456
主从组合名字及密码

sentinel down-after-milliseconds mymaster 30000
(sdown)判断mymaster集群中所有节点的主观下线时间,单位为毫秒,建议3000

Logfile
指定存放sentinel日志的文件及路径

三个哨兵的redis-sentinel.conf文件的主要配置项

如果sentinel配置文件权限不是redis权限,需修改,便于将来sentinel提升新主之后修改slave节点的配置信息
[16:05:13 root@master ~]$chown redis.redis /etc/redis-sentinel.conf
启动哨兵机制
[16:14:54 root@master ~]$systemctl enable --now redis-sentinel.service
[16:17:12 root@slave1 ~]$systemctl enable --now redis-sentinel.service
[16:17:58 root@slave2 ~]$systemctl enable --now redis-sentinel.service
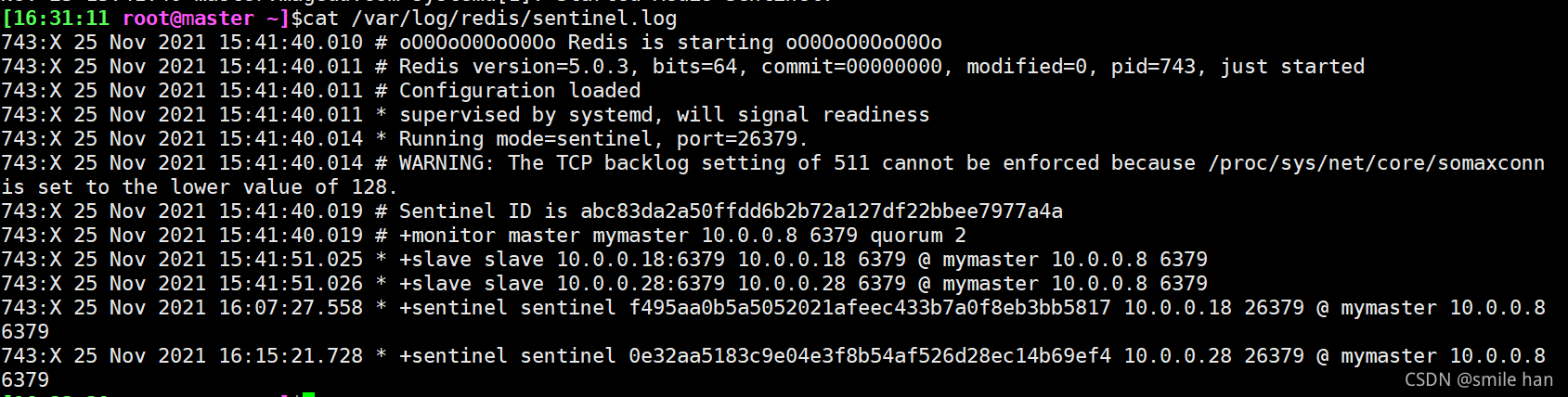
sentinel日志已生成
