







MolCA: Molecular Graph-Language Modeling with Cross-Modal Projector and Uni-Modal Adapter
0.摘要
语言模型(LMs)在各种一维文本相关任务中展示了令人印象深刻的分子理解能力。然而,它们固有地缺乏二维图形感知——这是人类专业人员理解分子拓扑结构的关键能力。为了弥合这一差距,我们提出了MolCA:使用跨模态投影器和单模适配器的分子图-语言建模。==MolCA通过跨模态投影器使LM(例如Galactica)能够理解基于文本和图形的分子内容。具体而言,跨模态投影器被实现为Q-Former,以连接图形编码器的表示空间和LM的文本空间。==此外,MolCA使用单模适配器(即LoRA)使LM有效地适应下游任务。与先前通过跨模态对比学习将LM与图形编码器耦合的研究不同,MolCA保留了LM生成开放式文本的能力,并增加了二维图形信息。为展示其有效性,我们在分子描述、IUPAC名称预测和分子-文本检索任务上广泛测试了MolCA,在这些任务上,MolCA显著优于基线。代码和检查点可以在MolCA找到。
1.引言
大多数现有的LM使用一维的SMILES串来表示分子(Figure1,a),以类似文本的方式对其进行处理,但这种处理方法忽视了分子的二维结构信息;最近的工作使用图神经网络对二维分子图进行编码,采用跨模态对比学习的方法将图编码器与LM进行联合训练(Figure1,b),但跨模态对比学习的应用范围有限:适用于检索任务,但不足以用于开放式的文本生成任务(因为分子到文本的生成任务是一种条件生成任务,它需要在LM理解二维分子图的基础上才能完成)。因此论文提出了MolCA,MolCA使得LM能将2D分子图作为输入并能够理解2D信息,从而较好地完成生成任务。
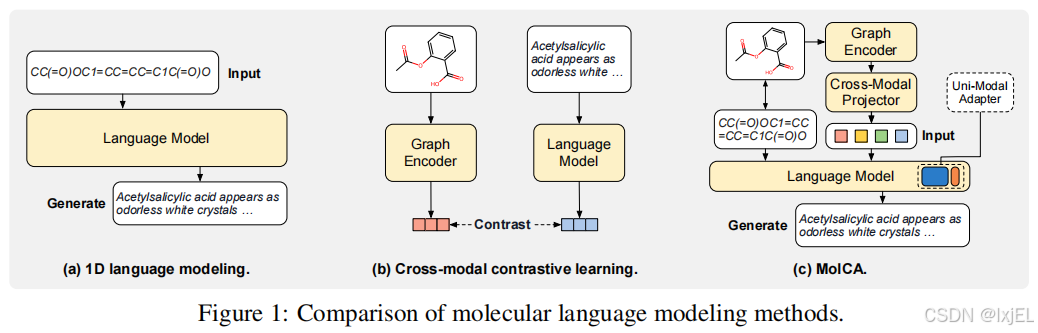
论文指出为使LM能够理解2D图,关键在于跨模态对齐。MolCA使用跨模态投影器将2D分子图转换为1D文本空间中的软提示实现跨模态对齐,其中将跨模态投影仪实现为Q-Former。
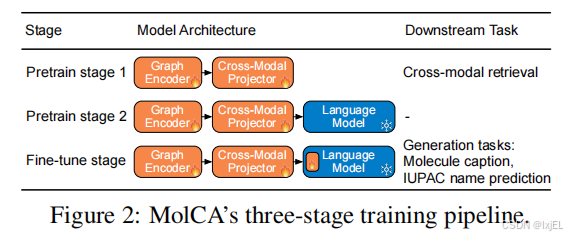
MolCA使用三个阶段的训练任务来整合其组件。
- 预训练1
训练投影仪和图编码器从2D分子图中提取与文本最相关的分子特征,使生成的模型具有强大的分子-文本检索能力。 - 预训练2
