






线性表
- 读完本篇文章你能学会什么?(要求)
- 理解线性表的概念
- 熟练掌握线性表的基本运算
- 掌握线性表的顺序存储结构及基本运算
- 掌握线性表的链式存储结构及基本运算
- 掌握在顺序表和链表上算法设计的基本技能
- 理解顺序表和链表的优缺点
- 线性表的基本概念
线性表(Linear List)是一种线性结构,它是由若干个结点按照“一对一”的逻辑关系组织起来的有穷序列。当线性表的长度为0时我们称它为空表,记为()。数据元素又称结点,当线性表的长度大于0时,线性表可表示为(a1,a2,a3......an),a1称为头结点,an称为尾结点(终端结点)。对任意一个结点(除头结点和尾结点)任意一个结点都有一个直接前驱和直接后继。a2的前驱是a1,a2的后继是a3。
基本特征:线性表中的结点具有“一对一”的关系,如果结点数不为0,除起始结点没有直接前驱外,其他每个结点有且仅有一个直接前驱;除尾结点没有直接后继外,其他每个结点有且仅有一个直接后继。
线性表中,每个结点可以代表不同的意义。在不同应用中各不相同。并且在一个解决方案中同一个线性表中的所有结点所代表的含义都是相同的。如每个结点可以表示一个数字,每个结点可以存储学生信息档案。当然可以存储更复杂的信息。
- 线性表的基本运算
- 初始化Initiate(L):建立一个空表L=(),L不含任何数据元素。
- 获取表长Length(L):返回线性表L的长度。
- 读取元素Get(L,i):返回线性表L的第i个数据元素。
- 定位Locate(L,e):查找线性表L中与e相同的数据元素值返回第一个,如果没有返回0。
- 插入Insert(L,i,e):在线性表L中的第i个位置插入e。
- 删除Delete(L,i):删除线性表L中的第i个元素。
- 输出Show(L):输出线性表的所有数据元素值。
- 线性表的顺序存储结构
线性表的顺序存储结构是这样的:

顺序存储结构是最简单的一种存储方式,对于线性表这种逻辑结构我们可以通过数组转换成存储结构。
顺序表的顺序存储结构:将表中的结点一起存放在计算机内存中的连续空间内,数据元素在顺序表的邻接关系就是它们在存储空间中的邻接关系。线性表的顺序存储结构是简单的,一般使用数组来实现。
【例1】学生档案信息标的顺序存储实现
typedef struct
{
int studentID; //学号
char name[8]; //名字
char sex[2]; //性别
int age; //年龄
int score; //成绩
}DataType; //定义一个学生信息档案的结构
typedef struct
{
DataType data[MAXSIZE]; //存放数据的数组
int length; //存放表长度
}SeqList;
SeqList student; //建立空表,此时student表中没有任何数据元素预先定义一个MAXSIZE宏定义常量,作为数组的最大长度。数据域data是一个数组,线性表的n个元素分别存在数组中的0—(length-1)中。

- 线性表的基本运算在顺序表中的实现
插入Insert(L,i,e):在线性表L中的第i个位置插入e。无返回值。
//实现思路:从表的最后一个结点开始遍历到第i个位置,将i和i后的元素向后的所有结点向后移动一个位置,将e插入到i的位置
void Insert(SeqList L, int i, DataType e)
{
int n;
if (L.length == MAXSIZE)
{
cout << "表已满" << endl;
exit(0);
}
if (i<1 || i>L.length)
{
cout << "位置出错" << endl;
exit(0);
}
for (n = L.length; n >= i; n--)
{
L.data[n + 1] = L.data[n];
}
L.data[i] = e;
L.length++;
}删除Delete(L,i):删除线性表L中的第i个元素。
//实现思路:从表的第一个结点开始遍历到第i个位置,将i和i后的结点向前移动一个位置,把最后一个结点设置为NULL(其实不用设置为空,表长度减去1就好了)。
void Delete(SeqList L,int i)
{
int n;
if (i<1 || i>L.length)
{
cout << "位置出错" << endl;
