







剑指offer10道
1、合并两个排序的链表(简单)
描述
输入两个递增的链表,单个链表的长度为n,合并这两个链表并使新链表中的节点仍然是递增排序的。
数据范围: 0≤n≤10000≤n≤1000,−1000≤节点值≤1000−1000≤节点值≤1000
要求:空间复杂度 O(1)O(1),时间复杂度 O(n)O(n)
如输入{1,3,5},{2,4,6}时,合并后的链表为{1,2,3,4,5,6},所以对应的输出为{1,2,3,4,5,6},转换过程如下图所示:
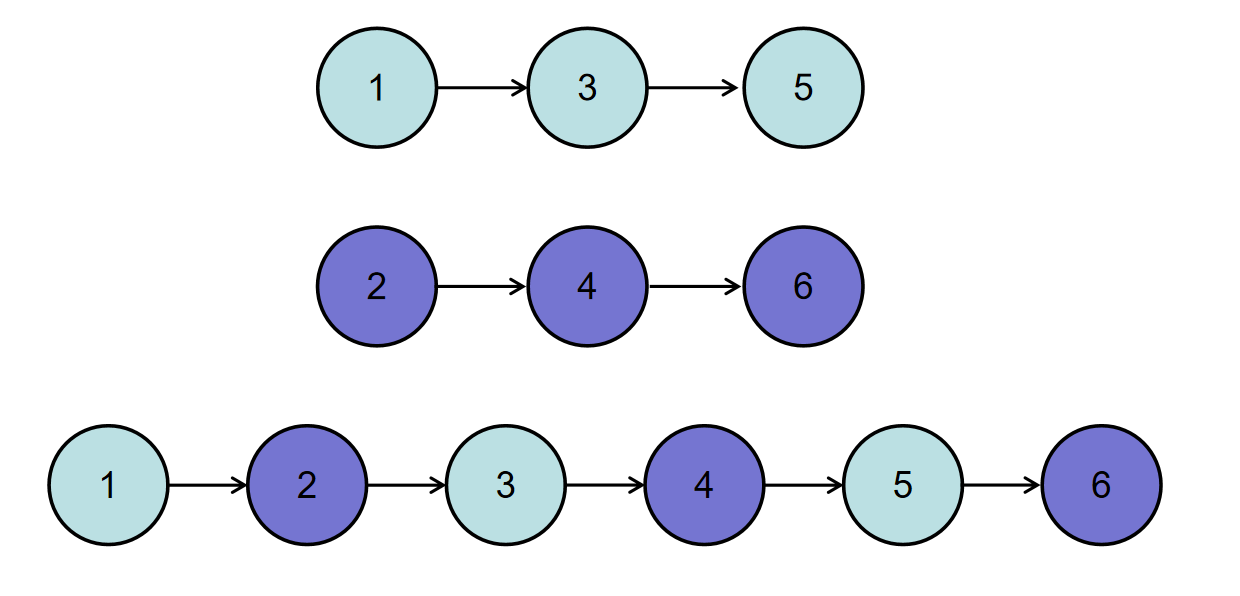
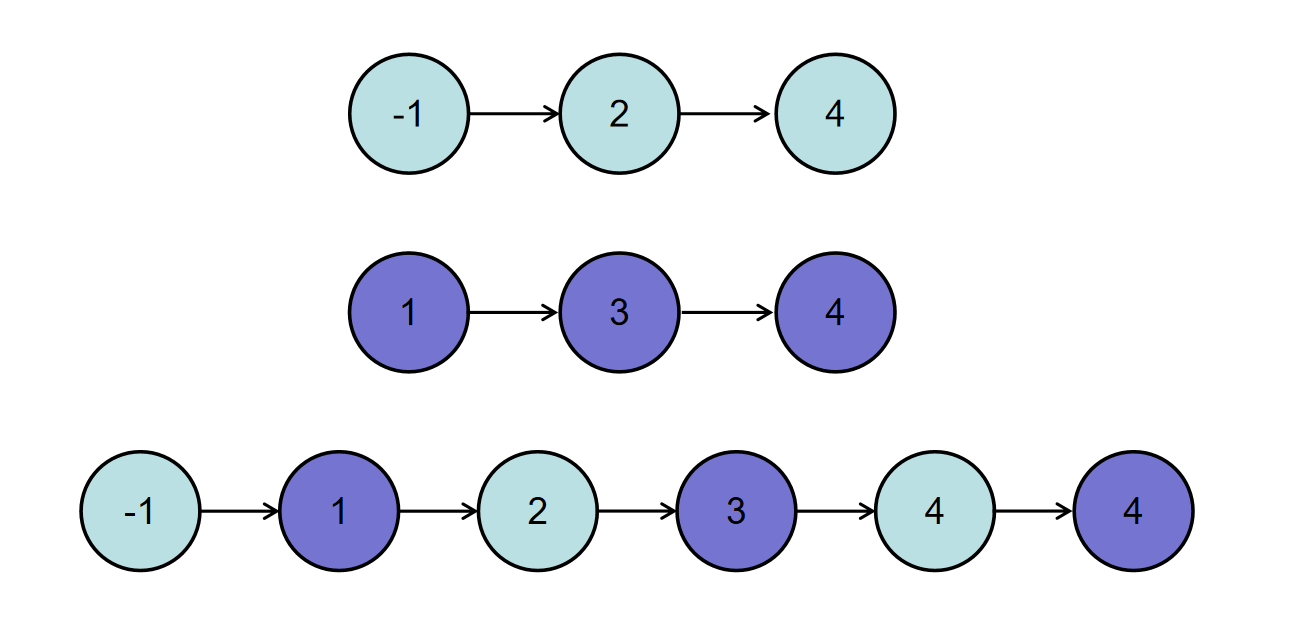
或输入{-1,2,4},{1,3,4}时,合并后的链表为{-1,1,2,3,4,4},所以对应的输出为{-1,1,2,3,4,4},转换过程如下图所示:
示例1
输入:
{1,3,5},{2,4,6}
返回值:
{1,2,3,4,5,6}示例2
输入:
{},{}
返回值:
{}示例3
输入:
{-1,2,4},{1,3,4}
返回值:
{-1,1,2,3,4,4}答案
依然递归,两个为空返回空,一个为空返回另一个,然后判断两个结点哪个大,哪个大就找他下一个
public ListNode Merge (ListNode pHead1, ListNode pHead2) {
// write code here
if(pHead1 == null && pHead2 == null) return null;
if(pHead1 == null) return pHead2;
if(pHead2 == null) return pHead1;
if(pHead1.val <= pHead2.val){
pHead1.next = Merge(pHead1.next,pHead2);
return pHead1;
}else{
pHead2.next = Merge(pHead1,pHead2.next);
return pHead2;
}
}2、树的子结构(中等)
描述
输入两棵二叉树A,B,判断B是不是A的子结构。(我们约定空树不是任意一个树的子结构)
假如给定A为{8,8,7,9,2,#,#,#,#,4,7},B为{8,9,2},2个树的结构如下,可以看出B是A的子结构

数据范围:
0 <= A的节点个数 <= 10000
0 <= B的节点个数 <= 10000
示例1
输入:
{8,8,7,9,2,#,#,#,#,4,7},{8,9,2}
返回值:
true示例2
输入:
{1,2,3,4,5},{2,4}
返回值:
true示例3
输入:
{1,2,3},{3,1}
返回值:
false答案
依然递归,深度,判断两个都空就返回false,某个为空的时候,子树为空那么就返回true,母树为空就返回false,判断当前的两个结点的值是否相等,若相等就继续判断左子树和右子树的有没有相等,如果不等就返回false,然后又是一个递归,找到最终为true的IsSame就返回true,如果没有递归母树的左子树和右子树找
public boolean HasSubtree(TreeNode root1, TreeNode root2) {
if(root2 == null||root1 == null) return false;
return IsSame(root1,root2) || HasSubtree(root1.left,root2) || HasSubtree(root1.right,root2);
}
boolean IsSame(TreeNode root1, TreeNode root2) {
