






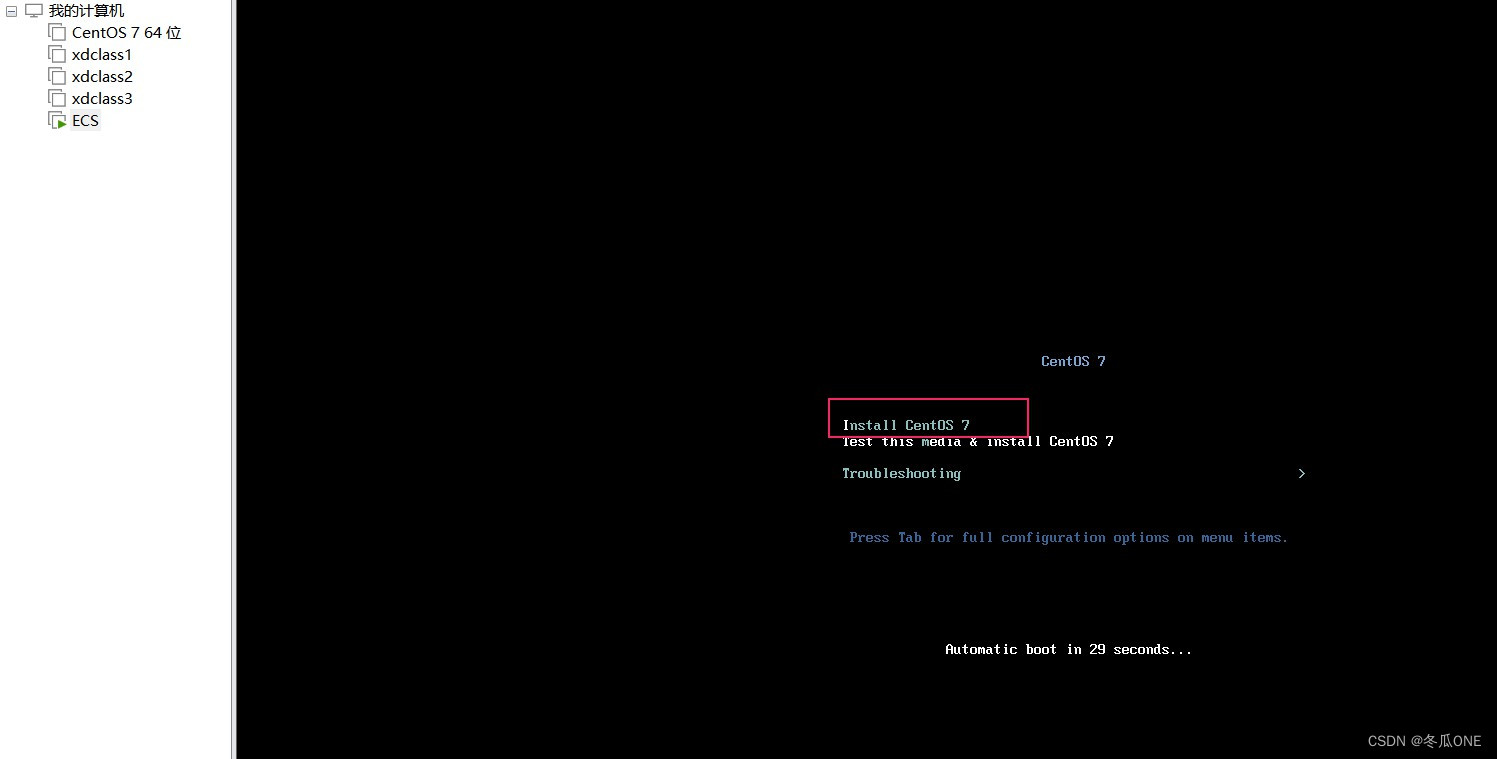
安装三台虚拟机
三台虚拟机分别配置主机名和静态ip地址(防止后期ip地址改变无法正常访问)

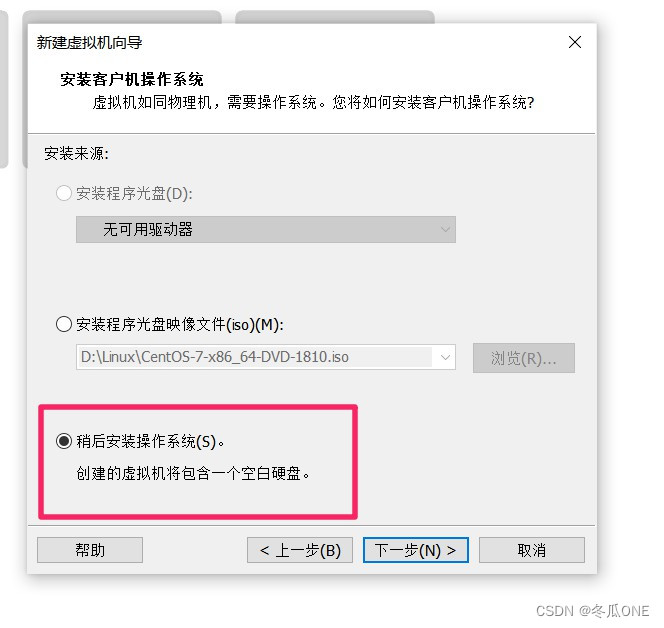
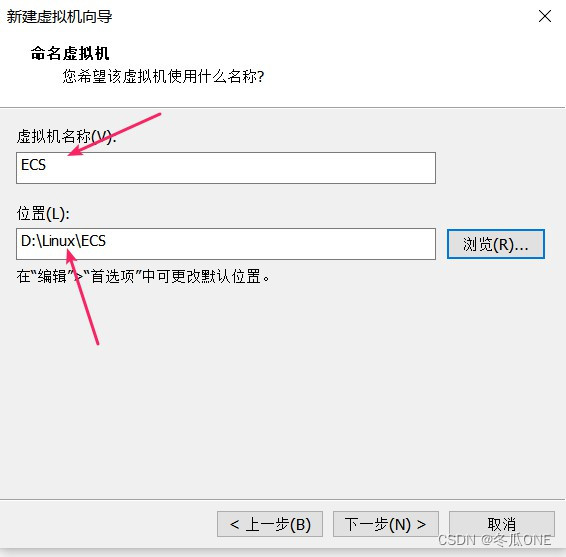
注意:这一步是配置虚拟机名(一般和主机名一样便于区分虚拟机,我配置的三台虚拟机名为xdclass1,xdclass2,xdclass3. )
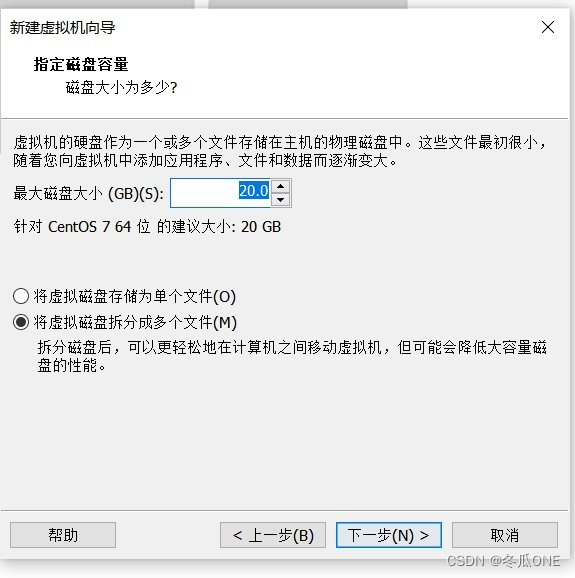
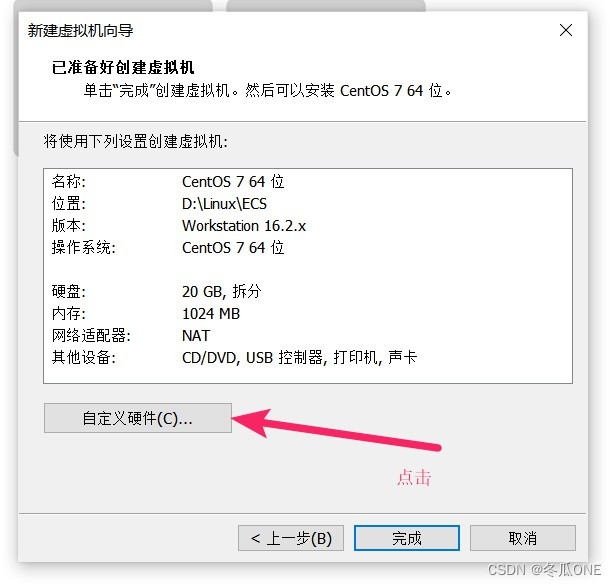
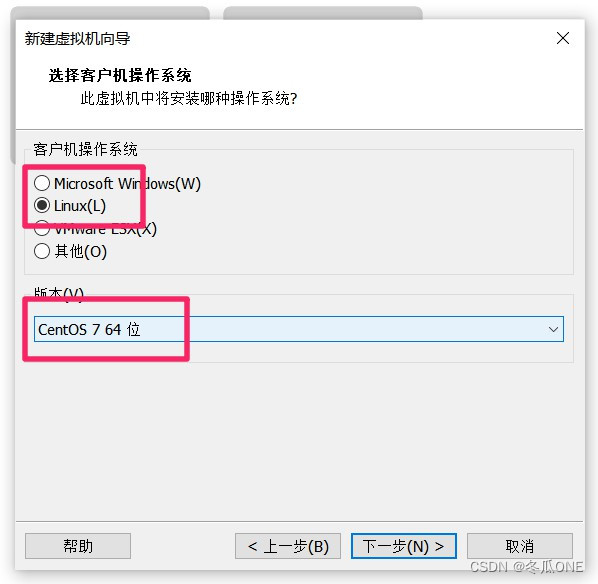
注意:这里选择第一个
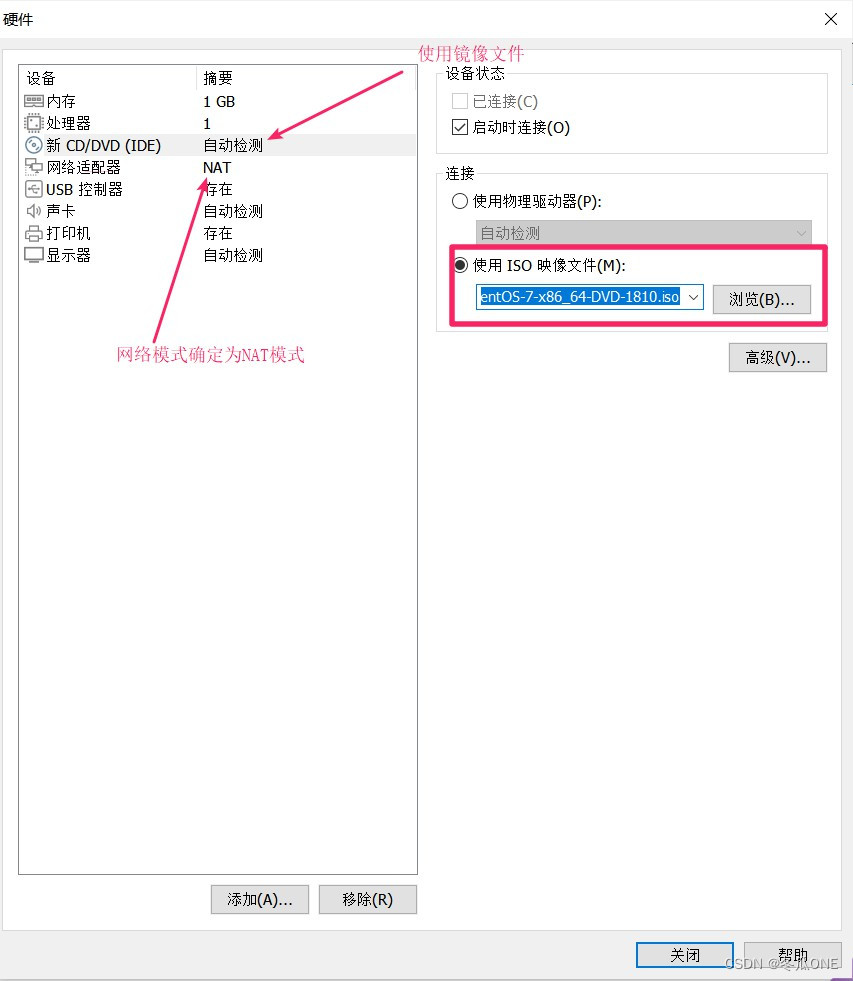
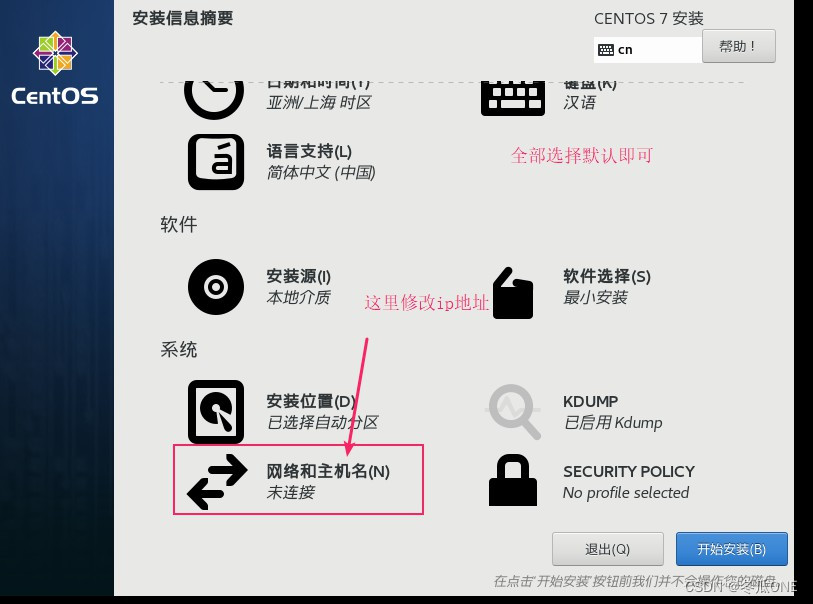
注意:这里面的配置除了“网络和主机名”不用设置,其它的选默认即可,如果警告点进去确定即可
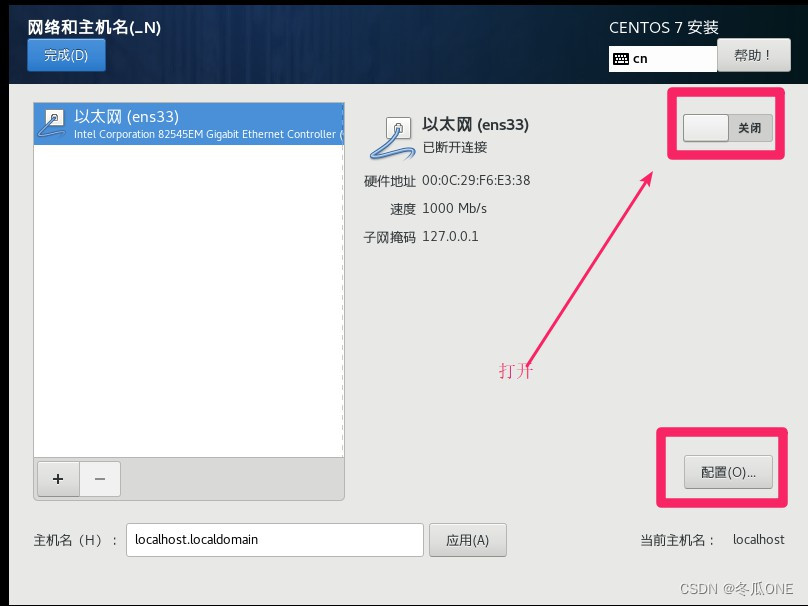
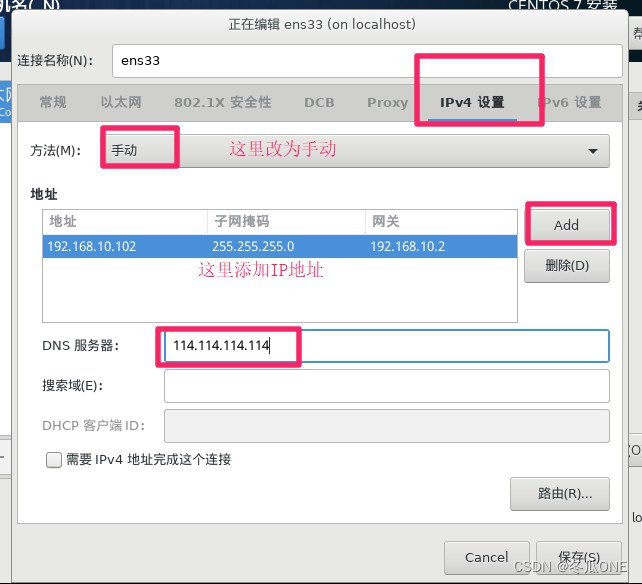
注意:这里是设置ip地址为静态ip地址一定要设置,三台虚拟机的IP地址不可一样
