







在ANSI C的任何一种实现中,存在两个不同的环境;
第一种是翻译环境,在这个环境中源代码被转化为可执行二进制的机器指令。
第二种是执行环境,它用于实际执行代码。
通常情况下,翻译环境是由编译器提供的;执行环境是由OS(Operating System)提供的。
一个源文件会经过两个过程生成一个可执行文件
第一个过程:编译(依赖编译器);
第二个过程:链接(依赖链接器);
vs2019,DEV C++,codeBlocks等等被称之为集成开发环境(IDE),具有编辑、编译、链接、调试等等功能。
例如,像VS2019它的编译器是cl.exe,它的链接器是link.exe.
链接库是一些库函数所依赖的库文件(*.lib)。
编译过程:可以细化为三个过程,预编译,编译,汇编。将一个源文件 ------> 目标文件
接下来我在Linux下演示着三个过程:
首先:我用C写了两个源文件;test.c和add.c;
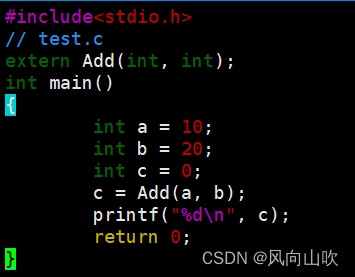

接下来, 如果只观察预编译后的结果(以test.c)举例, gcc test.c -E -o test.i
-o output
将预编译后的结果指定输出到test.i文件里

进入test.i你就会发现,这里面多了800多行代码,那这些是什么呢 ?
如果你细心观察,你会发现test.i里面虽然多了这么多代码,但是和test.c 相比少了#include<stdio.h>
include有包含的意思,难道是将test.c里面的头文件包含的东西全部展开吗 ?
OK,如果你这么想,那么你猜对了。
预编译首先做的就是会将头文件展开;
Ok,我在修改一下代码,看看预编译还会做什么?
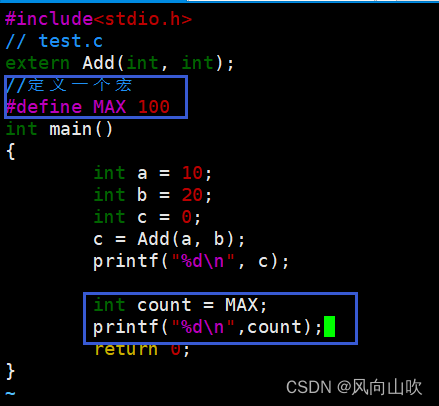
在test.c文件里增添了一个宏,看看预编译会做什么?

进入test.i
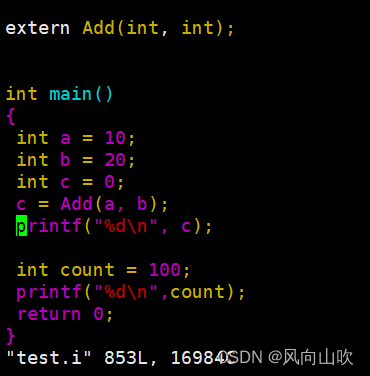
你惊奇的发现,宏消失了,宏符号MAX被替换成100了。并且所有的注释都没见了。
预编译的第二件事:#define定义符号的替换;
预编译的第三件事:删除注释;
总结:预编译会将头文件展开;会完成#define定义符号的替换;会删除注释;(而这些都是文本操作)。
接下来就进入编译,编译又会发生什么事呢 ?
OK,我们对预编译的文件进行处理,gcc test.i -S 得到一个(*.s)文件

我们进去看一下,这里面生成的到底是些什么东西?