if (root2 == null) return true;
if (root1 == null) return false;
if(root1.val != root2.val){
return false;
}
return IsSame(root1.left,root2.left) && IsSame(root1.right,root2.right);
}3、二叉树的镜像(简单)
描述
操作给定的二叉树,将其变换为源二叉树的镜像。
数据范围:二叉树的节点数 0≤n≤10000≤n≤1000 , 二叉树每个节点的值 0≤val≤10000≤val≤1000
要求: 空间复杂度 O(n)O(n) 。本题也有原地操作,即空间复杂度 O(1)O(1) 的解法,时间复杂度 O(n)O(n)
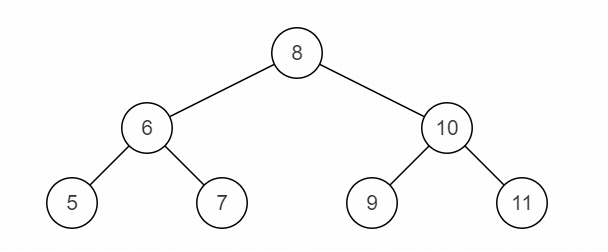
比如:
源二叉树
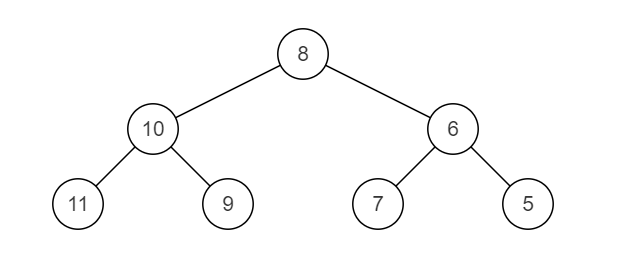
镜像二叉树
示例1
输入:
{8,6,10,5,7,9,11}
返回值:
{8,10,6,11,9,7,5}
说明:
如题面所示示例2
输入:
{}
返回值:
{}答案
依然递归,如果为空的话就直接返回,不为空的话调转左右子树,然后先递归左子树,先把左子树左右调换,再递归右子树
public TreeNode Mirror (TreeNode pRoot) {
// write code here
if(pRoot == null) return pRoot;
TreeNode tmp = pRoot.left;
pRoot.left = pRoot.right;
pRoot.right = tmp;
Mirror(pRoot.left);
Mirror(pRoot.right);
return pRoot;
}4、顺时针打印矩阵(简单)
描述
输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字,例如,如果输入如下4 X 4矩阵:
[[1,2,3,4], [5,6,7,8], [9,10,11,12], [13,14,15,16]]
则依次打印出数字
[1,2,3,4,8,12,16,15,14,13,9,5,6,7,11,10]
数据范围:
0 <= matrix.length <= 100
0 <= matrix[i].length <= 100
示例1
输入:
[[1,2,3,4],[5,6,7,8],[9,10,11,12],[13,14,15,16]]
返回值:
[1,2,3,4,8,12,16,15,14,13,9,5,6,7,11,10]示例2
输入:
[[1,2,3,1],[4,5,6,1],[4,5,6,1]]
返回值:
[1,2,3,1,1,1,6,5,4,4,5,6]答案
设置这个矩阵有顶边界(top)、底边界(bottom)、左边界(left)、右边界(right),每遍历一圈,就依次将这些边界缩小
import java.util.*;
import java.util.ArrayList;
public class Solution {
ArrayList<Integer> res = new ArrayList<>();
public ArrayList<Integer> printMatrix(int [][] matrix) {
if (matrix == null || matrix.length == 0) return res;
int m = matrix.length;
int n = matrix[0].length;
print(0,n-1,0,m-1,matrix);
return res;
}
