






背景:实习工作内容,对接业务人员因采购原材料,想要获取铝琔的历史价格
目标字段:品名,日期,价格
目的:爬取ADC12-F的历史价格。
1.调用相关库
import pymysql
import requests
from bs4 import BeautifulSoup2.设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
page = requests.get('http://m.baotaigroup.com.cn/index/offer/hoffer/id/9.html', headers = headers)
page.encoding = 'utf8'#保证不乱码
soup = BeautifulSoup(page.text, "html.parser")3.解析网页,获取总页数
for num_page in soup.find_all("ul", class_="pagination"):#看下面图片框起来的内容
a=num_page.get_text()
print("a",a,type(a))#
print(a.split()[1])#只取“123456789”部分
len_page=len(a.split()[1])#页码数正好和上面字符串的长度一致
print('len(a.split()[1])',len_page)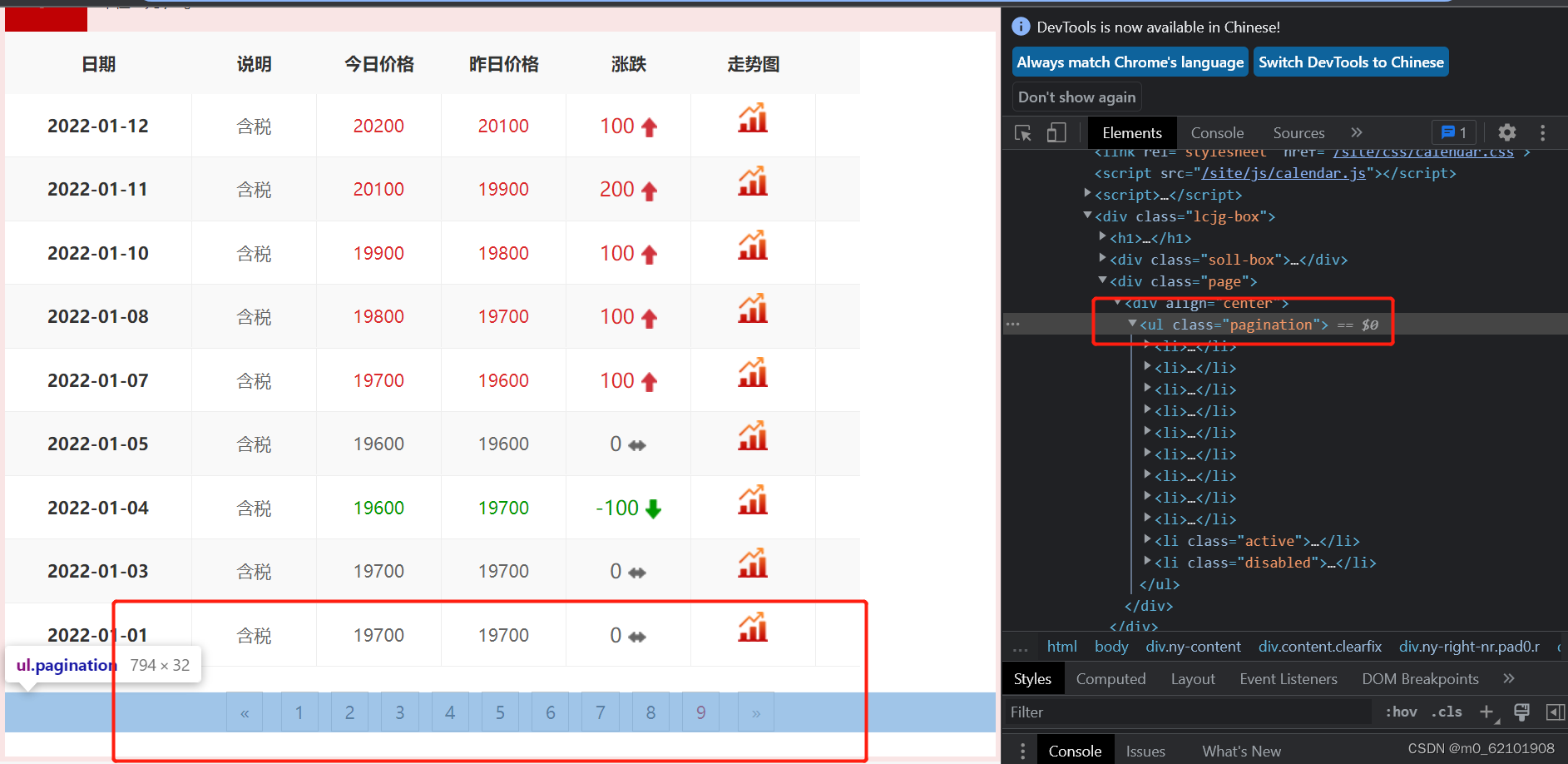
4.解析网页,选取目标字段
num = -1
pageNum = 0
for index in range(len_page):#有9页数据,循环获取,
pageNum = pageNum+1#更换网址
print('http://m.baotaigroup.com.cn/index/offer/hoffer/id/9.html?page='+str(pageNum))
pages = requests.get('http://m.baotaigroup.com.cn/index/offer/hoffer/id/9.html?page='+str(pageNum), headers=headers)
