







Redis哨兵(sentinel)
【目标】
-
掌握解决主从复制故障的解决方案
-
掌握哨兵监控的搭建
-
掌握哨兵监控机制及故障的自动转移
【理论知识】
-
哨兵监控架构设计
-
主观和客观下线
-
Leader选举流程
-
故障迁移流程
【实际操作】
- 哨兵监控配置
- 故障迁移演练
- 故障迁移日志查看
- 自动故障迁移相关指令
哨兵监控架构
模式一:手动故障转移
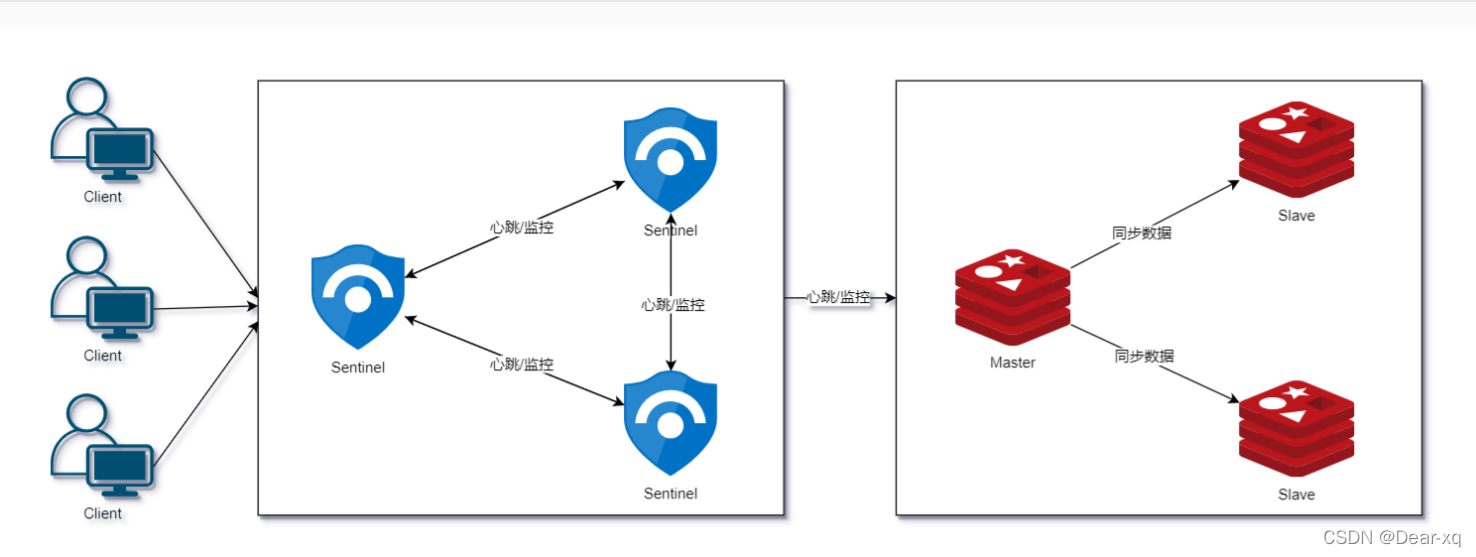
主从模式中,当主节点宕机之后,从节点是可以作为主节点顶上来继续提供服务,但是需要修改应用方的主节点地址,还需要命令所有从节点去复制新的主节点,整个过程需要人工干预。
模式二:自动故障转移

在 Redis 2.8 版本开始,引入了哨兵(Sentinel)这个概念,在主从复制的基础上,哨兵实现了自动化故障恢复。如上图所示,哨兵模式由两部分组成,哨兵节点和数据节点:
- 哨兵节点:哨兵节点是特殊的 Redis 节点,不存储数据;
- 数据节点:主节点和从节点都是数据节点
Redis Sentinel 是分布式系统中监控 Redis 主从服务器,并提供主服务器下线时自动故障转移功能的模 式。
四个特性:
监控(Monitoring):Sentinel 会不断地检查你的主服务器和从服务器是否运作正常;
提醒(Notification):当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或 者其他应用程序发送通知;
自动故障迁移(Automatic failover):当一个主服务器不能正常工作时, Sentinel 会开始一次自动故 障迁移操作。
配置提供者(Configuration provider):为客户端提供服务发现功能,客户端连接 Sentinel 获取当前 Master 节点的相关信息,当发生 failover 时,Sentinel 将新通知客户端。
Sentinel 的分布式特性
- Redis Sentinel 是一个分布式系统,可以在一个架构中运行多个 Sentinel 进程,优势如下:
- 当多个 Sentinel 确定 Master 不再可用,进行故障检测,这降低了误报的可能性
- 当在不同服务器上运行多个 Sentinel 进程,然后将 Sentinel 做集群,即使其中一个故障,也可以进行热切换,降低对客户端的影响,从而提升了系统健壮性
- Redis 客户端可连接任意 Sentinel 来使用 Redis
部署 Redis sentinel 前要了解
- Sentinel 运行默认侦听端口 26379。
- 一个健壮的部署至少需要三个 Sentinel 实例。
- 运行 Sentinel 必须指定配置文件,因为系统使用此文件来保存当前状态,以便重启 Sentinel 时重新 加载。指定的配置文件有问题或不指定配置文件,Sentinel 会拒绝启动。
- 三个 Sentinel 实例应放在相对独立的虚拟机或物理机中。
- 由于 Redis 使用异步复制,Sentinel + Redis 不能保证故障期间保留已确认的写入,但可配置 Sentinel 允许丢失有限的写入。另外还有一些安全性较低的部署方式。
- 使用的客户端要支持 Sentinel,大多数热门的都支持 Sentinel,但不是全部。
- 没有完全健壮的 HA 设置,所以要经常在测试环境中测试。