可以看到每个节点redis-sentinel.conf文件已生成新的信息
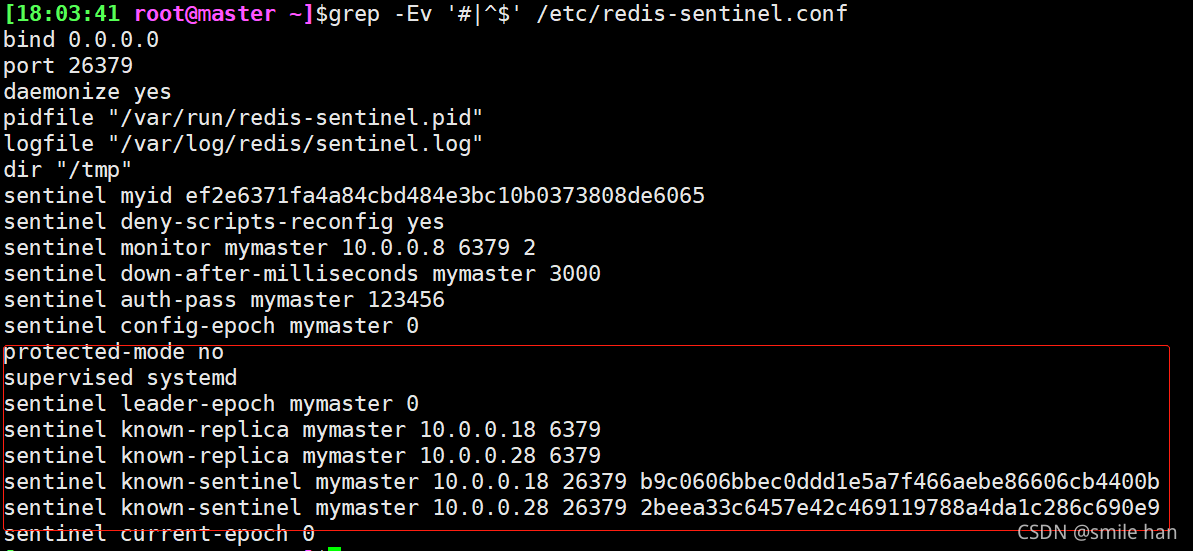
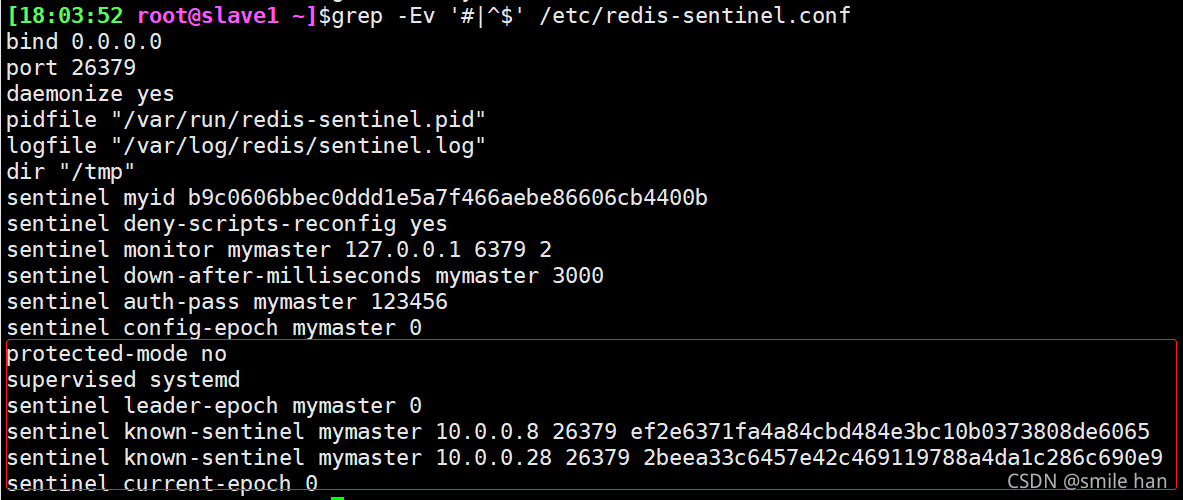
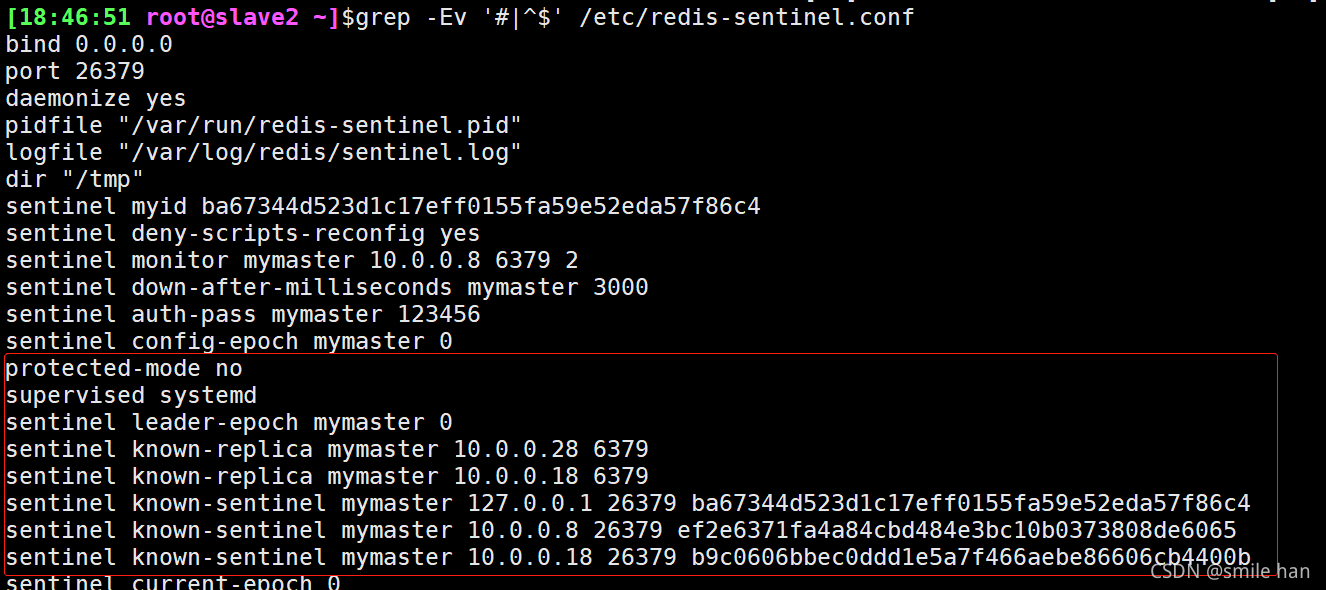
服务启动之后,每个sentinel节点会生成一个myid,确保每个哨兵机制myid不同,如果相同,必须手动修改为不同的值


登录redis服务查看每个节点的状态,目前主从状态健康
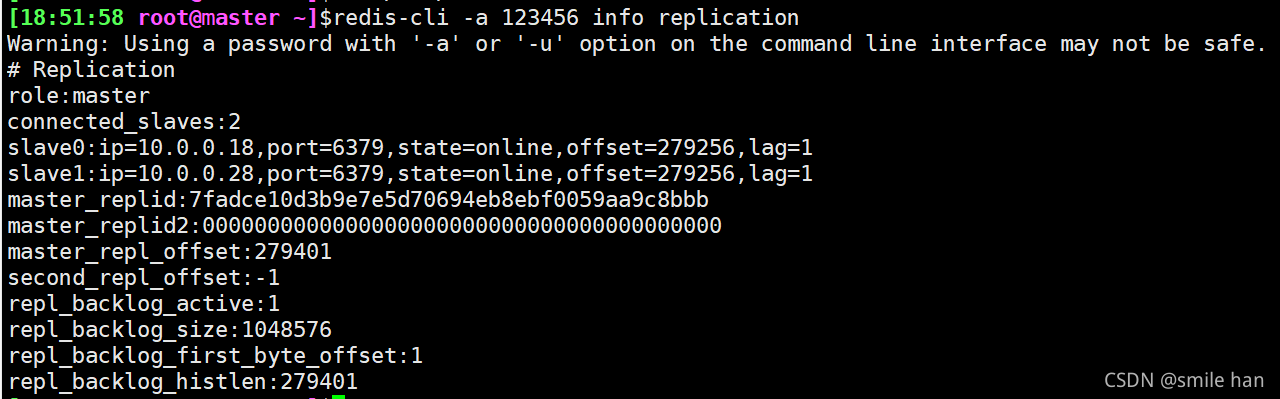