exit(0);
}
for (n = i; n < L.length; n++)
{
L.data[n] = L.data[n + 1];
}
L.length--;
}定位Locate(L,e):查找线性表L中与e相同的数据元素值返回第一个,如果没有返回0。
//实现思路:遍历整表,如果不相等继续往下遍历,一一对比,如果匹配不到返回0
int Locate(SeqList L, DataType e)
{
int i = 0;
while ((i<L.length)&&(L.data[i]!=e))
{
i++;
}
if (i < L.length)
return i + 1;
else
return 0;
}输出Show(L):输出线性表的所有数据元素值。
//实现思路:直接遍历整表
void Show(SeqList L)
{
int i;
for (i = 0; i = L.length - 1; i++)
{
cout << "学号:" << L.data[i].studentID << endl;
cout << "名字:" << L.data[i].name << endl;
cout << "性别" << L.data->sex << endl;
cout << "年龄:" << L.data[i].age << endl;
cout << "成绩:" << L.data[i].score << endl;
}
}- 顺序表实现算法的分析
从算法实现中可以看出,在顺序表实现算法中最频繁的操作就是数据元素的比较和移动。因此我们在分析时,一个最重要的指标就是数据元素比较和移动的次数。
在插入算法中,元素移动的次数不仅与顺序表的长度有关还与位置i相关。在此算法中,可以的处插入算法的的平均移动次数为n/2,其时间复杂度是O(n)。
在顺序表上做插入运算平均速度要移动表中一半的结点。由此可见,当n很大时,算法效率较低。
删除算法最坏情况下元素移动为n-1次,时间复杂度为O(n),平均移动次数为(n-1)/2,时间复杂度为O(n)。
定位算法最坏情况下需要查找n次,时间复杂度为O(n)。因此平均查找次数为n/2次,时间复杂度为O(n)。
对于获取表长和读取元素算法,其时间复杂度为O(1)。
通过以上分析可知,顺序表的插入、删除算法在时间性能方面并不理想。之后会对线性表的链式存储结构分析,并对两种结构的算法实现进行分析。
- 线性表的链式存储结构
线性表的链式存储结构类似这样的:
线性表的常见链式存储结构有单链表,双链表,循环列表,双向循环列表。这其中最简单的就是单链表,我们将讨论一下单链表算法的实现。
线性表的链式存储结构:这种结构简称为链表,将表中的结点一起存放在计算机内存中的空间内,可以是不连续的空间,链表分为两个部分:数据域和指针域。数据域顾名思义是用来存储数据的。那么指针域是什么?如果存储空间不是连续的我们怎么知道结点的直接前驱和直接后继呢?前辈们很聪明,设计了一种方法来解决上述问题。
指针域:每一个结点包括 数据域 和指向链表中下一个结点的 指针 (即下一个结点的地址)。如果链表每个结点中只有一个指向后继结点的指针,则该链表称为单链表。
这样我们就可以知道各个结点的直接前驱和直接后继了。
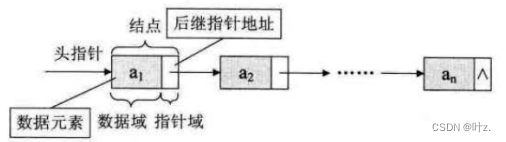
像这样,所有的结点通过指针链接成一个链表,head称为头指针,该指针指向单链表的第一个结点。可以用头指针变量名命名一个链表,“head链表”或者“链表head”。链表的头结点相当于火车头一样,它没有直接前驱,链表的最后一个结点称为尾结点,他就想火车的最后一节车厢,没有后继结点。其他结点想或者的其他车厢一样,有且仅有一个直接前驱和直接后继。头结点指向下一个结点,倒数第二个结点指向尾结点,尾结点指向NULL。(如果尾结点指向头结点那么就是循环链表)。如果头结点没有后继,此时head指向NULL,说明此时链表为空。我们不用考虑链表存在溢出的情况,因为链表在储存空间内不是连续的,只有内存空间满了,才会出现异常,而此时已经宕机了。
【例2】学生档案信息列表的类型完整描述如下:
typedef struct
{
int studentID; //学号
char name[8]; //名字
char sex[2]; //性别
int age; //年龄
int score; //成绩
}DataType; //定义一个学生信息档案的结构
