






内容是对《Python深度学习》的摘录、理解、代码实践和遇到的问题。
分类和回归术语表
- 样本sample或输入input:进入模型的数据点。
- 预测prediction或输出output:模型的输出结果。
- 目标target:真实值。(对于外部数据源,模型在理想状况下应该能够预测出目标)
- 预测误差prediction error或损失值loss value:模型预测与目标之间的差距。
- 类别calss:分类问题中可供选择的一组标签。
- 标签label:分类问题中类别标注的具体实例。
- 真实值ground-truth或标注annotation:数据集的所有目标,通常由人工收集。
- 二分类binary classification:一项分类任务,每个输入样本都应该被划分到两个互斥的类别中。
- 多分类multiclass classification:一项分类任务,每个输入样本都应该被划分到两个以上的类别中,比如手写数字分类。
- 标量回归scalar regression:目标是一个连续标量值的任务。预测房价就是一个很好的例子,不同的目标价格形成一个连续空间。
- 向量回归vector regression:目标是一组连续值的任务。如果对多个值(比如图像边界框的坐标)进行回归,那就是向量回归。
- 小批量mini-batch或批量batch:模型同时处理的一小部分样本(样本数通常在8和128之间)。样本数通常取2的幂,这样便于在GPU上分配内存。训练时,小批量用于计算一次梯度下降,以更新模型权重。
二分类问题示例——影评分类
二分类问题是最常见的一类机器学习问题,本例将学习如何根据影评文本将其划分为正面或负面。
IMDB数据集
IMDB数据集包含来自互联网电影数据库IMDB的50 000条严重两极化的评论。数据集被分为25 000条用于训练的评论与25 000条用于测试的评论,训练集和测试集都包含50%的正面评论和50%的负面评论
与MNIST数据集一样,IMDB数据集也内置于Keras库中。它已经经过预处理:评论(单词序列)已被转换为整数序列,其中每个整数对应字典中的某个单词,以便专注于模型的构建、训练与评估。(后面会学习如何从头开始处理原始文本的输入)
# 加载IMDB数据集
from tensorflow.keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
# 参数num_words=10000意为只保留训练数据中前10 000个最常出现的单词,舍弃只在少许样本中出现的、对分类没有意义的低频词,得到便于处理的较小的向量数据
# train_data和test_data都是由评论组成的列表,每条评论又是由单词索引组成的列表(表示单词序列)
# train_labels和test_labels都是由0和1组成的列表,其中0代表负面,1代表正面
# 将评论的单词索引整数列表转换为文本
word_index = imdb.get_word_index() # word_index保存将单词索引为整数的字典
# 将字典的键和值交换,得到由整数索引到单词的字典
reverse_word_index = dict(
[(value, key) for (key, value) in word_index.item()]
)
# 对评论解码,索引减去3是因为0,1,2分别是为"padding"(填充)、"start of sequence"(序列开始)、"unknown"(未知词)保留的索引
decoded_review = "".join(
[reverse_word_index].get(i-3, "?") for i in train_data[0]
)数据处理
不能直接将整数列表传入神经网络,因为整数列表的长度各不相同,但神经网络处理的是大小相同的数据批量。需要将列表转换为张量,转换方式有以下两种:
- 填充列表,使其长度相等,再将列表转换成形状为(samples, max_length)形状的张量,然后在模型第一层使用能处理这种整数张量的层(即Embedding层,会在后面介绍)
- 对列表进行multi-hot编码,将其转换为由0和1组成的向量。举例来说,将序列[8,5]转换成一个10 000维向量,只有索引8和索引5对应的元素是1,其余元素都是0(因为加载数据集时只保留了出现频率前10 000的单词索引,所以索引不会越界)。然后模型第一层可以用Dense层,它能处理浮点数向量数据。
