







Java基础常见面试题总结
基础概念与常识
Java语言有哪些特点?
1.简单易学;
2.面向对象(封装,继承,多态);
3.平台无关性(JVM实现了平台无关性);
4.支持多线程(C++11之前 没有内置多线程机制,因此必须调用操作系统的多线程来进行多线程设计,而Java提供了多线程支持);
5.可靠性(具有异常处理和自动内存管理机制);
6.安全性(Java本身的设计就提供了多重防护机制如控制访问符、限制程序直接访问操作系统资源);
7.高效性(通过JIT编译器等技术的优化,Java运行的效率还不错)
8.支持网络编程并且很方便;
9.编译与解释并存;
“Write Once, Run Anywhere(一次编写,随处运行)”这句宣传口号,真心经典,流传了好多年!以至于,直到今天,依然有很多人觉得跨平台是 Java 语言最大的优势。实际上,跨平台已经不是 Java 最大的卖点了,各种 JDK 新特性也不是。目前市面上虚拟化技术已经非常成熟,比如你通过 Docker 就很容易实现跨平台了。在我看来,Java 强大的生态才是!----JavaGuide
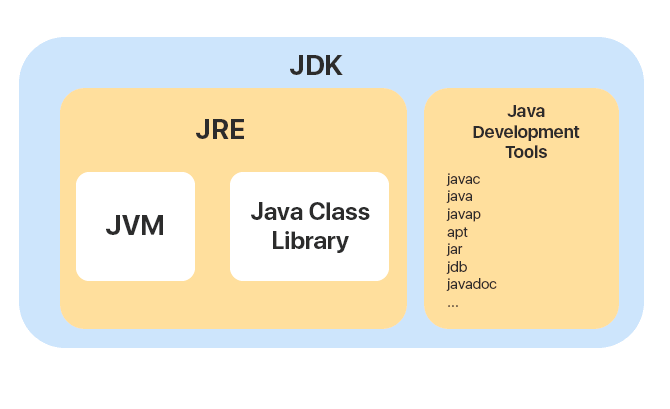
JVM & JDK & JRE
JVM
Java虚拟机(JVM)是运行Java字节码的虚拟机。JVM有针对不同系统的特定实现,目的是使用相同的字节码,都会给出相同的结果。字节码和不同系统上的JVM是实现Java语言“一次编译,随处运行”的关键
JVM并不只有一种,只要满足JVM规范,每个人都可以开发自己的专属JVM;
JDK和JRE
JDK(Java Development Kit),他是功能齐全的Java SDK,是提供给开发者使用,能够创建和编译Java程序的开发套件。包含了JRE、编译Java源码的Javac以及一些其他工具(Javadoc、jdb、jconsole、javap等等)
JRE(Java Runtime Environment)是Java运行时的环境。他是已经运行已编译Java程序所需的内容的集合,主要包括Java虚拟机(JVM)、Java基础类库(Class Library)
总的来说,JRE是Java运行时的环境,仅包含Java应用程序的运行时环境和必要类库。JDK包含了JRE,同时还包括了其他工具,用于Java应用程序的开发和调试。
什么是字节码,采用字节码的好处?
