






任务描述
本关任务:完成 Storm 容错机制的验证代码。
相关知识
为了完成本关任务,你需要掌握: 1.Storm 集群节点架构图; 2.集群节点宕机(服务器); 3.进程挂掉(进程); 4.消息完整性; 5.storm的主要创新。
Storm 集群节点架构图
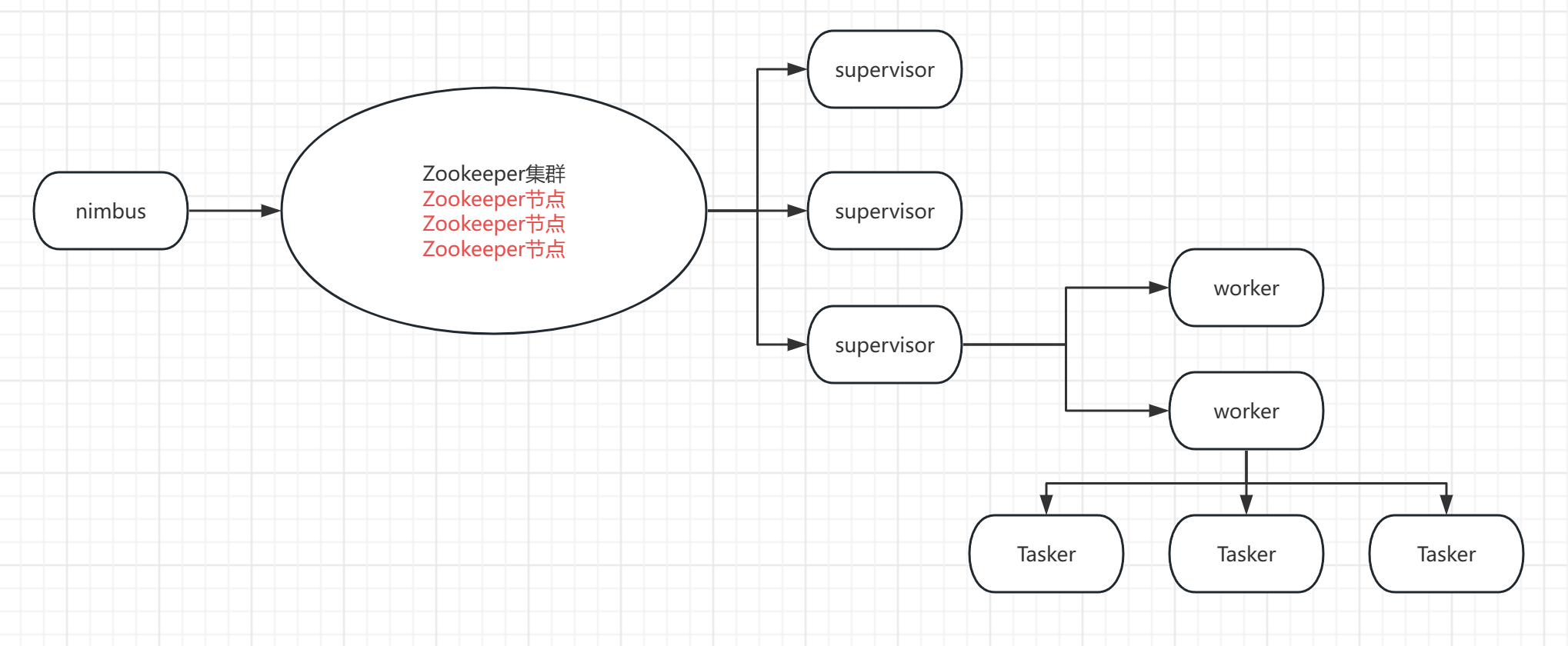
集群节点宕机(服务器)
1.在平时集群运行过程中不会使用到 Nimbus,当向集群中提交作业,先将作业提交给 Nimbus,然后 Nimbus 将作业存放在 Zookeeper 集群中。
2.如果集群中的 supervisor 发生宕机,该节点上所有的 Task 任务都会超时,Nimbus 会将这些 Task 任务重新分配到其他服务器上(supervisor)运行。
进程挂掉(进程)
worker
如果 supervisor 中的 Task 任务发生故障,supervisor 会尝试重启这个进程,如果启动过程中仍然一直失效,并且无法 Nimbus 发送心跳,Nimbus 会将该 Worker 重新分配到其他服务器上。
Supervisor
无状态(所有的状态信息都存放在 Zookeeper 中来管理)
快速失败(每当遇到任何异常信息,都会自动毁灭,这时候 Nimbus 可以迅速觉察到然后将任务分发到别的节点)
消息完整性
Storm 提供了几种不同级别的保证消息处理,包括尽力而为(best effort),至少一次(at least once),以及通过 Trident 保证只完全处理一次(exactly once)。
这里指至少完全处理一次:
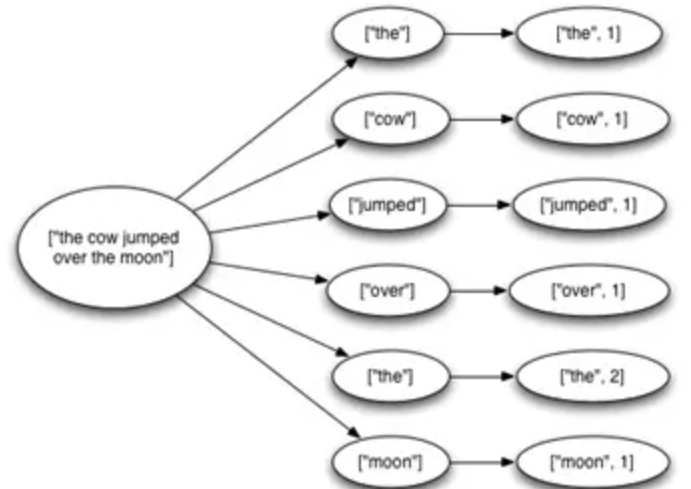
当元组树已经用完并且树中的每条消息都已处理完毕时,Storm 会认为从水龙头发射的元组是“完全处理”的。如果在指定的超时内无法完全处理其消息树,则认为该元组失败。可以使用 Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS 对指定的拓扑进行配置,默认为 30 秒。
public interface ISpout extends Serializable {void open(Map conf, TopologyContext context, SpoutOutputCollector collector);void close();void nextTuple();void ack(Object msgId);void fail(Object msgId);}
首先,storm 调用 spout 的 nextTuple 方法发射一个元组。spout 使用 SpoutOutputCollector 在声明的流中发射元组。当发射元组的时候,spout 使用 messageId 标记该元组。
//这里的msgId是由系统为我们创建的_collector.emit(new Values("field1", "field2", 3) , msgId);
其次,当向消费闪电发送元组的时候,strom 追踪该消息树。如果 storm 发现一个元组被完全处理了,storm 就会调用 spout 的 ack 方法并将该元组的 messageId 传送给它。如果元组处理超时,storm 就调用 spout 的 fail 方法。只会在发射该元组的 spout 中调用它的 ack 或者 fail 方法。
