






内容是对《Python爬虫开发:从入门到实战》的摘录、理解、代码实践和遇到的问题。
需求分析
从http://www.kanunu8.com/book3/6879爬取《动物农场》所有章节的网址,再通过一个多线程爬虫将每一章的内容爬取下来。在本地创建一个“动物农场”文件夹,并将小说中的每一章分别保存到这个文件夹中。每一章保存为一个文件
代码
import os
import multiprocessing
import requests
import lxml.html
# 获取网页源代码
start_url = 'http://www.kanunu8.com/book3/6879'
source = requests.get(start_url).content.decode('gb2312')
# 使用Xpath提取每一章地址(相对路径)
selector = lxml.html.fromstring(source)
urls = selector.xpath('//tr[@bgcolor="#ffffff"]/td/a/@href')
# 将相对路径拼接成绝对路径
url_list = []
for url in urls:
url_list.append(start_url+'/'+url)
# 使用多线程进行正文爬取
def get_content_and_save(url1):
# 得到每一章页面的源代码,并从中提取出正文部分
source1 = requests.get(url1).content.decode('gbk')
selector1 = lxml.html.fromstring(source1)
content_list = selector1.xpath('//p/text()')
# 用replace()去掉正文里混杂的多余字符’<br />‘
content = ''
for i in content_list:
content = content + i.replace('<br />', '')
# 创建.txt文件并将内容保存到里面
title = selector1.xpath('//font[@color="#dc143c"]/text()')[0]
title = title.replace(' ', '') # 去掉章节字符串中的空格,防止作为.txt文件名时出现错误
os.makedirs('动物庄园', exist_ok=True) # 创建一个名为动物庄园的文件夹用于保存内容,如果已有就不创建了
with open(os.path.join('动物庄园', title+'.txt'), 'w', encoding='utf-8') as f:
f.write(content)
# 多线程提取操作
if __name__=='__main__':
pool = multiprocessing.Pool(5) #使用5个线程同时爬取保存
pool.map(get_content_and_save, url_list)
需要注意的是,在Windows上要想使用进程模块,就必须把有关进程的代码写在if __name__ == ‘__main__’ 内,否则在Windows下使用进程模块会产生异常。Unix/Linux下则不需要。
python 进程池multiprocessing.Pool(44) - 知乎 (zhihu.com)
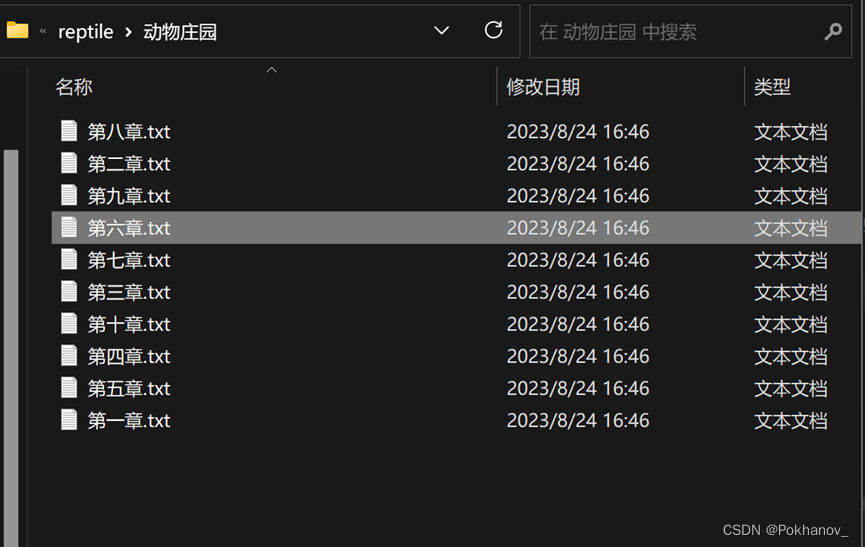
结果
(在项目保存路径下)
















 2200
2200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









