







注:碍于编者水平有限,恕很多地方写的不够准确或全面。若有任何纰漏,还请各位读者多多包涵。谢谢!
提要
可执行文件/ELF格式
- Windows的.exe和Linux下的ELF可执行文件就是我们所谓的可执行文件。
- 可执行文件均按照**可执行文件格式(Executable)**存储。同时,动态链接库(Windows中的.dll和Linux中的.so)以及静态链接库(Windows的.lib以及Linux中的.a)文件一般也都是按照可执行文件状态存储。
- 可执行文件在Windows中按照PE-COFF格式进行存储,在Linux下按照ELF格式进行存储,这两种格式都是COFF(Common file format)的变种,是当前PC平台最流行的可执行文件格式。
- ELF可执行文件装载的主要步骤:
- 检查 ELF 可执行文件格式的有效性,比如魔数、程序头表中段的数量。
- 寻找动态链接的
.interp段,设置动态链接器路径。 - 根据 ELF 可执行文件的程序头表的描述,对 ELF 文件进行映射,比如代码、数据、只读数据。
- 初始化 ELF 进程环境。
- 将系统调用的返回地址修改成 ELF 可执行文件的入口点,这个入口点取决于程序的链接方式。
可执行文件/ELF格式
Windows的 .exe和Linux下的ELF可执行文件就是我们所谓的可执行文件。
可执行文件都是按照可执行文件格式(ELF格式) 存储的,不光如此,动态链接库(Windows中的.dll和Linux中的.so)以及静态链接库(Windows的.lib以及Linux中的.a)文件都是按照可执行文件状态存储的,他们在Windows中按照PE-COFF格式进行存储,在Linux下按照ELF格式进行存储。接下来我们对两种文件格式进行简单的介绍。
目标文件与可执行文件的格式和操作系统和编译器密切相关,不同的系统平台下会有不同的格式,但是这些格式又大同小异,可以说,目标文件与可执行文件格式的历史几乎是操作系统的发展史。
COFF是由Unix System V Release 3首次提出并使用的格式规范,后来Microsoft在其基础上,制定了PE格式标准,并将其应用于自家的Windows NT系统。后台,System V Release 4 在 COFF的基础上引入了ELF格式,目前流行的Linux系统也是以ELF作为基本的可执行文件格式。这也是为什么目前PE和ELF如此相似的原因,因为它们都是源于同一种可执行文件格式COFF。