- Sentinel 在 Docker、端口映射或网络地址转换的环境中配置要格外小心: 在重新映射端口的情况 下,真实端口可能与转发的端口不同,会破坏 Sentinel 自动发现其他的 Sentinel 进程和 Master 的 Slave 列表。
优点
-
哨兵模式是基于主从模式的,所有主从的优点,哨兵模式都有;
-
主从可以自动切换,系统更健壮,可用性更高;
-
Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。当被监控的某个 Redis 服务器出现问 题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
缺点
- 主从切换需要时间,会丢失数据;
- 还是没有解决主节点写的压力;
- 主节点的写能力,存储能力受到单机的限制;
- 动态扩容困难复杂,对于集群,容量达到上限时在线扩容会变得很复杂。
监控环境搭建
节点准备
| IP | 角色 |
|---|---|
| 192.168.10.101 | Master |
| 192.168.10.102 | Slave |
| 192.168.10.103 | Slave |
编写配置文件
三个节点分别创建 sentinel.conf 并添加以下配置。
vi /usr/local/redis/conf/sentinel.conf
# 放行所有 IP 限制
bind 0.0.0.0
# 进程端口号
port 26379
# 后台启动
daemonize yes
# 日志记录文件
logfile "/usr/local/redis/log/sentinel.log"
# 进程编号记录文件
pidfile /var/run/sentinel.pid
# 指示 Sentinel 去监视一个名为 mymaster 的主服务器 2为制裁权重值
sentinel monitor mymaster 192.168.10.101 6379 2
# 访问主节点的密码
sentinel auth-pass mymaster 123456
# Sentinel 认为服务器已经断线所需的毫秒数
sentinel down-after-milliseconds mymaster 10000
# 若 Sentinel 在该配置值内未能完成 failover 操作,则认为本次 failover 失败
sentinel failover-timeout mymaster 180000
启动
先启动 3 个 Redis 服务
/usr/local/redis/bin/redis-server /usr/local/redis/conf/redis.conf
再启动 3 个 Sentinel 服务
/usr/local/redis/bin/redis-sentinel /usr/local/redis/conf/sentinel.conf
查看日志
tail -f /usr/local/redis/log/sentinel.log
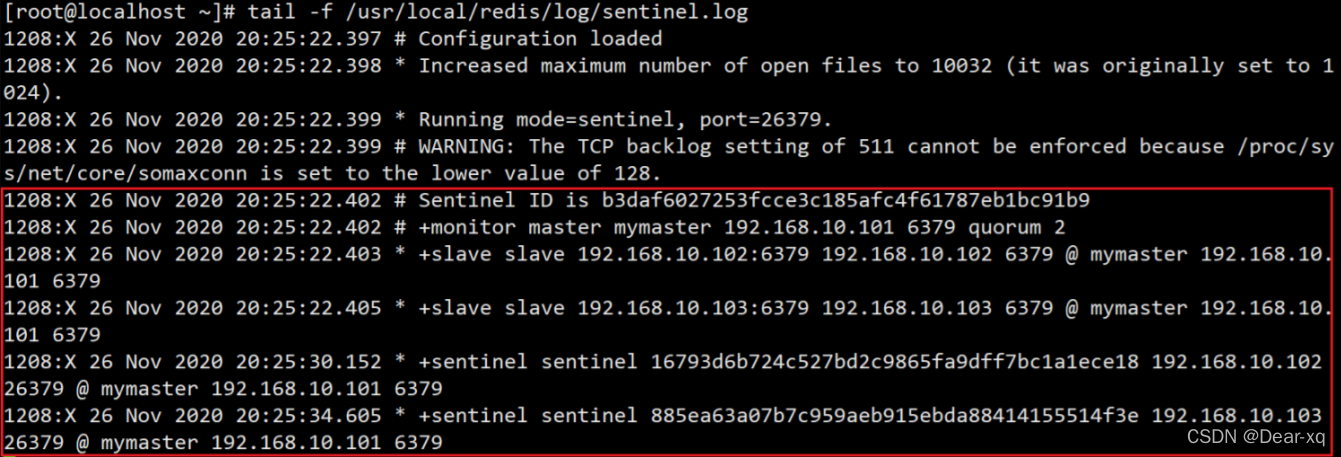
接下来我们了解一些 Sentinel 中的关键名词,然后系统讲解下哨兵模式的工作原理。
哨兵工作原理
定时任务
Sentinel 内部有 3 个定时任务,分别是:
- 每 1 秒每个 Sentinel 对其他 Sentinel 和 Redis 节点执行 PING 操作(监控),这是一个心跳检测, 是失败判定的依据。