注意:这里是设置主机名的一定要设置
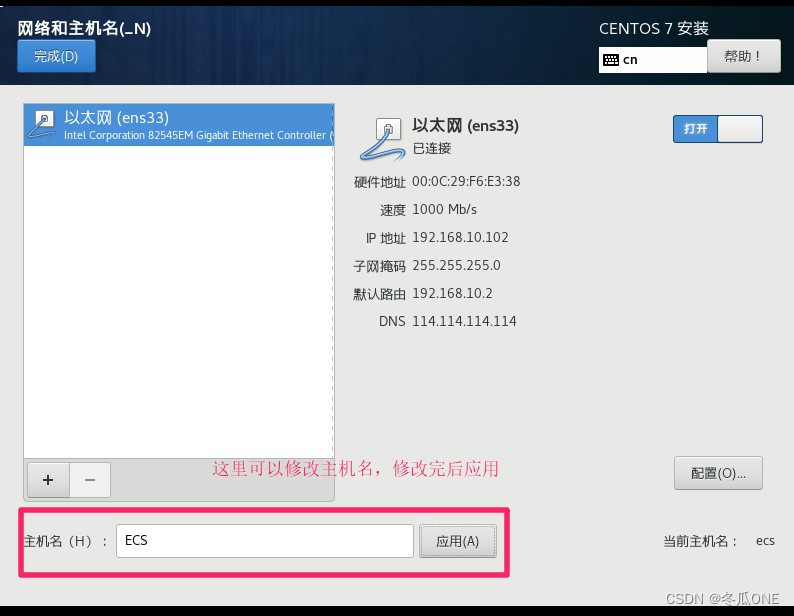

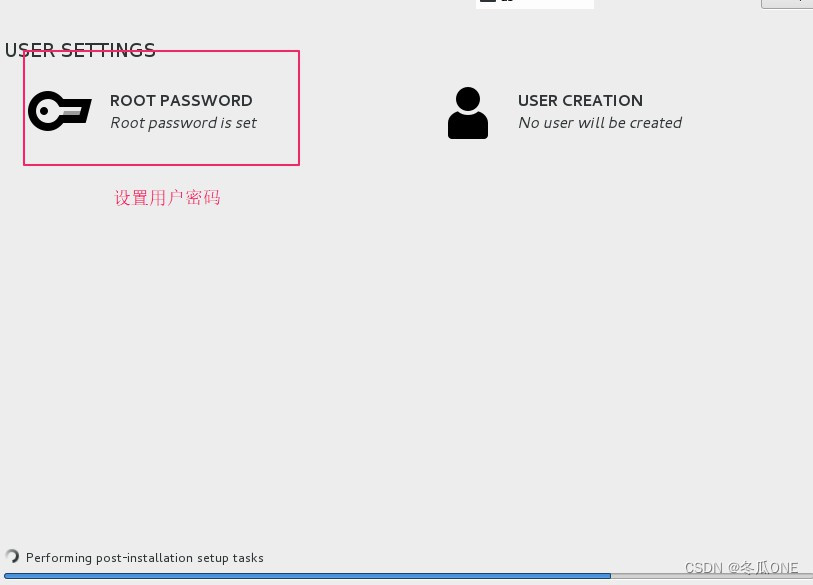
等待安装完毕后便可启动虚拟机。然后分别在配置另外两个虚拟机。配置完毕如下
使用远程连接软件连接虚拟机
我使用的SecureCRT软件连接的虚拟机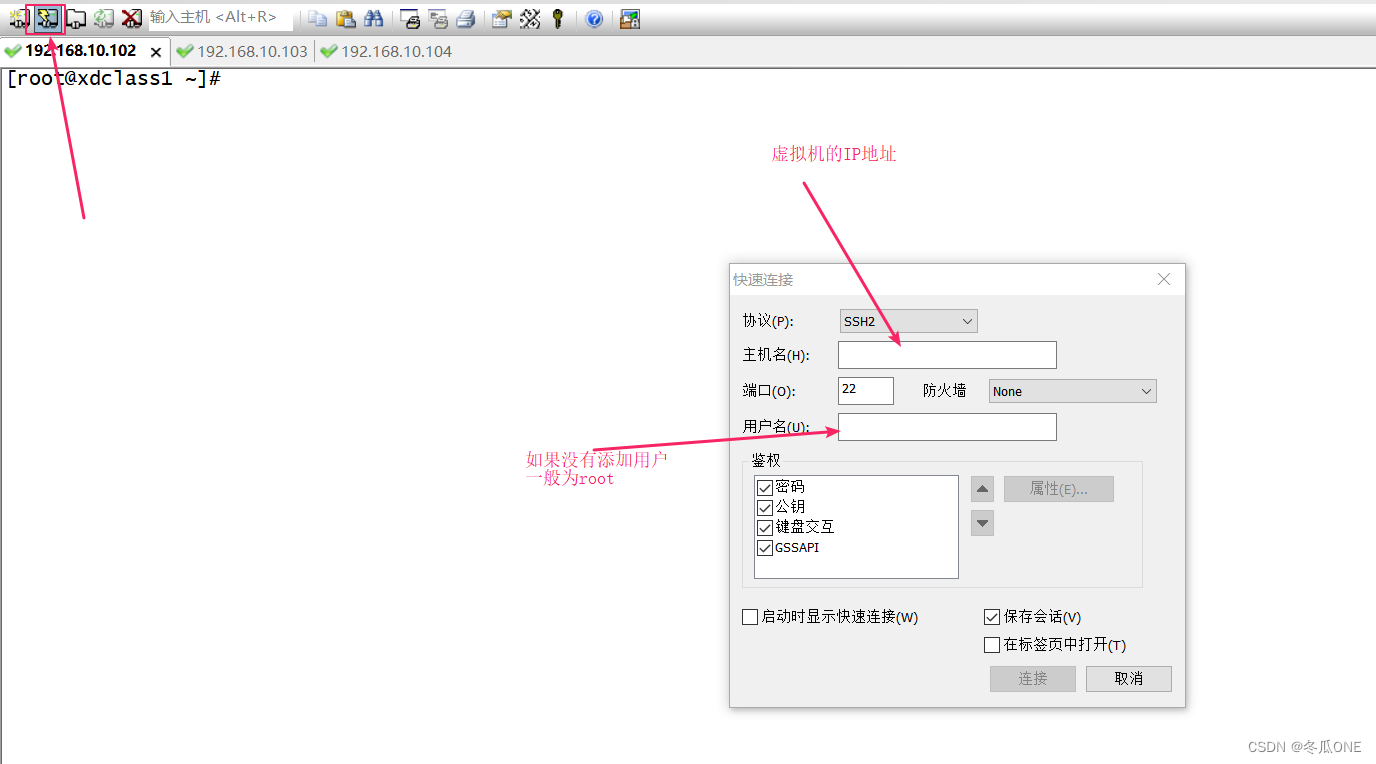
连接成功

配置ssh免密登录
Hadoop集群之间各个节点之间需要通信,需要配置免密登录
在xdclass1上操作:
1,进入.ssh目录:cd /root/.ssh
生成秘钥: ssh-keygen -t rsa 三次回车即可 (另外两个节点进行同样的操作)
查看.ssh下生成的文件,生成了一个公钥文件id_rsa和一个私钥文件id_rsa.pub
2,命令ssh-copy-id xdclass2把xdclass1的公钥给xdclass2,输入1次密码后续即可进行免密登录;然后测试是否可以免密登录
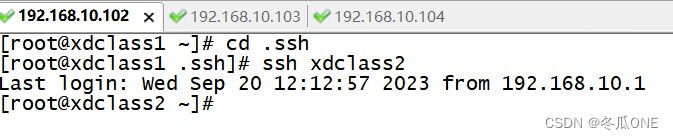
然后exit退出xdclass2
xdclass1对xdclass3同理;xdclass2对xdclass1,xdclass2和xdclass3同理。
JDK环境的安装配置
将jdk安装包上传到虚拟机中并重命名