在COFF之前,Unix最早的可执行文件格式是a.out格式,中文意为汇编器输出。因其设计简单,以至于后来共享库出现的时候,a.out格式变得捉襟见肘,难以满足共享库实现的要求,于是从Unix System V Release 3开始被COFF取代。由于COFF格式的设计非常通用,以至于COFF的继承者PE和ELF目前还在被广泛地使用。COFF的主要贡献是在目标文件中引入了“段”的机制,不同的目标文件可以拥有不同数量及不同类型的段。另外,还定义了调试数据的格式。
Linux的ELF格式
Linux的ELF文件标准中将系统中采用ELF格式的文件归为以下四类:
| ELF文件类型 | 说明 | 实例 |
|---|---|---|
| 可重定向文件 Relocatable File | 包括代码与数据,可以用来链接为可执行文件或共享目标文件,静态链接库也属于这一类。 | Linux的.o Windows的.obj |
| 可执行文件 Executable File | 包括可以直接执行的程序 | /bin/bash文件 Windows的.exe |
| 共享目标文件 Shared Object File | 包括代码与数据,可以和其他的可重定位文件以及共享目标文件链接,产生新的目标文件。也可以使用动态链接器将其与可执行文件结合作为进程映像的一部分运行。 | Linux的.so Windows的DLL |
| 核心转储文件 Core Dump File | 进程意外中止时,系统可以将该进程的地址空间的内容以及终止时一些其他信息转储到核心转储文件。 | Linux下的core dump |
在Linux中我们可以使用file命令来查看相应文件的格式: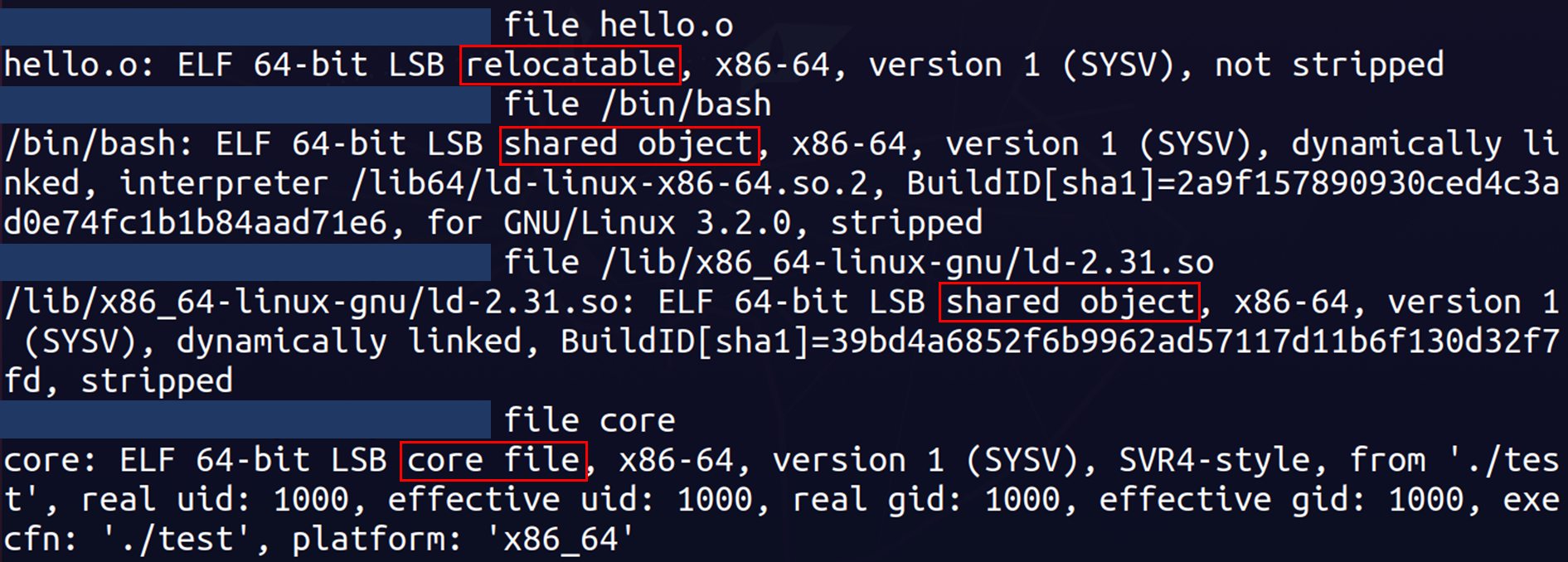
ELF文件结构描述
