







论文题目:ReactXT: Understanding Molecular “Reaction-ship” via Reaction-Contextualized Molecule-Text Pretraining
Abstract
反应-情境化分子-文本预训练(ReactXT)是一种新兴的研究方向,旨在通过文本界面和文本知识来促进与分子相关的任务。与单个分子研究不同,反应-文本建模有助于新材料和药物的合成。然而,以往的研究大多忽视了反应-文本建模,主要集中在建模单个分子-文本对或学习没有上下文的化学反应上。此外,反应-文本建模的一个关键任务——实验过程预测,由于缺乏开源数据集而较少被探索。该任务旨在预测进行化学实验的逐步操作,对于自动化化学合成至关重要。
为了解决上述挑战,我们提出了一种新的预训练方法ReactXT,专注于反应-文本建模,并推出了一个新的数据集OpenExp,用于实验过程预测。具体而言,ReactXT具有三种输入上下文类型,以逐步预训练语言模型(LM)。每种输入上下文对应一个预训练任务,以提高对反应或单个分子的文本理解。ReactXT在实验过程预测和分子描述生成方面表现出一致的改进,并在逆合成任务中提供了竞争力的结果。code。
1 Introduction
多模态大型语言模型(LMs)最近吸引了广泛的研究关注。值得注意的是,在视觉-语言领域,用视觉编码器增强的LMs在视觉问答和图像描述方面取得了令人钦佩的成果。受到这些成功的启发,分子-文本建模(molecule-text modeling,MTM)成为了一个新兴的研究领域,旨在为分子任务构建自然语言接口,包括文本引导的分子生成、分子描述和分子-文本检索。
在分子-文本建模(MTM)工作的基础上,我们研究了反应-文本建模(reaction-text modeling,RTM),旨在提高语言模型在与反应相关任务上的性能。化学反应涉及反应物到产物之间的转化过程,这对推动药物发现和材料科学至关重要。在回顾先前的工作时,我们发现RTM在学习模式和评估基准方面存在关键研究空白。
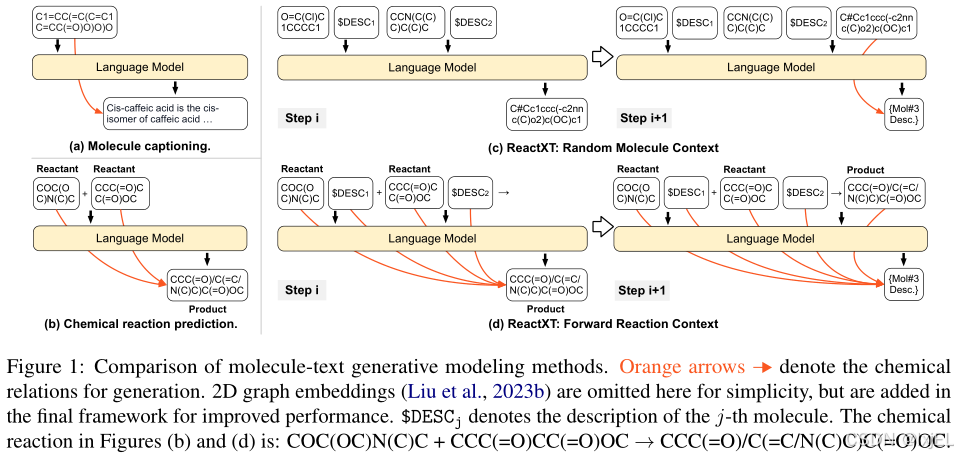
- 学习模式(Learning Paradigm):
在先前的研究中,大多数工作要么专注于生成单一分子的文本描述(Fig 1a),要么将语言模型(LMs)应用于化学反应预测,但没有在上下文中包含分子/反应的文本描述(Fig 1b)。这些方法忽视了文本描述中潜在的知识对模型性能的提升。先驱性的工作在提示Chat-GPT时包括了分子作用和实验条件的标签,但收到限制提示词prompt的限制,因此表现不佳。 - 评估基准(Evaluation Benchmark):一个用于实验步骤预测的开源数据集明显缺失。正如Fig 2所示,实验步骤预测旨在通过解释化学反应来推断实验执行的逐步行动,这对于自动化化学合成过程具有重要价值。这项任务与我们对反应-文本建模(RTM)的关注非常吻合,需要理解化学反应并通过文本界面来表达实验步骤。不幸的是,公共数据集的缺失阻碍了这一领域的进一步研究和开发。
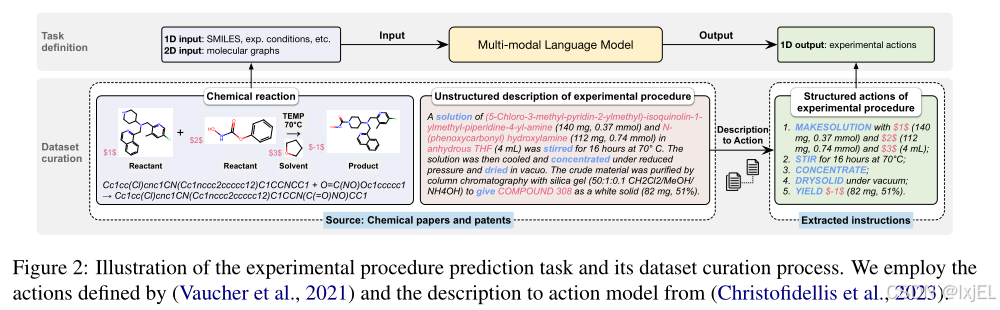
为了解决这些研究空白,我们提出了反应语境化的分子-文本预训练(Reaction-Contextualized Molecule-Text Pretraining,ReactXT),旨在提高对化学反应和分子的文本理解能力。此外,我们构建了一个用于实验步骤预测的开源数据集(OpenExp),作为评估反应-文本建模(RTM)方法的关键基准。以下是它们的详细信息:
ReactXT:
ReactXT 旨在通过引入三种类型的输入上下文来改进反应-文本建模(RTM)的学习范式,每种上下文都对应一个预训练任务,以提高语言模型(LMs)对化学反应或单个分子的理解。如Fig 1d所示,正向反应上下文被设计来学习同一反应中涉及的分子之间的化学联系。这些联系基于化学反应原理,如守恒定律。在这个分子相互作用的基础上,我们假设理解同一反应中的其他分子及其描述可以帮助预测当前分子及其文本描述。ReactXT鼓励LMs利用这些分子间关系来提高它们在反应中生成分子描述的能力,进而加深它们对化学反应原理的理解。此外,引入了反向反应上下文以支持逆合成任务(见第3.1节)。最后,如Fig 1c所示,ReactXT包括随机分子上下文,培养LMs对单个分子在反应之外的理解。
OpenExp:
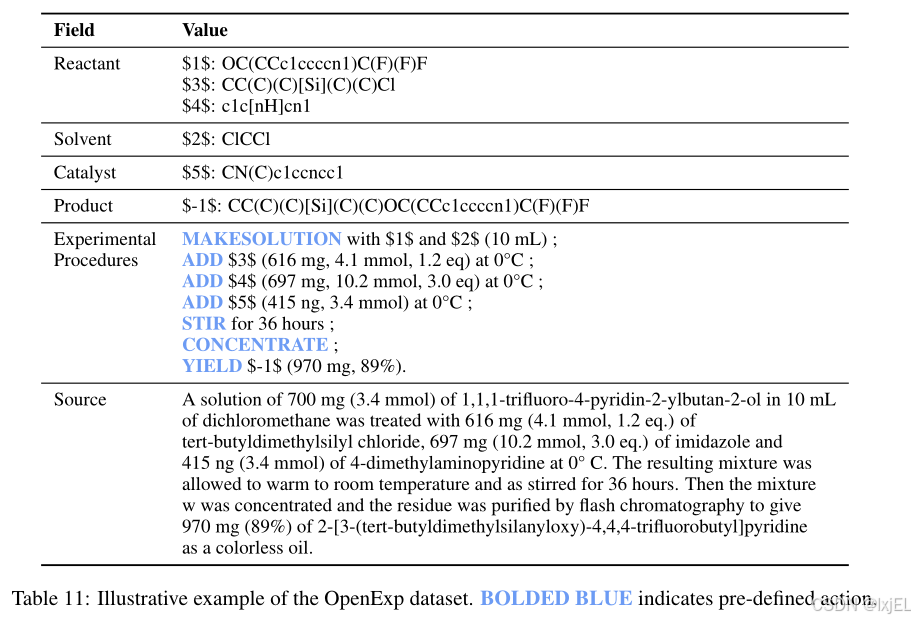
OpenExp 数据集包含了274,439对化学反应及其相应的逐步实验操作指令。该数据集是从 USPTO-Applications和 ORD数据库中汇编而成,并将根据 CC-BY-SA 许可证发布。为了确保数据质量,我们进行了仔细的数据预处理。此外,我们邀请了专家对数据集质量进行评估。在随机选择的100个样本中,有50个样本无需任何人工干预就可以直接使用,而90个样本仅需进行轻微修改即可进行实验操作(Fig 5)。
我们的贡献可以总结如下:
- 我们提出了ReactXT,这是一种结合了三种类型的输入上下文来逐步预训练语言模型(LM)的方法。这些上下文专门设计用来增强LM对化学反应和单个分子的理解。
- 我们策划了一个开源的实验步骤预测数据集OpenExp,这是自动化化学合成研究的新基准。