跨模态投影仪连接到frozen LM并进行分子描述训练,使跨模投影仪产生LM可以理解的软提示。 - 微调阶段
对下游的生成任务进行微调。
2.方法
2.1 模型框架
2.1.1 图编码器(Graph Encoder)
论文使用基于GNN的编码器对分子图进行编码。
采用了一个五层的GINE,该图编码器对来自ZINC15数据集的200万个分子进行预训练,通过对比学习的方法来提取与文本最相关的分子特征。
给定一个分子图
g
\mathcal{g}
g,图编码器
f
\mathcal{f}
f能够为
g
\mathcal{g}
g中的每个节点生成结构感知的特征,表示为:
f
(
g
)
=
Z
∈
R
∣
g
∣
×
d
(
1
)
\mathcal{f}(\mathcal{g})=\mathrm {Z} \in\mathbb{R}^{|\mathcal{g}|\times d}(1)
f(g)=Z∈R∣g∣×d(1)
其中
∣
g
∣
|\mathcal{g}|
∣g∣表示分子图中节点的数量。
2.1.2 语言模型(Language Model)
采用Galactica作为基础的语言模型(LM)。
2.1.3 跨模态投影器(Cross-Model Projector)
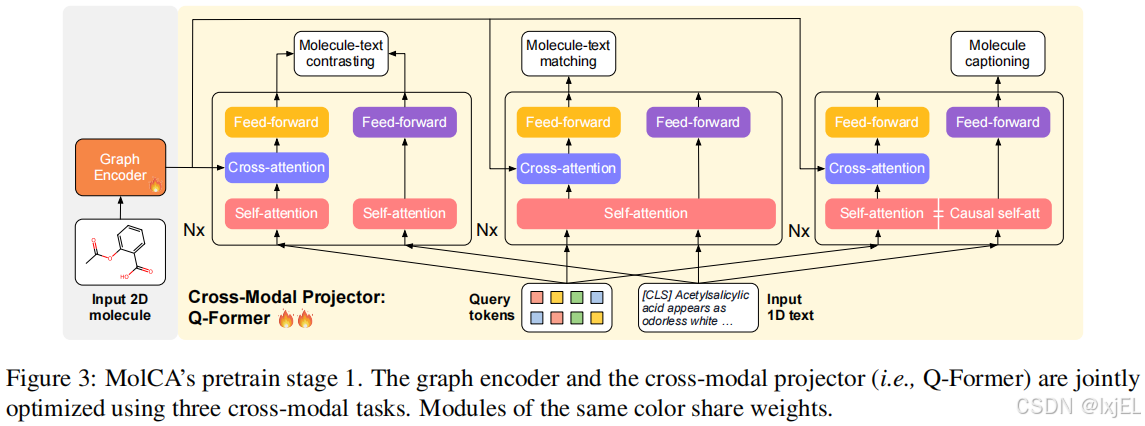
论文将跨模态投影器实现为一个Querying-Transformer(Q-Former),以将图编码器的输出映射到语言模型的输入文本空间。如Figure 3所示,Q-Former在处理2D分子图和1D文本时有不同的程序。
- 给定文本输入,Q-Former在开头插入 ′ [ C L S ] ′ '[CLS]' ′[CLS]′标记,并通过 N N N层自注意力模块和前馈网络处理文本。当预训练任务是文本生成时,自注意力模块采用因果掩码(即模型在预测当前token时看不到当前token之后的token)。
- 给定一个分子图 g \mathcal{g} g,Q-Former作为一个分子特征提取器工作。具体来说,它维护一组可学习的query tokens { q k } k = 1 N q {\{\mathrm{q}_k\}}_{k=1}^{N_q} {qk}k=1Nq 作为输入。这些query tokens可以通过交叉注意力模块与图编码器的输出 Z \mathrm {Z} Z交互并提取分子特征。此外,query tokens也可以通过相同的自注意力模块与文本输入交互。query tokens和文本输入由不同的前馈网络处理,以保持处理分子和文本的能力。