void print(int left, int right, int top, int bottom, int [][] matrix) {
for (int i = left; i <= right; i++) res.add(matrix[top][i]);
top++;
if (left > right || top > bottom) return;
for (int i = top; i <= bottom; i++) res.add(matrix[i][right]);
right--;
if (left > right || top > bottom) return;
for (int i = right; i >= left; i--) res.add(matrix[bottom][i]);
bottom--;
if (left > right || top > bottom) return;
for (int i = bottom; i >= top; i--) res.add(matrix[i][left]);
left++;
print(left,right,top,bottom,matrix);
}
}5、包含min函数的栈(简单)
描述
定义栈的数据结构,请在该类型中实现一个能够得到栈中所含最小元素的 min 函数,输入操作时保证 pop、top 和 min 函数操作时,栈中一定有元素。
此栈包含的方法有:
push(value):将value压入栈中
pop():弹出栈顶元素
top():获取栈顶元素
min():获取栈中最小元素
数据范围:操作数量满足 0≤n≤300 0≤n≤300 ,输入的元素满足 ∣val∣≤10000 ∣val∣≤10000
进阶:栈的各个操作的时间复杂度是 O(1) O(1) ,空间复杂度是 O(n) O(n)
示例:
输入: ["PSH-1","PSH2","MIN","TOP","POP","PSH1","TOP","MIN"]
输出: -1,2,1,-1
解析:
"PSH-1"表示将-1压入栈中,栈中元素为-1
"PSH2"表示将2压入栈中,栈中元素为2,-1
“MIN”表示获取此时栈中最小元素==>返回-1
"TOP"表示获取栈顶元素==>返回2
"POP"表示弹出栈顶元素,弹出2,栈中元素为-1
"PSH1"表示将1压入栈中,栈中元素为1,-1
"TOP"表示获取栈顶元素==>返回1
“MIN”表示获取此时栈中最小元素==>返回-1
示例1
输入:
["PSH-1","PSH2","MIN","TOP","POP","PSH1","TOP","MIN"]
返回值:
-1,2,1,-1答案
这个就是弄一个辅助栈,每次压入的时候判断辅助栈中的顶是不是最小,哪个小就压入辅助栈,删除的时候两个一起删除,最后peek辅助栈得到最小
import java.util.*;
import java.util.Stack;
public class Solution {
Stack<Integer> s1 = new Stack<>();
//用于存储最小min
Stack<Integer> s2 = new Stack<Integer>();
public void push(int node) {
s1.add(node);
if(s2.isEmpty() || s2.peek() > node){
s2.push(node);
}else{
s2.push(s2.peek());
}
}
public void pop() {
s1.pop();
s2.pop();
}
public int top() {
return s1.peek();
}
public int min() {
return s2.peek();
}
}
6、栈的压入、弹出序列(中等)