- ReactXT在OpenExp数据集上实现了实验步骤预测的最新性能,突显了其卓越的反应-文本建模(RTM)能力。在PubChem324k数据集上,它还通过3.2%的改进超越了分子描述的基线。ReactXT在逆合成方面也有竞争力的表现,我们正在对其进行优化,以超越当前的最新方法。
2 Related Works
Molecule-Text Modeling (MTM)
MTM旨在联合建模分子和文本,以解决与文本相关的分子任务。分子可以通过一维序列的SMILES和SELFIES来表示,这使得在混合的文本和分子的一维序列上预训练统一的语言模型(LMs)成为可能。此外,这些LMs可以通过指令调整与人的偏好对齐。与一维LMs平行,还研究了多模态方法,使用图神经网络(GNNs)来编码二维分子图。值得注意的是,CLIP-style的跨模态对比学习和BLIP2-style的跨模态投影都被研究用于促进分子-文本检索,以及分子到文本的生成。最近,还提出了MolTC,使用链式思维来建模分子相互作用。然而,先前的工作主要关注单个分子而不是化学反应。为了弥补这一差距,ReactXT探索了反应-文本建模,通过使用文本接口和文本知识,促进与反应相关的任务。
Experimental Procedure Prediction
合成复杂化合物需要详细规划合成路径和中间步骤,这个过程既劳动密集又复杂。机器学习(ML)可以通过预测实验步骤来潜在地自动化这个过程。先前的工作已经探索了通过阅读化学反应来预测反应条件(例如,催化剂和溶剂)和合成步骤。根据已知的实验步骤,ML也被探索用于赋能化学实验室机器人和自动化实验室流水线。值得注意的是,工具增强的GPT4被探索用于规划和执行已知的化学实验。与先前的工作不同,我们的OpenExp数据集是第一个旨在促进未见过的化学实验的程序预测的开源数据集。
Retrosynthesis and Chemical Reaction Prediction
给定一个化学反应,逆合成是从产物预测反应物,而反应预测是从反应物预测产物。它们可以被形式化为由SMILES字符串表示的序列到序列的转换。同时,2D分子图也被探索用于反应预测:基于选择的方法侧重于区分最合适的反应模板;基于图的生成模型直接合成目标分子。然而,上述方法仅利用反应而不使用文本。值得注意的是,两项先驱工作应用ChatGPT进行反应预测,它们的性能受到提示词的限制。
3 ReactXT: Reaction-Contextualized Molecule-Text Pretraining
ReactXT由两个关键组成部分构成:
1)创建输入上下文以逐步预训练语言模型(LM)的方法
2)反应上下文的平衡采样策略
我们首先介绍我们的多模态LM主干,然后详细阐述ReactXT的两个组成部分。
Multi-Modal Language Model Backbone
分子可以通过一维的SMILES序列或二维的分子图来表示。我们采用MolCA作为我们的主要语言模型骨架,以有效地利用一维和二维的分子模态。具体来说,MolCA结合了一个图神经网络(GNN)编码器,用于编码二维分子图。这个GNN的输出随后通过一个跨模态投影器映射到语言模型的输入空间,从而使得语言模型能够感知二维分子图。跨模态投影器和GNN都已经通过分子-文本对齐进行了预训练。MolCA在微调用于分子命名和IUPAC名称预测时显示出了很好地的性能。
3.1 Creating Input Contexts

解决语言模型(LMs)的核心挑战关键在于精心选择输入数据。如Table 1所示,ReactXT纳入了三种类型的输入上下文来逐步预训练LMs:正向反应上下文、反向反应上下文和随机分子上下文。这些上下文专门设计用于基于文本的化学反应和单个分子的理解:
- Forward Reaction Context
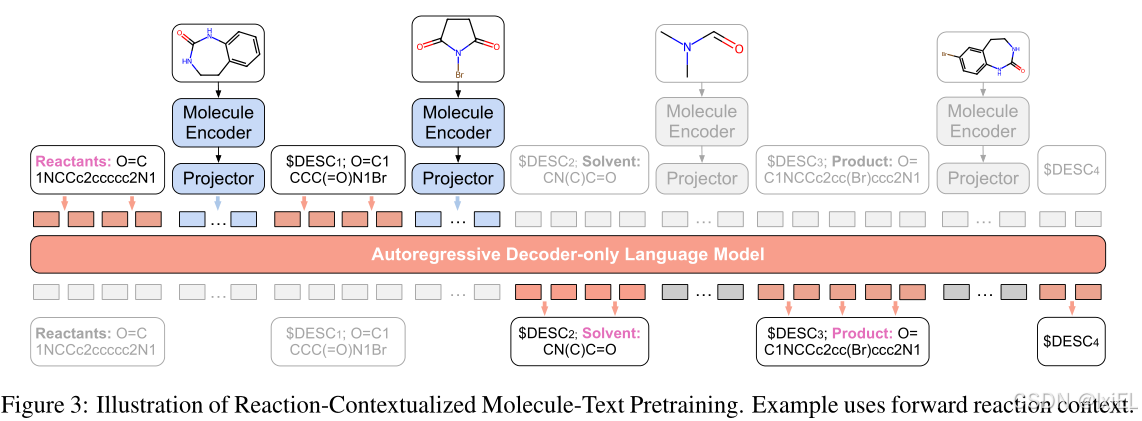
如Fig 3所示,正向反应上下文根据分子在反应中的角色——反应物、催化剂、溶剂和产物——对分子进行标记,并按照特定的顺序排列它们。需要注意的是,并不是每个反应都有催化剂或溶剂。对于每个分子,我们在其SMILES后附加其二维分子图嵌入,以增强语言模型对分子结构的理解;并在二维分子图嵌入后附加分子描述,以将分子与文本对齐。
- Backward Reaction Context
类似于正向反应上下文,但是分子角色的顺序是相反的,这种上下文旨在对抗语言模型(LMs)的“反转诅咒”:在“A is B”上训练的LMs不能泛化到“B is A”。反转泛化至关重要,因为下游应用包括反向逆合成。 - Random Molecule Context
引入这种上下文是为了确保语言模型(LMs)保持在化学反应之外描述单个分子的能力。
Context Length
在每个输入上下文中,我们使用 k k k个分子及其描述,其中 k k k是一个超参数。对于超过 k k k个分子的反应,我们应用加权分子采样,详见3.2节。
Molecule Description
输入上下文的一个关键组成部分是分子描述,其质量和全面性对于分子-文本对齐至关重要。我们从多个来源收集分子描述和属性,涵盖三种类型的内容:
- Molecule Patent Abstracts
