






在数据科学的众多工具中,主成分分析(PCA)是一种非常重要的统计技术,用于数据降维和模式识别。它通过提取数据中的关键特征来简化数据结构,从而帮助我们更好地理解数据集的主要变化因素。本文将介绍如何在 Java 编程环境中实现 PCA,利用 Apache Commons Math 库来处理实际数据。
什么是主成分分析(PCA)?
主成分分析是一种统计方法,通过正交变换将可能相关的变量转换为一组线性不相关的变量,称为主成分。这种技术常用于减少数据集的维数,同时保持数据集中最重要的变异性。在多变量数据中,PCA 可以揭示隐藏在复杂数据集背后的简单结构。
环境准备
在开始编写 PCA 程序之前,需要确保 Java 开发环境已经设置好,这包括:
-
开发工具:如 IntelliJ IDEA 2017。
-
Java 开发套件:JDK 8。
-
数学库:Apache Commons Math 4.0,可以从其官网下载。
如何在 Java 中进行 PCA?
以下是在 Java 中实现 PCA 的步骤:
-
数据准备:首先,创建一个二维数组来存储数据。在这个数组中,每一行代表一个观察样本,每一列代表一个特征。
-
计算协方差矩阵:PCA 的第一步是计算数据的协方差矩阵,它反映了变量之间的协方差,即变量如何一起变化。
-
特征值分解:通过对协方差矩阵进行特征值分解,我们可以找到主成分。这些主成分定义了数据中变化最大的方向。
-
分析结果:分解产生的特征值和对应的特征向量表示数据的主成分。特征值越大,对应的特征向量在数据集中的重要性越高。
示例代码
import org.apache.commons.math4.legacy.linear.Array2DRowRealMatrix;
import org.apache.commons.math4.legacy.linear.EigenDecomposition;
import org.apache.commons.math4.legacy.linear.RealMatrix;
import org.apache.commons.math4.legacy.stat.correlation.Covariance;
public class PCAExample {
public static void main(String[] args) {
// 创建数据矩阵,每行是一个观测,每列是一个变量
double[][] data = {
{2.5, 2.4},
{0.5, 0.7},
{2.2, 2.9},
{1.9, 2.2},
{3.1, 3.0},
{2.3, 2.7},
{2.0, 1.6},
{1.0, 1.1},
{1.5, 1.6},
{1.1, 0.9}
};
RealMatrix matrix = new Array2DRowRealMatrix(data);
// 计算协方差矩阵
Covariance covariance = new Covariance(matrix);
RealMatrix covarianceMatrix = covariance.getCovarianceMatrix();
// 进行特征值分解
EigenDecomposition decomposition = new EigenDecomposition(covarianceMatrix);
// 输出特征值和特征向量
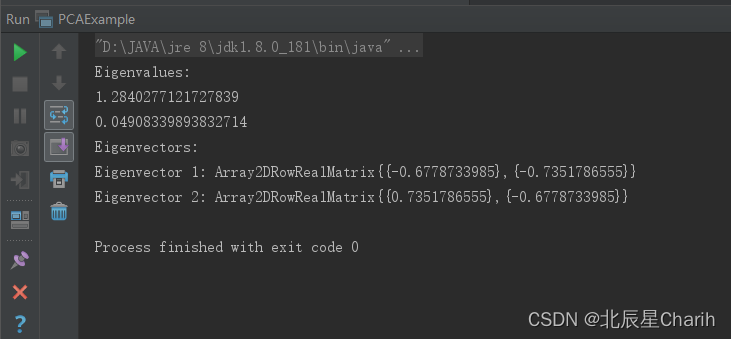
System.out.println("Eigenvalues:");
for (double eigenvalue : decomposition.getRealEigenvalues()) {
System.out.println(eigenvalue);
}
System.out.println("Eigenvectors:");
for (int i = 0; i < decomposition.getV().getColumnDimension(); i++) {
System.out.println("Eigenvector " + (i + 1) + ": " + decomposition.getV().getColumnMatrix(i));
}
}
}
结论
通过以上步骤和示例代码,我们展示了如何在 Java 中使用 Apache Commons Math 库进行 PCA。这为研究者和开发者提供了一个强大的工具,以数学和统计方法来解析和理解大量数据。使用 PCA,可以有效地识别出哪些特征最能代表原始数据的结构和变化趋势。这在减少数据维度、提高分析效率、以及在某些情况下提高算法性能方面特别有用。例如,在机器学习和数据可视化领域,通过降维可以更清晰地展示数据的本质特性,同时去除冗余和噪声。
















 488
488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