ELF文件格式提供了其内容的两种并行视图,一种被称为链接视图 ,静态链接器(即编译后参与生成最终ELF过程的链接器,如ld )会以链接视图解析ELF;另一种被称为执行视图 ,动态链接器(如x86架构 linux下的 /lib/ld-linux.so.2)会以执行视图解析ELF并动态链接。这两种视图的一大主要区别在于结构中的某些部分是可选的 ,以及节(Section) 和段(Segment) 的一些区别。(其实段大都是来源于链接视图中的节,常常认为节和段是一致的。后续不专门区分段和节。)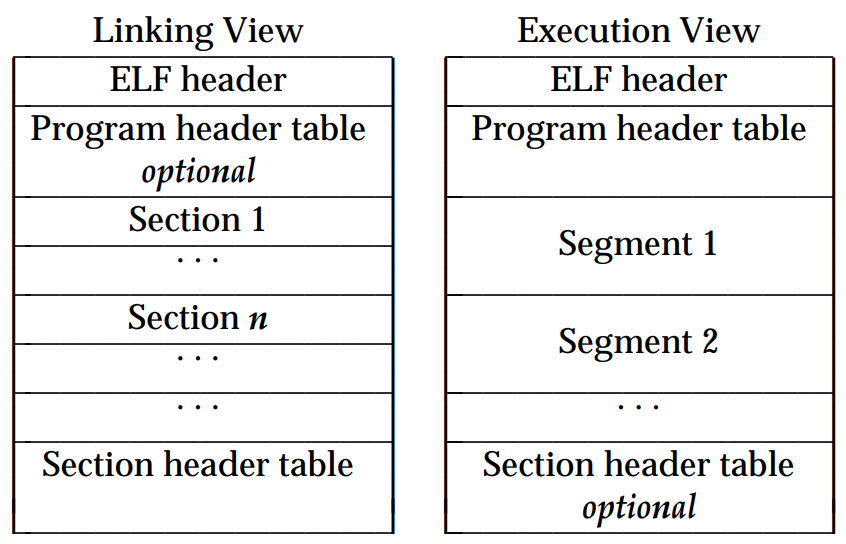
注:实际上除了 ELF 头部表以外,其它部分都没有严格的顺序。
ELF文件头(Header)
利用readelf我们可以查看某个ELF文件结构文件的文件头: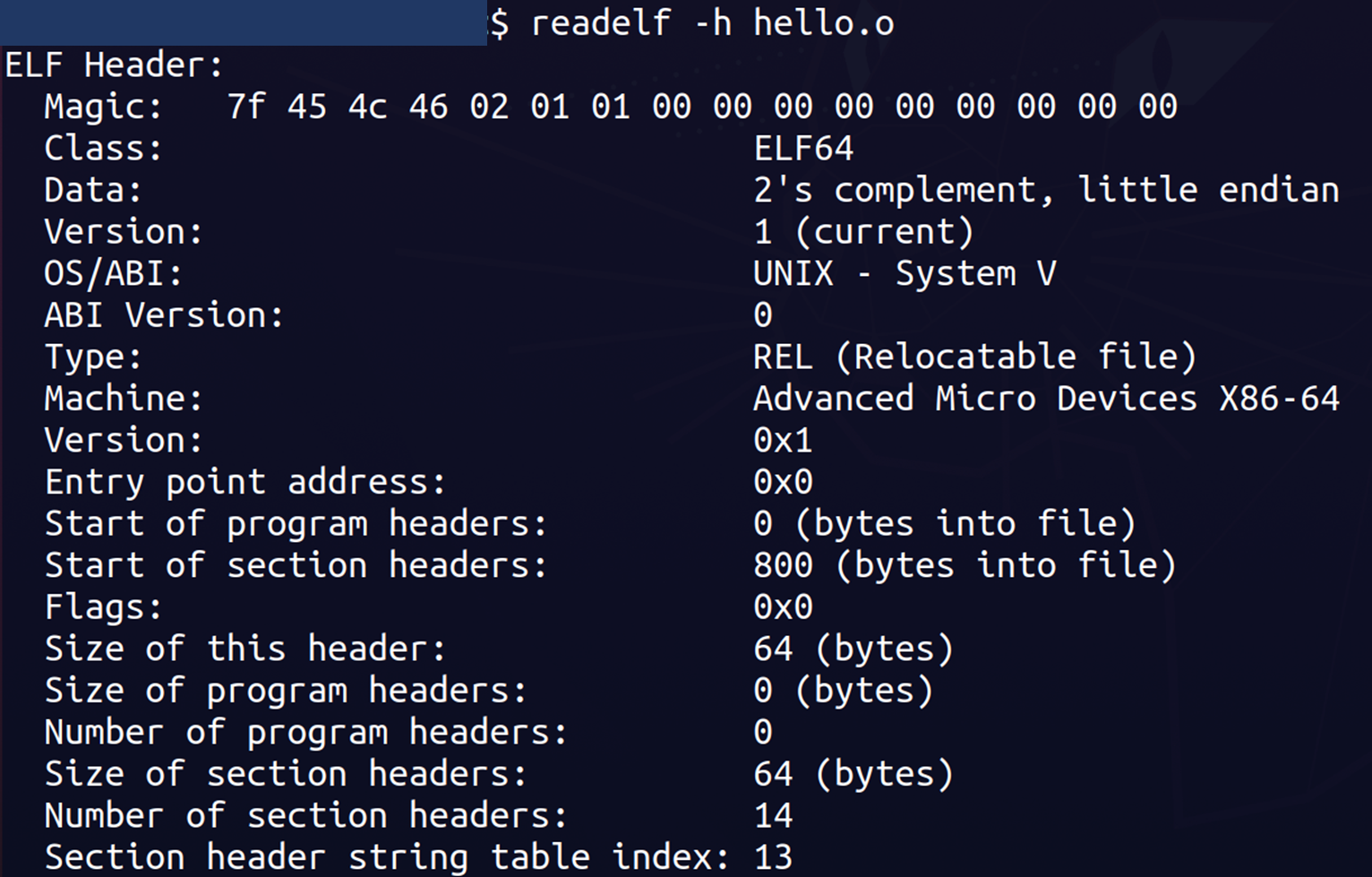
实际上32位ELF文件头结构有如下定义:
#define EI_NIDENT 16
typedef struct {
unsigned char e_ident[EI_NIDENT];
ELF32_Half e_type;
ELF32_Half e_machine;
ELF32_Word e_version;
ELF32_Addr e_entry;
ELF32_Off e_phoff;
ELF32_Off e_shoff;
ELF32_Word e_flags;
ELF32_Half e_ehsize;
ELF32_Half e_phentsize;
ELF32_Half e_phnum;
ELF32_Half e_shentsize;
ELF32_Half e_shnum;
ELF32_Half e_shstrndx;
} Elf32_Ehdr;
我们把功能对应过来就是:
| 成员 | readelf 输出结果与含义 |
|---|---|
e_ident | Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 Class: ELF64 Data: 2’s complement, little endian Version: 1 (current) OS/ABI: UNIX - System V ABI Version: 0 |
e_type | Type: REL (Relocatable file) ELF文件类型。 |
e_machine | Machine: Advanced Micro Devices X86-64 ELF文件的CPU平台属性,相关常量以 EM_开头。 |