cd /usr/local/ //将jdk长传到此目录
tar -zxvf jdk-8u162-linux-x64.tar.gz //解压jdk
mv jdk1.8.0_162 jdk1.8 //对jdk重命名
cd /usr/local/ //查看jdk
配置Java环境
vi /etc/profile
添加一下内容,注意路径
export JAVA_HOME=/usr/local/jdk1.8 #这个路径要改,其余不需要改
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
export PATH=/usr/local/apache/bin:/usr/local/jdk1.8/bin:/usr/local/jdk1.8/jre/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin点击i进入输入模式,在最后面添加,java路径是之前安装的路径,编辑完成,按键盘上的"esc“退出编辑模式,然后输入”:wq" 保存并退出
编辑保存好后
source /etc/profile //重启使/etc/profile文件生效jdk的环境验证
java -version
Hadoop环境配置
将Hadoop安装包上传到/opt/module目录
cd /opt/module
tar -zxvf hadoop-2.7.7.tar.gz //hadoop压缩包已在此目录下才可以执行,解压到/opt/module目录
mv hadoop-2.7.7.tar.gz hadoop //重命名,在/opt/module目录下执行配置Hadoop系统环境变量
vi /etc/profile
添加内容如下:
export HADOOP_HOME=/opt/module/hadoop-2.7.4 //这是Hadoop安装路径
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbinsource /etc/profile //重启文件
hadoop version //查看是否安装好
hadoop集群主要配置文件

配置文件地址
这些配置文件全部都在Hadoop文件下的etc目录中。我的是在
/opt/module/hadoop-2.7.4/etc/hadoop/etc/
下面所有修改文件的操作都是在此目录下执行的:例如:“vi 配置文件名”
修改hadoop-env.sh文件
vi hadoop-env.sh
具体操作步骤
> cd /opt/module/hadoop-2.7.4/etc/hadoop/etc/ //在安装路径中找到hadoop下etc文件夹中的hadoop
> vi hadoop-env.sh添加如下内容:
export JAVA_HOME=/usr/local/jdk1.8 //jdk的安装路径修改core-site.xml文件