你惊奇的发现,诶,这不是一些汇编指令吗 ?
OK,从结果来看我们可以知道,编译过程就是将源程序的代码翻译成了汇编代码。
这个过程十分复杂,会进行语法分析、词法分析、语义分析、符号汇总。
在这里本人能力有限,不能详解。
当编译完成后,进入汇编,这时候汇编又会发生什么事呢?
我们需要对编译后的(*.s)进行处理 gcc test.s -c 得到一个目标文件
这个目标文件在Windows环境为(*.obj),在Linux环境为(*.o);
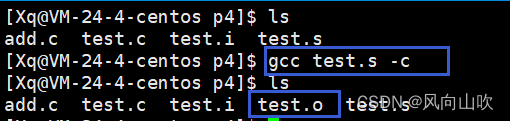
OK,生成的这个目标文件里面到底是些什么东西呢?
你会发现,生成的这些一大串,我们是无法看懂的。这是因为目标文件是二进制形式的。
即汇编过程就是将,编译生成的汇编指令翻译成了二进制的机器指令。
但其实,汇编过程还会形成符号表。
在Linux环境下,test.o的可执行程序的格式是:elf;
虽然我们看不懂这些二进制,但是有一个工具叫readelf可以看懂。
我们用这个工具,会发现有一个选项叫 -s 可以帮助我们显示符号表。
![]()
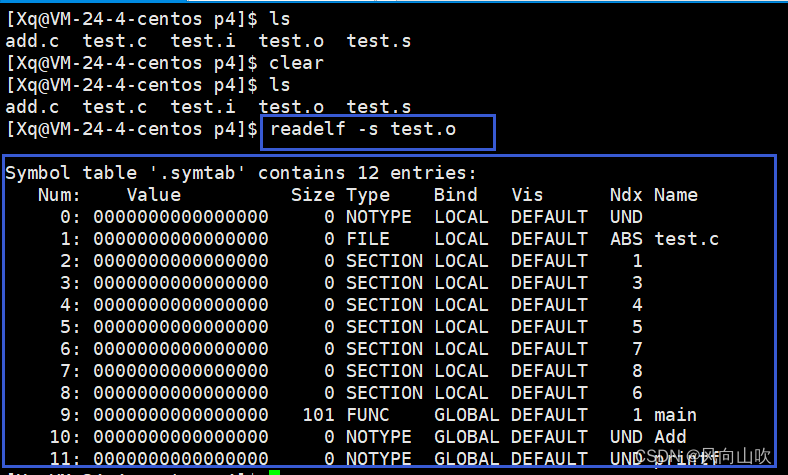
当汇编结束后,就会进入链接过程。
链接过程会发生什么事呢?
1.合并段表;
2.符号表的合并和重定位。
其实不止这些过程,在这里只是一小部分,这个过程都是十分复杂的。
在这里谈一下符号表的合并和重定位。
前面已经说过,每一个源程序,经过编译过程都会生成一个二进制的目标文件,并且形成自己的
符号表。
在这里我用vs举例
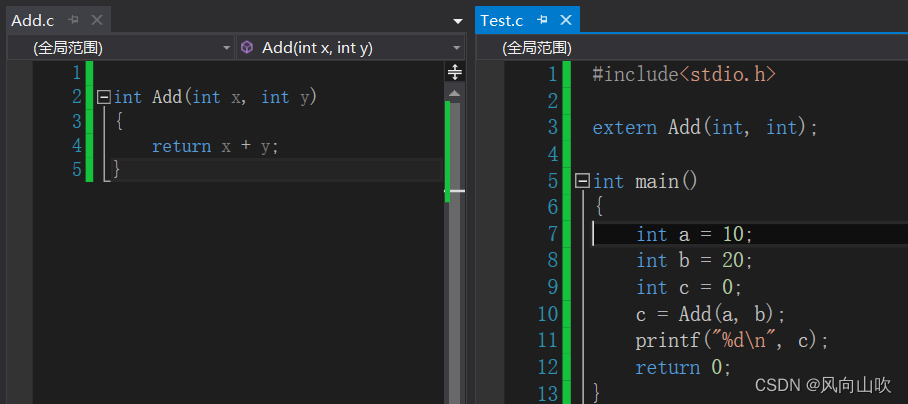
说这两个.c文件在编译过程都会形成属于自己的符号表。
