






题目背景
考虑到安全指数是一个较大范围内的整数、小菜很可能搞不清楚自己是否真的安全,顿顿决定设置一个阈值,以便将安全指数转化为一个具体的预测结果——“会挂科”或“不会挂科”。因为安全指数越高表明小菜同学挂科的可能性越低,所以当时,顿顿会预测小菜这学期很安全、不会挂科;反之若,顿顿就会劝诫小菜:“你期末要挂科了,勿谓言之不预也。”那么这个阈值该如何设定呢?顿顿准备从过往中寻找答案。
题目描述
具体来说,顿顿评估了n位同学上学期的安全指数,其中第 i 位同学的安全指数为 yi,是一个[0,1e8] 范围内的整数;同时,该同学上学期的挂科情况记作result ,其中 0 表示挂科,1 表示未挂科。等价地表述为如下规则:
1.最佳阈值仅在yi中选取,即与某位同学的安全指数相同;
2.按照该阈值对这m位同学上学期的挂科情况进行预测,预测正确的次数最多(即准确率最高);
3.多个阈值均可以达到最高准确率时,选取其中最大的。
输入格式
从标准输入读入数据。输入的第一行包含一个正整数m。接下来输入m行,其中第i行包括用空格分隔的两个整数 yi 和 result,含义如上文所述。
输出格式
输出到标准输出。输出一个整数,表示最佳阈值。
分析:
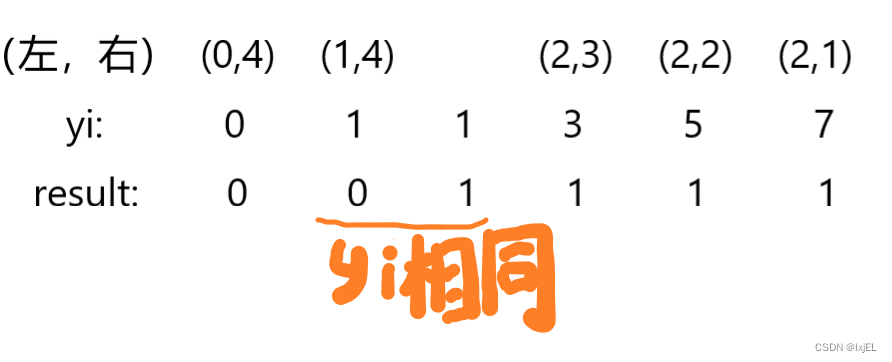
首先把题目数据按照从小到大排好序,根据题意可以看出来,预测正确的次数也就是每一个yi左边的0的个数加上自身以及自身右边1的个数的总和sum,要求最终就是求最大sum所对应的最大yi。但是有一点需要注意的是:当出现重复的yi的时候只记录第一次的数据,因为只有它第一次出现的时候,它前面的0才是它预测正确的0,它后面的1是它预测正确的1,也就是类似于赋值一样,对于下图中的第二个1而言,其前已经出现的yi = 1,result = 0相当于是既定事实了,后面出现的 1,1就和前面相违背为了,因此不计算重复的yi对应的sum值。
代码如下:
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 100010;
typedef pair<int,int> PII;
PII all[N];
int sum0[N],sum1[N];
int main()
{
int n;
scanf("%d",&n);
for(int i = 1;i <= n;i++)
scanf("%d%d",&all[i].first,&all[i].second);
sort(all+1,all+n+1);
for(int i = 1;i <= n;i++)
{
sum0[i] = sum0[i-1];
sum1[i] = sum1[i-1];
if(!all[i].second)
sum0[i] += 1;
else
sum1[i] += 1;
}
int ans = 0;
int max_yi;
for(int i = 1;i <= n;i++)
{
if(all[i].first == all[i-1].first)
continue;
int t = sum0[i-1]+sum1[n]-sum1[i-1];
if(t >= ans)
{
ans = t;
max_yi = all[i].first;
}
}
printf("%d",max_yi);
return 0;
}















 92
92











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