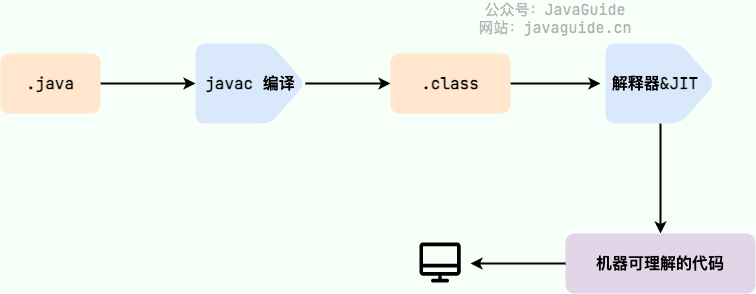
在Java中JVM可以理解的代码叫做字节码(拓展名为.class的文件),他不面向任何特定的处理器,只面向虚拟机。
Java通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以Java程序运行起来还是相对高效的。而且由于字节码并不针对特定的机器,因此Java程序无需重新编译即可在多种不同的操作系统的计算机上运行。
Java 程序从源代码到运行的过程如下图所示:
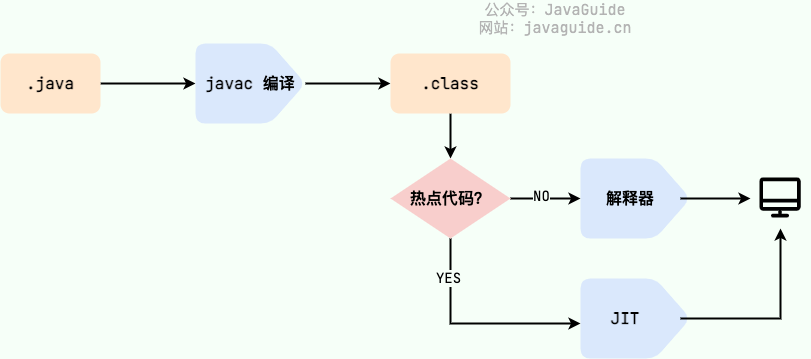
.class->机器码这一步,JVM类加载器首先加载字节码文件,然后通过解释器逐行解释执行,这种方式执行速度相对比较慢,而且有些方法和代码块经常需要被调用(热点代码),所以后面引进了JIT(Just In Time Commpliation)编译器,JIT属于运行时编译。当JIT编译器完成第一次编译后,会将字节码对应的机器码保存起来,下次可以直接使用。这也解释了为什么说 Java 是编译与解释共存的语言 。
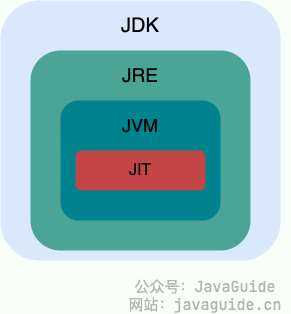
JDK、JRE、JVM、JIT 这四者的关系如下图所示。
为什么说Java语言“编译与解释并存”?
高级编程语言按照程序执行方式分为两种:
- 编译型:编译型语言会将源代码一次性翻译成可以被该平台执行的机器码。一般情况下,该类型开发效率较低,执行速度较快。(C、C++、GO、Rust)
- 解释型:解释型语言会通过解释器一句一句将代码解释为机器代码后再执行。该类型开发较快,执行速度较慢。(Python、JavaScript、PHP)
为什么说Java语言“编译与解释并存”?
因为Java语言既有编译型语言特征也有解释型语言特征。因为Java程序要经过先编译,后解释两个步骤,由Java编写的程序先经过编译步骤,生成字节码,这种字节码再由Java解释器来解释运行。
AOT有什么优点?为什么不全部使用AOT?
JDK9新引入了一种新的编译模式AOT(Ahead of Time Compilation)。这种模式会在程序被执行前就将其编译成机器码,属于静态编译(C++,Rust,GO就是静态编译)。AOT避免了JIT预热等各方面开销,可以提高Java程序的启动速度,避免预热时间长。并且,AOT还能减少内存占用和增强Java程序的安全性(AOT编译后的代码不容易被反编译和修改),特别适用于云原生场景。
AOT的优势在于启动时间,内存占用和打包体积。JIT的优势在于具备更高的极限处理能力,可以降低请求的最大延迟。
既然 AOT 这么多优点,那为什么不全部使用这种编译方式呢?
两者各有优点,AOT更适合云原生场景,对微服务架构支持也比较友好,AOT无法支持Java一些动态特性,如反射、动态代理、动态加载等。然而很多的框架和库(Spring)都用到了这些特性。如果只使用AOT编译就没办法使用这些框架和库了。
Java和C++的区别?
