






1.1 HDFS的体系结构
HDFS,采用master/slaves主从结构,结构模型由Client,NameNode,DataNode和Secondary NameNode组成。
*真正的一个HDFS集群包括一个NameNode和多个DataNode。
1)NameNode:中心服务器,负责文件系统的命名空间。同时能持久性对文件备份,避免由于宕机而导致数据缺失。主要管理客户端对文件的访问,即NameNode并不真正保存数据,而是保存用户的操作。
2)DataNode:真正负责管理客户端的读写请求,保存数据。每个DataNode会定期给NameNode发送数据,告知自己的状态(心跳机制),没有按时发送心跳机制信息的DataNode会被NameNode标记为“宕机”,不会分配I/O请求。
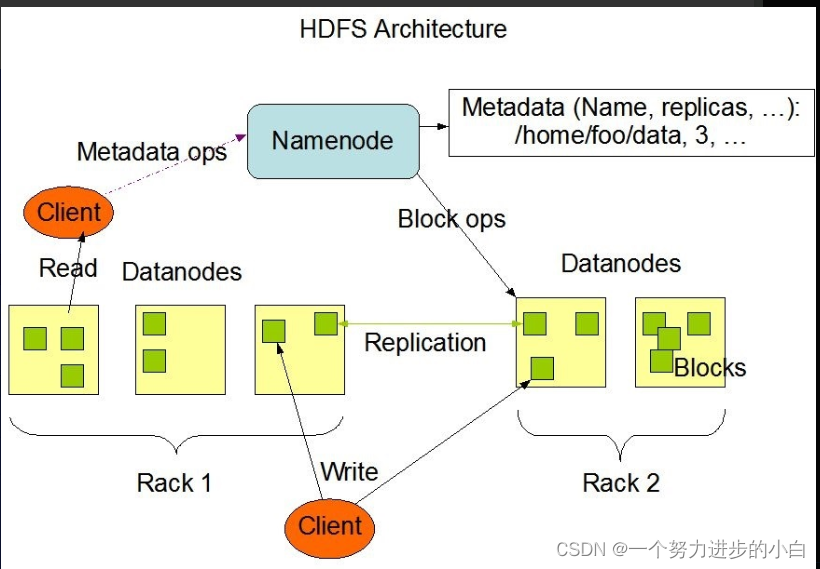
由于HDFS的一次写入,多次读取,不可修改构建思路,使得它是最高效的访问模式。
1.2 HDFS几种常用的命令
1)在hadoop下创建目录:
start-dfs.sh 一定要记住启动NameNode和DataNode
hadoop fs -mkdir /usr 创建一个/usr目录
hadoop fs -mkdir -p /usr/text -p 可级联创建
2)上传文件到dfs
现在本地/input目录下创建一个hello.txt文件
touch hello.txt
hadoop fs -put /input/hello.txt /usr/text 将文件上传至hdfs的/usr/test中
3)删除与移出
hadoop fs -mv /usr/test/hello.txt 将hello.txt移动到根目录
hadoop fs -rm /usr/test/hello.txt 将文件hello.txt删除(非空白)
hadoop fs -rmr /usr/test/hello.txt 递归删除
4)从本地复制
hadoop fs -copyFromLocal 原文件路径 新的文件路径
5) 从HDFS复制到本地
hadoop fs -copyToLocal 原文件路径 新的文件路径
小小白吐槽:在写hdfs命令是一定要先开启start-dfs.sh 或start-all.sh ,我在第一次写的时候一直回报-bash: hadooop: command not found,当时还不知道是什么原因,甚至会产生是由于没进入hadoop的原因,在cd hadoop ,还是不对,一度焦躁,后来无疑往前回顾知识点原来是没有开启hdfs,因此衷心的建议大家学编程是一项艰难,细致的过程,希望大家保持一个平静的心态学习。
最后给大家分享一个我很喜欢的话
Don't aim for success if you really want ,just stick to what you love and believe in ,and it will come naturally! ---------少一些功利主义的追求,多一些不为什么的坚持!















 914
914











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