描述
输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否可能为该栈的弹出顺序。假设压入栈的所有数字均不相等。例如序列1,2,3,4,5是某栈的压入顺序,序列4,5,3,2,1是该压栈序列对应的一个弹出序列,但4,3,5,1,2就不可能是该压栈序列的弹出序列。
1. 0<=pushV.length == popV.length <=1000
2. -1000<=pushV[i]<=1000
3. pushV 的所有数字均不相同
示例1
输入:
[1,2,3,4,5],[4,5,3,2,1]
返回值:
true
说明:
可以通过push(1)=>push(2)=>push(3)=>push(4)=>pop()=>push(5)=>pop()=>pop()=>pop()=>pop()
这样的顺序得到[4,5,3,2,1]这个序列,返回true 示例2
输入:
[1,2,3,4,5],[4,3,5,1,2]
返回值:
false
说明:
由于是[1,2,3,4,5]的压入顺序,[4,3,5,1,2]的弹出顺序,要求4,3,5必须在1,2前压入,且1,2不能弹出,但是这样压入的顺序,1又不能在2之前弹出,所以无法形成的,返回false 答案
也是一个辅助栈,遍历,如果栈为空,或者栈顶与popV的第i位不相等的话,就压入pushV中没有压入的数,看到相等了话就跳出将相等的删掉,然后继续,如果直到pushV的所有数字都压入栈的时候还没发现相等,那么就直接返回false
public boolean IsPopOrder (int[] pushV, int[] popV) {
// write code here
Stack<Integer> s = new Stack<>();
int n = pushV.length;
int j = 0;
for (int i = 0; i < n; i++) {
while (j < n && (s.isEmpty() || s.peek() != popV[i])) {
s.push(pushV[j]);
j++;
}
if (s.peek() == popV[i])
s.pop();
else return false;
}
return true;
}7、从上往下打印二叉树(简单)
描述
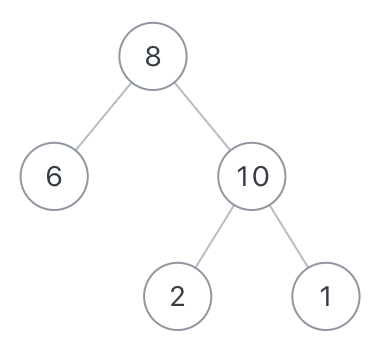
不分行从上往下打印出二叉树的每个节点,同层节点从左至右打印。例如输入{8,6,10,#,#,2,1},如以下图中的示例二叉树,则依次打印8,6,10,2,1(空节点不打印,跳过),请你将打印的结果存放到一个数组里面,返回。
数据范围:
0<=节点总数<=1000
-1000<=节点值<=1000
示例1
输入:
{8,6,10,#,#,2,1}
返回值:
[8,6,10,2,1]示例2
输入:
{5,4,#,3,#,2,#,1}
返回值:
[5,4,3,2,1]答案
利用队列的先进先出原则,将结点从左到右加入队列,然后依次出队把值存到列表中
public ArrayList<Integer> PrintFromTopToBottom(TreeNode root) {
ArrayList<Integer> list = new ArrayList<>();
if(root == null) return list;
Queue<TreeNode> q = new ArrayDeque<>();
q.offer(root);
while(!q.isEmpty()){
TreeNode cur = q.poll();
list.add(cur.val);
if(cur.left != null) q.add(cur.left);