e_version | Version: 0x1 ELF版本号。 |
e_entry | Entry point address: 0x0 入口地址,规定ELF程序的入口虚拟地址,操作系统在加载完程序后从这个地址开始执行进程的指令。可重定位文件一般没有入口地址,则这个值为0。 |
e_phoff | Start of program headers: 0 (bytes into file) 这一项给出程序头部表在文件中的字节偏移(Program Header table OFFset),如果文件中没有程序头部表,则为 0。 |
e_shoff | Start of section headers: 800 (bytes into file) 段表在文件中的偏移(Section Header table OFFset)。(这里为段表从第800个字节开始),如果文件中没有节头表,则为 0。 |
e_word | Flags: 0x0 标志位,用来标志一些ELF文件平台相关的属性。 |
e_ehsize | Size of this header: 64 (bytes) ELF文件头本身的大小。 |
e_phentsize | Size of program headers: 0 (bytes) 给出程序头部表中每个表项的字节长度(Program Header ENTry SIZE)。每个表项的大小相同。 |
e_phnum | Number of program headers: 0 给出程序头部表的项数(Program Header entry NUMber)。因此, e_phnum与e_phentsize的乘积即为程序头部表的字节长度。如果文件中没有程序头部表,则该项值为 0。 |
e_shentsize | Size of section headers: 64 (bytes) 段表描述符的大小(Section Header ENTry SIZE),一般等于 sizeof(Elf64_Ehdr)。 |
e_shnum | Number of section headers: 14 段表描述符数量(Section Header NUMber),等于ELF文件中拥有段的数量。 |
e_shstrndx |
