






OneRel: Joint Entity and Relation Extraction with One Module in One Step
联合抽取->细粒度的三重分类问题
1.基于评分的分类器模型
- 评估token和对应关系是否属于事实三元组
- 解决的问题:一个entity可能由多个token构成
2.基于特定关系的角标记策略
- 保证了一个简单而有效的解码过程
- 运行过程:对于token对 ( w i , w j ) (w_i, w_j) (wi,wj)和预定义关系 r k r_k rk,基于评分的分类器衡量组合 ( w i , r k , w j ) (w_i, r_k, w_j) (wi,rk,wj)的正确性,如果有效,将为其分配一个有意义的标记,否则将为其分配“-”
Introduction:
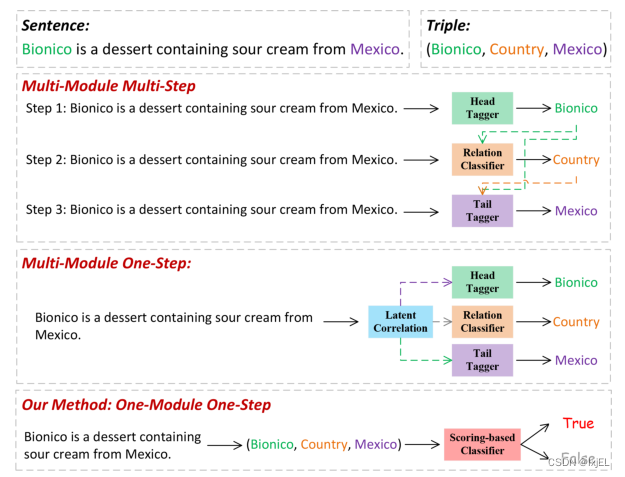
1.多模块多步 m u l t i − m o d u l e multi-module multi−module m u l t i − s t e p multi-step multi−step
利用级联分类或文本生成框架中的不同模块获取实体并且逐步建立关系。
使用不同的模块和相互关联的处理步骤来串行的提取实体和关系:
(1)先识别句子中的所有实体,然后在每个实体对之间进行关系分类;
(2)先检测句子所表达的关系,然后预测头尾实体;
(3)首先区分头实体,然后通过序列标记或问答 推测出对应的关系和尾实体。
2.多模块一步 m u l t i − m o d u l e multi-module multi−module o n e − s t e p one-step one−step
分别识别实体和关系,然后根据他们的潜在相关性将它们组合成三元组。
并行抽取实体和关系,然后组合成三元组:
(1)将实体识别和关系分类视为填表问题,其中每个条目代表两个单独单词之间的相互作用;
(2)将联合抽取任务表述为一个集合预测问题,避免了考虑多个三元组的预测顺序。
3. o n e r e l onerel onerel
放入三元组,判断其正确性。
好处:
(1)将头部实体、关系实体和尾部实体同时输入到一个分类模块中,从而可以完全捕获三重元素之间的依赖关系,从而减少冗余信息。
(2)只采用一步分类,可以有效地避免级联误差。
(3)一模块一步的简单架构,使网络直观,易于训练。
编码:
输入句子,OneRel输出一个三维矩阵,每个条目对应于
(
w
i
,
r
k
,
w
j
)
(w_i,r_k,w_j)
(wi,rk,wj)的分类结果。
引入Rel-Spec horns tagging(基于特定关系的角标记策略relation-specific horns tagging)来确定头实体和尾实体的边界标记。
Method:
一个句子
S
S
S = {
w
1
,
w
2
,
.
.
.
,
w
L
w_1,w_2,...,w_L
w1,w2,...,wL},有L个token和K个预定义关系
R
R
R = {
r
1
,
r
2
,
.
.
.
,
r
K
r_1,r_2,...,r_K
r1,r2,...,rK}
联合实体和关系提取的目的是识别S中所有可能的三元组![![[Pasted image 20230704102131.png]]](https://img-blog.csdnimg.cn/e2f0922bc2fc4c24815fd00158b5c54f.png)
,N为三元组的个数,
h
i
,
t
i
h_i,t_i
hi,ti为多个token组成的头尾实体,
e
n
t
i
t
y
.
s
p
a
n
=
w
p
:
q
entity.span = w_{p:q}
entity.span=wp:q,
w
p
:
q
w_{p:q}
wp:q表示由
w
p
w_p
wp持续至
w
q
w_q
wq。
eg.
"《邪少兵王》是冰火未央写的网络小说连载于旗峰天下"有24个token("《"、"邪"、"少"、"兵"、"王"、"》"、"是"、"冰"、"火"、"未"、"央"、"写"、"的"、"网"、"络"、"小"、"说"、"连"、"载"、"于"、"旗"、"峰"、"天"、"下")2个entity("邪少兵王"、"冰火未央")和1个预定义关系("作者")
{
"id": 0,
"text": "《邪少兵王》是冰火未央写的网络小说连载于旗峰天下",
"relation_list":
[{
"subject": "邪少兵王",
"object": "冰火未央",
"predicate": "作者"
}],
"entity_list":
[
{"text": "邪少兵王",
"type": "图书作品"}
{"text": "冰火未央",
"type": "人物"},
]
}
Relation Specific Horns Tagging
(为了便于解释,这里用给定的关系来说明子矩阵,因此,矩阵M退化成二维(不然会是三维M矩阵,
M
L
∗
K
∗
L
M_{L*K*L}
ML∗K∗L))