Java和C++都是面向对象语言,都支持封装、继承和多态
- Java不提供指针来直接访问内存,程序内存更加安全
- Java的类是单继承的,C++支持多重继承;但是Java接口可以多继承
- Java有自动内存管理垃圾回收机制(GC),不需要手动释放无用内存。
- C++同时支持方法重载和操作符重载,Java只支持方法重载(操作符重载增加了复杂性,与Java最初的设计思想不符)
基本语法
标识符和关键字区别?
在编写程序时,需要大量为程序,方法,类,变量等取名字,于是简单来说标识符就是一个名字
有些标识符,Java已经赋予了其特殊的含义,只能用于特定的地方,这些特殊的标识符就是关键字。
Java关键字:
这里列举截止到Java17所有的关键字及其功能:
- abstract 声明一个类为抽象类或一个方法为抽象方法。
- assert 断言表达式使用,用来对某些东西进行判断,如果判断失败会抛出错误,默认无效,需要添加启动参数才能开启,一般在测试环境中使用。
- boolean 基本数据类型,布尔类型,只有true和false两种结果。
- break 用于for/while循环语句中对循环提前终止,以及在switch语句中结束当前case语句块,防止程序继续向下执行。
- byte 基本数据类型,字节类型,可以表示1字节的数据,取值范围为-128 到 127。
- case 用于在switch语句中判断条件,匹配后执行相应的代码块。
- catch 用于捕获异常,处理try块中抛出的异常。
- char 基本数据类型,字符类型,表示单个字符(16位Unicode字符)表示范围为’\u0000’ (0) 到 ‘\uffff’ (65535)
- class:声明一个类型,此外,使用
类名.class用于获取指定类型的Class对象。 - const 保留关键字,无实际用途。
- continue:用于for/while循环语句中跳过当前循环的剩余代码,直接开启下一轮循环。
- default 在switch语句中表示默认情况,同时,在接口中也可以为抽象方法指定默认实现(仅Java8之后可用)
- do 用于do-while循环中定义循环体,循环开始前会执行一次循环。
- double 基本数据类型,双精度浮点数,表示范围为4.9e-324 到 1.8e+308,精度为15位小数。
- else 与if语句一起使用,表示条件不成立时执行的代码块,也可以与if组合为else if判断。
- enum 声明枚举类型。
- extends 声明类继承另一个类,在接口中可以继承多个其他接口,在泛型类中List<? extends Number>表示为类型参数设定上界。
- final 声明一个变量的值不可修改、一个类不能被继承、一个方法不能被子类重写。
- finally 声明一个代码块,在异常处理时,无论是否发生异常都会执行。
- float 基本数据类型,单精度浮点数,表示范围为1.4e-45 到 3.4e+38,精度为6-7位小数。
- for 创建for循环语句。
- if 创建条件判断语句。
- implements 表示一个类实现的接口,可以跟一个或多个接口。
- import 用于导入包或类。
- instanceof 用于判断对象是否为指定类型。
- int 基本数据类型,整数类型,取值范围为-2^31 到 2^31-1。
- interface:定义接口。
- long 基本数据类型,长整数类型,取值范围为-2^63 到 2^63-1。
- native 用于声明一个本地方法,方法的实现使用非Java语言编写,一般为C或C++编写,详情请看JVM篇JNI相关介绍。
- new 用于实例化对象。
- null 表示空对象引用。
- package 用于声明包。
- private 权限修饰符,表示私有的,仅在类的内部可见。
- protected 权限修饰符,表示受保护的,仅当前类和子类可见。
- public 权限修饰符,表示公共的,对所有类可见。
- record 用于声明记录类型,Java14新增类型。
- return 用于方法返回值。
- sealed 用于声明密封类型,Java17新增类型。
- non-sealed 用于声明类型为非密封类型,Java17新增类型。
- short 用于声明短整型变量。
- static 将类、方法、属性声明为静态的。
- strictfp 用于确保浮点运算结果一致。
- super 表示父类对象,在泛型类中List<? super Integer>表示为类型参数设定下界,在编写子类构造方法时,默认需要优先执行super()调用父类构造方法(无参情况下可省略)在Java22之后super不再要求强制优先调用。
- switch 用于多重条件判断,在Java13之后可以使用switch表达式。
- synchronized 用于线程同步加锁。
- this 表示当前对象,使用this()可以调用当前类型的构造方法。
- throw 抛出异常对象。
- throws 在方法声明中指定可能被抛出的异常。
- transient 声明变量在对象序列化时不参与序列化。
- try 异常捕获的起始块。
- void 表示没有返回值。
- volatile 用于可能会被多个线程同时修改的变量,使其保证线程之间的可见性,禁止指令重排,但无法保证原子性,详情请见JUC篇视频教程。
- while 用于创建while循环,当条件满足时执行代码块。
移位运算符
<< :左移运算符,向左移若干位,高位丢弃,低位补零。x << 1,相当于 x 乘以 2(不溢出的情况下)。
>> :带符号右移,向右移若干位,高位补符号位,低位丢弃。正数高位补 0,负数高位补 1。x >> 1,相当于 x 除以 2。
>>> :无符号右移,忽略符号位,空位都以 0 补齐。
continue、break和return区别?
