






引言
在机器学习领域,sklearn(Scikit-learn)是一个广受欢迎的开源库,它为各种常见的机器学习算法提供了高效的实现。对于初学者来说,sklearn 提供了一个简单且易于上手的工具,可以用来实现分类、回归、聚类等任务。本文将引导你了解 sklearn 的基础知识,帮助你快速开始你的机器学习之旅。
1. 什么是 Scikit-learn?
Scikit-learn 是基于 Python 语言的一个开源机器学习库。它建立在 NumPy、SciPy 和 matplotlib 这些库的基础上,提供了大量的常用机器学习算法的实现。由于其简单、易学的特性,sklearn 成为了机器学习入门者和某些高级项目的首选工具。
2. 安装 Scikit-learn
开始使用 sklearn 前,你需要确保你的 Python 环境已安装以下库:NumPy 和 SciPy。接着,你可以通过 pip 安装 Scikit-learn:
pip install numpy scipy matplotlib scikit-learn
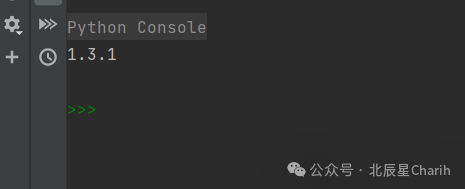
确保所有依赖都已正确安装后,你可以导入 sklearn 并检查其版本来确认安装成功:
import sklearn
print(sklearn.__version__)
3. sklearn 的核心组件
3.1 数据预处理
数据预处理是机器学习中的一个关键步骤。Sklearn 提供了许多工具,帮助你准备数据,例如标准化、归一化、编码分类特征等。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit_transform(X_train) # X_train 是你的训练数据
3.2 选择模型
Sklearn 支持多种机器学习模型,包括但不限于线性回归、支持向量机(SVM)、决策树和随机森林等。选择哪一个模型通常取决于数据类型和要解决的问题。
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
3.3 训练模型
一旦选择了模型,你可以使用训练数据来训练它。Sklearn 使这个过程变得非常简单。
model.fit(X_train, y_train) # X_train 是特征,y_train 是目标变量
4. 实战示例
让我们来看一个简单的例子,使用 sklearn 的决策树算法来分类鸢尾花:
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载数据
iris = load_iris()
X = iris.data
y = iris.target
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# 创建模型
clf = DecisionTreeClassifier()
# 训练模型
clf.fit(X_train, y_train)
# 预测测试集
predictions = clf.predict(X_test)
# 评估模型
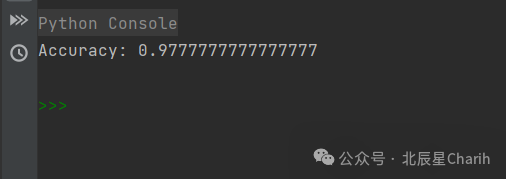
print("Accuracy:", accuracy_score(y_test, predictions))
结语
Sklearn 是一个强大的机器学习库,为机器学习爱好者和专业人士提供了丰富的算法和工具。通过本教程,你应该能够开始使用 sklearn 来实现简单的机器学习模型。随着你对机器学习理解的加深,你将能够探索更复杂的模型和技术。


















 1155
1155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