vi core-site.xml
添加内容如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://xdclass1:9000</value> //修改成自己的主机名
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.4/tmp</value> //修改成自己的Hadoop路径
</property>
</configuration>修改hdfs-site.xml文件
vi hdfs-site.xml
添加的内容如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>xdclass2:50090</value> #这里改为第二台虚拟机的名字,我的是xdclass2
</property>
</configuration>修改mapred-site.xml文件
这里我们首先需要重命名为mapred-site.xml
> mv mapred-site.xml.template mapred-site.xml
然后再对文件进行修改
vi mapred-site.xml
添加的内容如下:
<configuration>
<!--指定MapReduce运行时的框架,这里指定在Yarn上,默认时local-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>修改yarn-site.xml文件
vi yarn-site.xml
添加的内容如下:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>xdclass1</value> #这里写主机名,其他内容不变
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>修改/etc/hosts文件
vi /etc/hosts
添加的内容如下(IP地址+主机名):
192.168.10.102 xdclass1
192.168.10.102 xdclass2
192.168.10.104 xdclass3修改slaves文件
vi slaves
打开该配置文件,先删除里面的内容(默认localhost),然后配置如下内容:
xdclass1
xdclass2
xdclass3 (内容为自己三台虚拟机的主机名)将集群主节点的配置文件分发到其他子节点
> scp /etc/profile xdclass2:/etc/profile
> scp /etc/profile xdclass3:/etc/profile //将配置文件发给其他主机
> scp -r /usr/local/ xdclass2:/usr/ //将jdk发给其他主机