1.continue: 跳出当前这一次的循环,继续下一次循环
2.break: 跳出整个循环体,继续执行循环下面的语句。
3.return: 跳出所在的方法,结束该方法运行。
基本数据类型
Java中有8种基本数据类型:
- 6种数字型:
- 4中整数型:byte、short、int、long
- 2种浮点型:float、double
- 1种字符类型:char
- 1种布尔类型:boolean
对应的包装类型:Byte、Short、Integer、Long、Float、Double、Character、Boolean
基本数据类型和包装类型的区别?

用途:除了定义一些常量和局部变量之外,我们在其他地方比如方法参数、对象属性中很少会使用基本类型来定义变量。并且,包装类型可用于泛型,而基本类型不可以。
存储方式:基本数据类型的局部变量存放在 Java 虚拟机栈中的局部变量表中,基本数据类型的成员变量(未被 static 修饰 )存放在 Java 虚拟机的堆中。包装类型属于对象类型,我们知道几乎所有对象实例都存在于堆中。
占用空间:相比于包装类型(对象类型), 基本数据类型占用的空间往往非常小。
默认值:成员变量包装类型不赋值就是 null ,而基本类型有默认值且不是 null。
比较方式:对于基本数据类型来说,== 比较的是值。对于包装数据类型来说,== 比较的是对象的内存地址。所有整型包装类对象之间值的比较,全部使用 equals() 方法。
⚠️ 注意:基本数据类型存放在栈中是一个常见的误区! 基本数据类型的存储位置取决于它们的作用域和声明方式。如果它们是局部变量,那么它们会存放在栈中;如果它们是成员变量,那么它们会存放在堆中。
包装类型的缓存机制?
Java基本数据类型的包装类型大部分都用到了缓存机制来提升性能。
Byte、Short、Integer、Long这四种包装类默认创建了数值[-128, 127]的相应类型的缓存数据,Character创建了数值在[0, 127]范围的缓存数据,Boolean直接返回True或者False。
所有整型包装类对象之间值的比较,全部使用 equals 方法比较。
自动装箱与拆箱?原理?
什么是自动拆装箱?
- 装箱:将基本类型用它们对应的引用类型包装起来;
- 拆箱:将包装类型转换为基本数据类型;
Integer i = 10; //装箱
int n = i; //拆箱
装箱其实就是调用了包装类的valueOf()方法,拆箱调用了xxxValue()方法。
Integer i = 10等价于Integer i = Integer.valueOf(10)int n = i等价于int n = i.intValue();
如果频繁拆装箱的话,也会严重影响系统的性能。我们应该尽量避免不必要的拆装箱操作。
变量
成员变量与局部变量的区别

-
语法形式:从语法形式上看,成员变量是属于类的,而局部变量是在代码块或方法中定义的变量或是方法的参数;成员变量可以被
public,private,static等修饰符所修饰,而局部变量不能被访问控制修饰符及static所修饰;但是,成员变量和局部变量都能被final所修饰。存储方式:从变量在内存中的存储方式来看,如果成员变量是使用
static修饰的,那么这个成员变量是属于类的,如果没有使用static修饰,这个成员变量是属于实例的。而对象存在于堆内存,局部变量则存在于栈内存。生存时间:从变量在内存中的生存时间上看,成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动生成,随着方法的调用结束而消亡。
默认值:从变量是否有默认值来看,成员变量如果没有被赋初始值,则会自动以类型的默认值而赋值(一种情况例外:被
final修饰的成员变量也必须显式地赋值),而局部变量则不会自动赋值。
为什么成员变量有默认值?