好处是:
首先,当创建了新的元组树边的时候,要通知 storm。其次,当完成了一个元组的处理之后要告诉 storm。通过这种方式,storm 就可以知道元组被完全处理了,然后调用 ack 方法,或者调用 fail 方法,如果处理失败。在元组树中创建一条边,称为锚点。当发送一个新元组的时候就会创建一条边。
public class SplitSentence extends BaseRichBolt {OutputCollector _collector;public void prepare(Map conf, TopologyContext context, OutputCollector collector) {_collector = collector;}public void execute(Tuple tuple) {String sentence = tuple.getString(0);for(String word: sentence.split(" ")) {_collector.emit(tuple, new Values(word));}//如果执行成功,会发送一个确认消息_collector.ack(tuple);}public void declareOutputFields(OutputFieldsDeclarer declarer) {declarer.declare(new Fields("word"));}}
每个元组通过在 emit 中指定输入的元组进行锚点标记。由于被标记锚点,如果在下游处理中处理失败了,元组树顶点的元组会重新发送。
//没有对元组进行锚点标记,当元组在下游处理失败了,根元组不会重新发送_collector.emit(new Values(word));
输出的元组也可以标记多个锚点。如果流中有聚合或者 join,就比较有用。标记了多个锚点的元组如果处理失败,就会触发多个元组树根元组重发。通过 list 集合为元组标记多个锚点:
List<Tuple> anchors = new ArrayList<Tuple>();anchors.add(tuple1);anchors.add(tuple2);_collector.emit(anchors, new Values(1, 2, 3));
手动调用 fail 方法比通过元组的处理超时从而由 storm 调用 fail 方法要更快地重发根元组。由于 storm 使用内存来存储元组树,如果不及时的 ack 或者 fail 有可能导致内存溢出。
storm 的拓扑中提供了一组 acker 用于追踪 spout 发射的每个元组及其衍生的元组,一旦发现 DAG 处理完了,就同创建该元组的 spout 进行确认。
Config.TOPOLOGY_ACKERS 用于设置 acker 的数量。默认情况下一个 worker 一个 acker 任务。
当拓扑创建了元组,就会为其分配一个随机的 64bit 的 id,acker 使用该 ID 追踪 spout 发送的每个元组。元组树上的元组都知道这个 ID。当在闪电中创建了新的元组,该 ids 会拷贝给新的元组。当元组确认后,元素发送消息给 acker 任务,以改变元组树。
如果拓扑中包含多个 acker,当一个元组确认后,如何知道向哪个 acker 发送确认消息?