if(cur.right != null) q.add(cur.right);
}
return list;
}8、二叉搜索树的后序遍历序列(中等)
描述
输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历的结果。如果是则返回 true ,否则返回 false 。假设输入的数组的任意两个数字都互不相同。
数据范围: 节点数量 0≤n≤10000≤n≤1000 ,节点上的值满足 1≤val≤1051≤val≤105 ,保证节点上的值各不相同
要求:空间复杂度 O(n)O(n) ,时间时间复杂度 O(n2)O(n2)
提示:
1.二叉搜索树是指父亲节点大于左子树中的全部节点,但是小于右子树中的全部节点的树。
2.该题我们约定空树不是二叉搜索树
3.后序遍历是指按照 “左子树-右子树-根节点” 的顺序遍历
4.参考下面的二叉搜索树,示例 1
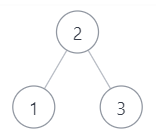
示例1
输入:
[1,3,2]
返回值:
true
说明:
是上图的后序遍历 ,返回true 示例2
输入:
[3,1,2]
返回值:
false
说明:
不属于上图的后序遍历,从另外的二叉搜索树也不能后序遍历出该序列 ,因为最后的2一定是根节点,前面一定是孩子节点,可能是左孩子,右孩子,根节点,也可能是全左孩子,根节点,也可能是全右孩子,根节点,但是[3,1,2]的组合都不能满足这些情况,故返回false示例3
输入:
[5,7,6,9,11,10,8]
返回值:
true答案
后序遍历的二叉树有个性质,就是根结点在最后一位,左右子树在前面排着,
首先我们需要按照题目给出列表的逆序进行遍历,这样我们的遍历视角转成了[根−右子树−左子树][根−右子树−左子树]。假定原输入列表的顺序为[tn,tn1,...,t2,t1][tn,tn1,...,t2,t1],则该逆序后列表内容[t0,t1,t2,...,tn][t0,t1,t2,...,tn]有如下特性:
- 当ti<ti+1ti<ti+1时,说明节点ti+1ti+1是titi的右子节点
- 当ti>ti+1ti>ti+1时,说明节点ti+1ti+1是已经遍历过的所有节点中比ti+1ti+1大的且最接近ti+1ti+1的节点的左子节点,设ti+1ti+1对应的该父节点为rootroot。同时要满足ti+1,ti+2,...,tnti+1,ti+2,...,tn都要比rootroot小。
- 根据我们推理的以上性质(加粗部分),用单调栈工具进行操作,如果能找到不符合以上性质的矛盾点,则返回
false,如果上述性质都满足,则返回true
public boolean VerifySquenceOfBST(int [] sequence) {
if(sequence.length == 0) return false;
Stack<Integer> s = new Stack<>();
int root = Integer.MAX_VALUE;
for(int i = sequence.length - 1;i >= 0;i--){
if(sequence[i] > root) return false;
while(!s.isEmpty() && s.peek() > sequence[i]){
root = s.pop();
}
s.add(sequence[i]);
}
return true;
}9、复杂链表的复制(较难)
描述
输入一个复杂链表(每个节点中有节点值,以及两个指针,一个指向下一个节点,另一个特殊指针random指向一个随机节点),请对此链表进行深拷贝,并返回拷贝后的头结点。(注意,输出结果中请不要返回参数中的节点引用,否则判题程序会直接返回空)。 下图是一个含有5个结点的复杂链表。图中实线箭头表示next指针,虚线箭头表示random指针。为简单起见,指向null的指针没有画出。