1.变量存储的是内存地址对应的任意随机值,程序读取该值时会出现意外。
2.默认值有两种设置方式:手动和自动
方法
静态方法为什么不能调用非静态成员?
1.静态方法是属于类的,类加载时就会分配内存,可以通过类名直接访问。而非静态成员属于实例对象,只有在对象实例化后才存在,需要通过类的实例对象去调用。
2.在类的非静态成员不存在时静态方法就已经存在了,此时内存调用内存中不存在的非静态成员属于非法操作。
重载与重写
重载
发生在同一个类中(或者父类和子类之间),方法名必须相同,参数类型不同,个数不同,顺序不同,返回值和访问修饰符可以不同。
重写
重写发生在运行期,是子类对父类的允许访问的方法的实现过程进行重新编写。
1.方法名】参数列表必须相同,子类方法返回值类型应比父类方法返回值类型相同或更小,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类。
2.如果父类方法访问修饰符为 private/final/static 则子类就不能重写该方法,但是被 static 修饰的方法能够被再次声明。
3.构造方法无法被重写
面向对象基础
面向对象和面向过程的区别?
两者区别在于解决问题的方式不同:
- 面向过程把解决问题的过程拆分成一个个方法,通过一个个方法解决问题。
- 面向对象会先抽象出对象,然后对象执行方法来解决问题。
面向对象开发的程序一般更易维护、易服用、易扩展。
创建一个对象用什么运算符?对象实体与对象引用有何不同?
new运算符,new创建对象实例(对象实例在堆内存中),对象引用指向对象实例(对象应用存放在栈内存中)。
- 一个对象引用可以指向0或1个对象
- 一个对象可以有n个引用指向它
对象相等和引用相等区别
- 对象的相等一般比较的是内存中存放的内容是否相等。
- 引用相等一般指的是指向的内存地址是否相等
==和equals
面向对象的三大特征
封装
封装是指把一个对象的状态信息(也就是属性)隐藏在对象内部,不允许外部对象直接访问对象的内部信息。但是可以提供一些可以被外界访问的方法来操作属性。
继承
继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。通过使用继承,可以快速地创建新的类,可以提高代码的重用,程序的可维护性,节省大量创建新类的时间 ,提高我们的开发效率
关于继承如下 3 点请记住:
- 子类拥有父类对象所有的属性和方法(包括私有属性和私有方法),但是父类中的私有属性和方法子类是无法访问,只是拥有。
- 子类可以拥有自己属性和方法,即子类可以对父类进行扩展。
- 子类可以用自己的方式实现父类的方法。
多态
多态,顾名思义,表示一个对象具有多种的状态,具体表现为父类的引用指向子类的实例。
多态的特点:
- 对象类型和引用类型之间具有继承(类)/实现(接口)的关系;
- 引用类型变量发出的方法调用的到底是哪个类中的方法,必须在程序运行期间才能确定;
- 多态不能调用“只在子类存在但在父类不存在”的方法;
- 如果子类重写了父类的方法,真正执行的是子类覆盖的方法,如果子类没有覆盖父类的方法,执行的是父类的方法。
接口和抽象类有什么共同点和区别?