| Section header string table index: 13
段表字符串表所在的段在段表中的下标。(Section Header table InDeX related with section name STRing table) |
e_ident指的是ELF identification,相关详细内容可以在ELF标准文档(或一些其它文档)中找到,下面主要介绍其中Magic这个参数。Magic的16个字节刚好对应Elf32_Ehdr的e_ident这个成员。这16个字节被 ELF 标准规定用来标识 ELF 文件的平台属性,比如这个ELF字长(32 位/64 位)、字节序、ELF 文件版本。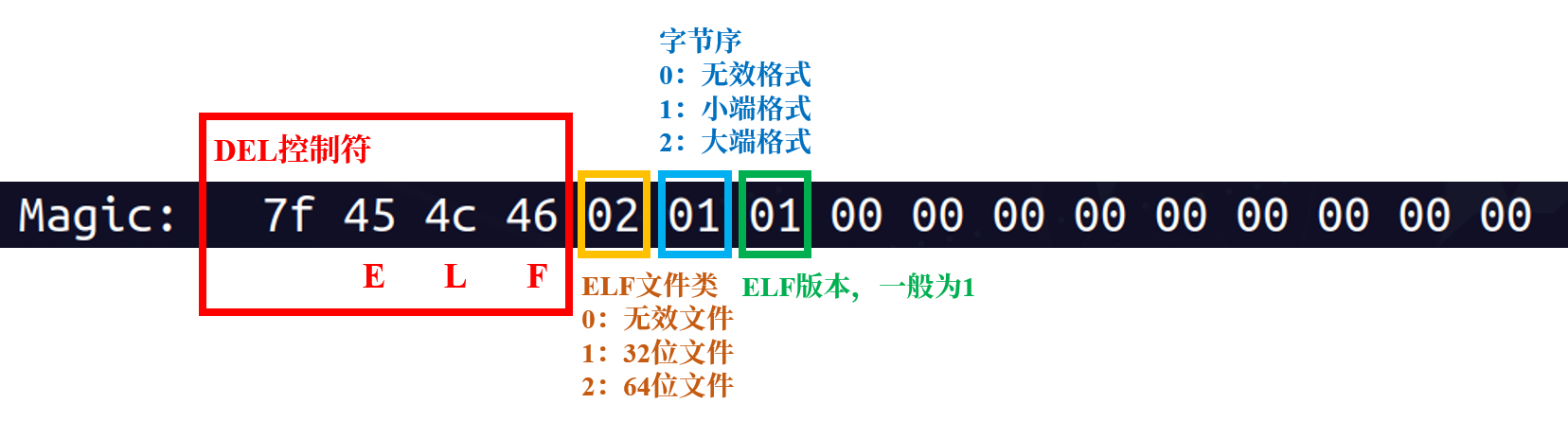
最开始的 4 个字节是所有 ELF 文件部必须相同的标识码,分别为0x7F、0x45、0x4c、0x46,第一个字节对应 ASCII 字符里面的 DEL 控制符,后面3个字节刚好是ELF这3个字母的ASCII码。这4个字节又被称为ELF文件的魔数。这种魔数用来确认文件的类型,操作系统在加载可执行文件的时候会确认魔数是否正确,如果不正确会拒绝加载。
魔数的一些有趣的小知识
- 几乎所有的可执行文件格式的最开始的几个字节都是魔数。比如 a.out 格式最开始两个字节为 0x01、0x07;PE/COFF 文件最开始两个个字节为 0x4d、0x5a,即 ASCII 字符 MZ。
- UNIX 早年是在 PDP 小型机上诞生的,当时的系统在加载一个可执行文件后直接从文件的第一个字节开始执行,人们一般在文件的最开始放置一条跳转(jump)指令,这条指令负责跳过接下来的 7 个机器字的文件头到可执行文件的真正入口。而 0x01 0x07 这两个字节刚好是当时 PDP-11 的机器的跳转 7 个机器字的指令。为了跟以前的系统保持兼容性,这条跳转指令被当作魔数一直被保留到了几十年后的今天。
- ELF 的可执行文件格式的头 4 个字节为 0x7F、e、l、f;而 Java 的可执行文件格式的头 4 个字节为 c、a、f、e;如果被执行的是 Shell 脚本或 perl、python 等这种解释型语言的脚本,那么它的第一行往往是 “#!/bin/sh” 或 “#!/usr/bin/perl” 或 “#!/usr/bin/python”,这时前两个字节 “#” 和 “!” 就构成了魔数,系统一旦判断到这两个字节,就对后面的字符串进行解析,以确定具体的解释程序的路径。