storm 使用 hash 取模的方式将一个 spout 的元组 id 跟一个 acker 任务绑定。
acker 任务如何知道该向哪个 spout 任务发送确认消息?
spout 发射元组的时候会给合适的 acker 发送一个消息表示对哪个 spout 的元组负责。acker 发现元组树完成了,就知道向哪个 spout 任务发送完成的消息。
Storm的主要创新
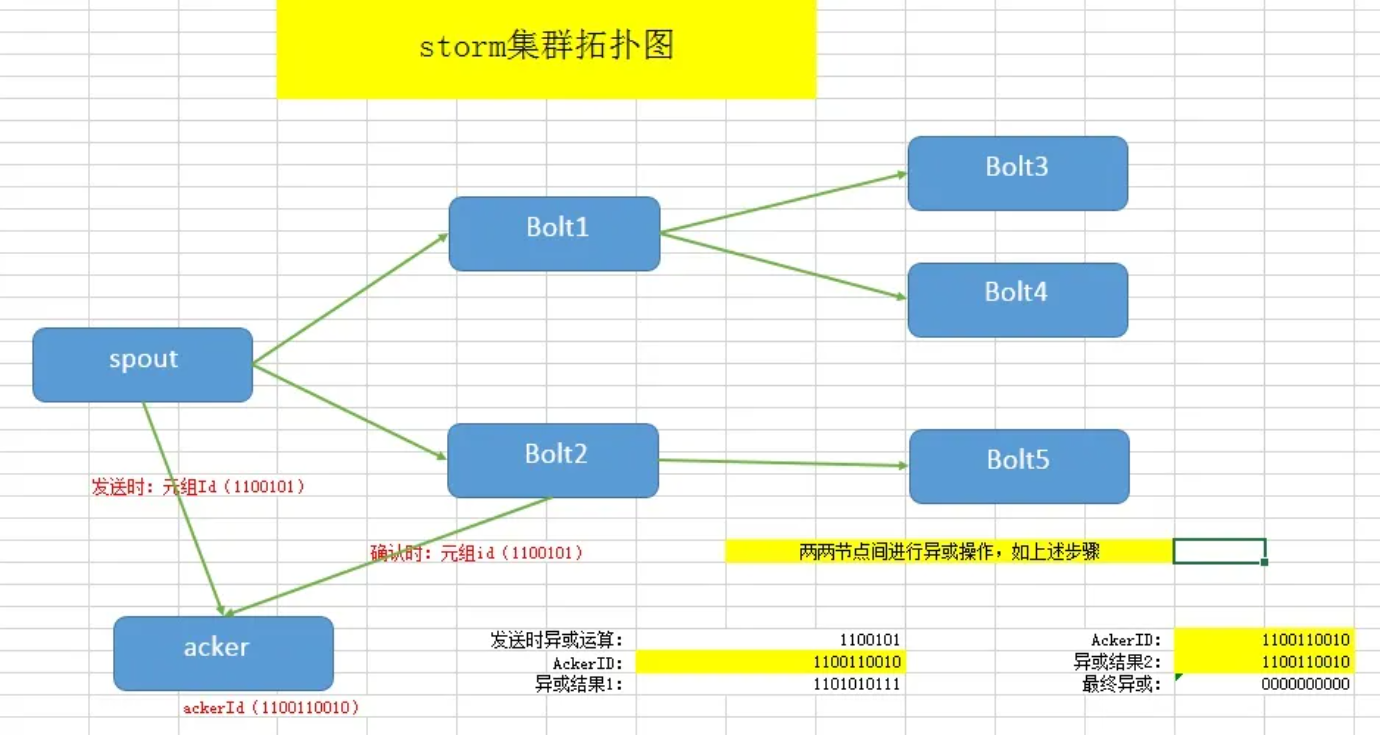
acker 不会去显示的追踪元组。如果有数十万的节点,追踪会有耗尽 acker 内存的风险。acker 使用一个定长为 20 字节的空间去做这个动作。
acker 将 spout 发射的元组 id 和一个 64bit 的数字(ack val)相关联。ack val 代表了该元组数的状态,不管 spout 发射的元组及其衍生的元组有多少,它只对所有创建的元组以及确认的元组 id 求异或 xor 操作。如果最终这个值 ack val 变成了 0,表示元组数已经被完全处理了。
示意图如下:
编程要求
根据提示,在右侧编辑器补充代码,通过编写补充 FaultToleranceExample 来补充 NumBolt 中的 execute 方法。实现抛出异常,抛出异常时提示:Error processing number 5
提示: 如果想要查看更详细的通信机制的产生,可以开启代码的 debug 然后测评后再查看目录 /root/st.log 文件日志。
测试说明
平台会对你编写的代码进行测试:
预期输出:
9365 [Thread-18-bolt-executor[2 2]] INFO o.a.s.d.executor - Processing received message FOR 2 TUPLE: source: spout:3, stream: default, id: {}, [5]Received number: 59366 [Thread-18-bolt-executor[2 2]] ERROR o.a.s.util - Async loop died!java.lang.RuntimeException: java.lang.RuntimeException: Error processing number 5at org.apache.storm.utils.DisruptorQueue.consumeBatchToCursor(DisruptorQueue.java:522) ~[storm-core-1.2.4.jar:1.2.4]at org.apache.storm.utils.DisruptorQueue.consumeBatchWhenAvailable(DisruptorQueue.java:487) ~[storm-core-1.2.4.jar:1.2.4]at org.apache.storm.disruptor$consume_batch_when_available.invoke(disruptor.clj:74) ~[storm-core-1.2.4.jar:1.2.4]at org.apache.storm.daemon.executor$fn__9766$fn__9779$fn__9832.invoke(executor.clj:861) ~[storm-core-1.2.4.jar:1.2.4]at org.apache.storm.util$async_loop$fn__553.invoke(util.clj:484) [storm-core-1.2.4.jar:1.2.4]at clojure.lang.AFn.run(AFn.java:22) [clojure-1.7.0.jar:?]at java.lang.Thread.run(Thread.java:748) [?:1.8.0_171]Caused by: java.lang.RuntimeException: Error processing number 5at com.step1.FaultToleranceExample$NumberBolt.execute(FaultToleranceExample.java:85) ~[storm_study-1.0-SNAPSHOT.jar:?]at org.apache.storm.daemon.executor$fn__9766$tuple_action_fn__9768.invoke(executor.clj:739) ~[storm-core-1.2.4.jar:1.2.4]at