






关于YOLOv3系列的一些理论概念
网络结构
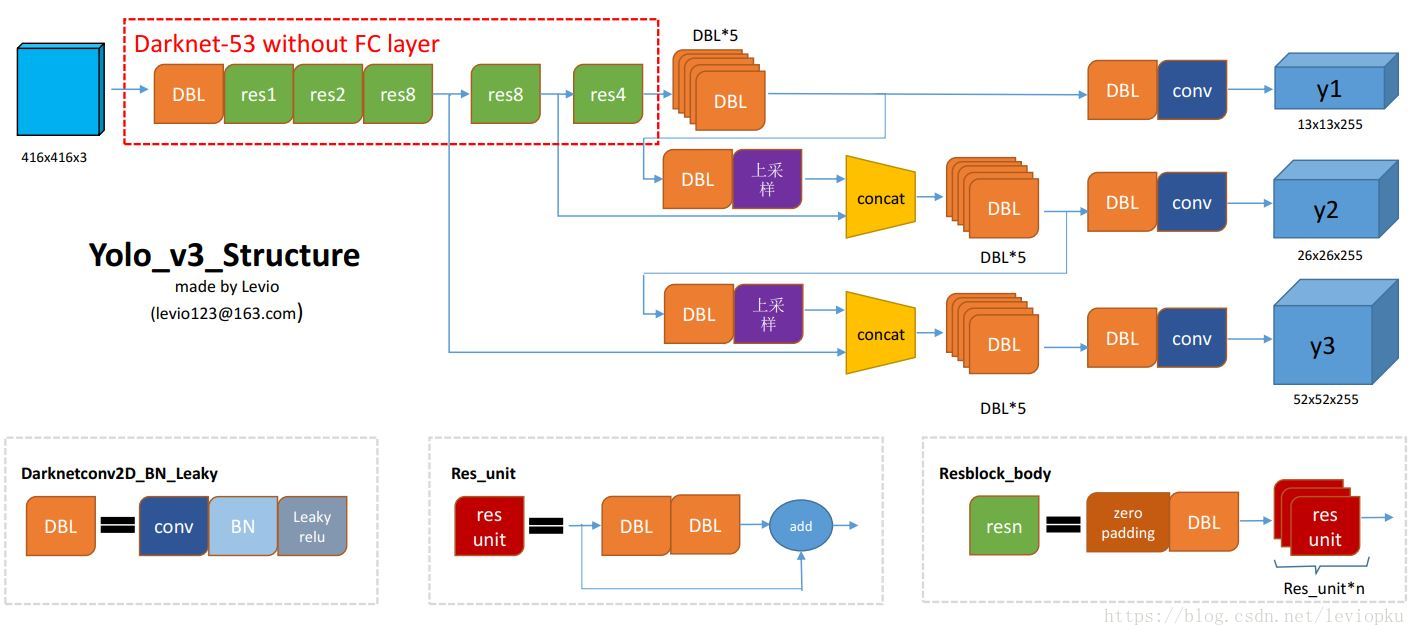
图片来源:(22条消息) yolo系列之yolo v3【深度解析】_木盏的博客-CSDN博客_yolo3
DBL:
代码中的Darknetconv2d_BN_Leaky,是YOLOv3的基本组件,就是卷积+BN+Leaky relu。
resn:
n代表数字,有res1,res2, … ,res8等等,表示这个res_block里含有多少个res_unit。不懂resnet请戳这儿
concat:
张量拼接;将darknet中间层和后面的某一层的上采样进行拼接。拼接的操作和残差层add的操作是不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。
Backbone:darknet-53
为了达到更好的分类效果,作者自己设计训练了darknet-53,在ImageNet数据集上实验发现这个darknet-53,的确很强,相对于ResNet-152和ResNet-101,darknet-53不仅在分类精度上差不多,计算速度还比ResNet-152和ResNet-101强多了,网络层数也比他们少,测试结果如图所示。
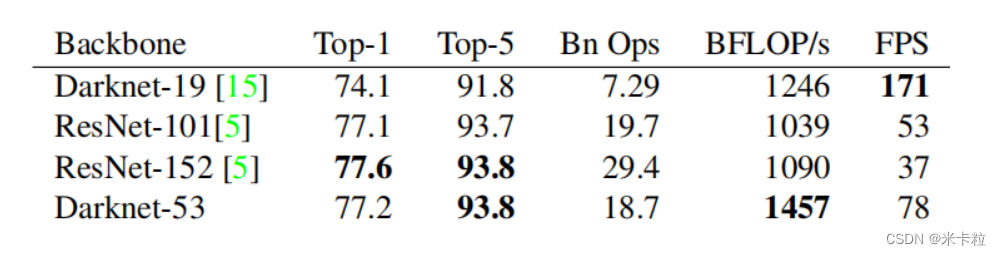
darknet-53的网络结构如下图所示。YOLOv3使用了darknet-53的前面的52层(没有全连接层),YOLOv3这个网络是一个全卷积网络,大量使用残差的跳层连接,并且为了降低池化带来的梯度负面效果,作者直接摒弃了POOLing,用conv的stride来实现降采样。在这个网络结构中,使用的是步长为2的卷积来进行降采样。
为了加强算法对小目标检测的精确度,YOLOv3中采用类似FPN的upsample和融合做法(最后融合了3个scale,其他两个scale的大小分别是26×26和52×52),在多个scale的feature map上做检测。
作者在3条预测支路采用的也是全卷积的结构,其中最后一个卷积层的卷积核个数是255,是针对COCO数据集的80类:3*(80+4+1)=255,3表示一个grid cell包含3个bounding box,4表示框的4个坐标信息,1表示objectness score。
output
所谓的多尺度就是来自这3条预测之路,y1,y2和y3的深度都是255,边长的规律是13:26:52。YOLOv3设定的是每个网格单元预测3个box,所以每个box需要有(x, y, w, h, confidence)五个基本参数,然后还要有80个类别的概率。所以3×(5 + 80) = 255,这个255就是这么来的。















 1811
1811











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