段与段表
从前面的描述我们可以看到,ELF文件中有各种各样的段,在一般情况下,段表示的就是一个一定长度的区域。程序源代码编译后的机器指令常常被放置在代码段中,我们常常看到的.text段或者.code段指的就是代码段;而已经初始化的全局变量和局部静态变量常常放置在数据段中,常常记为.data段,而未初始化的全局变量和局部静态变量一般放在一个叫做.bss的段中(BSS,即Block Started by Symbol,最初为UA-SAP汇编器中的一个伪指令,用于为符号预留一块内存空间)。总体来说,程序源代码被编译后主要分成两种段:程序指令和程序数据,代码段就属于程序指令,而数据段和.bss段就属于程序数据。
我们可以使用objdump来查看各种ELF文件格式文件的结构和内容,比如对于下面这个目标文件格式的文件,我们可以使用objdump -h hello.o来看到其一些重要的段的信息: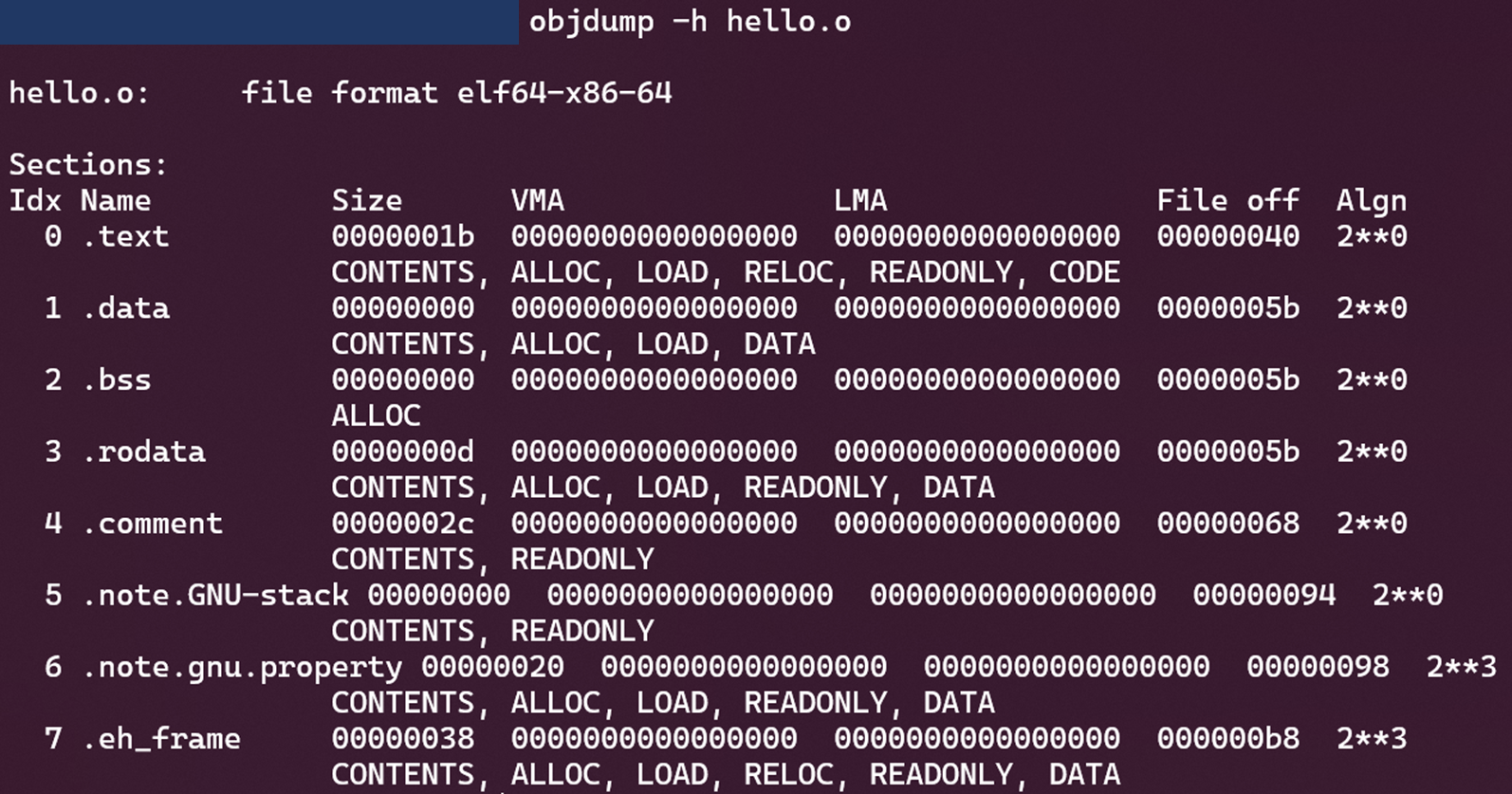
注:其中.rodata表示只读数据段。使用readelf -S hello.o可以看到更多的段。
还有一个专门的命令size来查看ELF文件的代码段、数据段和BSS段的长度(dec字段表示这三个段长度的和的十进制,而hex表示其十六进制):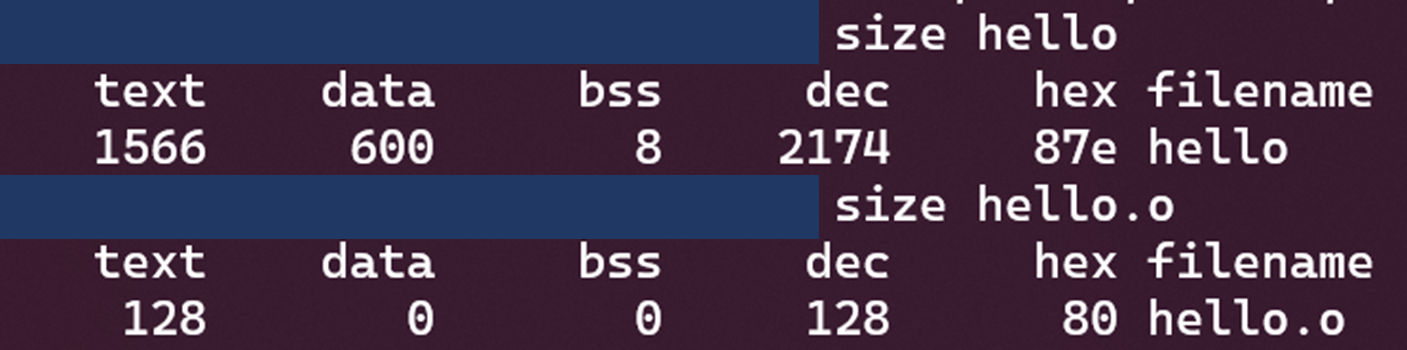
我们还能使用objdump将其中关于代码段的内容提取出来: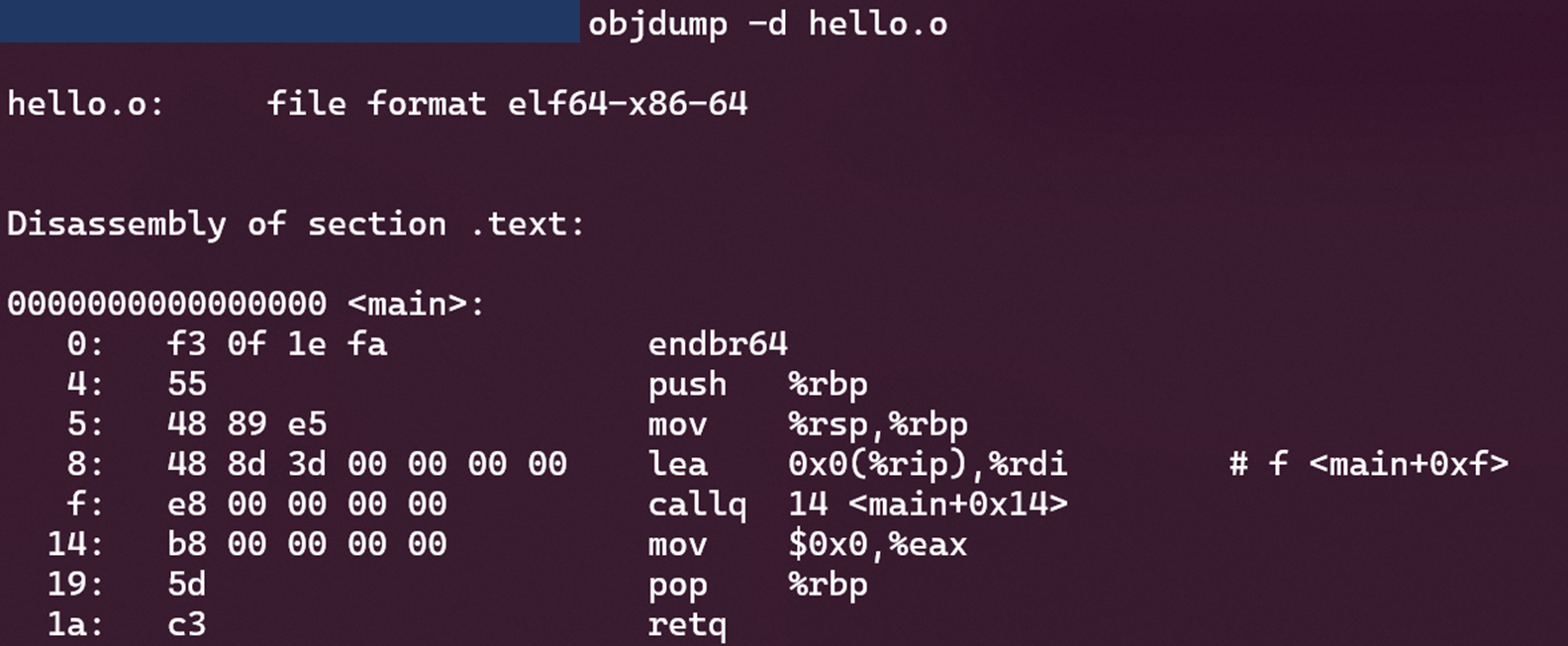
ELF文件中还有一个很重要的结构叫做段表(Section Header Table),是存储各种段的基本属性的结构,包括每个段的段名、段的长度、在文件中的偏移、读写权限以及其他属性等等。而其中段表在ELF中的位置由ELF文件头中的e_shoff来决定。
ELF中还有一些重要的结构比如重定位表和符号表,读者可以自行了解,在此便不多赘述。
ELF文件标准的历史