typedef struct node
{
DataType data; //数据域
struct node *next; //指针域
}Node,*LinkList;
LinkList head;为方便运算实现,在单链表的第一个结点之前增设一个类型相同的结点称为头结点,其他结点称表结点。表结点中第一个和最后一个结点称为首结点和尾结点。头结点的数据域可以不存任何信息也可以存放一个特殊标志或表长度,也可以根据算法的需要定义。
- 线性表的链式存储结构算法实现
初始化Initiate(L):建立一个空表L=(),L不含任何数据元素。
//空表由一个头指针和一个头结点组成。因此初始化一个单链表需要创建一个头结点并将其指针域设为NULL(表示该节点不指向任何结点,此时表为空),然后用一个LinkList类型的变量指向新创建的结点。
LinkList Initiate()
{
LinkList head;
head = new Node;
head->next = NULL;
return head;
}建立一个链表的步骤:1.初始化调用Initiate 2.创建表结点(采用动态内存分配的方法)(这一步时我们可以创建一个全局变量用来存表的长度,创建一个结点就+1。这样获取表长的算法复杂度将变成O(1))。3.前一个结点指向新的表结点,表结点指向NULL。(尾插法,当然也可以采用头插法)。
获取表长Length(L):返回线性表L的长度。
//这个算法中我们要获取表结点的个数,这只一个工作指针p,初始时,p指向head,并设置计数器初始值为0。遍历整表,每循环一次,计数器变量加1。返回计数器(int型)。
int Length(LinkList L)
{
Node *p = L;
int cnt = 0;
while (p->next!=NULL)
{
p = p->next;
cnt++;
}
return cnt;
}读取元素Get(L,i):返回线性表L的第i个数据元素。
//从前向后遍历一直到i的位置返回i
node * Get(LinkList L, int i)
{
int n;
Node *p;
p = head->next;
if (i<1 || i>Length(L))
{
cout << "位置错误" << endl;
exit(0);
}
for (n = 1; n < i; n++)
{
p = p->next;
}
return p;
}定位Locate(L,e):查找线性表L中与e相同的数据元素值返回第一个,如果没有返回0。
//循环遍历表,一一对比。
int Locate(LinkList L, DataType e)
{
Node *p = L;
p = p->next;
int i = 0;
while (p!=NULL&&p->data!=e)
{
i++;
p = p->next;
}
if (p != NULL)
return i + 1;
else
return 0;
}插入Insert(L,i,e):在线性表L中的第i个位置插入e。
再讲单链表的插入操作时我们先回忆一下顺序表的插入操作。在顺序表中的实现思路:从表的最后一个结点开始遍历到第i个位置,将i和i后的元素向后的所有结点向后移动一个位置,将e插入到i的位置。因为顺序表是连续的空间所以需要一个一个移动。而单链表就不用了,我们直接横插一刀。
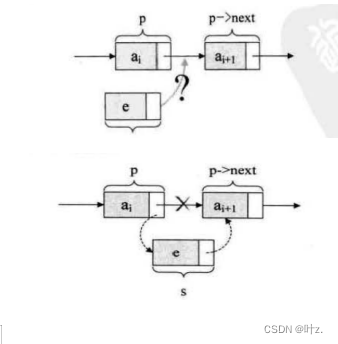
//我们先给插入的结点申请一个空间,然后对它进行操作(这里省略),然后从第一个结点遍历到第i个结点前,将新结点的指针域指向i前的结点的指针域,i前一个结点的指针域指向新结点。(如上图的操作)。与上图变量名不同,注意区别。
void Insert(LinkList L, int i, DataType e)
{
Node *p, *q;
if (i == 1)
q = L;
else
q = Get(L, i - 1);
if (q == NULL)
{
cout << "位置错误" << endl;
exit(0);
}
else
{
p = new Node;
p->data = e;
p->next = q->next;
q->next = p;
}
}删除Delete(L,i):删除线性表L中的第i个元素。