我们从PubChem的专利中获取专利摘要。这些摘要通常描述分子结构、性质或应用,但如果分子只是被顺带提及而不是核心主题,也可能包含不相关信息。尽管存在噪声,专利摘要对于反应-文本建模(RTM)是不可或缺的:它们涵盖了我们所使用的反应数据库中约95%的分子。相比之下,从PubChem的描述部分衍生的分子-文本数据集只涵盖了这些分子的约1%。 - Computed and Experimental Properties

我们从PubChem获取这些数值属性,旨在通过预测学习增强对分子结构的理解。某些属性对于反应预测也很有帮助。例如,了解溶解度有助于在制备溶液时确定浓度;了解熔点和沸点有助于识别在给定温度下的物态。Table 2展示了一个专利摘要及其计算/实验属性的示例。Table 14包含我们收集的分子属性的详细统计信息。
- PubChem Descriptions
接着,我们从PubChem获取分子描述。由于它们对于反应数据库中的分子的覆盖率有限(大约1%),我们专门将它们用于随机分子上下文。
Autoregressive Language Modeling for Interleaved Molecule-Text Sequences(自回归语言建模用于交错的分子-文本序列)
鉴于上述交错的分子和文本的输入上下文,我们应用语言建模损失来逐步预训练语言模型(LM)、分子编码器和投影器。我们只计算文本标记的损失,不包括二维分子图嵌入。
3.2 Balanced Sampling of Reaction Contexts
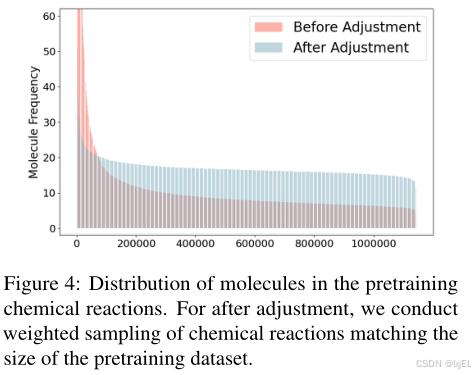
Fig 4揭示了化学反应中分子分布的偏斜情况(红色条形),一小部分分子出现的频率远高于其他分子。为了解决这种不平衡,我们开发了一种采样策略,以促进分子在反应中出现的公平性。这种方法通过调整:
1)每个反应
r
r
r的采样权重
W
(
r
)
W(r)
W(r)
2)在选定反应
r
r
r中每个分子
m
m
m的采样权重
W
(
m
∣
r
)
W(m|r)
W(m∣r)
来减少常见分子的主导地位,具体的调整基于以下公式:
W
(
r
)
=
∑
m
∈
r
1
C
o
u
n
t
(
m
)
∑
r
′
∈
R
∑
m
∈
r
1
C
o
u
n
t
(
m
)
(
1
)
W(r)=\frac{ {\textstyle \sum_{m\in r}\frac{1}{Count(m) }}}{ {\textstyle \sum_{r^{'}\in \mathcal{R}}} {\textstyle \sum_{m \in r}\frac{1}{Count(m)} } } (1)
W(r)=∑r′∈R∑m∈rCount(m)1∑m∈rCount(m)1(1)
W
(
m
∣
r
)
=
1
C
o
u
n
t
(
m
)
∑
m
′
∈
r
1
C
o
u
n
t
(
m
′
)
(
2
)
W(m|r)=\frac{ \frac{1}{Count(m)} }{ {\textstyle \sum_{m^{'} \in r}\frac{1}{Count(m^{'})} } }(2)
W(m∣r)=∑m′∈rCount(m′)1Count(m)1(2)
式中,
R
\mathcal{R}
R为化学反应数据集;
C
o
u
n
t
(
m
)
Count(m)
Count(m)表示分子
m
m
m在
R
\mathcal{R}
R中的计数。
方程(1)将反应的采样权重设置为其分子总出现次数的倒数,倾向于那些含有罕见分子的反应;方程(2)提高了给定反应中更罕见分子的权重。然后,这些权重被应用于加权随机抽样,且不进行替换。图4中的蓝色条形图展示了调整后分子的采样频率,显示出了一个更平坦的分布。实现细节在附录B中。
4 OpenExp: An Open-Source Dataset for Experimental Procedure Prediction
在这里,我们简要介绍了OpenExp的策划过程,细节详见附录A.1。OpenExp来源于USPTO-Applications和ORD的化学反应数据库。如Fig 2所示,这些数据库包括化学反应和相应的非结构化实验步骤描述。为了将这些非结构化描述转换为结构化的动作序列,我们首先运行了paragraph2action模型,然后对其进行预处理。预处理的目的是移除低质量数据、消除重复项,并在反应和实验步骤之间构建分子映射。具体的预处理步骤在Table 3中总结。一个例子展示在Table 11中。
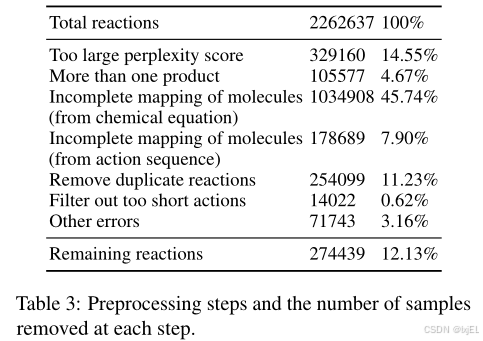
如表4所示,最终的OpenExp数据集包括274k个反应-程序对。它按照8:1:1的比例随机划分为训练集、验证集和测试集。与先前的工作相比,后者因使用商业的Pistachio数据库而为闭源,我们开放了这个数据集以协助未来的研究。
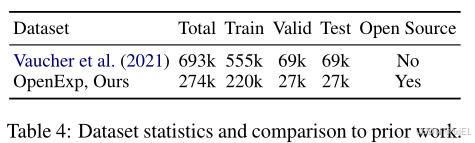
为了对数据集质量进行衡量,我们邀请了两名化学专业的研究生来评估动作序列与它们原始描述之间的对齐程度,评分从1(最低)到5(最高),如图5所示。简而言之,在评估的250个样本中,有126个(≥50%)动作序列最多有1个错误(得分超过4),181个(≥50%)动作序列最多有2个错误(得分超过3)。我们更仔细的检查显示,得分为4的样本中的错误通常是材料/动作名称的拼写错误,或者是数值上的不一致,这并不妨碍整体的执行。详见附录C.3.2。