MolCA从Sci-BERT初始化Q-Former,其交叉注意力模块是随机初始化的。
2.2 训练
MolCA包含三阶段训练流程(Figure 2)。前两个预训练阶段利用分子-文本对数据集 D = { ( g 1 , y 1 ) , ( g 2 , y 2 ) , . . . } \mathcal{D}=\{(g_1,y_1),(g_2,y_2),...\} D={(g1,y1),(g2,y2),...}来训练跨模态投影器和图编码器。预训练的目标是将2D分子图转换为冻结的语言模型(LM)能够理解的软提示。微调阶段则专注于高效适应下游生成任务。
2.2.1 Pretrain Stage 1: Learning to Extract Text Relevant Molecule Representations
该阶段的目标是优化跨模态投影器(即Q-Former)以提取与文本输入最相关的分子特征。这个阶段作为跨模态投影器在连接到语言模型(LM)之前的“热身”训练。应用了三个为Q-Former架构量身定制的跨模态预训练任务:分子-文本对比、分子-文本匹配和分子描述。
- 分子文本比对 Molecule-Text Contrasting (MTC)
应用跨模态对比学习来训练Q-Former提取与文本相关的分子特征。query tokens和input 1D text被分别送入Q-Former以获得Q-Former的分子表示和文本表示。
令 { ( g 1 , y 1 ) , . . . , ( g B , y B ) } \{(g_1,y_1),...,(g_B,y_B)\} {(g1,y1),...,(gB,yB)}为一批分子-文本对。我们将 g i g_i gi的Q-Former表示为 { m i k } k = 1 N q \{m_{ik}\}_{k=1}^{N_q} {mik}k=1Nq(每个元素对应于一个query token)。将 y i y_i yi的Q-Former表示为 t i t_i ti([CLS]的表示)。对于任意的 i , j ∈ [ 1 , B ] i,j\in[1,B] i,j∈[1,B],我们通过计算 t i t_i ti与 { m j k } k = 1 N q \{m_{jk}\}_{k=1}^{N_q} {mjk}k=1Nq中每个元素之间的最大相似度来衡量 t i t_i ti与 { m j k } k = 1 N q \{m_{jk}\}_{k=1}^{N_q} {mjk}k=1Nq之间的相似度。MTC损失 ℓ M T C \ell _{MTC} ℓMTC的计算公式如下:
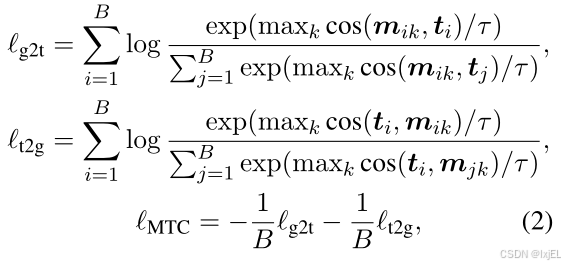
这里的 c o s ( ⋅ , ⋅ ) / τ cos(·, ·)/τ cos(⋅,⋅)/τ是温度缩放的余弦相似度。温度 τ τ τ经验性地设置为0.1。 - 分子文本匹配 Molecule-Text Matching (MTM)
MTM是一个二元分类任务,目标是预测一个分子-文本对是否匹配(正样本)或不匹配(负样本)。MTM允许query和text通过同一个自注意力模块进行交互。通过这种方式,query tokens可以从分子和文本中提取多模态信息。对于MTM预测,在所有查询的Q-Former表示进行平均池化后附加一个线性分类器。设 ρ ( g , y ) ρ(g, y) ρ(g,y)表示MTM预测的 ( g , y ) (g, y) (g,y)匹配的概率。MTM损失 ℓ M T M ℓ_{MTM} ℓMTM可以表示为:
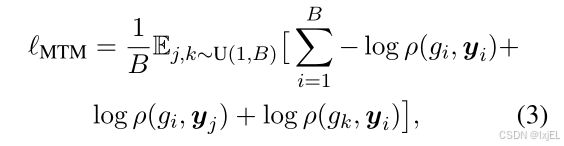
其中 U ( 1 , B ) U(1,B) U(1,B)为均匀分布, y j y_j yj和 g k g_k gk为批次中的随机负样本。 - 分子描述 Molecule Captioning (MCap)
MCap的目标是根据分子表示生成分子的文本描述。为了完成这个任务,MolCA采用了一种特殊的掩码策略在自注意力模块中,以确保query学会提取与文本描述相对应的分子特征:为query使用了双向自注意力掩码,允许它们相互看到,但看不到文本标记。此外,对同一自注意力模块上的文本应用因果掩码,以进行文本描述的自回归解码。每个文本标记可以看到query和前面的文本,但看不到后面的文本标记。由于文本标记不能直接与图编码器交互,它们必须从query中获取分子信息,这迫使查询通过交叉注意力模块提取分子信息。设 ( p 1 ( y ∣ g ) ) ( p_1(y|g) ) (p1(y∣g))为Q-Former生成文本 ( y ) ( y ) (y)对于图 ( g ) ( g ) (g)的概率。使用以下损失函数:
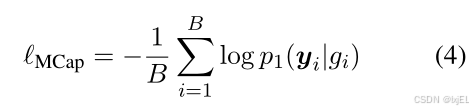
2.2.2 Pretrain Stage 2: Aligning 2D Molecular Graphs to Texts via Language Modeling
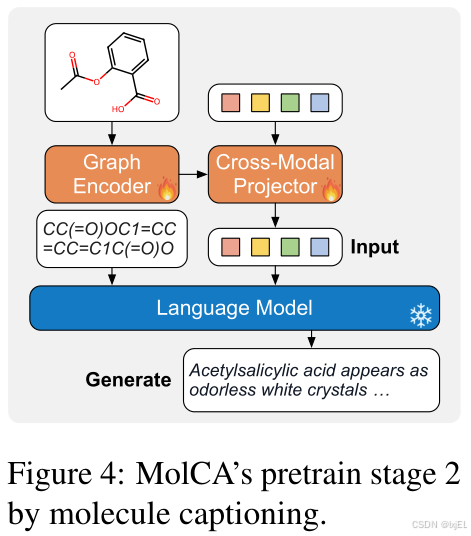
这个阶段的目标是将跨模态投影器的输出与冻结的语言模型(LM)的文本空间对齐。如Figure 4所示,将跨模态投影器对2D分子图的表示作为输入喂给冻结的LM,并训练模型生成分子的文本描述。这个过程鼓励跨模态投影器提供LM能够理解的表示,以促进文本生成。
考虑一个分子-文本对
(
g
,
y
)
(g, y)
(g,y),
g
g
g的SMILES表示
s
s
s,跨模态投影器对
g
g
g的表示记作
{
m
k
}
k
=
1
N
q
\{m_k\}_{k=1}^{N_q}
{mk}k=1Nq。定义
p
2
(
⋅
)
p_2(\cdot)
p2(⋅)为由冻结的语言模型参数化的文本分布。通过最小化以下损失函数来优化跨模态投影器和图编码器:
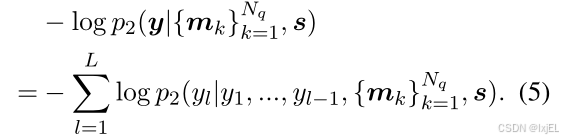
2.2.3 Fine-tune Stage: Uni-Modal Adapter for Efficient Downstream Adaptation
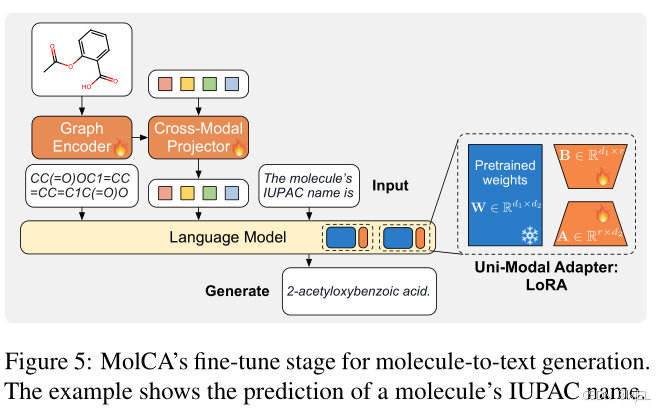
在这个阶段,我们对MolCA进行微调以适应下游的生成任务。如Figure 5所示,在分子表示之后添加了任务描述的文本提示。然后,我们应用语言模型损失来微调MolCA,以用于生成任务,例如分子的IUPAC名称预测。
- Uni-Modal Adapter
为减少训练参数,MolCA采用了LoRA(Low-Rank Adaptation)适配器,在LM中选定的权重矩阵(例如, W ∈ R d 1 × d 2 W ∈ \mathbb{R}^{d_1×d_2} W∈Rd1×d2)中,LoRA会以并行的方式添加一对秩分解矩阵(例如, B A BA BA,其中 B ∈ R d 1 × r B \in \mathbb{R}^{d_1 \times r} B∈Rd1×r, A ∈ R r × d 2 A \in \mathbb{R}^{r \times d_2} A∈Rr×d2。原始的 h = W x h = Wx h=Wx层被更改为:
h = W x + B A x , ( 6 ) h=Wx+BAx,(6) h=Wx+BAx,(6)
其中 W W W保持冻结状态,新添加的 B A BA BA在适应过程中进行训练。由于 r ≪ m i n ( d 1 , d 2 ) r \ll min(d_1, d_2) r≪min(d1,d2),LoRA可以有效地使LM适应下游任务,同时只需要很少的存储空间来保存梯度。
3.实验
3.1 数据集
PubChem324k Dataset
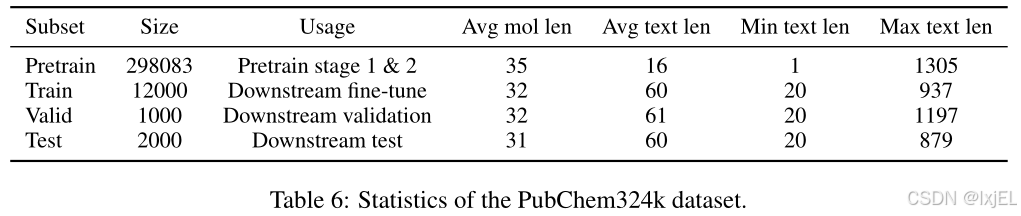
MolCA收集了PubChem-324k数据集,该数据集包含了来自PubChem网站的324k个分子-文本对。数据集中包括了许多信息量不大的文本,例如“The molecule is a peptide”,MolCA从中抽取了一个包含15k对、文本长度超过19个单词的高质量子集,用于下游任务。这个高质量子集进一步被随机划分为训练集/验证集/测试集。剩余的数据集被用于预训练。此外还过滤了预训练子集,排除了其他下游数据集的验证集/测试集中的分子,包括CheBI-20、PCDes和MoMu数据集。过滤后的数据集总共包含了313k个分子-文本对。
3.2 对比实验
3.2.1 Molecule Captioning
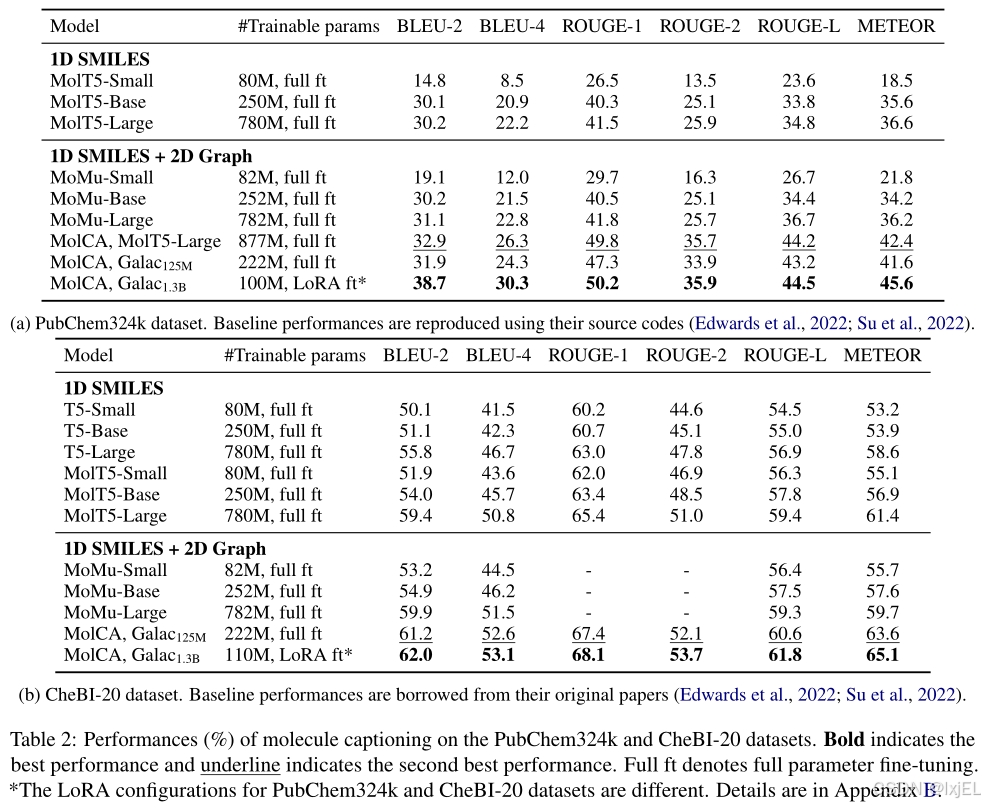
在PubChem324k和CheBI-20数据集上评估了MolCA的性能,使用了基于Galactica 1.3 B _{1.3B} 1.3B、Galactica 125 M _{125M} 125M和MolT5-Large的语言模型,并采用了BLEU、ROUGE和METEOR作为评估指标来评估MolCA性能。实验结果如Table 2所示,MolCA在各项指标上表现优于基准模型,尤其是 G a l a c 1.3 B Galac_{1.3B} Galac1.3B版本表现最佳。此外,MolCA-Galac 125 M _{125M} 125M版本在各项指标上都优于规模较大的基准模型,表明MolCA的优势并非仅限于模型规模。
3.2.2 IUPAC Name Prediction
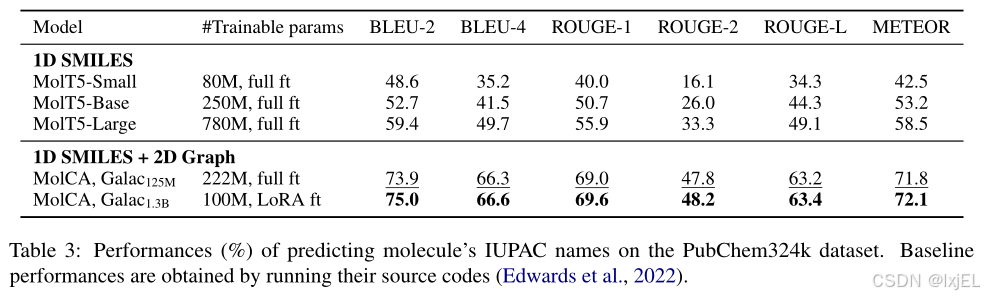