下面采用第二种方法将数据向量化,且为了加深理解,将手动实现这一方法。
import numpy as np
def vectorize_sequences(sequences, dimension = 10000):
results = np.zeros((len(sequences), dimension)) # 创建形状为(len(sequences), dimension)的零矩阵
for i, sequence in enumerate(sequences):
for j in sequence:
results[i, j] = 1. # 将索引对应值设为1
return results
x_train = vectorize_sequences(train_data) # 将训练数据向量化
x_test = vectorize_sequences(test_data) # 将测试数据向量化
y_train = np.asarray(train_labels).astype("float32") # 将标签数据向量化
y_test = np.asarray(test_labels).astype("float32")构建模型
输入数据是向量,而标签是标量(1和0),有一类模型在这种问题上表现良好,即带有relu激活函数的密集链接层Dense的简单堆叠(Sequential)。对于Dense层的这种堆叠,需要做出以下两个关键的架构决策:
- 神经网络有多少层
- 每层有多少个单元
第五章将会介绍作出上述架构决策的具体原则。这里先直接给出:两个中间层,每层16个单元。第三层输出一个标量预测值,代表当前评论的情感类别。
模型架构示意图
# 模型定义
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(16, activation="relu"),
layers.Dense(16, activation="relu"),
layers.Dense(1, activation="sigmoid")
])传入每个Dense层的第一个参数是该层的单元unit个数,即该层表示空间的维数。
而每个带有relu激活函数的Dense层都实现了以下张量运算:
output = relu(dot(input, W) + b)
16个单元对应的权重矩阵W的形状为(input_dimension, 16),与W做点积相当于把输入数据投影到16维表示空间中。可以将表示空间的维度直观理解为“模型学习内部表示时所拥有的自由度”,单元越多(表示空间的纬度越高),模型就能学到越复杂的表示,但同时模型的计算代价也变得更大,并可能导致学到不必要的模式(过拟合)。
中间层使用relu作为激活函数,最后一层使用sigmoid激活函数,以便输出一个介于0和1之间的概率值(表示样本目标值等于“1”的可能性)。relu函数将所有负值归零,sigmoid函数则将任意值“压缩”到[0, 1]区间内,其输出可以看作概率值。
什么是激活函数,为什么要使用激活函数
如果没有像relu这样的激活函数(也叫非线性激活函数),Dense层就只包含点积与加法两个线性运算,这样的层只能学习输入数据的线性变换(仿射变换):该层的假设空间是从输入数据到16维线性空间所有可能的线性变换集合。这种假设空间非常受限,无法利用多个表示层的优势,因为多个线性层堆叠实现的仍是线性运算,增加层数并不会扩展假设空间。
为了得到更丰富的假设空间,从而利用多层表示的优势,需要引入非线性,也就是添加激活函数。relu是深度学习中最常用的激活函数,但也还有许多其他函数可选。
选择损失函数和优化器
当前面对的是一个二分类问题,模型输出的是一个概率值(模型最后一层只有一个单元并使用sigmoid激活函数),所以最好使用binary_crossentropy(二元交叉熵)损失函数。这并不是唯一可行的选择,还可以使用mean_squared_error(均方误差),但对于输出概率值的模型,交叉熵crossentropy通常是最佳选择。交叉熵是一个来自信息论领域的概念,用于衡量分布之间的距离,在这个例子中就是真实分布与预测值之间的距离。
将使用rmsprop作为优化器。对于几乎所有问题,它通常都是很好的默认选择。
优化器写法仍然参考以下博客:
AttributeError: module 'tensorflow_core.keras.optimizers' has no attribute 'rmsprop'