5 Experiment
我们通过三个下游任务来实证评估ReactXT,包括实验程序预测、分子描述和逆合成。此外,我们还展示了各个独立组件贡献的消融研究。为确保我们实验的意义,我们在附录C.2中包含了统计测试结果。
5.1 Experimental Setting
ReactXT是由MolCA的stage-2检查点初始化的,如果没有特别说明的话。然后,它使用我们提出的方法进行预训练,并对每个下游数据集分别进行微调。上下文长度 k k k设为4。我们在预训练和微调中采用全参数调整。更多细节在附录B中。
ReactXT’s Pretraining Dataset
我们的预训练数据集包括PubChem324k的预训练子集,其中包含298k个分子-文本对,以及来自USPTO-Applications和ORD数据库的111万个化学反应。对于反应中的分子,我们按照3.1节获取了它们的专利摘要和分子属性。为了防止信息泄露,我们从最初的116万反应中排除了出现在下游数据集(即OpenExp、USPTO-50K)的验证集/测试集中的54k个反应。详见附录A.2。
Baselines
我们将ReactXT与科学领域的最新语言模型(LMs)进行了比较,包括Galactica、MolT5、TextChemT5和MolCA。对于逆合成和正向反应预测任务,我们还与特定任务的语言模型进行了比较:R-SMILES、AT、MEGAN和Chemformer。对于描述生成,我们额外与MoMu进行了比较。
5.2 Experimental Procedure Prediction
我们的研究采用了以下评估指标:有效性(Validity),用于检查动作序列的句法正确性;机器翻译指标BLEU和ROUGE;以及标准化的Levenshtein相似度。具体来说,90%LEV表示预测结果中Levenshtein标准化得分大于0.9的比例。基于随机抽样和最近邻的三个原始基线借鉴于paper。更详细的信息请见附录B。
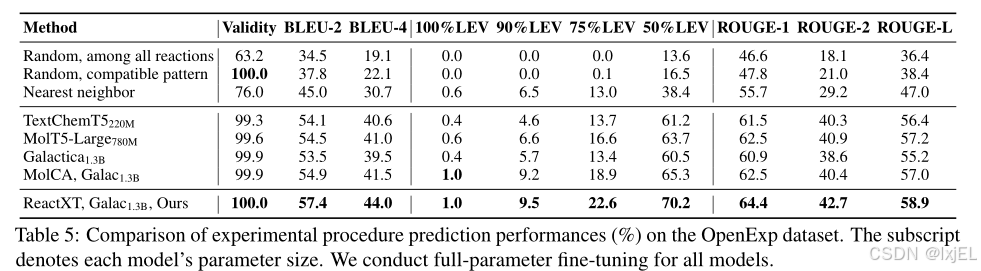
Table 5展示了性能结果。我们可以观察到ReactXT在所有指标上都一致性地超越了基线。具体来说,它在BLEU-2上超过了基线2.2%,在75%LEV上超过了3.3%,这证明了ReactXT在基于文本的反应理解方面的有效性。
5.3 Molecule Captioning
为了评估ReactXT理解单个分子的能力,我们展示了其在PubChem324k和CheBI-20数据集上的分子描述性能。我们报告了BLEU、ROUGE和METEOR等指标。
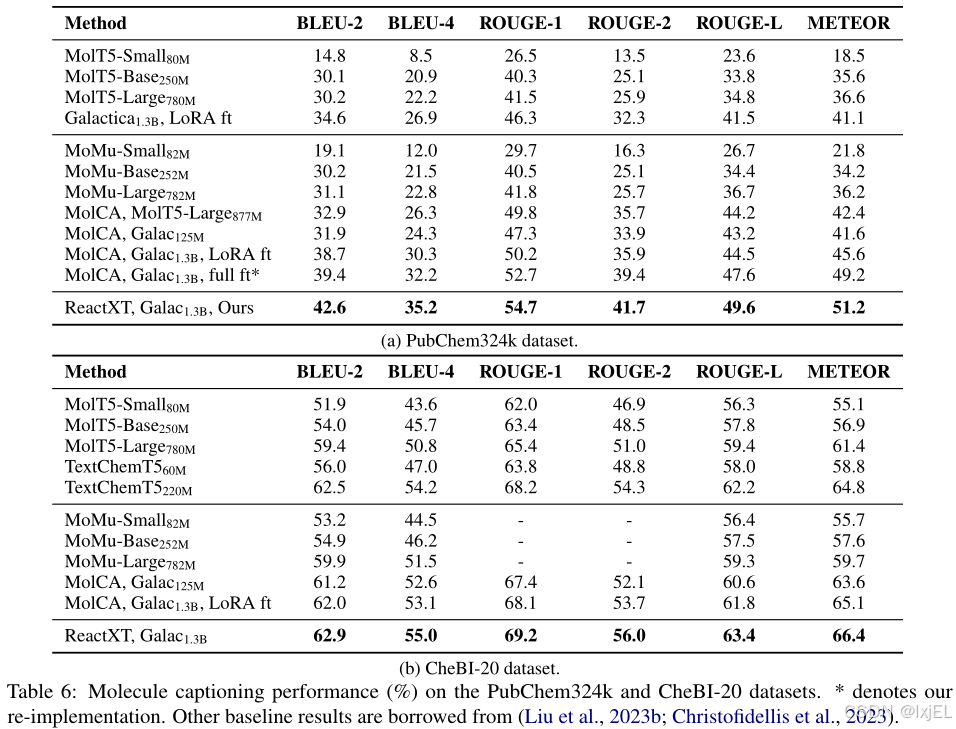
Table 6展示了描述性能。我们可以观察到ReactXT在所有指标上一致性地超越了基线。具体来说,ReactXT在PubChem324k上显示出3.2%的BLEU-2和2.3%的ROUGE-2分数提升,在CheBI-20上显示出1.7%的ROUGE-2提升。这些改进强调了我们的预训练方法在增强对单个分子理解方面的有效性。
5.4 Retrosynthesis
逆合成任务的目标是给定产物分子来预测反应物分子。对于这项任务,我们采用了以下评估指标:top-k准确率,该指标衡量的是预测结果中与真实情况完全匹配的百分比。我们在USPTO-full数据集上进行了自监督预训练,并在训练和测试中使用了SMILES的根对齐增强。此外,我们还报告了在不使用这些增强的情况下的测试性能。
Table 7展示了结果。在使用增强进行测试时,ReactXT在所有指标上都优于R-SMILES。特别是,top-1准确率的提高尤为显著,比第二好的结果提高了2.3%。无论是否应用测试集数据增强,ReactXT都实现了比MolT5-Large更好的top-k准确率,MolT5-Large也是一种多模态语言模型。这些性能提升源于ReactXT使用反应而非单个分子进行预训练。
5.5 Ablation Study
在本节中,我们进行了消融研究,以显示不同的预训练数据类型和主干LMs在我们的方法中的影响。
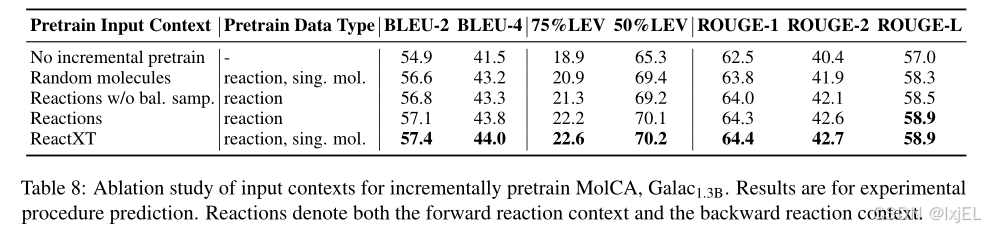
Pretrain Data Type
我们对ReactXT的关键组件进行了消融研究,使用的基线是MolCA和
G
a
l
a
c
1.3
B
Galac_{1.3B}
Galac1.3B,它们没有进行增量预训练。Table 8展示了结果。具体来说,我们比较了ReactXT的三个变体:
1)仅使用随机分子上下文进行预训练,使用相同的预训练数据集;
2)使用正向和反向反应上下文进行预训练,不使用随机分子上下文;
3)在反应上下文中应用均匀采样,而不是平衡采样。
我们可以观察到:
1)ReactXT的完整模型展现了最佳性能,表明其性能是所有组件综合贡献的结果;
2)仅应用随机分子上下文就超过了基线,强调了我们精心制作的预训练数据集中宝贵的文本知识;
3)纳入反应上下文比随机分子上下文取得了更好的结果,突出了在预训练中学习反应知识的好处;
4)平衡采样在性能上优于均匀采样。
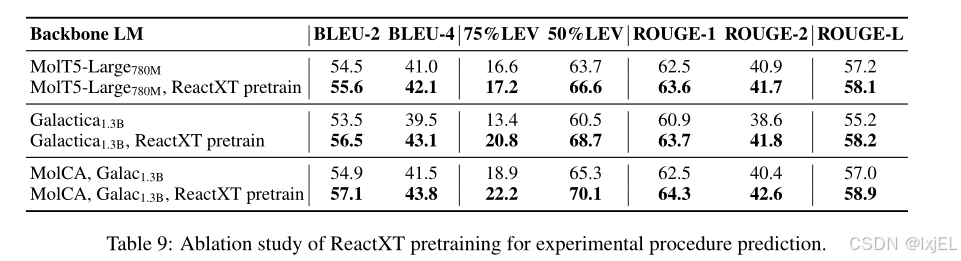