20 世纪 90 年代,一些厂商联合成立了一个委员会,起草并发布了一个 ELF 文件格式标准供公开使用,并且和希望所有人能够遵循这项标准并且从中获益。1993 年,委员会发布了 ELF 文件标准。当时参与该委员会的有来自于编译器的厂商,如 Watcorn 和 Borland;来自 CPU 的厂商如 IBM 和 Intel;来自操作系统的厂商如 IBM 和 Microsoft。1995 年,委员会发布了 ELF 1.2 标准,自此委员会完成了自己的使命,不久就解散了。所以 ELF 文件格式标准的最新版本为 1.2。
Linux内核装载ELF的过程
下面让我们简单了解一下Linux内核对ELF文件的装载过程(程序执行时所需要的指令与数据装入内存的过程)。
考虑我们在 Linux 系统的 bash 下输入一个命令执行某个** ELF 程序的情况。首先在用户层面,bash 进程会调用 fork() 系统调用创建一个新的进程,然后新的进程会调用 execve() 系统调用执行指定的 ELF 文件,原先的 bash 进程继续返回等待刚才启动的新进程结束,然后继续等待用户输入命令。(Glibc 对 execvp() 系统调用进行了包装,提供了 execl()、execlp()、execle()、execv() 和 execvp() 等 5 个不同形式的 exec 系列 API,它们只是在调用的参数形式上有所区别,但最终都会调用到 execve() 。)
在进入execve()系统调用之后,Linux 内核就开始进行真正的装载工作。execve()在内核中系统调用相应的入口是sys_execve()。sys_execve()进行一些参数的检查复制之后,调用do_execve()。do_execve()会首先查找被执行的文件,如果找到文件,则读取文件的前 128 个字节,之后调用search_binary_handle()判断文件头部的魔数确定文件的格式,然后调用相应的装载处理过程。
如果我们聚焦于ELF可执行文件**的装载,那么其处理过程定义在load_elf_binary()中。主要步骤为:
- 检查 ELF 可执行文件格式的有效性,比如魔数、程序头表中段的数量。
- 寻找动态链接的
.interp段,设置动态链接器路径。 - 根据 ELF 可执行文件的程序头表的描述,对 ELF 文件进行映射,比如代码、数据、只读数据。
- 初始化 ELF 进程环境。
