







关于Yolov3的一些理解
*本博客主要为记录自己学习的一些笔记,故以下图表和内容中许多来自其他博主,在此感谢他们工作
网络结构:
整体结构

Yolo_v3的网络结构可以理解为一系列组件的拼接,上图各组件的解释如下:
DBL:上图中的Darknetconv2D_BN_Leaky,是yolo_v3的基本组件。就是卷积+BN+Leaky relu。
Res_unit: 由DBL组件和concat组成,此处借鉴了ResNet的残差结构,使用这种结构可以搭建更深的网络结构。
concat:张量维度拼接。拼接的操作和残差层add的操作是不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变
resn:n代表数字,有res1,res2, … ,res8等等,表示这个res_block里含有多少个res_unit。
backbone:darknet-53
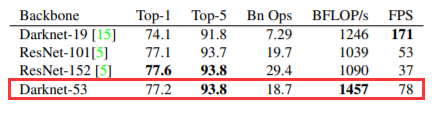
为了提升模型的检测精度,作者单独设计了darknet-53。在ImageNet上实验结果表明:darknet-53达到了和ResNet-152/ResNet-101相当的分类精度前提下,计算速度大幅度提升,网络层数也比他们少。
**
Yolo_v3使用了darknet-53的前52层(去掉全连接层)做为backbone,用于特征提取。yolo_v3是一个全卷积网络,大量使用残差的跳层连接;同时为了降低池化带来的梯度负面效果,作者直接摒弃了POOLing,降采样是通过改变卷积核的步长来实现的【即使用的是步长为2的卷积来进行降采样】,如下图红色框所示,darknet-53一共进行5次下采样操作,将输出特征图缩小到输入的1/32。所以,通常都要求输入图片的分辨率大小是32的倍数。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4099
4099











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