Backbone LMs
此外,我们还对不同的分子-文本语言模型(LMs)进行了消融研究,包括:
1)MolCA,它使用一维SMILES和二维图来表示分子,基于仅解码器架构;
2)Galactica,它使用一维SMILES来表示分子,基于仅解码器架构;
3)MolT5,它使用一维SMILES来表示分子,基于编码器-解码器架构。
实验结果表明,无论使用哪种背景语言模型,ReactXT预训练方案都取得了一致的性能提升。
6 Conclusion and Future Works
在这项工作中,我们探索了反应-文本建模,以赋予与反应相关的任务以文本接口和知识。我们提出了ReactXT,这是一种预训练方法,用于在相应的分子文本描述的上下文中学习化学反应。此外,我们还提出了一个新的数据集OpenExp,以支持实验程序预测的开源研究。ReactXT在实验程序预测和分子描述任务中建立了最佳性能。它在逆合成方面也表现出了竞争性的表现。
未来的工作计划包括将语言模型(LMs)应用于学习大分子(例如蛋白质和核酸)之间的相互作用,或者引入分子的动态和3D空间结构,以更好地理解分子语言。我们还对探索分子LMs在OOD泛化方面的表现感兴趣。
Limitations
在这项工作以及之前的研究中,实验程序预测的评估仅限于将预测结果与参考动作序列进行比较。虽然提高这一指标确实反映了实验设计的进步,但应该承认,对于未来开发的模型而言,更希望进行真实世界的化学实验评估。为此,可以考虑自动化化学流水线的方法。
另一个限制或未来的研究方向是改进我们提出的OpenExp数据集中定义的动作空间,目标是涵盖更广泛的化学实验范围。例如,“纯化”动作是缺失的;而“浓缩”动作可以细化为“蒸发”和“加压”等操作,以提供更清晰的化学实验指导。
Potential Ethics Impact
在这项研究中,所提出的方法和数据集专注于化学反应和分子,并不涉及人类主体。因此,我们认为这项研究没有直接的伦理问题。然而,我们的研究中包含的语言模型(LMs)确实可能引发潜在问题,因为LMs可能被滥用来产生错误或有偏见的信息。因此,我们工作的伦理含义与LM研究中常见的伦理问题一致,强调了负责任地使用和应用LMs的必要性。
Acknowledgement
这项研究得到了国家重大科技专项(2023ZD0121102)、国家自然科学基金(92270114)的支持。这项研究部分得到了新加坡国家研究基金会在新加坡人工智能计划(AISG Award No: AISG2-TC-2023-010-SGIL)下的支持,新加坡教育部学术研究基金一级项目(Award No: T1 251RES2207)以及谷歌云研究积分计划的资助(Q4MJ-YH1K-3MVX-FP6Q)。这项研究由NExT研究中心支持。
附录
A.Dataset Details
A.1 Collection and Preprocessing of OpenExp
OpenExp是根据以下两个来源的原始数据编译的:
- USPTO-Applications
该数据集包含了从2001年到2016年9月,美国专利商标局(USPTO)发布的194万条反应及其相应应用的记录。我们从Figshare网站下载了原始的XML文件。对于数据集中的每个反应,我们从四个元素中提取其关键信息:< productList >,包含反应的产物;< reactantList >,详细列出反应物;,包含催化剂和溶剂;以及< dl:paragraphText >,提供实验步骤的文本描述。 - Open Reaction Database
ORD 数据集包含了超过200万条化学反应记录,其中详细记录了反应条件和实验步骤。它包括了来自USPTO申请文件(2001年至2016年9月)、USPTO授权专利(1976年至2016年9月)以及化学文献中的实验记录的数据。
Paragraph2Action
如Fig 2所示,这些数据库包括化学反应和相应的非结构化实验步骤描述。这些描述的非结构化特性构成了一个重大挑战,即:
1)使用机器人自动化化学合成;
2)应用机器学习方法来预测未见反应的实验步骤。
为了解决这一问题,提出了paragraph2action任务,旨在将非结构化的实验步骤描述转换为具有预定义动作的结构化、分步指令。在本研究中,我们利用了Vaucher等人定义的动作规则,并使用了Christofidellis等人发布的paragraph2action模型。
Preprocessing
我们在paragraph2action转换后进行预处理。预处理有两个目的:
1)提取实验步骤中的重要实体(即分子),并将所有分子映射到化学反应中的前体;
2)应用基于规则的过滤来提高数据集质量。
我们的预处理策略受到(Vaucher等人,2020年)的启发,并增加了两个额外的步骤:
困惑度过滤和相似动作聚合。完整的预处理步骤如下所列:
- Perplexity Filtering
为了确保上述翻译步骤的质量,我们为每个输出计算了一个困惑度分数,并排除了分数大于1.0的样本。这些困惑度分数是使用TextChemT5模型计算的。
(困惑度过滤(Perplexity Filtering)是一种评估语言模型对数据拟合程度的指标。在自然语言处理中,困惑度用来衡量模型对测试数据的预测能力,其值越低,表示模型对数据的预测越准确。具体来说,困惑度是测试数据概率的倒数的几何平均数的指数。在预处理步骤中,困惑度过滤可能被用来移除那些模型预测概率低的数据点,从而提高数据集的整体质量 )