pages.encoding = 'utf8'#网页编码,有些网页是gb2312 等
soups = BeautifulSoup(pages.text, "html.parser")
print('1')
li_0=[]
i=1
for spw140 in soups.find_all("span", class_="w140"):
i+=1
w140=spw140.get_text()
#print('w140_-',w140)
#if w140 :
if i%5==3:#通过观察索引发现目标字段“价格”的位置
li_0.append(w140)#7121722
#print('li_0',li_0)
#li_0_new=pd.DataFrame(li_0) #
#print('li_0_new',li_0_new)
#print()
li_1=[]
for spw300 in soups.find_all("span", class_="w300"):
w300=spw300.get_text()
#print('w300_-',w300)
li_1.append(w300)
#print()
#print('li_1',li_1)
li_name=[] #增加品名列
for j in range(len(li_0)-1):
li_name.append('ADC12-F')#更换品名
#将上述三列目标字段(列表形式)转换成数据框格式:
data=pd.DataFrame({
'ITEM_NAME':li_name[:],
'DATE_1':li_1[1:],
'TJPRICE':li_0[1:]
})
print('data',data)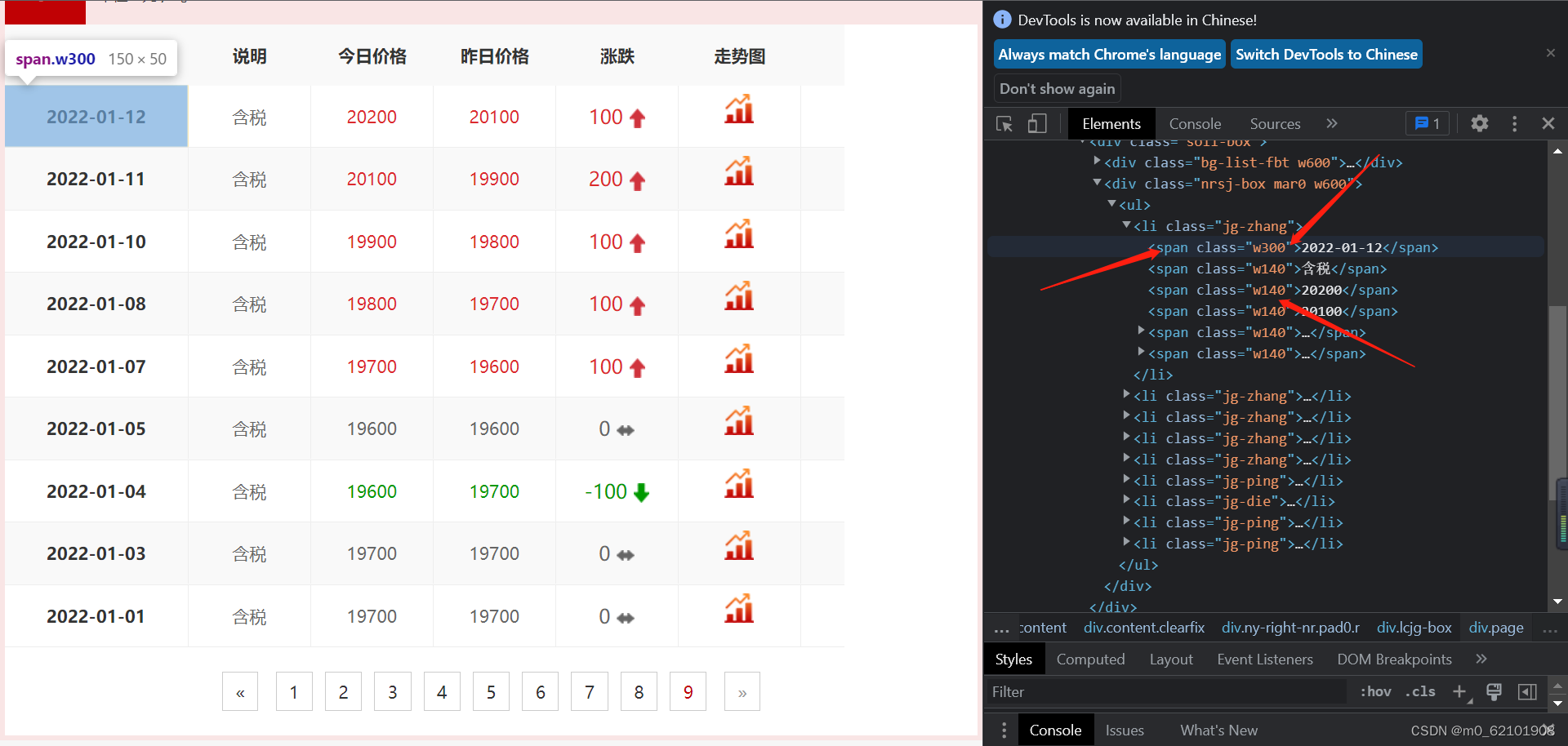
5.存储数据
第4步得到的数据为数据框格式,我预计存到数据库里,这里不再详述。















 4079
4079











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