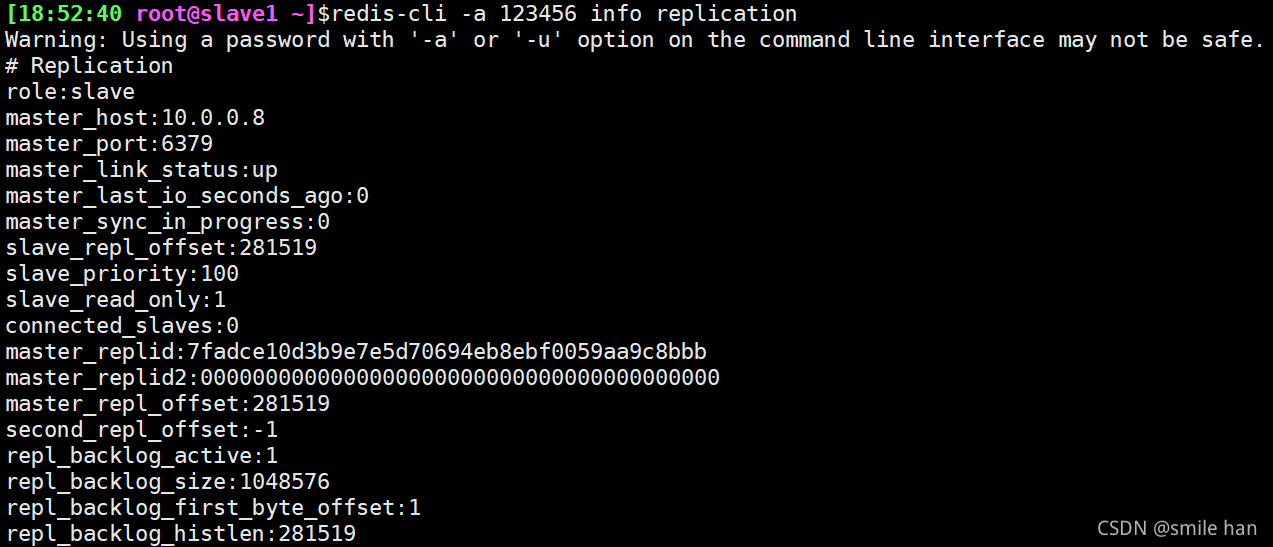
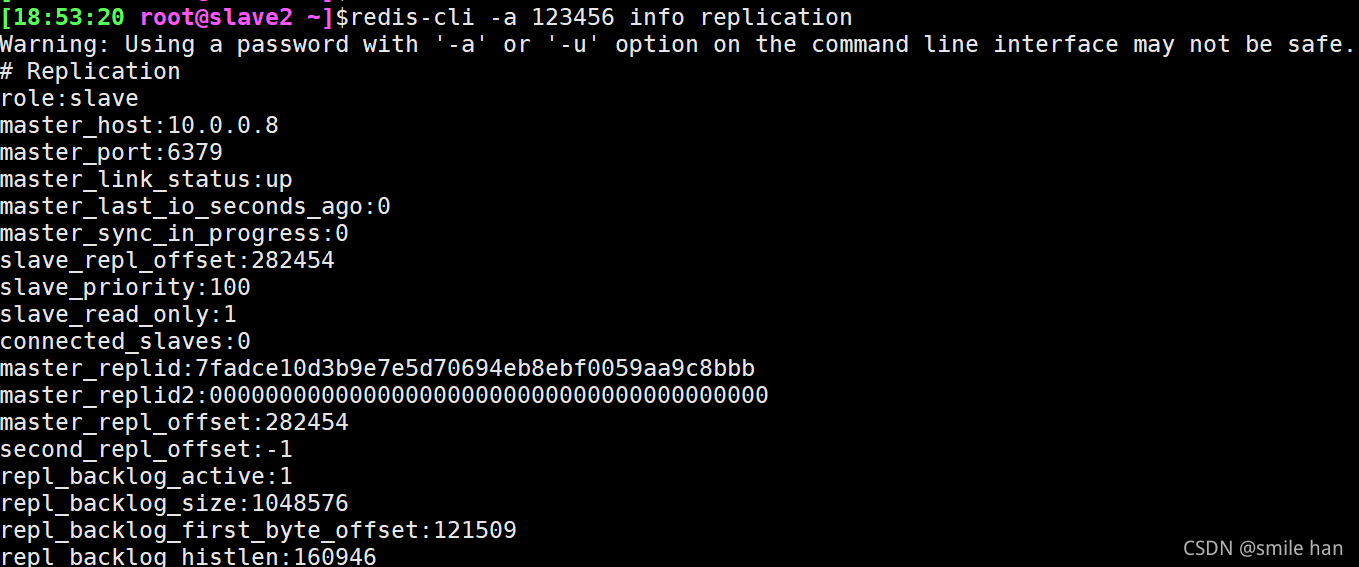
登录26379端口,查看各个节点sentinel状态,没有问题
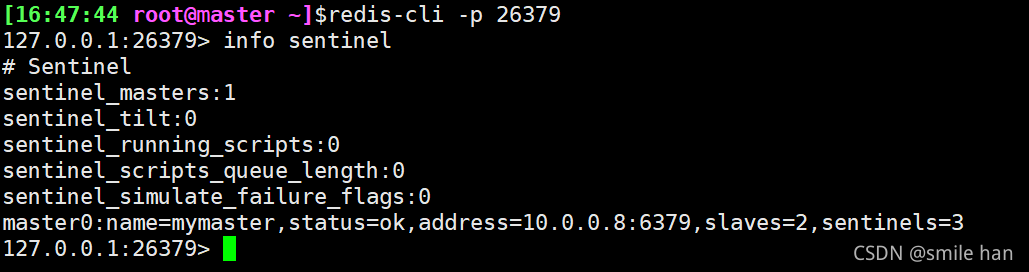
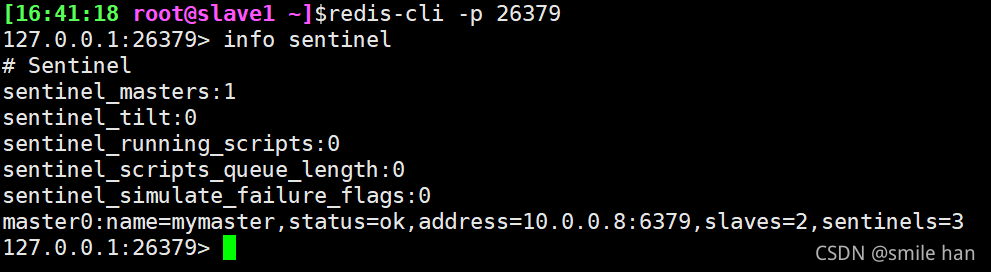
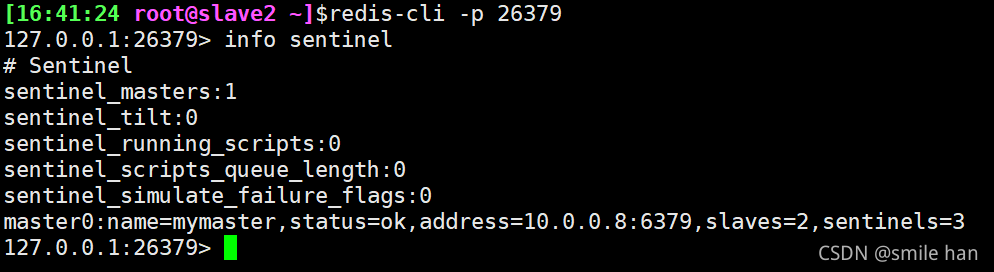
shutdown模拟master节点down机
查看日志,sentinel开始投票选举新的master节点,日志显示,最终选举10.0.0.28为新的master节点