- 将系统调用的返回地址修改成 ELF 可执行文件的入口点,这个入口点取决于程序的链接方式。对于静态链接的 ELF 可执行文件,程序入口为 ELF 文件的文件头中
e_entry的所指地址,对于动态链接的 ELF 可执行文件,程序入口为动态链接器。
当 load_elf_binary() 执行完毕返回至do_execve()再返回至sys_execve()时,系统调用的返回地址已经被改成了被装载的 ELF 程序的入口地址。因此当sys_execve()系统调用从内核态返回到用户态时,相关寄存器直接跳转到了 ELF 程序,新的程序开始执行,ELF 可执行文件装载完成。
Windows的PE/COFF
在 32 位 Windows 平台下,微软引入了一种称为 **PE(Protable Executable)**的可执行格式。作为 Win32 平台的标准可执行文件格式,PE 有着跟 ELF 一样良好的平台扩展性和灵活性。PE 文件格式事实上与 ELF 同根间源,都是由 COFF(Common Object File Format) 格式发展而来。
后来随着 64 位 Windows 的发布,微软对 64 位 Windows 平台上的 PE 文件结构稍微做了一些修改,这个新的文件格式叫做 PE32+。实际上 PE32+ 并没有添加任何结构,最大的变化只是把那些原来 32 位的字段变成了 64 位,比如文件头中与地址相关的字段。绝大部分情况下,PE32+ 与 PE 的格式一致,可以将其看作是一般的 PE 文件。
与 ELF 文件相同,PE/COFEF 格式也采用了基于段的格式。一个段可以包含代码、数据或其他信息。在 PE/COFE 文件中,至少包含一个代码段,这个代码段的名字往往叫做 .code,数据段叫做 .data,只是不同的编译器产生的目标文件的段名有略微的不同。
参考
[1]《程序员的自我修养——链接、装载与库》俞甲子,石凡,潘爱民
[2] https://zhuanlan.zhihu.com/p/73114831
[3] http://flint.cs.yale.edu/cs422/doc/ELF_Format.pdf

















 1062
1062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