- 每2 秒每个 Sentinel 通过 Master 节点的 channel 交换信息(Publish/Subscribe);
- 每 10 秒每个 Sentinel 会对 Master 和 Slave 执行 INFO 命令,这个任务主要达到两个目的:
- 发现 Slave 节点;
- 确认主从关系。
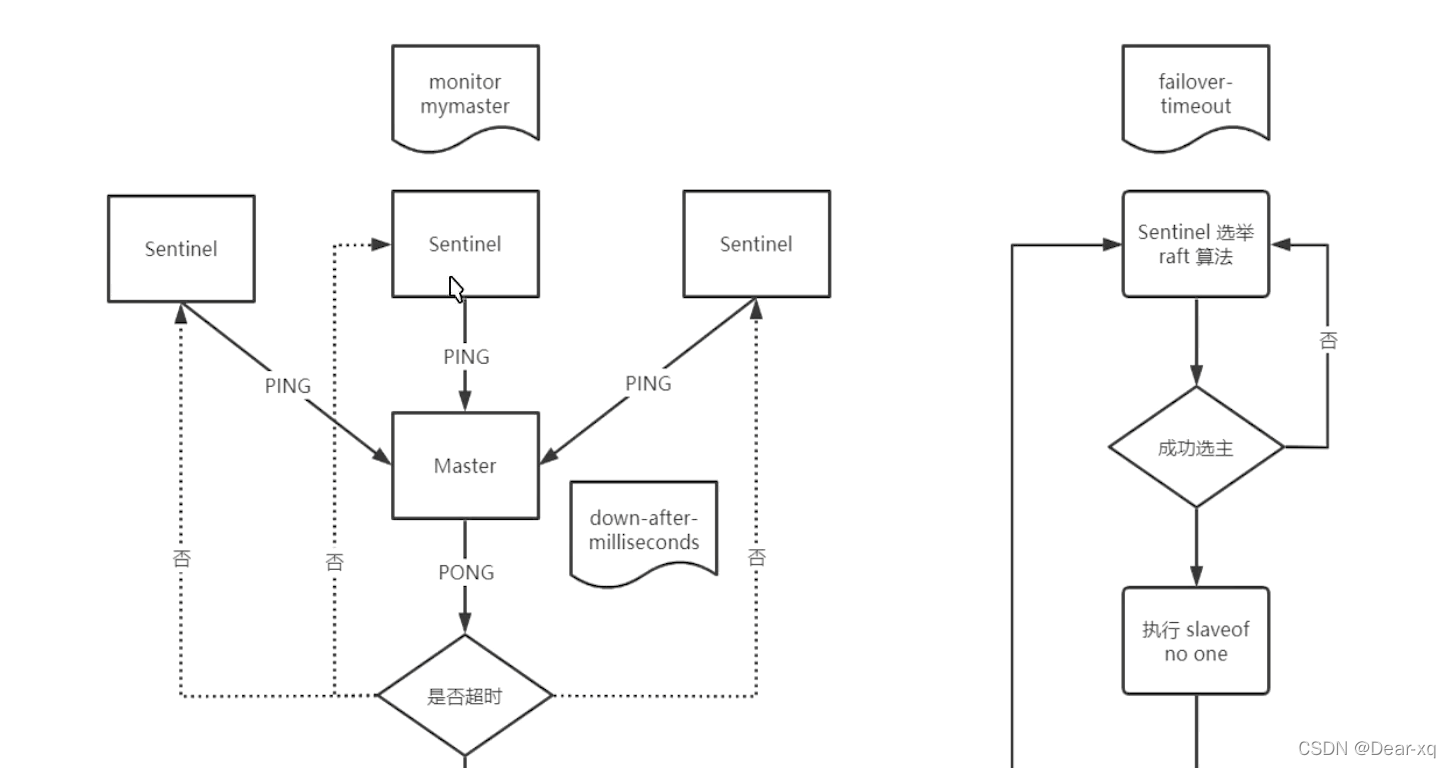
主观下线
所谓主观下线(Subjectively Down, 简称 SDOWN)指的是单个 Sentinel 实例对服务器做出的下线判 断,即单个 Sentinel 认为某个服务下线(有可能是接收不到订阅,之间的网络不通等等原因)。 主观下线就是说如果服务器在给定的毫秒数之内, 没有返回 Sentinel 发送的 PING 命令的回复, 或者返 回一个错误, 那么 Sentinel 会将这个服务器标记为主观下线(SDOWN)。
客观下线
客观下线(Objectively Down, 简称 ODOWN)指的是多个 Sentinel 实例在对同一个服务器做出 SDOWN 判断,并且通过命令互相交流之后,得出的服务器下线判断,然后开启 failover。 只有在足够数量的 Sentinel 都将⼀个服务器标记为主观下线之后, 服务器才会被标记为客观下线 (ODOWN)。只有当 Master 被认定为客观下线时,才会发生故障迁移。
仲裁
仲裁指的是配置文件中的 quorum 选项。某个 Sentinel 先将 Master 节点标记为主观下线,然后会将这 个判定通过 sentinel is-master-down-by-addr 命令询问其他 Sentinel 节点是否也同样认为该 addr 的 Master 节点要做主观下线。
最后当达成这一共识的 Sentinel 个数达到前面说的 quorum 设置的值 时,该 Master 节点会被认定为客观下线并进行故障转移。 quorum 的值一般设置为 Sentinel 个数的二分之一加 1,例如 3 个 Sentinel 就设置为 2
哨兵模式工作原理
- 每个 Sentinel 以每秒一次的频率向它所知的 Master,Slave 以及其他 Sentinel 节点发送一个 PING 命令(发布/订阅);
- 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过配置文件 own-aftermilliseconds 选项所指定的值,则这个实例会被 Sentinel 标记为主观下线;
- 如果一个 Master 被标记为主观下线,那么正在监视这个 Master 的所有 Sentinel 要以每秒一次的频 率确认 Master 是否真的进行主观下线状态;
- 当有足够数量的 Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认 Master 的确进行 了主观下线状态,则 Master 会被标记为客观下线;
- 如果 Master 处于 ODOWN 状态,则投票自动选出新的主节点。将剩余的从节点指向新的主节点继续 进行数据复制;
- 在正常情况下,每个 Sentinel 会以每 10 秒一次的频率向它已知的所有 Master,Slave 发送 INFO 命 令;当 Master 被 Sentinel 标记为客观下线时,Sentinel 向已下线的 Master 的所有 Slave 发送 INFO 命令的频率会从 10 秒一次改为每秒一次;