共同点:
- 都不能被实例化
- 都可以包含抽象方法
- 都可以有默认实现的方法(Java8可以用default关键字在接口中定义默认方法)
区别:
- 接口主要用于对类的行为进行约束,实现某个接口就具有了对应的行为。抽象类主要用于代码复用,强调的是所属关系。
- 一个类只能继承一个类,但是可以实现多个接口。
- 接口中的成员变量只能是
public static final类型的,不能被修改且必须有初始值,而抽象类的成员变量默认default,可以在子类中被重新定义,也可被重新赋值。
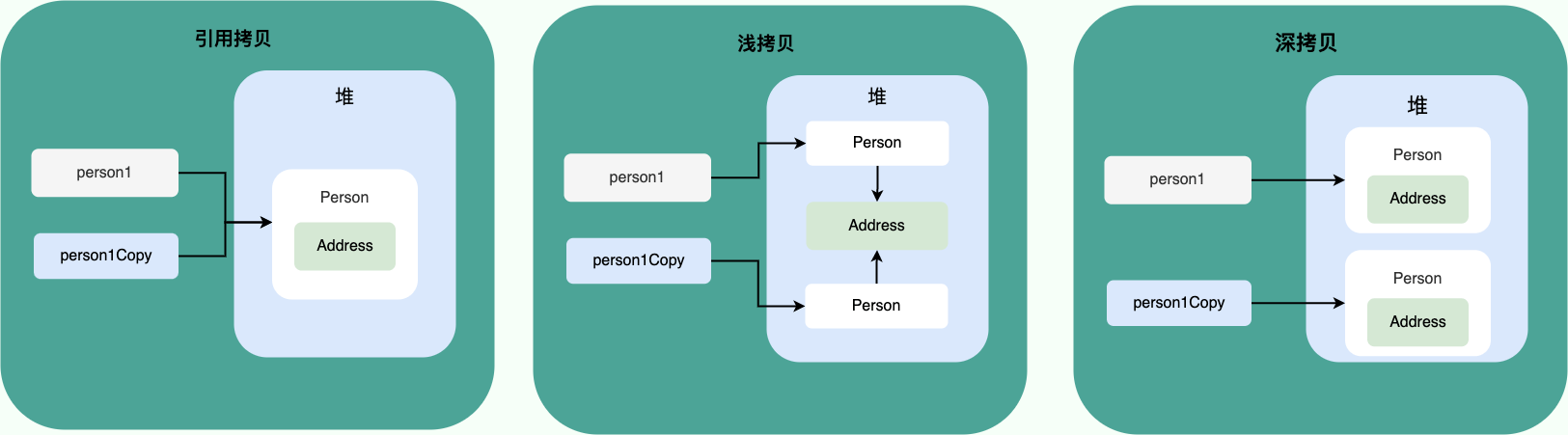
深拷贝和浅拷贝区别?什么是引用拷贝?
浅拷贝:浅拷贝会在堆上创建一个新的对象(区别于引用拷贝的一点),不过,如果原对象内部的属性是引用类型的话,浅拷贝会直接复制内部对象的引用地址,也就是说拷贝对象和原对象共用同一个内部对象。
深拷贝:深拷贝会完全复制整个对象,包括这个对象所包含的内部对象。
引用拷贝:引用拷贝就是两个不同的引用指向同一个对象。
Object
Object类常见方法?