登录新主查看状态
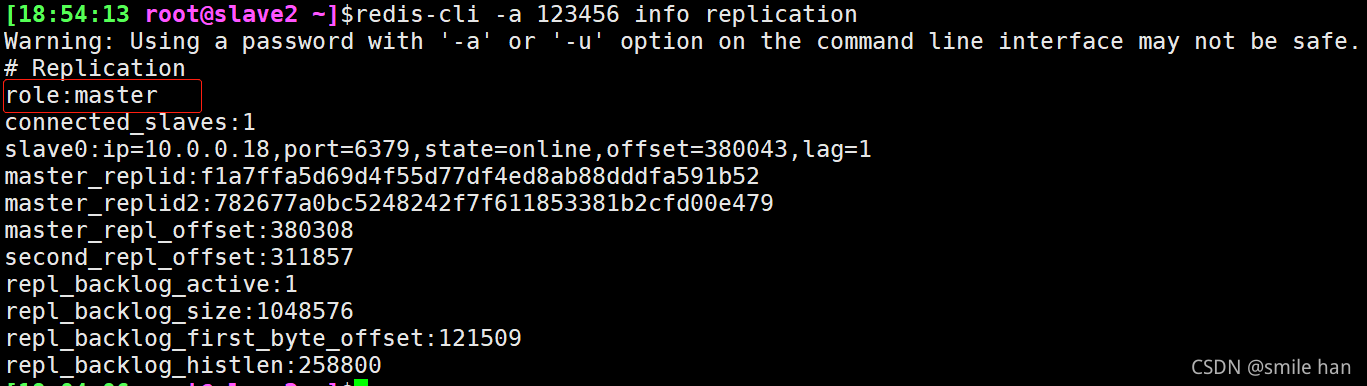
10.0.0.18还是slave节点
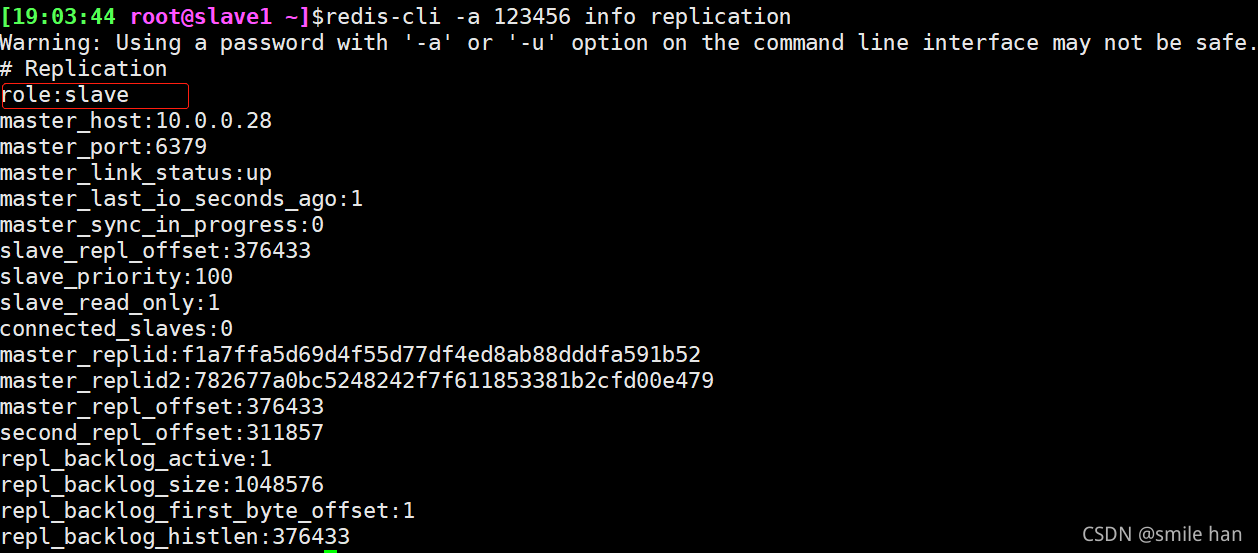
如果原master故障恢复,重新启动原master的redis服务,查看状态,就会成为新主的slave
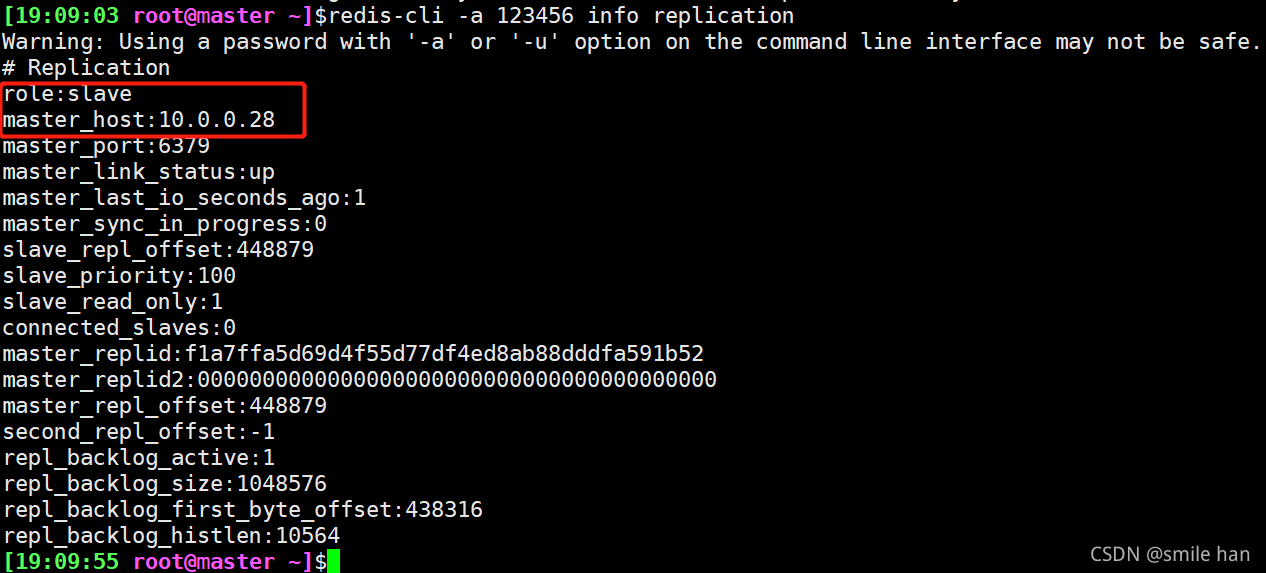
新从的redis-sentinel.conf及redis.conf文件都已更改

到此,redis的sentinel机制架构已完成,与masql的高可用性MHA不同的是MHA是一次性机制,完成任务即退出,而sentinel机制是一直运行的,时刻监控各个节点的故障。
如果曾经的master故障修复之后还是想让其当主的话,可以设置优先级,redis.conf有个优先级的配置,slave_priority 100,值设为整数,数字越小表示优先级越高,当master故障时会按照优先级来选择slave端进行回复,如果值设置为0,那么表示该slave永远不会被选择。














 5399
5399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