- 若没有足够数量的 Sentinel 同意 Master 已经下线,Master 的客观下线状态就会被移除。若 Master 重新向 Sentinel 的 PING 命令返回有效回复,Master 的主观下线状态就会被移除。
故障转移演示
先启动 3 个 Redis 服务
/usr/local/redis/bin/redis-server /usr/local/redis/conf/redis.conf
再启动 3 个 Sentinel 服务
/usr/local/redis/bin/redis-sentinel /usr/local/redis/conf/sentinel.conf
查看日志
tail -f /usr/local/redis/log/sentinel.log
测试
模拟主节点故
kill -9 杀死 Redis 主节点,down-after-milliseconds 时间满⾜以后,观察 Sentinel 日志是否会发起 重新选举操作,内容如下。
# ----------主节点主观下线(单个 Sentinel 实例对服务器做出的下线判断)----------
+sdown master mymaster 192.168.10.101 6379
# ----------客观下线(多个 Sentinel 实例在对同一个服务器做出 SDOWN 判断)--------
+odown master mymaster 192.168.10.101 6379 #quorum 2/2
# ----------启动新的选举流程,记录选举次数----------
+new-epoch 1
# ----------开启 failover 故障转移----------
+try-failover master mymaster 192.168.10.101 6379
# ----------投票选举一个领导人去做故障转移这件事----------
+vote-for-leader b3daf6027253fcce3c185afc4f61787eb1bc91b9
1885ea63a07b7c959aeb915ebda88414155514f3e voted for b3daf6027253fcce3c185afc4f61787eb1bc91b9
116793d6b724c527bd2c9865fa9dff7bc1a1ece18 voted for
b3daf6027253fcce3c185afc4f61787eb1bc91b9 1
# ----------对 192.168.10.101 6379 进行故障转移----------
+elected-leader master mymaster 192.168.10.101 6379
# ----------查找环境中(主从环境)合适的 Slave----------
+failover-state-select-slave master mymaster 192.168.10.101 6379
# ----------已经找到环境中(主从环境)合适的 Slave----------
+selected-slave slave 192.168.10.103:6379 192.168.10.103 6379 @mymaster 192.168.10.101 6379