/**
* native 方法,用于返回当前运行时对象的 Class 对象,使用了 final 关键字修饰,故不允许子类重写。
*/
public final native Class<?> getClass()
/**
* native 方法,用于返回对象的哈希码,主要使用在哈希表中,比如 JDK 中的HashMap。
*/
public native int hashCode()
/**
* 用于比较 2 个对象的内存地址是否相等,String 类对该方法进行了重写以用于比较字符串的值是否相等。
*/
public boolean equals(Object obj)
/**
* native 方法,用于创建并返回当前对象的一份拷贝。
*/
protected native Object clone() throws CloneNotSupportedException
/**
* 返回类的名字实例的哈希码的 16 进制的字符串。建议 Object 所有的子类都重写这个方法。
*/
public String toString()
/**
* native 方法,并且不能重写。唤醒一个在此对象监视器上等待的线程(监视器相当于就是锁的概念)。如果有多个线程在等待只会任意唤醒一个。
*/
public final native void notify()
/**
* native 方法,并且不能重写。跟 notify 一样,唯一的区别就是会唤醒在此对象监视器上等待的所有线程,而不是一个线程。
*/
public final native void notifyAll()
/**
* native方法,并且不能重写。暂停线程的执行。注意:sleep 方法没有释放锁,而 wait 方法释放了锁 ,timeout 是等待时间。
*/
public final native void wait(long timeout) throws InterruptedException
/**
* 多了 nanos 参数,这个参数表示额外时间(以纳秒为单位,范围是 0-999999)。 所以超时的时间还需要加上 nanos 纳秒。。
*/
public final void wait(long timeout, int nanos) throws InterruptedException
/**
* 跟之前的2个wait方法一样,只不过该方法一直等待,没有超时时间这个概念
*/
public final void wait() throws InterruptedException
/**
* 实例被垃圾回收器回收的时候触发的操作
*/
protected void finalize() throws Throwable { }
== 和 equals()的区别
==对于基本类型和引用类型作用效果是不同的:
- 对基本类型来说,
==比较的是值。 - 对引用数据来说,
==比较的是对象的内存地址。
equals()两种使用方法:
- 类没有重写equals()方法:通过equals()比较该类的两个对象是,等价于通过“==”比较
- 类重写了equals()方法:比较两个对象中的属性是否相等。
hashCode()有什么用?
hashCode() 的作用是获取哈希码(int 整数),也称为散列码。这个哈希码的作用是确定该对象在哈希表中的索引位置。
为什么要有hashCode?
当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashCode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashCode 值作比较,如果没有相符的 hashCode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashCode 值的对象,这时会调用 equals() 方法来检查 hashCode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
那为什么JDK还要同时提供这两个方法呢?
因为在一些容器里(如HashMap、HashSet)中,有了hashCode()之后,判断元素是否相等效率更高。
我们在前面也提到了添加元素进HashSet的过程,如果 HashSet 在对比的时候,同样的 hashCode 有多个对象,它会继续使用 equals() 来判断是否真的相同。也就是说 hashCode 帮助我们大大缩小了查找成本。
那为什么不只提供hashCode()方法呢?
因为两个对象的hashcode值相等并不代表两个对象就相等。
为什么两个对象hashCode相等他们也不一定是相等的?
因为 hashCode() 所使用的哈希算法也许刚好会让多个对象传回相同的哈希值。越糟糕的哈希算法越容易碰撞,但这也与数据值域分布的特性有关(所谓哈希碰撞也就是指的是不同的对象得到相同的 hashCode )。
总结下来就是:
- 如果两个对象的
hashCode值相等,那这两个对象不一定相等(哈希碰撞)。 - 如果两个对象的
hashCode值相等并且equals()方法也返回true,我们才认为这两个对象相等。 - 如果两个对象的
hashCode值不相等,我们就可以直接认为这两个对象不相等。
为什么重写equals()时必须重写hashCode()方法?
因为两个相等的对象hashCode值必须相等。如果equals方法判断两个对象是否相等的,那么这两个对象的hashCode值也要相等。
如果重写 equals() 时没有重写 hashCode() 方法的话就可能会导致 equals 方法判断是相等的两个对象,hashCode 值却不相等。
总结:
equals方法判断两个对象是相等的,那这两个对象的hashCode值也要相等。- 两个对象有相同的
hashCode值,他们也不一定是相等的(哈希碰撞)。
String
String、StringBuffer、StringBuilder的区别?
可变性
String是不可变的
线程安全性
String中的对象是不可变的,也就可以理解为常量,线程安全。StringBuffer 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder 并没有对方法进行加同步锁,所以是非线程安全的。
性能
每次对 String 类型进行改变的时候,都会生成一个新的 String 对象,然后将指针指向新的 String 对象。StringBuffer 每次都会对 StringBuffer 对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用 StringBuilder 相比使用 StringBuffer 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
对于三者使用的总结:
- 操作少量的数据: 适用
String - 单线程操作字符串缓冲区下操作大量数据: 适用
StringBuilder - 多线程操作字符串缓冲区下操作大量数据: 适用
StringBuffer
字符串常量池作用
字符串常量池 是 JVM 为了提升性能和减少内存消耗针对字符串(String 类)专门开辟的一块区域,主要目的是为了避免字符串的重复创建。
异常
Exception和Error区别?