- Entity Recognition
我们使用(Vaucher等人,2020年)的源代码从动作序列中提取所有分子(无论是通过名称还是SMILES)。然后,我们在提取的分子和化学反应中的分子之间进行IUPAC名称的字符串匹配。STOUT和PubChemPy用于IUPAC名称和SMILES之间的转换。如果任何分子无法与其在化学反应中的对应物匹配,我们认为反应数据无效,并将其从数据集中移除。然而,我们允许某些常见物质,如常见的有机溶剂,包含在每个反应中。我们的代码中包含了134种常见物质的名称和SMILES表达式。实体识别后,我们为每个实体分配一个唯一的ID,并通过替换实体提及为相应的实体ID来更新实验程序。 - Common Substance Renaming
我们对那些有多个名称的常见物质的命名法进行了标准化(例如,水也可能被称为H2O、纯水、水(aq.)等),以提高数据集的精确度。使用PubChemPy,我们将不同名称与其标准化的SMILES表示对齐,这允许我们通过比较它们的SMILES表达式来识别不同术语是否指的是同一分子。 - Similar Action Aggregation
如果两个相邻的操作非常相似(例如,搅拌和搅拌5分钟),它们将被合并在一起。 - Ensuring Single Product
确保单一产物。这个数据集专注于单一材料的制备,因此我们移除了产生多种产物的反应。 - Action Filtering
我们移除了动作序列少于五个或包含无效动作的动作序列。 - Reaction Deduplication
我们从数据集中移除了重复的反应。
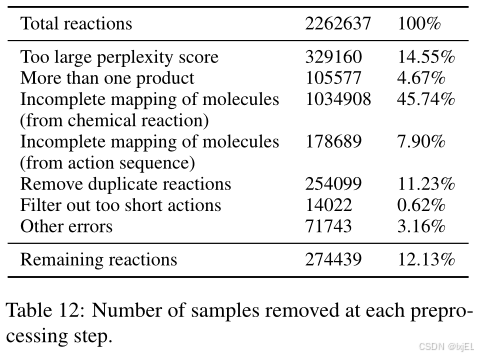
Table 12给出了每个预处理步骤移除的样本数量。此外,Table 11提供了最终OpenExp数据集的示例,我们可以观察到它包含:
• 结构化的、分步的实验程序说明;
• 反应中的所有分子及其角色(即反应物、溶剂、催化剂、产物);
• 识别实体(即分子)与其ID之间的映射关系;
• 原始的非结构化实验程序。
Discussion on License
ORD数据库可以在CC-BY-SA许可下获取,而USPTO-Applications数据集则在CC0许可下可用。我们在研究中使用了TextChemT5和Paragraph2Actions的代码,这两个代码都遵循MIT许可。因此,为了遵守这些资源中最严格的许可,我们将在CC-BY-SA许可下发布OpenExp数据集。这种许可允许内容的分发和共享,只要应用相同的许可。
Human Evaluation
我们邀请了两名化学专业的博士研究生来评估OpenExp数据集的质量。具体来说,从数据集中随机抽取了250个数据点,并根据以下规则分配给评估者:1)前50个数据点同时分配给两名志愿者,以验证他们的评估一致性;2)剩下的200个数据点然后平均分配给两名评估者。根据这个分配规则,每位评估者负责150个数据点。然后要求评估者根据1(最低)到5(最高)的评分标准,对每个数据点的质量进行评分。我们对评估者的指示如下所示:

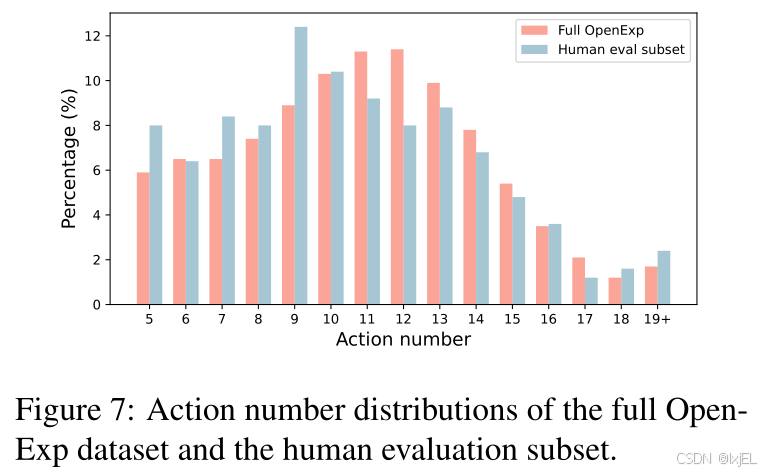
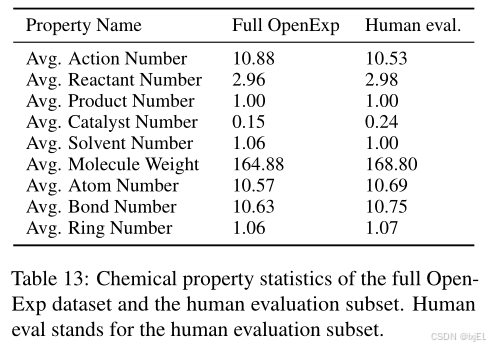
(Figure 5 presents the human evaluation results. Statistics of these 250 data points and the entire dataset can be found in Figure 7 and Table 13. We can observe that the distribution of the sampled data points closely resembles that of the entire dataset,
suggesting that the human evaluation results can reflect the overall quality of the OpenExp dataset. Fig 5展示了人类评估结果。250个数据点的统计信息和整个数据集的统计信息可以在Fig 7和Table 13中找到。我们可以观察到,抽样数据点的分布与整个数据集的分布非常相似,这表明人类评估结果能够反映OpenExp数据集的整体质量。)
(翻译:我们正在策划一个部分由人工智能模型生成的数据集,并希望从专家那里获得对其质量的反馈。在评估过程中,我们将提供机器语言序列(机器生成的实验动作操作序列)和相应的自然语言序列(原始自由文本中的实验程序描述)。您应该根据操作序列与原始描述的对齐程度来对这些样本进行评分。请使用1(对齐程度低)到5(对齐程度高)的评分标准。在评估期间,提供分子骨架公式作为参考图像。这个数据集的所有原始数据都来自美国专利商标局(USPTO),确保了反应的可行性。
以下是详细的评分指南,最高分为5分:
- 5分:机器生成的动作序列在捕捉原始实验程序的关键细节方面没有错误,包括动作、材料和数值。