# ----------向 Slave 发送 “slaveof no one” 指令(关闭复制功能),此时 Slave 已经完成⻆色转换,此 Slave 即为 Master----------
* +failover-state-send-slaveof-noone slave 192.168.10.103:6379 192.168.10.103 6379 @ mymaster 192.168.10.101 6379
# ----------等待其他 Sentinel 确认 Slave 的升级----------
* +failover-state-wait-promotion slave 192.168.10.103:6379 192.168.10.103 6379 @ mymaster 192.168.10.101 6379
# ----------确认完毕,提升 192.168.10.103:6379 为主节点----------
+promoted-slave slave 192.168.10.103:6379 192.168.10.103 6379 @mymaster 192.168.10.101 6379
# ----------开始对 Slaves 进行 reconfig 操作----------
+failover-state-reconf-slaves master mymaster 192.168.10.101 6379
# --------向指定的 Slave 发送 “slaveof” 指令,告知此 Slave 跟随新的 Master-------
* +slave-reconf-sent slave 192.168.10.102:6379 192.168.10.102 6379 @ mymaster 192.168.10.101 6379
# ----------192.168.10.101 6379 客观下线----------
-odown master mymaster 192.168.10.101 6379
# ----------此 Slave 正在执行 slaveof + SYNC 过程----------
* +slave-reconf-inprog slave 192.168.10.102:6379 192.168.10.102 6379 @ mymaster 192.168.10.101 6379
# ----------此 Slave 同步完成,可以继续下一个 Slave 的 reconfig 操作----------
* +slave-reconf-done slave 192.168.10.102:6379 192.168.10.102 6379 @ mymaster 192.168.10.101 6379
# ----------故障转移结束----------
+failover-end master mymaster 192.168.10.101 6379
# ----------故障转移成功后,各个 Sentinel 实例开始监控新的 Master----------
+switch-master mymaster 192.168.10.101 6379 192.168.10.103 6379
* +slave slave 192.168.10.102:6379 192.168.10.102 6379 @ mymaster192.168.10.103 6379
* +slave slave 192.168.10.101:6379 192.168.10.101 6379 @ mymaster192.168.10.103 6379