再讲单链表的删除操作时我们先回忆一下顺序表的删除操作,在顺序表中实现思路:从表的第一个结点开始遍历到第i个位置,将i和i后的结点向前移动一个位置,把最后一个结点设置为NULL(其实不用设置为空,表长度减去1就好了)。而单链表就不用了,我们直接给它掏出来。
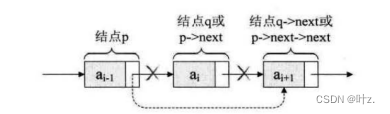
//从第一个结点遍历到第i个结点前,将这个结点的指针域指向i结点的指针域,然后释放i结点的空间。
void Delete(LinkList L, int i)
{
Node *q,*p;
if (i == 1)
q = L;
else
q = Get(L, i - 1);
if (q != NULL && q->next != NULL)
{
p = q->next;
q->next = p->next;
delete p;
}
else
{
cout << "位置错误" << endl;
exit(0);
}
}输出Show(L):输出线性表的所有数据元素值。
//遍历整表
void Show(LinkList L)
{
Node *p = L;
while (p->next!=NULL)
{
cout << "学号:" << p->data.studentID << endl;
cout << "名字:" << p->data.name << endl;
cout << "性别:" << p->data.sex << endl;
cout << "年龄:" << p->data.age << endl;
cout << "成绩:" << p->data.score << endl;
p = p->next;
}
}- 链表实现算法的分析
链表实现算法的分析方法域顺序表相同。
在获取表长和获取元素的算法中,其时间复杂度则为O(n),而顺序表实现同种功能的算法的时间复杂度则是O(1)。由此可见在这个实现算法上,链表是不如顺序表的。
在删除和插入的算法中,其时间复杂度是O(1),而顺序表实现同种功能的算法的时间复杂度则是O(n)。由此可见在这个实现算法上,顺序表是不及链表的。
因此我们要适当的选择链表和顺序表,来设计算法。
- 思考与练习
- 设r指向单链表的最后一个结点,要在最后一个结点后面插入一个s所指的结点,需要怎么做?( );r=s;r->next=NULL;
- 在单链表中,指针p所指的结点为最后一个节点的条件是( )。
- 在带头结点的单链表L中,第一个数据元素的指针是( )。
- 在双向循环链表中,在指针p所指结点前插入指针s所指的结点,需要执行下列语句:s->next=p;s->prior=p->prior;p->prior;( )=s;
- 带头结点的双向循环链表L为空的条件是( )。
- 若某线性表最常用的操作是在最后一个结点之后插入一个新节点或删除最后一个结点,要使操作时间最少,应选择()存储结构。
A.无头结点的单项列表
B.带头结点的单向链表
C.带头结点的双循环链表
D.不带头结点的单循环链表
- 在表长为n的顺序表中做删除运算,其平均时间复杂度为()。
A.O(1)
B.O(n)
C.O(n^2)
D.O(2)
- 在表长为n的顺序表中做插入运算,平均要移动的结点数为()。
A.n/4
B.n/3
C.n/2
D.N
- 若线性表最常用的操作是存取第i个元素及其前驱的值,那么最节省操作时间的存储方式是()。
A.单链表
B.双向循环链表
C.单循环链表
D.顺序表
- 设顺序表有9个元素,在第三个元素插入一个元素,需要移动结点个数为()。
- A.a
- B.6
- C.7
- D.9
- 从逻辑关系来看,一个数据元素的直接前驱为0个或一个的数据结构只有()。
A.线性结构
B.树形结构
C.线性结构和树形结构
D.线性结构和图结构
- 叙述一下概念:指针变量、头指针、尾指针、头结点、尾结点、首结点,并说明头指针和头结点的作用。
- 何时选用顺序表,何时选用链表?
- 编写一个学生档案管理系统
- 编写一个图书馆书籍管理系统
答案:
(1)r->next=s(2)p->next==NULL(3)L->next(4)(s->prior)->next(5)(L->next=L)&&(L->prior==L)
选择: CBCDCC
参考:
其他各种链表














 1327
1327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