Java中,所有异常都有一个共同祖先,java.lang包的Throwable类。
其中两个重要的子类:
- Exception:程序本身可以处理的异常,可以通过
catch来进行捕获。Exception又可以分为 Checked Exception (受检查异常,必须处理) 和 Unchecked Exception (不受检查异常,可以不处理)。 - Error:Error属于程序无法处理的错误。
finally中的代码一定会执行吗?
不一定!某些情况下不会。
比如finally之前虚拟机被终止运行,finally中的代码就不会被执行。
在以下 2 种特殊情况下,finally 块的代码也不会被执行:
- 程序所在的线程死亡。
- 关闭 CPU。
泛型
什么是泛型?作用是什么?
Java泛型是JDK5引入的新特性,使用泛型参数可以增强代码的可读性以及稳定性。
泛型的使用方式有哪几种?
泛型一般有三种使用方式:泛型类、泛型接口、泛型方法。
1.泛型类:
//此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型
//在实例化泛型类时,必须指定T的具体类型
public class Generic<T>{
private T key;
public Generic(T key) {
this.key = key;
}
public T getKey(){
return key;
}
}
//实例化
Generic<Integer> genericInteger = new Generic<Integer>(123456);
2.泛型接口:
public interface Generator<T> {
public T method();
}
//实现,不指定类型
class GeneratorImpl<T> implements Generator<T>{
@Override
public T method() {
return null;
}
}
//实现,指定类型
class GeneratorImpl<T> implements Generator<String>{
@Override
public String method() {
return "hello";
}
}
3.泛型方法:
public static < E > void printArray( E[] inputArray )
{
for ( E element : inputArray ){
System.out.printf( "%s ", element );
}
System.out.println();
}
//使用
// 创建不同类型数组:Integer, Double 和 Character
Integer[] intArray = { 1, 2, 3 };
String[] stringArray = { "Hello", "World" };
printArray( intArray );
printArray( stringArray );
反射
反射是框架的灵魂,它赋予了我们在运行时分析类以及执行类中方法的能力。通过反射可以获取任意一个类的所有属性和方法,还可以调用这些方法和属性。
反射的优缺点?
反射可以让我们的代码更加灵活、为各种框架提供开箱即用的功能提供的便利。但是,反射让我们在运行时有了分析操作类的能力的同时,也增加了安全问题,比如可以无视泛型参数的安全检查(泛型参数的安全检查发生在编译时)。另外,反射的性能也要稍差点,不过,对于框架来说实际是影响不大的。
注解
{
for ( E element : inputArray ){
System.out.printf( "%s ", element );
}
System.out.println();
}
//使用
// 创建不同类型数组:Integer, Double 和 Character
Integer[] intArray = { 1, 2, 3 };
String[] stringArray = { “Hello”, “World” };
printArray( intArray );
printArray( stringArray );
## 反射
反射是框架的灵魂,它赋予了我们在运行时分析类以及执行类中方法的能力。通过反射可以获取任意一个类的所有属性和方法,还可以调用这些方法和属性。
### 反射的优缺点?
反射可以让我们的代码更加灵活、为各种框架提供开箱即用的功能提供的便利。但是,反射让我们在运行时有了分析操作类的能力的同时,也增加了安全问题,比如可以无视泛型参数的安全检查(泛型参数的安全检查发生在编译时)。另外,反射的性能也要稍差点,不过,对于框架来说实际是影响不大的。
## 注解
`Annotation` (注解) 是 Java5 开始引入的新特性,可以看作是一种特殊的注释,主要用于修饰类、方法或者变量,提供某些信息供程序在编译或者运行时使用。















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