示例:
输入:{1,2,3,4,5,3,5,#,2,#}
输出:{1,2,3,4,5,3,5,#,2,#}
解析:我们将链表分为两段,前半部分{1,2,3,4,5}为ListNode,后半部分{3,5,#,2,#}是随机指针域表示。
以上示例前半部分可以表示链表为的ListNode:1->2->3->4->5
后半部分,3,5,#,2,#分别的表示为
1的位置指向3,2的位置指向5,3的位置指向null,4的位置指向2,5的位置指向null
如下图:

示例1
输入:
{1,2,3,4,5,3,5,#,2,#}
返回值:
{1,2,3,4,5,3,5,#,2,#}答案
public RandomListNode Clone(RandomListNode pHead) {
//空节点直接返回
if (pHead == null)
return pHead;
//添加一个头部节点
RandomListNode cur = pHead;
//遍历原始链表,开始复制
while (cur != null) {
//拷贝节点
RandomListNode clone = new RandomListNode(cur.label);
//将新节点插入到被拷贝的节点后
clone.next = cur.next;
cur.next = clone;
cur = clone.next;
}
cur = pHead;
RandomListNode clone = pHead.next;
RandomListNode res = pHead.next;
//连接新链表的random节点
while (cur != null) {
//跟随前一个连接random
if (cur.random == null)
clone.random = null;
else
//后一个节点才是拷贝的
clone.random = cur.random.next;
//cur.next必定不为空
cur = cur.next.next;
//检查末尾节点
if (clone.next != null)
clone = clone.next.next;
}
cur = pHead;
clone = pHead.next;
//拆分两个链表
while (cur != null) {
//cur.next必定不为空
cur.next = cur.next.next;
cur = cur.next;
//检查末尾节点
if (clone.next != null)
clone.next = clone.next.next;
clone = clone.next;
}
return res;
}10、二叉搜索树与双向链表(中等)
描述
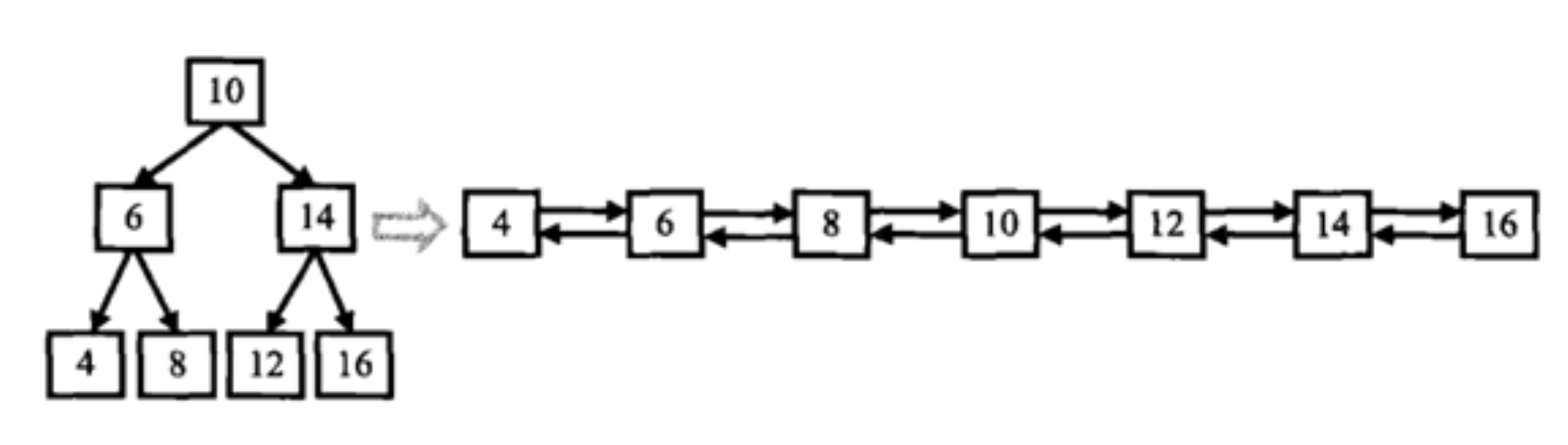
输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的双向链表。如下图所示
数据范围:输入二叉树的节点数 0≤n≤10000≤n≤1000,二叉树中每个节点的值 0≤val≤10000≤val≤1000
要求:空间复杂度O(1)O(1)(即在原树上操作),时间复杂度 O(n)O(n)
注意:
1.要求不能创建任何新的结点,只能调整树中结点指针的指向。当转化完成以后,树中节点的左指针需要指向前驱,树中节点的右指针需要指向后继
2.返回链表中的第一个节点的指针
3.函数返回的TreeNode,有左右指针,其实可以看成一个双向链表的数据结构
4.你不用输出双向链表,程序会根据你的返回值自动打印输出
输入描述:
二叉树的根节点
返回值描述:
双向链表的其中一个头节点。
示例1
输入:
{10,6,14,4,8,12,16}
返回值:
From left to right are:4,6,8,10,12,14,16;From right to left are:16,14,12,10,8,6,4;
说明:
输入题面图中二叉树,输出的时候将双向链表的头节点返回即可。 示例2
输入:
{5,4,#,3,#,2,#,1}
返回值:
From left to right are:1,2,3,4,5;From right to left are:5,4,3,2,1;
说明:
5
/
4
/
3
/
2
/
1
树的形状如上图 答案
依然递归
import java.util.*;
/**
public class TreeNode {
int val = 0;
TreeNode left = null;
TreeNode right = null;
public TreeNode(int val) {
this.val = val;
}
}
*/
public class Solution {
//返回的第一个指针,即为最小值,先定为null
public TreeNode head = null;
//中序遍历当前值的上一位,初值为最小值,先定为null
public TreeNode pre = null;
public TreeNode Convert(TreeNode pRootOfTree) {
if(pRootOfTree == null)
//中序递归,叶子为空则返回
return null;
//首先递归到最左最小值
Convert(pRootOfTree.left);
//找到最小值,初始化head与pre
if(pre == null){
head = pRootOfTree;
pre = pRootOfTree;
}
//当前节点与上一节点建立连接,将pre设置为当前值
else{
pre.right = pRootOfTree;
pRootOfTree.left = pre;
pre = pRootOfTree;
}
Convert(pRootOfTree.right);
return head;
}
}
面试题5道
1、谈一谈你对操作系统的理解?
操作系统是一种软件,它是计算机系统中的核心组件,负责管理和协调计算机硬件资源,为应用程序提供运行环境和服务。
操作系统的主要作用包括:
- 资源管理:操作系统负责管理计算机的硬件资源,如处理器、内存、硬盘和外部设备等,以便合理地分配和利用这些资源。它通过调度算法和资源分配机制,确保每个任务或进程都能得到适当的资源。
-
进程管理:操作系统能同时运行多个程序,通过进程管理,它可以控制程序的执行、调度和协作,以便提高计算机的整体效率。它负责创建、终止、挂起和恢复进程,以及管理进程之间的通信与同步。
-
文件管理:操作系统负责管理计算机的文件系统,方便用户存储和获取数据,确保数据的安全性和完整性。它提供了文件的创建、读写、删除和重命名等操作,以及文件的权限管理和保护。
-
用户界面:操作系统提供了与计算机交互的用户界面,可以是命令行界面或图形用户界面(GUI),使得用户可以方便地使用计算机。用户可以通过输入指令或点击图标进行操作和访问系统功能。
-
错误检测和恢复:操作系统能够监测和处理软件和硬件错误,提供错误检测和恢复的机制,以保证计算机的稳定性和可靠性。它可以监测和捕获程序的异常、处理硬件故障、提供备份和恢复机制等。
操作系统是计算机系统中的大管家,它负责管理和协调计算机的各种资源,为应用程序提供一个安全、高效的运行环境。操作系统的设计和优化对于提高计算机的性能、可靠性和用户体验至关重要。
2、简单说下你对并发和并行的理解?