org.apache.storm.daemon.executor$mk_task_receiver$fn__9687.invoke(executor.clj:468) ~[storm-core-1.2.4.jar:1.2.4]at org.apache.storm.disruptor$clojure_handler$reify__9198.onEvent(disruptor.clj:41) ~[storm-core-1.2.4.jar:1.2.4]at org.apache.storm.utils.DisruptorQueue.consumeBatchToCursor(DisruptorQueue.java:509) ~[storm-core-1.2.4.jar:1.2.4]... 6 more...........
代码如下:
package com.step1;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.IRichBolt;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.util.Map;
public class FaultToleranceExample {
public static void main(String[] args) {
// 创建Topology构建器
TopologyBuilder builder = new TopologyBuilder();
// 设置Spout,并指定名称为"spout"
builder.setSpout("spout", new NumberSpout());
// 设置Bolt,并指定名称为"bolt"
builder.setBolt("bolt", new NumberBolt())
.shuffleGrouping("spout");
// 创建配置对象
Config config = new Config();
config.setDebug(true);
// 创建本地集群
LocalCluster cluster = new LocalCluster();
// 提交拓扑和配置到集群中运行
cluster.submitTopology("fault-tolerance", config, builder.createTopology());
}
public static class NumberSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private int count = 0;
@Override
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector collector) {
this.collector = collector;
}
@Override
public void nextTuple() {
if (count < 10) {
collector.emit(new Values(count));
count++;
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("num"));
}
}
public static class NumberBolt extends BaseRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
int number = input.getIntegerByField("num");
System.out.println("Received number: " + number);
// 模拟一个错误,当数字为5时抛出异常
//##########BEGIN##########
try {
if (number == 5) {
throw new Exception("Error processing number 5");
}
// 其他代码...
} catch (Exception e) {
System.out.println("捕获到异常: " + e.getMessage());
}
//##########END##########
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 不发射任何输出字段
}
}
}



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