Tagging
使用"BIE"(Begin,Inside,End)符号指示token在entity中的位置信息,"HB"表示头实体开始的token,“HE"表示头实体结束的token,“HI"表示在头实体之中,TB"表示尾实体开始的token,“TE"表示尾实体结束的token,“TI"表示在尾实体之中。
因为可以通过检测实体的边界token来得到实体,因此论文只采用了四种类型的标签:
(1)“HB-TB”
(2)“HB-TE”
(3)“HE-TE”
(4)”-”:除上述三种情况外,其余的都标记为”-”。
这种标记方法可以自然地解决具有重叠模式的复杂场景,因为:
- 对于头尾实体的标记是分开进行的;
- 对于不同的关系,其标记也是分别进行的。
Decoding
实体的标记都是成对进行的,对于每个关系:
头实体的跨度为从"HB-TB"到"HE-TE",
尾实体的跨度为从"HB-TE"到"HE-TE"。
Scoring-based Classifier
(1)对于一个输入的句子,使用预训练的Bert作为句子编码器来得到每个token的二维标记嵌入
e
i
e_i
ei,它是对相应的标记嵌入和位置嵌入的总和。
{
e
1
,
e
2
,
.
.
.
,
e
L
e_1,e_2,...,e_L
e1,e2,...,eL} = BERT({
x
1
,
x
2
,
.
.
.
,
x
L
x_1,x_2,...,x_L
x1,x2,...,xL})(
x
i
x_i
xi为token的输入表示)
(2)枚举所有可能的(
e
i
,
r
k
,
e
j
e_i,r_k,e_j
ei,rk,ej)(
r
k
r_k
rk是随机初始化的关系)组合,并设计一个分类器来分配高置信度的标签。
直观地说,也就是可以使用一个输入为(
e
i
,
r
k
,
e
j
e_i, r_k, e_j
ei,rk,ej)的简单分类网络来实现这个目标。
但是其中存在两个缺陷:
- 简单的分类器不仅无法充分探索实体和关系之间的相互作用,而且难以对三元组固有的结构信息进行建模;
- 使用
(
e
i
,
r
k
,
e
j
)
(e_i, r_k, e_j)
(ei,rk,ej)作为输入意味着模型需要执行至少L × K × L的计算来对所有组合进行分类,这在时间上是不可接受的。
(3)借鉴HOLE的思想 - 得分函数定义:
![![[Pasted image 20230704144933.png]]](https://img-blog.csdnimg.cn/1f45302a1b3a42ebbe6b41c9cc290326.png)
, h , t h,t h,t分别为头尾实体的表示, ★表示circular correlation(循环相关),用于挖掘两个实体之间的潜在依赖关系。(当两个循环变量之间存在关联时,我们可以使用循环相关性来衡量它们之间的关系。) - 这里定义★为a non-linear concatenation projection(非线性串联投影),
![![[Pasted image 20230704145419.png]]](https://img-blog.csdnimg.cn/a45c0ea87bdb4c28b5e5dfde5a154d9e.png)
其中
![![[Pasted image 20230704150112.png]]](https://img-blog.csdnimg.cn/0f08a8916d63413b8df54005d1d2cd23.png)
b为可训练权值和偏差, d e d_e de为实体对表示的维数,";"为串联操作,φ(·)为RELU激活函数。
好处: - 分类器的评分功能可以与句子编码器的输出无缝连接;
- 可以通过矩阵W自适应学习实体特征到实体对表示的映射函数;
- 两个实体之间的连接是不可交换的,即
[
h
;
t
]
!
=
[
t
;
h
]
[h;t]!=[t;h]
[h;t]!=[t;h]。
(4)接下来使用所有关系表示
![![[Pasted image 20230704151402.png]]](https://img-blog.csdnimg.cn/e32fbfcc63ba4fbbb3e842d2986e9ff5.png)
同时计算一个token-pair ( w i , r k , w j ) (w_i,r_k,w_j) (wi,rk,wj)的显著性
![![[Pasted image 20230704151526.png]]](https://img-blog.csdnimg.cn/530ebbeaae6a4991acc7e4d62c157fbc.png)
其中4为分类标签的数量。
(5)因此最终的得分函数为:
![![[Pasted image 20230704151922.png]]](https://img-blog.csdnimg.cn/23882321a0454931ae6facf567bef322.png)
v为分数向量,drop(·)为防止过拟合的dropout策略。
(6)最终将 ( w i , r k , w j ) (w_i,r_k,w_j) (wi,rk,wj)的得分向量输入softmax函数来预测相应的标签。
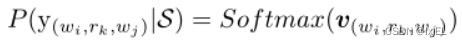
(7)目标函数定义为
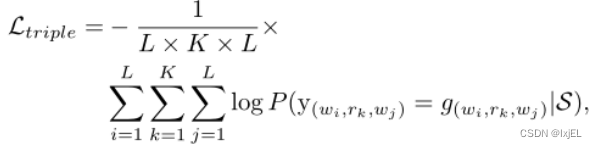
g
(
w
i
,
r
k
,
w
j
)
g_{(w_i,r_k,w_j)}
g(wi,rk,wj)为标注的标签。















 2488
2488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