当谈到计算机系统中的并发和并行时,它们具有不同的含义。
并发(Concurrency)是指系统能够处理多个任务的能力,这并不意味着这些任务一定会同时进行。并发的任务可能会交错进行,因此并发可以在单核CPU上实现。这是因为CPU可以通过时间片轮转或其他任务切换策略,在各个任务之间快速切换,给人以它们在同时进行的错觉。一个简单的例子就是我们的操作系统,它可以在运行大量应用程序(如我们的浏览器,文档编辑器,音乐播放器等)同时,保持系统稳定和响应,尽管实际上,那些进程并不总是“同时”运行。
而并行(Parallelism)则是指系统同时执行多个任务的能力。并行显然需要硬件的支持,如多核心或多处理器。在这种情况下,多个任务确实可以在同一时间内进行。例如,现代的多核CPU可以让我们在看电影的同时进行视频编码,每一个任务在不同的处理器核心上执行,这就是并行。
总的来说,如果你有两个线程在单核心的CPU上,那么可能会通过交错执行达到并发。如果你的电脑有多个核心或处理器,你就可以在多个核心或处理器上同时执行多个线程,这是并行。
3、同步和异步有什么区别?
同步和异步是操作系统中的两种重要概念,它们主要涉及到程序的运行方式和时间管理。
- 同步(Synchronous)操作是在一个操作完成之前,不进行下一个操作。这是一种阻塞调用,也就是说,进行某项操作的过程中,不得不停下来等待,直到这个操作完成。例如,当你在核对大批量的数据时,你需要等待所有数据都加载完毕才能继续进行下一项操作,这就是同步。
-
异步(Asynchronous)操作是不需要立刻得到结果,即使未完成也可进行其它操作。这是一种非阻塞调用,也就是说,还没得到结果,就继续做别的事情,不会因为单一操作的等待而阻塞。例如,你去网上订一张火车票,由于网站服务器繁忙,订票需要一些时间,但是你不会就一直盯着屏幕等,而是可以一边浏览新闻或者查看其他信息一边等待订票结果,这就是异步操作。
这两种方式各有利弊,选择使用同步还是异步,主要取决于具体的需求和场景。
4、阻塞和非阻塞有什么区别?
阻塞和非阻塞是描述任务或操作在等待结果时的行为方式的概念。
阻塞是指任务在等待某个操作完成时,暂停自己的执行,并等待操作完成后再继续执行。在阻塞状态下,任务会一直等待,直到所需的资源或结果就绪。在此期间,任务不能执行其他操作。例如,当一个线程调用阻塞式IO操作时,它会被挂起,直到IO操作完成后才能继续执行。
非阻塞是指任务在等待某个操作完成时,不会暂停自己的执行,而是立即返回,继续执行其他任务。非阻塞的任务会周期性地查询所需资源或结果的状态,判断是否就绪,从而决定是否继续执行。例如,在进行非阻塞式IO操作时,任务会立即返回,并周期性地检查IO操作的状态,直到IO完成后再处理结果。
简单来说,阻塞是等待结果时暂停自己的执行;非阻塞是等待结果时继续执行其他任务。
在实际应用中,阻塞和非阻塞可以用在不同的场景中。阻塞适用于需要确保结果完整性和依赖顺序的情况,而非阻塞适用于需要提高并发性和响应性的情况。选择适合的阻塞和非阻塞方式可以提高程序的效率和性能。
5、computed、watch、methods的区别
computed计算属性是用来声明式的描述一个值依赖了其它的值。当你在模板里把数据绑定到一个计算属性上时,Vue会在其依赖computed计算属性是用来声明式的描述一个值依赖了其它的值。当你在模板里把数据绑定到一个计算属性上时,Vue会在其依赖















 6266
6266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