> scp -r /usr/local/ xdclass3:/usr/
> scp -r /opt/ xdclass2:/ //将Hadoop发给其他主机
> scp -r /opt/ xdclass3:/在其他主机上执行
> source /etc/profile //使分发的文件生效格式化文件系统(在主节点上执行。即xdclass这台虚拟机上执行)
> hdfs namenode -format(格式化文件系统这个操作只能在第一次启动hdfs集群时来操作,后面不能再进行格式化)
启动集群
注意:要关闭三个虚拟机的防火墙,三台都要执行
firewall-cmd --state //查看是否关闭防护墙
systemctl stop firewalld.service //关闭
start-dfs.sh或stop-dfs.sh启动或关闭所有HDFS服务进程start-yarn.sh或stop-yarn.sh启动或关闭所有YARN服务进程start-all.sh或stop-all.sh指令,直接启动或关闭整个Hadoop集群服务
第一台主机xdclass上显示的五个进程,jps查看
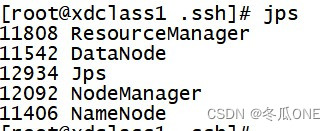
第二台虚拟机xdclass2上显示的四个进程,jps查看

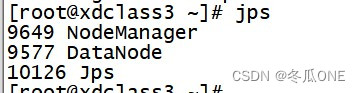
第三台虚拟机xdclass3上显示的三个进程,jps查看