+sdown slave 192.168.10.101:6379 192.168.10.101 6379 @ mymaster192.168.10.103 6379
查看主从信息
此时再查看 192.168.10.102 和 192.168.10.103 的环境,发现 103 已切换为主节点,且从节点只有 102 是因为 101 还未重启,重启以后将作为从节点加入到环境中。
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=192.168.10.102,port=6379,state=online,offset=137591,lag=1
master_replid:1f9f9c105cb08669a2e45c6499d5f1dddc72bebd
master_replid2:27bbf26c1a482a3d2533e121739468fa1950f8cf
master_repl_offset:137877
second_repl_offset:30906
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:137877
重启 192.168.10.101 以后,Sentinel 日志如下:
# ----------⻆色转换为 Slave----------
* +convert-to-slave slave 192.168.10.101:6379 192.168.10.101 6379@ mymaster 192.168.10.103 6379
查看 192.168.10.101 主从信息如下:
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:192.168.10.103
master_port:6379
master_link_status:up
master_last_io_seconds_ago:1
master_sync_in_progress:0
slave_repl_offset:379722
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:1f9f9c105cb08669a2e45c6499d5f1dddc72bebd
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:379722
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:379271
repl_backlog_histlen:452
再次查看 192.168.10.103 主从信息,如下则表示一次主从切换成功完成。
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.10.102,port=6379,state=online,offset=397866,lag=1
slave1:ip=192.168.10.101,port=6379,state=online,offset=397866,lag=0
master_replid:1f9f9c105cb08669a2e45c6499d5f1dddc72bebd
master_replid2:27bbf26c1a482a3d2533e121739468fa1950f8cf
master_repl_offset:397866
