







目录
什么是文件系统?
文件系统是操作系统的一部分,它是一个软件程序,主要用于管理和存储文件。文件系统提供了各种接口和命令,便于用户通过他们对文件进行各种操作。
为什么出现了HDFS分布式文件系统
大数据时代的到来,人们对数据的依赖性越来越大、上网产生的数据量急剧增加、信息量爆炸式增长。因此,只是通过增加计算机的硬盘容量处理数据难以达到要求,这样将所有的数据存储和处理在同一台计算机上便不可行了。此时通过增加计算机的横向容量,即增加计算机的数量,将数据分布在多台计算机上的Hadoop 分布式计算便诞生了。而HDFS是Hadoop 分布式计算的一个重要组成部分,分布式文件系统。
HDFS的设计目标
- 高容错性。HDFS被设计成可运行于由成千上万的PC或服务器组成的集群上,在系统处理数据的过程中,硬件发生故障可能是常态,为了保证数据的正常处理,数据在HDFS中会自动保存多份,并且存储于不同的机架上,这样就可以大大增加系统容错性。
- 流式数据访问。通过分块机制,不需要等待全部数据的到来,只需要将数据分块,一块一块的进行处理,增加实时性。
- 面向大数据集。运行于HDFS之上的应用一般都具有大数据集。HDFS不适合小文件的处理,占用 namenode 节点。
- 不允许数据修改。由于HDFS处理的都是大数据集,因此,当数据上传到Hadoop集群后,会进行文件的切割、复制、分发等操作,当写好的数据被修改时相当于再来一遍该过程。
- 移动计算程序而不是计算数据。在靠近数据存储的位置进行数据处理是最有利的方式,这样减少了大量数据的传输,消除了网络的拥堵。因此HDFS提供了接口来让代码移动到靠近数据存储的位置。
分布式文件系统的结构

HDFS 架构主要由四部分组成,Client、NameNode、SecondaryNameNode、DataNode。
- Client 为客户端。主要功能如下:
- 文件切分 。当文件要写入HDFS时,Client 会将文件切分成无数的block,一个一个的依次写入。
- 与namenode 交互。从namenode 获取文件所要存储的位置。
- 与datanode 交互。进行数据传输,写入或读取数据。
- 管理和访问HDFS。
- namenode为名称节点,也称为主节点。
- 管理着数据节点和数据块之间的映射关系。
- 可以在默认的情况下进行文本复制。
- 响应客户端请求(上传、下载、复制文件信息等 )。
- datanode为数据节点。
- 管理数据块,执行数据块的读写操作。数据节点中保存着数据块,数据块用来存储数据。
- datanode 保持着与namenode 之间的通讯,以执行namenode 的指令。同时namenode 可以确保datanode 是否正常工作,如果超过10分钟的时间没有接受datanode 的指令,则会将该地对应的数据块复制到其他正常的datanode 中。
- 块:在操作系统中,文件系统一般会将磁盘划分为相同大小的 “磁盘块”,用来进行文件读写,它是文件系统进行读写的最小单位,在 HDFS 中,同样也是如此,但不同的是,HDFS 中块的大小一般为64MB或128MB。
- 名称节点(主节点namenode ):保存文件的属性信息,便于用户能够访问到所有的数据块。
HDFS 读写文件流程
写文件流程:

- 首先客户端向namenode 请求上传文件,并传输想要创建文件的目录。
- namenode 检查该目录树是否可以创建文件,并响应给客户端可以上传文件。
- Client 请求上传第一个block。
- namenode 返回可以存储数据的三个节点。
- Client 请求datanode建立Block 传输通道,以此来实现数据的多份存储。
- datanode 返回建立通道成功。
- Client 直接向namenode 返回的三个datanode 节点写入数据。
读文件流程:
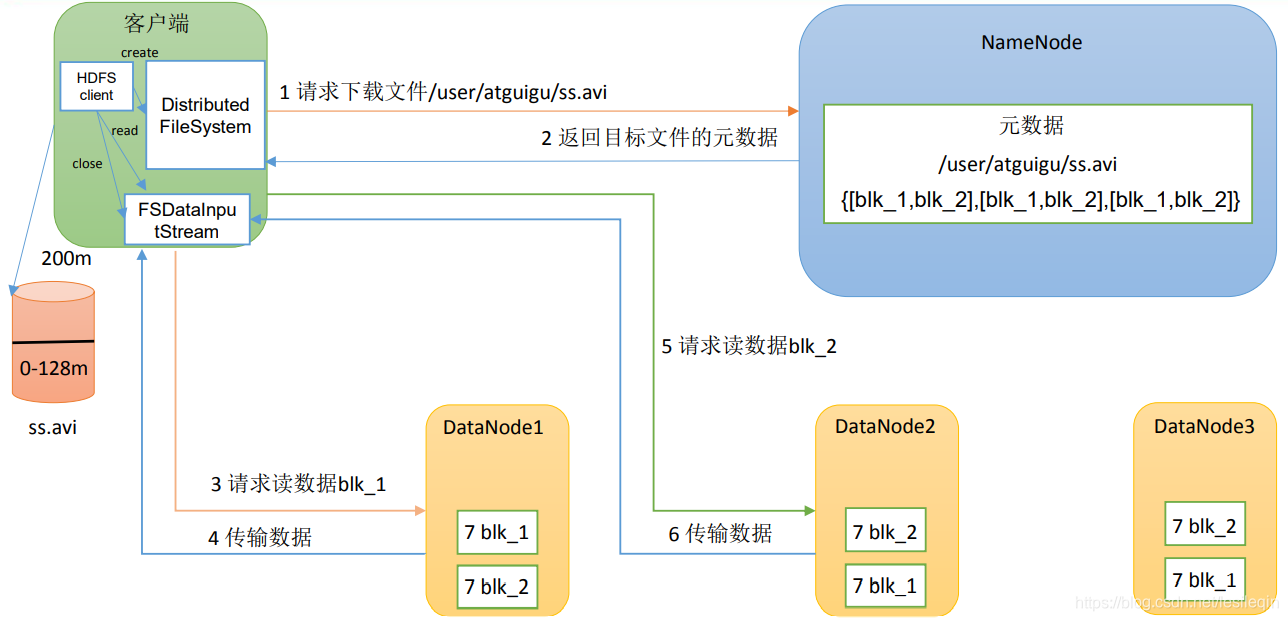
- 首先客户端向namenode 请求下载,传入文件的目录。
- namenode 返回给Client 文件的存储位置(查询文件元数据,得到存储文件的datanode 地址)。
- Client 请求读数据。
- 采用就近原则读取datanode 中的数据。















 1109
1109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