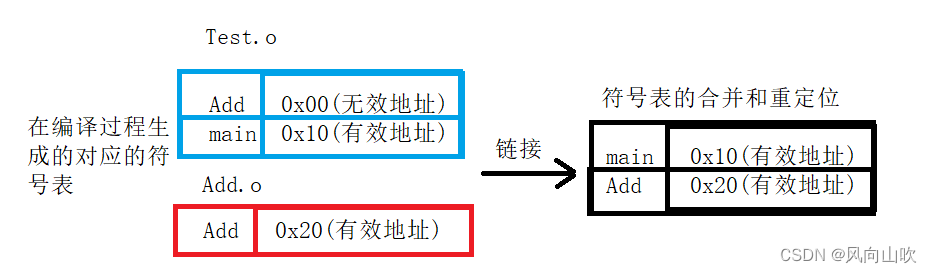
如果我将左侧的Add函数给注释掉,让Add变为无效地址
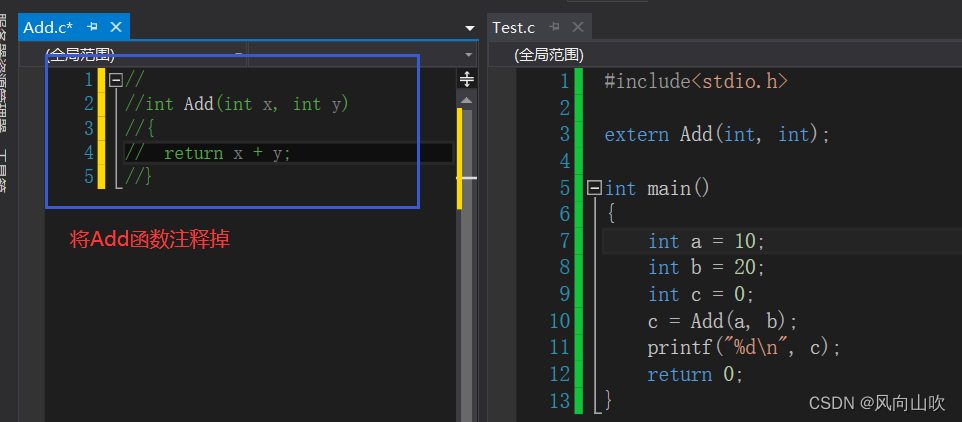 编译器自然就会在链接过程报错。此时的符号表汇总就会变成这样。
编译器自然就会在链接过程报错。此时的符号表汇总就会变成这样。
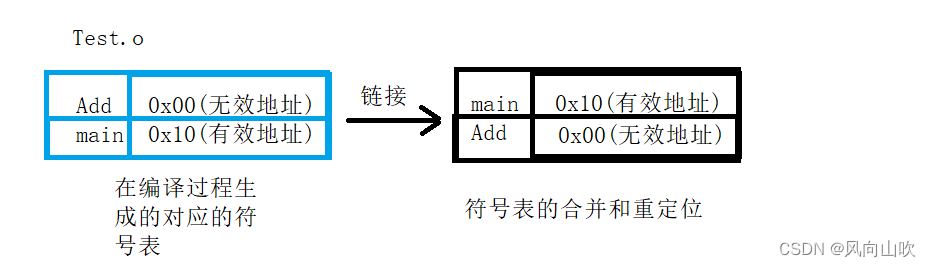
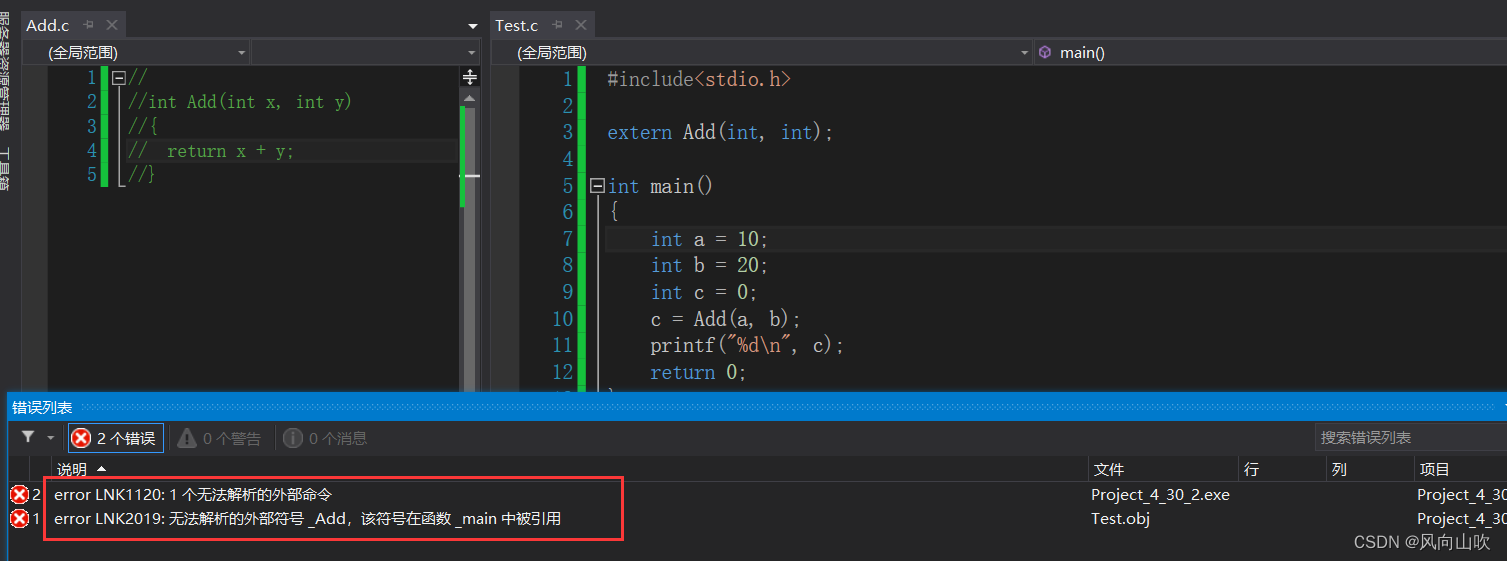
果然,error LNK 就是说在链接过程中无法找到Add这个有效的地址。自然会报错。
运行环境
程序执行的过程:
1.程序必须载入内存中。再有OS的环境中:一般这个由OS完成。在独立的环境中,
程序的载入必须由手工安排,也可能是通过可执行代码置入只读内存来完成。
2.程序的执行便开始。接着调用main函数。
3.开始执行程序代码。这个时候程序将使用一个运行时堆栈(stack),存储函数的局部变量和地址。
程序同时也可以使用静态(static)内存,存储与静态内存中的变量在程序的整个执行过程一直保留它们的值。
4.终止程序。正常终止main();也可能是意外终止。
最后,我想说的是,我对这些过程只能说存于表面,并没有深入理解,各位权当是看看,如果有兴趣深入理解这些过程,建议去看一本书《程序员的自我修养》。当然如果对上面内容有建议或者发现错误的话,希望你能评论或者私信,我十分非常愿意倾听你的建议。















 2792
2792











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