second_repl_offset:30906
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:397866
查看主从配置
以下是原来的 192.168.10.101 的配置文件,文件末尾发生了如下改变,添加只读配置,复制配置。
# 从节点只读
replica-read-only yes
# Generated by CONFIG REWRITE
pidfile "/var/run/redis.pid"
user default on #8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca12020c923adc6c92 ~* +@all
replicaof 192.168.10.103 6379
以下是原来的 192.168.10.102 的配置文件,文件末尾发生了如下改变,复制节点改为了 103。
replica-read-only yes
replicaof 192.168.10.103 6379
# Generated by CONFIG REWRITE
pidfile "/var/run/redis.pid"
user default on #8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca12020c923adc6c92 ~* +@all
以下是原来的 192.168.10.103 的配置文件,文件末尾发生了如下改变,已经移除了复制配置。
# Generated by CONFIG REWRITE
2 pidfile "/var/run/redis.pid"
3 user default on #8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca1
2020c923adc6c92 ~* +@al
自动故障迁移流程
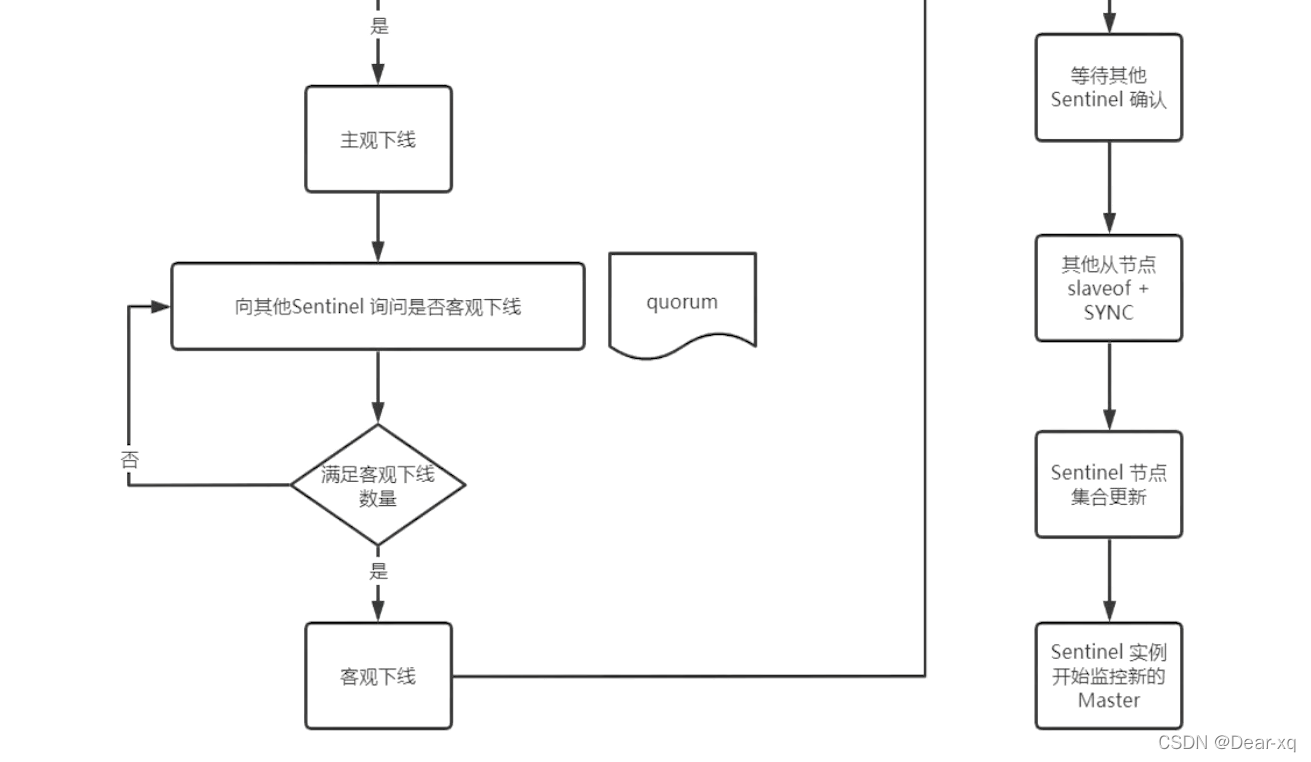
节点管理
添加 Sentinel
基于 Sentinel 自动发现机制,添加一个新 Sentinel 是非常简单的。你只需要启动配置 sentinel monitor mymaster 监视当前活动主服务器的新 Sentinel,10s 内 Sentinel 将获得其他 Sentinel 列表及被监控 Master 的所有 Slave 信息。
添加多个 Sentinel
建议一个一个添加,等待其他 Sentinel 已经能和新 Sentinel 通信,再添加下一个。因为新增 Sentinel 有可能失败,一个一个添加 Sentinel 能有效保证大多数 Sentinel 都是正常的。一般每 30s 添加一个 Sentinel 是比较常见的。
添加结束后,可用命令 SENTINEL MASTER mastername 检查所有 Sentinel 是否已经完全获取到所有 Master 的信息。
删除 Sentinel
Sentinel 不会完全清除已经添加过的 Sentinel 信息,即使被删除的 Sentinel 很长时间无法访问,因为 要尽量减少其他 Sentinel 的配置版本的更新。
因此为了移除一个 Sentinel,在没有网络隔离的情况下应遵循以下步骤:
1. 停止要删除的 Sentinel 进程。
2. SENTINEL RESET * 向所有其他 Sentinel 实例发送命令(*如果您只想重置一个主机,则可以使用确切的主机名代替)。一个接一个,在两次实例之间至少等待30秒。