Hadoop集群测试
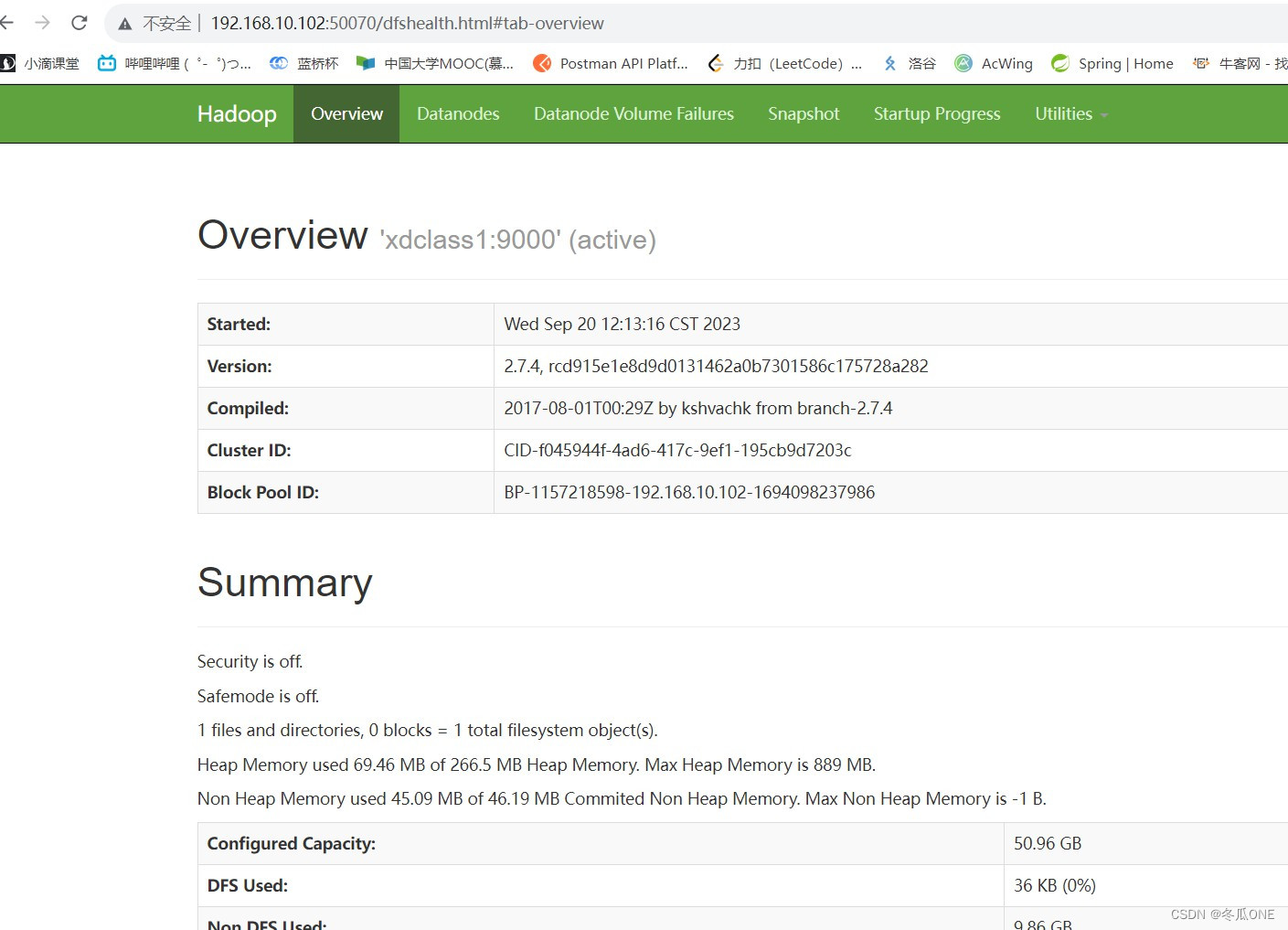
访问50070端口
在浏览器访问xdclass1:50070或者192.168.10.102:50070(格式为:主机名或IP地址+端口号)查看HDFS
访问8088端口
去浏览器搜索xdclass1:8088或者192.168.10.102:8088(格式为:主机名或IP地址+端口号)可查看YARN集群管理页面

到这里Hadoop集群配置完成!!!
搭建过程中用到的资源
jdk1.8安装包
链接:https://pan.baidu.com/s/1UzvRjc6oMjLvE2awoUOr1g
提取码:zshn
SecureCRT安装包
链接:https://pan.baidu.com/s/1Tm2dE1UaOu1V7VPWeoAl8A
提取码:zshn
Hadoop2.7安装包
链接:https://pan.baidu.com/s/1NjvtPPxOWFuBpHDVNTFmig
提取码:zshn
CentOS7镜像文件
链接:https://pan.baidu.com/s/1gLyQgQl5iTzr6EG3eBPrew
提取码:zshn















 2404
2404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