国际纯粹与应用化学联合会(IUPAC)建立了一个标准化的化学化合物命名系统,即IUPAC名称。如Table 3所示,MolCA在各项指标上一致优于基线模型,BLEU-2的平均提升达到了10.0,突出了MolCA在理解分子结构方面的优势。
3.2.3 Molecule-Text Retrieval
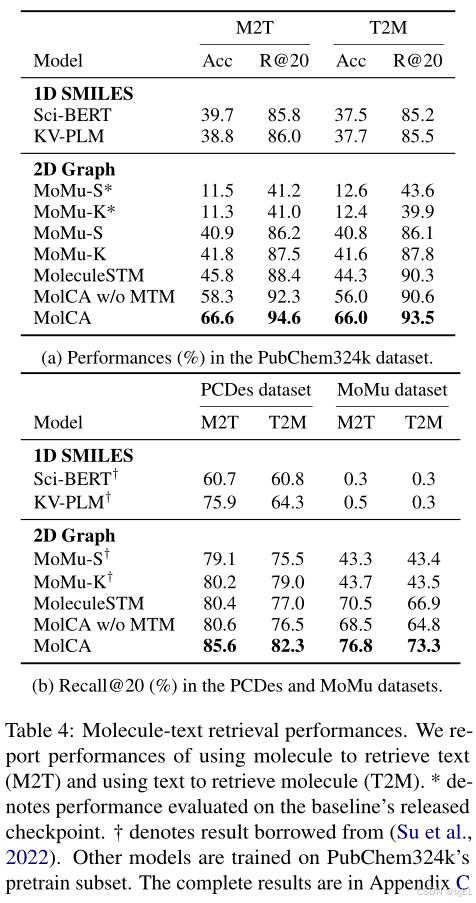
在所有实验中,MolCA首先使用分子-文本对比(MTC)检索出前128个候选对象,然后利用分子-文本匹配(MTM)模块进行重新排序。选择准确率(Accuracy, Acc)和召回率@20(Recall@20, R@20)作为评估指标,并对整个测试集的检索性能进行了报告:
- 在PubChem324k数据集中,MolCA的准确率比基线模型提高了20%以上。在PCDes和MoMu数据集中,MolCA也持续优于基线模型,证明了其在分子-文本检索方面的有效性。
- 结合MTM显著提升了MolCA的性能。这可以归因于MTM模块能够通过交叉注意力和自注意力模块,对分子特征和文本之间的长期交互进行建模。
- MolCA的优异表现部分可以归因于更大的预训练数据集——PubChem324k。如Table 4(a)所示,比较了MoMu原始检查点(在15k分子-文本对上预训练)与使用PubChem324k数据集重新训练的MoMu的性能。后者的检索准确率提高了25%以上。
3.3 消融实验
对分子的两种表示类型进行了消融研究:1D SMILES和2D图形。比较了MolCA与其两个变体:1) 1D SMILES:一个仅使用1D SMILES进行预训练和微调的语言模型;2) 2D Graph。
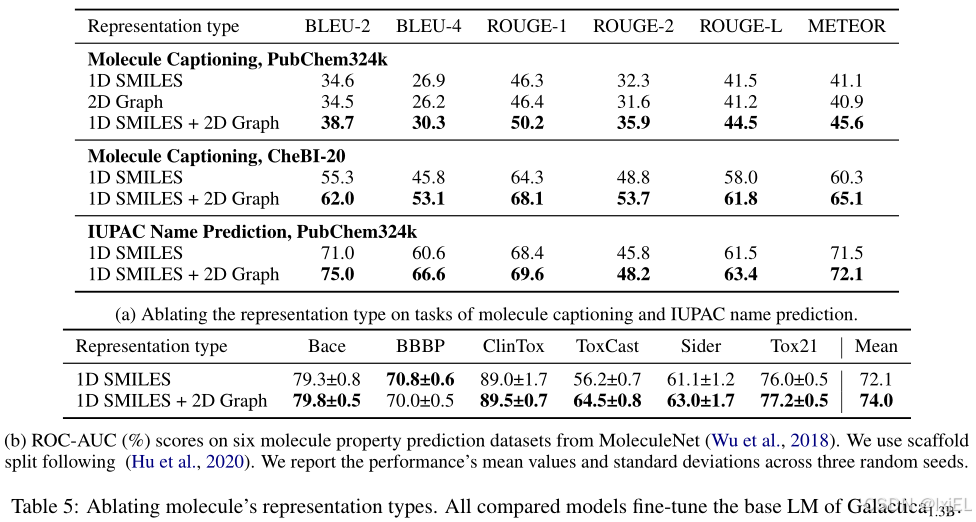
Table 5展示了分子到文本生成和分子属性预测任务的结果。可以观察到,结合2D图形和1D SMILES能够提高所有比较任务的性能。
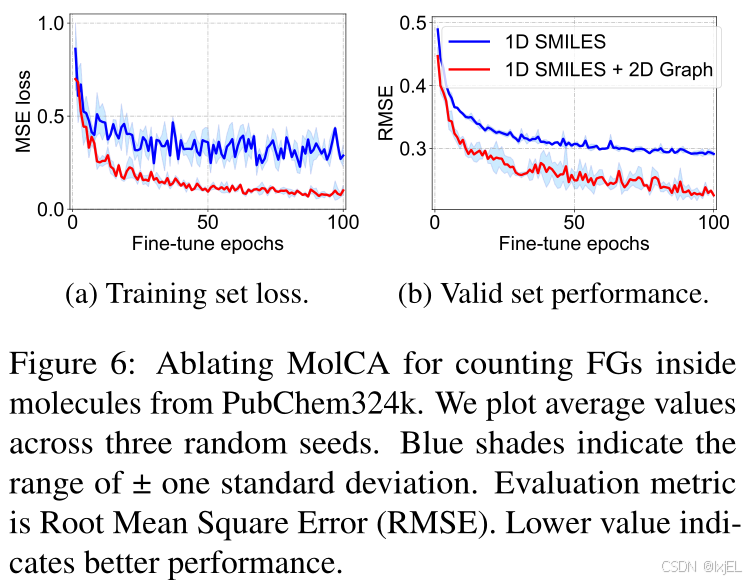
对MolCA在计算分子中85种功能团(FGs)的能力进行了消融研究。功能团是分子的一个子图,它在不同分子中表现出一致的化学行为。如Figure 6所示,整合2D图形显著提高了MolCA在计算功能团数量上的性能,从而增强了其理解分子结构的能力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









