






文章目录
第三章 词法分析
3.1 单词的描述
词法分析器的任务

词法分析器的位置
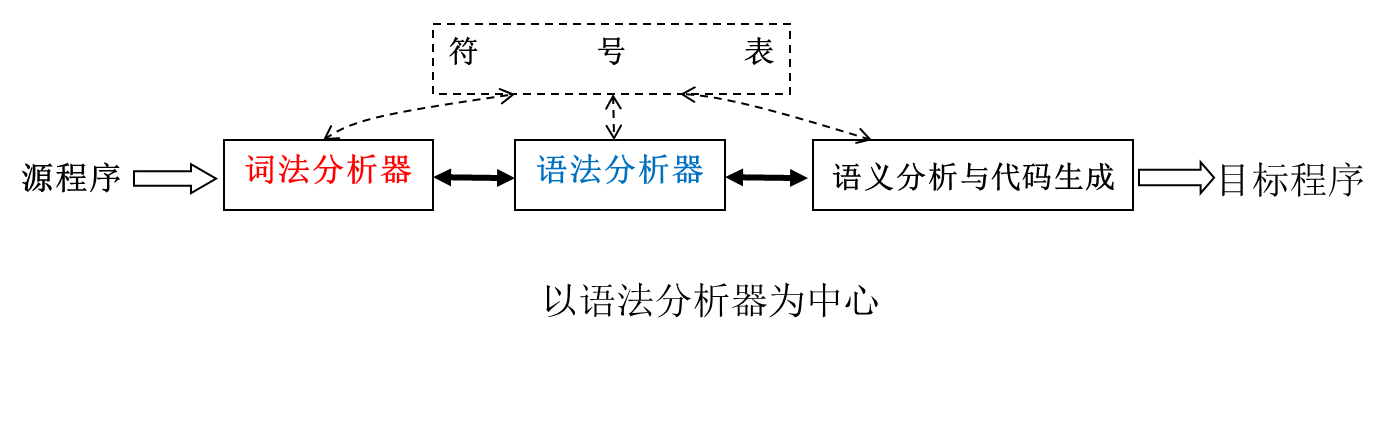
将词法分析器设计为单独的遍具有如下优点:
- 简化编译器的设计:任务独立,语法分析更简易
- 提高编译器的效率
- 增强编译器的可移植性:只有词法分析与输入设备有关。
词法单元符号设计
语法分析器依据文法识别token串,符号的集合即是文法的终结符集合。

单词的描述:正则表达式
正则表达式可以由较小的正则表达式按照特定规则递归地构建。每个正则表达式 r r r定义(表示)一个语言,记为 L ( r ) L(r ) L(r)。这个语言也是根据 r r r的子表达式所表示的语言递归定义的
如果两个正则表达式 r r r和 s s s表示同样的语言,则称 r r r和 s s s等价,记作 r = s r=s r=s
运算的优先级:*、连接、|


对任何正则文法 G,存在定义同一语言的正则表达式 r
对任何正则表达式 r,存在生成同一语言的正则文法 G
正则定义

3.2 单词的识别(重点)
有穷自动机:系统只需要根据当前所处的状态和当前面临的输入信息就可以决定系统的后继行为。
- 给定输入串 x x x,如果存在一个对应于串 x x x的从初始状态到某个终止状态的转换序列,则称串 x x x被该FA接收
- 由一个有穷自动机 M M M接收的所有串构成的集合称为该FA定义(或接收)的语言,记为 L ( M ) L(M) L(M)
服从最长子串匹配原则
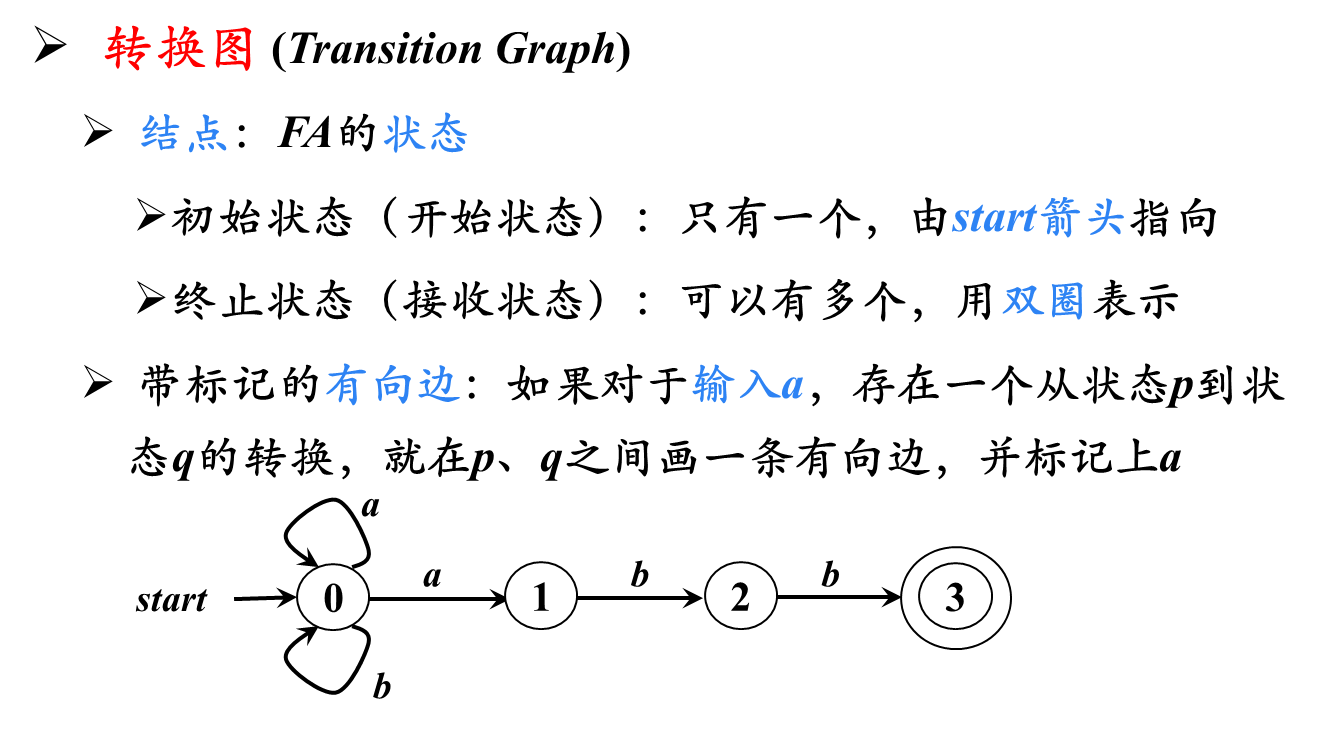
3.2.1 DFA

3.2.2 NFA

带有“ε-边”的 NFA

DFA和NFA可以识别相同的语言
- 对任何NFA N N N ,存在定义同一语言的DFA D D D
- 对任何DFA D D D ,存在定义同一语言的NFA N N N
3.2.3 从正则表达式到有穷自动机

3.2.4 从NFA到DFA的转换


3.3 词法分析阶段的错误处理

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









