






在谈及与IO有关的场景时,一般都不会落下缓存。这两位关系之所以如此紧密,还是由于不论是网络IO还是磁盘IO,效率实在是令人不敢恭维,基本都在几十至几百毫秒(1ms = 1 * 10的6次方ns);而内存的访问速度是微秒级别(1μs = 1 * 10的3次方ns),差不多比磁盘IO能快1000倍上下。
而缓存又依照一些特性被分为多级,简单了解一下:
- 一级缓存:进程内缓存,即单个Java进程内存放的缓存数据,最简单的实现可以是一个List、ConcurrentHashMap。
- 二级缓存:单机/分布式缓存,一般独立于Java进程,部署在与Java服务不同的服务器上,常采用Redis、Memcache中间件组成集群来实现。
二级缓存的使用已经是老生常谈的话题,比如大家都知道的Redis集群。但如果你的项目复杂度并没有高到需要引入分布式缓存,或者说你想采用更简单的方案(毕竟引入新的中间件伴随着更高的系统复杂度),再或者你需要极致的性能,那么一级缓存便是不二的方案。
但在享受一级缓存带来便利的同时,也别忘了他自身的缺陷:
- 基本不可干预。我们知道Redis有控制命令、有可视化工具可以对Key或者实例本身进行修改,而一级缓存依附于Java进程,这个特性使得他基本无法被修改,除非对外暴露一些可以操作他的接口,但这无形中又提升了工作量,把使用他省下来的那点又还回去了。
- 没有持久化功能。这点是十分致命的,如果你将一些数据存放在一级缓存内,准备择良时写入磁盘;此时服务器出问题了,进程跟着终止,还没来得及持久化的数据也随着一起离开人世。持久化频率设置得高低,就决定了丢数据数量的多少。
- 缓存一致性。在分布式系统内,同样的实例会部署在不同的服务器上,那么这份一级缓存也就会存在多份,当你修改了缓存内的值,如何保证所有服务器上的值都被正常修改?如何降低不一致现象存在的时间?
- 扩展性较低。这个很好理解嘛,他是塞在进程内的,你倒是想扩展,咋扩啊?像Redis集群如果想扩容,直接加机器动态扩容,通过一致性哈希就可以将数据分布在所有实例上。对于一级缓存,这种情景就不太可能了,好在内存是比较廉价的资源,不要太过挥霍都不会出太大问题。
好嘛,说了半天全是缺点,那还用个屁啊。话也不是这么说,他的优势也是十分明显的:使用复杂度低(简单来说就是一个HashMap)、非常快(网络通讯开销为0)、成本低(不用买服务器,内存是廉价的),业内也有很多非常成熟的实现,放一些变动不频繁的数据是很合适的。
下面我们正式介绍Guava Cache缓存实现。
1 Guava Cache的构建
有些同学应该也听说过Spring Caffeine,是Spring自带的缓存实现,应该也是极为好用的。但我比较喜欢Guava因此采用了Guava Cache。
Guava Cache有两种实现,分别为Cache和LoadingCache,不同在构建时是否指定加载缓存值的方法:
@CheckReturnValue
public <K1 extends K, V1 extends V> LoadingCache<K1, V1> build(CacheLoader<? super K1, V1> loader) {
this.checkWeightWithWeigher();
return new LocalCache.LocalLoadingCache(this, loader);
}
@CheckReturnValue
public <K1 extends K, V1 extends V> Cache<K1, V1> build() {
this.checkWeightWithWeigher();
this.checkNonLoadingCache();
return new LocalCache.LocalManualCache(this);
}两者的区别不是很大,LoadingCache在获取不到缓存值时,会直接调用构建时传入的CacheLoader的load()方法来加载缓存值,我们通过重写load()方法来指定加载逻辑。而Cache在获取值时,需要显式传入加载方法,当然也有getIfPresent()方法用于“有值时获取”场景。因此,LoadingCache一般在缓存数据被隔离开时使用,比如有多个LoadingCache来缓存不同类。而Cache里面可能存放了五花八门的数据,每个类的加载方式不同,就需要每次获取时传入不同的加载逻辑。
重点来看看其他几个构建参数。
1.1 容量:
- initialCapacity:初始容量,设置合理的初始容量可以避免扩容带来的性能损耗。
- maximumSize:最大容量,代表缓存最大的key数量。
- maximumWeight:最大容量,代表缓存最大容量,每个key占用的容量通过weigher指定,在创建key时weight就已经决定。和maximumSize互斥。
1.2 过期策略:
- expireAfterWrite:写入后多久被标记为过期,过期后需要调用Load方法重新加载。
- refreshAfterWrite:写入后多久被标记为过期,但在新值加载完成前,其他线程返回旧值。
- expireAfterAccess:最后一次被读写后多久被标记为过期,意为每次被读写都会重置过期时间,直到一段时间没有被读取后,标记为过期。
1.3 并发量:
concurrencyLevel,并发量。试想这样一个场景,我们同时缓存了1000个key,60秒后他们同时过期;此时又有人来访问这1000个key,他们会同时被加载,可能是去DB查询加载。这就是我们常说的“缓存雪崩”,“缓存击穿”同理,如果有一个热点key过期,会出现同样的现象,也无法保证线程安全。
Guava自然要避免这样的问题出现,保证一个key同时只会被一个线程加载,因此需要限制加载方法调用的并发量,那么如何限制?Guava采用了ConcurrentHashMap早期的思路,将锁加在Segment(段)上。理想情况下,每个键值对经过hash后会存放在不同的Segment内,因此Segment越多锁越多、竞争度越低,而加在方法上就是万年不变的1。
设置concurrencyLevel正是在设置Segment的数量,该值缺省为4,我们可以酌情将其设置得高一些。
但其实还是不太对劲,使用expireAfterWrite模式时,到达指定时间key过期,如果有多个线程想要获取该key的值,只有第一个线程会获取锁并加载值,其他线程在第一个线程加载完值前会一直阻塞,也不是很理想。因此在高并发环境下,使用refreshAfterWrite让其他线程先返回旧值吞吐量会高一些。
但问题是:key过期后并不会立即被删除,而是被标记为过期并放入一个map中,获取该key时检查其状态,未过期才会返回值,否则重新加载。
如果使用refreshAfterWrite,key过期了但一直没有人来访问,这个key就一直不会被加载,时间长了这缓存里的值可就老了去了。
那我们能不能结合一下这两种,短时间内返回旧值,时间过长再强制阻塞获取新值。答案是可以,我们可以同时配置expireAfterWrite和refreshAfterWrite,但是前者时间要比后者设置得长一些,否则根本不会触发refresh。
例如refresh设置60秒,expire设置600秒,会出现如下情况:
- 第60秒时key失效,等待refresh,此时多个线程访问该key,只有第一个进入的线程会阻塞加载新值,其他线程会先返回旧值;
- 第120秒时key又失效,等待refresh,此时没有人访问该key;
- 第660秒时,key彻底过期,变成expire状态,此时再有人来访问,会阻塞所有线程并重新加载。
这样既不会频繁阻塞在加载值、又一定程度保障了数据的新鲜度。
2 读取/写入
使用起来其实非常简单,我们以Cache类为例,介绍一下缓存的读取和写入方法。
2.1 读取
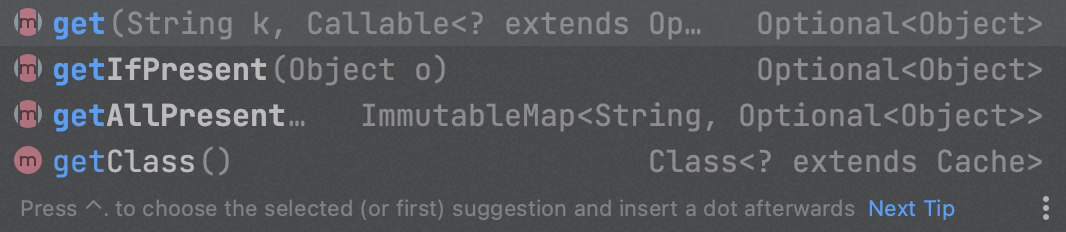
有两种方式,一种是存在则获取、不存在则返回null的getIfPresent()方法,另一种是读取时传入加载方法的get()方法。
getIfPresent()常配合put()方法,在key不存在时主动查询并调用put()写入;而get()则是较为常规的,没有值则调用传入的加载方法。
2.2 写入