- 4分:机器生成的动作序列最多包含一个(nerr ≤ 1)与动作、材料或数值相关的错误或遗漏。
- 3分:机器生成的动作序列最多包含两个(nerr ≤ 2)与动作、材料或数值相关的错误或遗漏。
- 2分:机器生成的动作序列最多包含四个(nerr ≤ 4)与动作、材料或数值相关的错误或遗漏。
- 1分:机器生成的动作序列包含超过四个(nerr > 4)与动作、材料或数值相关的错误或遗漏。)
基于50个共享数据点,我们计算了相同样本的评分差异(即,评估者1给出的分数减去评估者2给出的分数)。结果在图6中展示。我们可以观察到,40%的样本(20个中的50个)评分完全一致,54%的样本(27个中的50个)记录了较小的评分差异(±1)。两个或更多评分差异很少见,仅出现在6%的样本中(3个中的50个)。一些详细评估的数据点示例在附录C.3.2中。
A.2 Collection and Preprocessing of ReactXT’s Pretraining Dataset
在第3节中,我们收集并编制了一个数据集,以逐步预训练语言模型(LM),提高对化学反应和单个分子的理解。在这里,我们详细阐述了这个数据集的细节,它包括以下内容:
- 1162551个化学反应方程式;
- 涵盖1,254,157个分子的专利摘要和计算/实验属性,这些分子都来自于化学反应。
我们从ORD和USPTO数据集中提取化学反应。然后,我们从PubChem的Patent View||获取专利摘要,并使用PubChem的Pub-View API获取分子属性。对于每个分子,摘要文本来源于提及该分子的专利文件摘要,其属性包括计算和实验属性。Tbale 14显示了这些属性的完整列表。在Table 15中,我们比较了我们的预训练数据集与PubChem324k的统计数据。我们可以观察到,ReactXT的预训练数据集包含了更多的分子,并且还包括了化学反应。
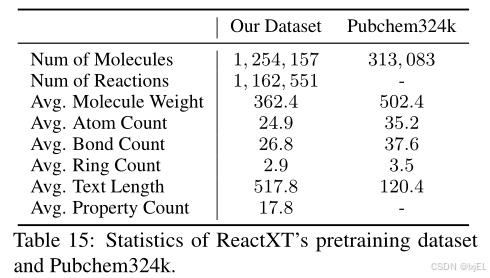
为了防止信息泄露,我们从预训练数据集中排除了出现在下游数据集(即OpenExp和USPTO-50K)的验证集和测试集中的共计54,403个反应。剩下的1,108,148个反应用于预训练。
Discussion on License
ORD数据库可以在CC-BY-SA许可下获取,而USPTO-Applications数据集则在CC0许可下可用。从PubChem获取的专利摘要由Google Patent提供,其发布遵循CC-BY-4.0许可。为了遵守这些资源中最严格的许可条款,我们将在CC-BY-SA许可下发布我们的数据集。
此外,我们还在预训练中使用了PubChem网站上的文本描述、计算属性和实验属性。鉴于这些数据是由PubChem从不同来源聚合的,确定一个单一合适的许可是具有挑战性的。为了避免许可的复杂性并支持未来的研究,我们将提供下载和预处理这些数据的脚本,而不是直接分发数据。
B.Experimental Details
在这里,我们详细说明了ReactXT在三个下游任务中的预训练和微调的超参数设置。由于训练大型语言模型(LMs)的成本较高,因此对下游数据集的微调仅限于单次运行。
B.1 Hyperparameters
ReactXT Pretrain
ReactXT的预训练阶段共有500万步,每个反应中的分子数量为 k k k=4。按照MolCA的实验设置,我们使用了一个带有8个query token的Q-former。我们使用AdamW作为优化器,权重衰减设置为0.05。优化器的峰值学习率设置为 1 × 1 0 − 4 1×10^{-4} 1×10−4,通过线性预热和余弦衰减进行调度。预热有1000步,起始学习率为 1 × 1 0 − 6 1×10^{-6} 1×10−6。
Experimental Procedure Prediction
我们对所有基线方法和ReactXT进行了完整的微调,共20个epoch,批量大小为32。优化器和学习率设置与预训练阶段保持一致。
Retrosynthesis
我们在训练和测试子集上采样了20个根对齐的增强。在对USPTO-50K数据集进行微调之前,我们首先在USPTO-full数据集上对MolT5和ReactXT进行了2个epoch的掩蔽自监督预训练,遵循R-SMILES的预训练策略。在微调期间,我们在增强的训练集上使用批量大小32对MolT5进行了20个周期的训练,对ReactXT进行了5个周期的训练。然后,我们将模型的参数在最后几个微调步骤中平均作为最终的测试检查点。在测试期间,我们对两个模型都进行了束搜索,束大小为20,并返回前十个结果作为模型的预测。束大小(20)和结果数量(10)遵循R-SMILES的实验。优化器和学习率设置与预训练阶段保持一致。
Molecule Captioning
在两个数据集上,我们对MolCA和ReactXT进行了完整的微调,共20个周期,批量大小为32。优化器和学习率设置与预训练阶段保持一致。
B.2 Other Implementation Details
Baselines
我们简单介绍一下baselines:
- Galactica
Galactica是一个科学语言模型,它在PubChem的200万个化合物上进行了预训练。它对SMILES公式有不错的理解。 - MolT5