3. 执行命令 SENTINEL MASTER mastername 检查每个 Sentinel 显示的 Sentinel 数量是否一致。
删除旧的 Master 或无法访问的 Slave
Sentinel 不会完全清除指定 Master 的 Slave,即使 Slave 长时间无法访问。在故障转移后,一旦旧 Master 再次可用,会自动成为新 Master 的 Slave,此时,新 Master 和新 Slave 会组成新的主从复制 架构。
若想从 Sentinel 监控的 Master/Slave 列表里永久删除一个 Slave,在停止 Slave 进程后,你需要向所 有 Sentinel 发送命令 SENTINEL RESET mastername,重置 mastername 所有状态信息。
故障迁移一致性
这里用到了分布式一致性的算法Raft共识算法,就是怎样选举Sentinel节点为领头节点
1)Sentinel自动故障迁移使用Raft算法来选举领头(leader)Sentinel ,从而确保在一个给定的周期 (epoch)里,只有一个领头产生。
2)这表示在同一个周期中, 不会有两个 Sentinel 同时被选中为领头,并且各个 Sentinel 在同一个节点 中只会对一个领头进行投票。
3)更高的配置节点总是优于较低的节点,因此每个 Sentinel 都会主动使用更新的节点来代替自己的配 置。
简单来说,我们可以将Sentinel配置看作是一个带有版本号的状态。一个状态会以最后写入者胜出(lastwrite-wins)的方式(也即是,最新的配置总是胜出)传播至所有其他Sentinel。
TILT模式
Redis Sentinel 严重依赖系统时间:为了确认实例是否可用,他会记录最后一次回复 PING 的时间,并和 当前时间比较推断距离最后一次回复过去了多久。
然而,若系统时间发生非正常改变,或者系统非常繁忙,或进程由于某些原因阻塞,Sentinel 可能会出现一些问题。
TITL 模式是一种特殊的“保护”模式,Sentinel 在发生一些意料之外问题时,会进入这个模式,降低对系 统时间的依赖。
Sentinel 所做的就是记录之前的中断调用时间,并和当前调用时间对比:
如果两次调用时间之间的差距为负值(系统时钟调整到之前某个时间值), 或者非常大(超过 SENTINEL_TILT_TRIGGER 时间,默认为 2s), 那么 Sentinel 进入 TILT 模式。
如果 Sentinel 已经进入 TILT 模式, 那么 Sentinel 延迟退出 TILT 模式的时间。
当处于 TITL 模式,Sentinel 或持续监控所有状态,但:
停止处理请求。
当有实例向这个 Sentinel 发送 SENTINEL is-master-down-by-addr 命令时,Sentinel 返回负 值:因为这个 Sentinel 所进行的下线判断已经不再准确。
如果 TILT 可以正常维持 30 秒钟(SENTINEL_TILT_PERIOD 时长,默认为 30s), 那么 Sentinel 退 出 TILT 模式,TITL 模式是 Sentinel 的被动模式。














 2954
2954











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