写入也比较简单,分为单个写和批量写。
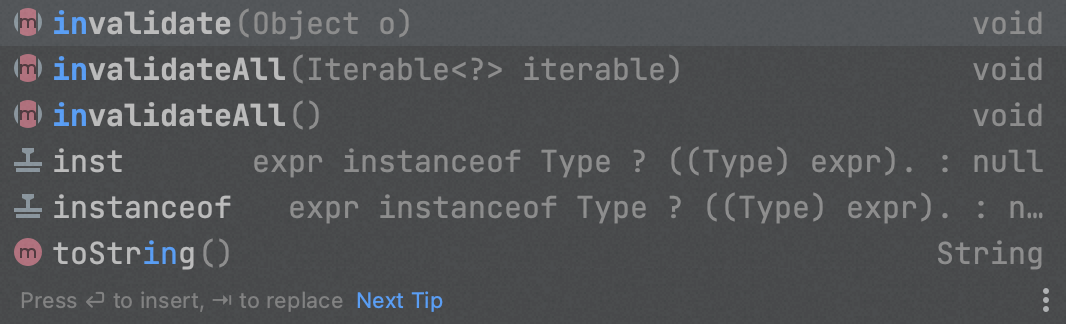
还有立即过期,类似调用HashMap的remove()方法,将key移除。也分为单个过期、批量过期、全部过期。
2.3 如何写入空值
可以看到使用起来确实是非常简单,体感上就是一个普通的HashMap。但试想这样一个问题:有个key本身就不存在,我们还需要让他不断地查询DB吗?没错,就是经典的“缓存穿透”问题。如果这个key在DB中根本不存在,自然没有必要不断去查询,那我们能否将这个空值记录在Cache中?
经过试验,我们得知Guava Cache并不允许写入null,不论是put()方法还是CacheLoader的load()方法,只要返回null立马报错。
实际上这个问题可以巧妙的解决,可以约定一个特殊值,比如字符串“EMPTY_KEY”,每次查询到值后判断是否为这个特殊的字符串,如果是就说明该值在DB中并不存在。但这种方式实在是不优雅,这意味着获取正常的缓存值,也需要加上这个丑陋的判断。
聪明的同学应该已经想到解决方案了,我们可以采用JDK 8提供的新功能:Optional,每次写入缓存不再是这个对象本身,而是一个Optional对象。当load()方法没能查询到值,就写入一个空的Optional对象,在获取时发现缓存的值为null,就说明DB中并不存在该值,接下来该怎么处理怎么处理,这样就能省去一部分无意义的查询。















 6998
6998











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