MolT5是基于T5模型开发的。它的训练语料包括自然语言和SMILES数据,使其适合于分子描述和基于文本的分子生成任务。 - TextChemT5
TextChemT5是一个基于T5的多领域语言模型,它在各种文本-分子任务上进行了调优。 - MolCA
MolCA是一个多模态语言模型,它在Galactica模型的基础上进行了微调。它不仅包括图编码器,还包括语言模型,其中应用了一个查询变换器(Querying Transformer)来对齐它们的潜在空间。 - AT
AT 使用数据增强来训练用于逆合成的变换器(transformers)。数据增强是通过重新排列训练和测试集中SMILES字符串中的字符顺序来实现的。 - MEGAN
MEGAN是一种将化学反应建模为一系列图编辑操作的模型,它通过顺序修改目标分子来进行逆合成反应预测。 - MoMu
MoMu是一个对比性预训练模型,它联合训练了一个图神经网络(GNN)和一个语言模型(LM),使用配对的分子图-文本数据。可以适应检索和生成任务。 - Chemformer
Chemformer是一个基于Transformer的分子语言模型,它在SMILES语料库上进行了自监督预训练。它可以被应用于分子生成和属性预测任务。 - Random, among all reactions
从训练集中随机选择一个动作序列。 - Random, compatible pattern
从反应的训练子集中随机选择一个与当前反应具有相同分子数的动作序列。 - Nearest Neighbor
根据反应指纹,从训练集中选择与当前反应最相似的动作序列。
C More Experimental Results
C.1 Ablation Study

Table 16展示了一项消融研究,检验了输入上下文对分子描述的影响。移除随机分子上下文会导致描述性能下降。这一观察可以归因于两个因素:
1)包括用于创建随机分子上下文的PubChem324k数据集对于维持分子描述性能很重要;2)没有随机分子上下文,语言模型就会过度依赖反应上下文,这损害了它准确描述单个分子的能力。
这一发现强调了在训练中纳入随机分子上下文的重要性。
C.2 Statistical Analysis
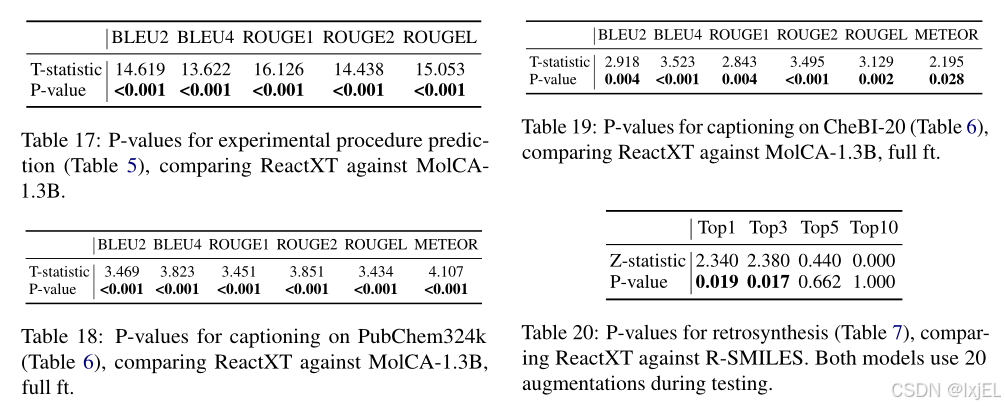
我们对实验结果进行了统计测试,以证明ReactXT与基线模型相比实现了显著的性能提升。对于大多数指标(如BLEU、ROUGE、METEOR),我们采用了T检验;对于Top-k准确率,由于计算标准差较为困难,我们转而使用了两比例Z检验。
统计测试的结果展示在Table 17-Table 20中。我们将小于0.05的p值加粗显示。从这些表格中可以观察到,我们的方法在实验程序预测(Table 17)和分子描述(Table 18和19)任务的所有指标上都取得了统计学上显著的改进。至于逆合成任务(Table 20),我们的方法在Top1和Top3准确率上都显示出了统计学上的显著提升。这些观察结果共同证明了我们提出的预训练方法的有效性。
C.3 Case Studies and Error Analysis
C.3.1 Experimental Procedure Prediction
在本节中,我们从实验程序预测任务中提出了案例研究,以指导未来的研究。我们包括了准确预测的示例(见Table 21)、不准确预测的示例(见Table 22),以及与注释不同但可能同样有效的预测(见Table 23和Table 24)。我们的选择标准优先考虑动作序列的准确性和主要材料的正确识别,同时忽略了具体细节,如材料数量和温度。所有示例均来自OpenExp的测试集。
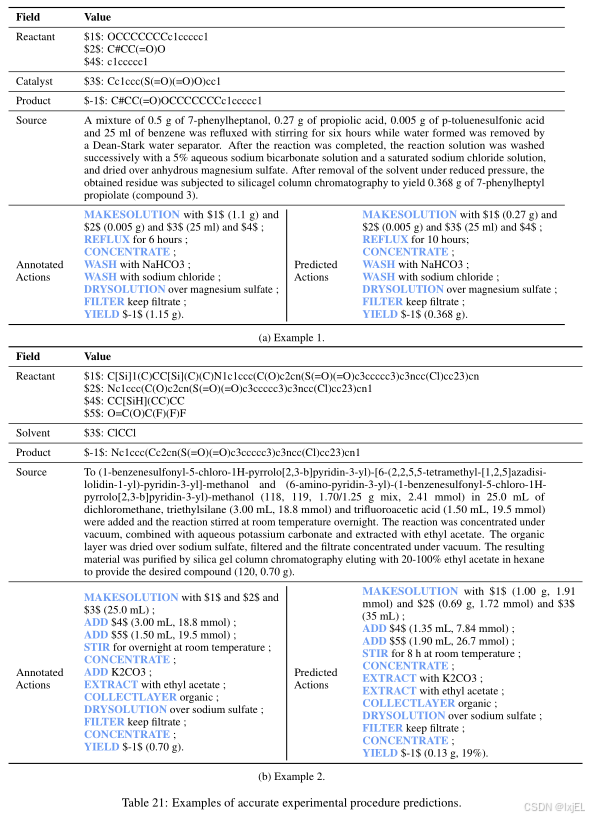
Table 21展示了两个实验程序准确预测的示例,显示了预测动作与注释动作之间的密切对齐,尽管在材料数量和实验时间上有轻微的变化。这些案例突出了语言模型预测实验程序的能力,为自动化化学合成指明了方向。

Table 22展示了两个实验程序预测失败的示例。预测的动作序列与注释序列显著偏离,使它们变得不切实际。此外,我们可以观察到一个常见的错误是重复,即相同或相似的动作被复制。


Table 23和Table 24展示了三个预测与注释不同,但仍然可行的示例。在示例5中,作为注释的“用乙酸乙酯提取”的替代方案,模型提出了一系列动作(“收集层”、“用乙酸乙酯洗涤”、“干燥溶液”和“过滤”),起到了类似的作用。在示例6中,模型没有指定“设置温度”和“搅拌”,而是建议“在0°C下搅拌1小时”,起到了相同的目的。在示例7中,模型建议依次添加组分(“添加$ 4 $”、“添加 $ 5 $”、“添加 $ 6 $”),而不是像注释中那样制作单一溶液,这也可能是有效的。
C.3.2 Human Evaluation of OpenExp
在本节中,我们从人类评估OpenExp数据集的案例研究中展示结果。包含了由人类评估者给出5分到1分的样本,如Table25-Table29所示。所有样本均来自250个人类评估的数据点(见附录A.1)。可以观察到,有两处或更少错误的样本可能只有轻微的缺陷,例如打字错误或不正确的数值。























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