解决 AttributeError: module ‘keras.optimizers‘ has no attribute ‘RMSprop‘ 和‘Adam‘ 报错问题_晓亮.的博客-CSDN博客
原因分析:发现优化器的调用方式发生了改变。
解决方案:
from tensorflow.python.keras.optimizers import rmsprop_v2
使用
optimizer =rmsprop_v2.rmsprop(learning_rate=1e-4)
而不是
optimizer = rmsprop(lr=1e-4) 或 optimizer = RMSprop(lr=1e-4)
model.compile(optimizer=rmsprop_v2.RMSProp(),
loss="binary_crossentropy" ,
metrics=["accuracy"])验证
前面讲到过,深度学习模型不应该在训练数据上进行评估,标准做法是使用验证集来监控训练过程中的模型精度。下面我们将从原始训练数据中留出10 000个样本作为验证集。
# 预留验证集
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]用由512个样本组成的小批量,对模型训练20轮,同时监控在验证集上的损失和精度。
# 训练模型
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val,y_val))调用model.fit()会返回一个History对象,这个对象有一个名为history的成员,它是一个字典,包含训练过程中的全部数据。
history_dict = history.history
print(history_dict.keys())dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
这个字典中包含四个条目,分别对应训练过程和验证过程中监控的指标。
利用Matplotlib绘制训练损失、验证损失、训练精度、验证精度
import matplotlib.pyplot as plt
loss_values = history_dict["loss"]
val_loss_values = history_dict["val_loss"]
epochs = range(1, len(loss_values)+1)
plt.plot(epochs, loss_values, "bo", label="Training loss") # "bo"表示"蓝色圆点"
plt.plot(epochs, val_loss_values, "b", label="Validation loss") # "b"表示"蓝色实线"
plt.title("Training and validation loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend() #添加图例
plt.show()
# 绘制精度变化图像
plt.clf() # 清空图像
acc = history_dict["accuracy"]
val_acc = history_dict["val_accuracy"]
plt.plot(epochs, acc, "bo", label="Training acc")
plt.plot(epochs, val_acc, "b", label="Validation acc")
plt.title("Training and validation accuracy")
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
plt.show()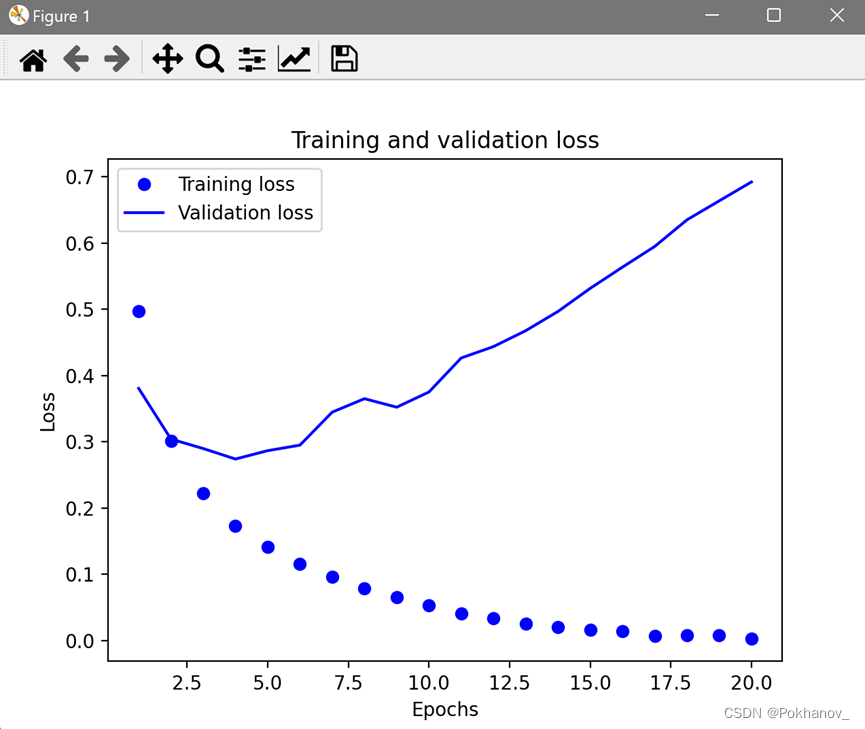
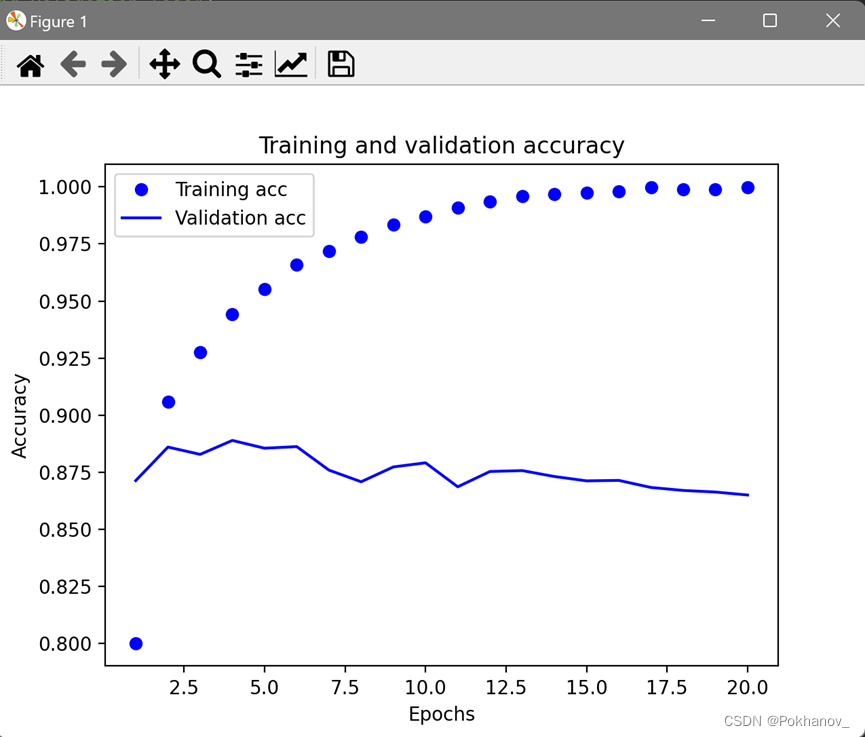
如图所示,训练损失每轮都在减小,训练精度每轮都在提高,这正是梯度下降优化的预期结果。但验证损失和验证精度并非如此,这说明模型在训练数据上表现越来越好的同时,在前所未见的数据上不一定表现得越来越好,这种现象叫作过拟合overfit。具体到本次训练而言,在第4轮之后,模型是在针对训练数据做过度优化,最终学到的表示仅针对训练数据,而无法泛化到训练集以外的数据。
为了防止过拟合,可以在4轮之后停止训练,也有其他多种方式可以降低过拟合,将在第五章介绍。
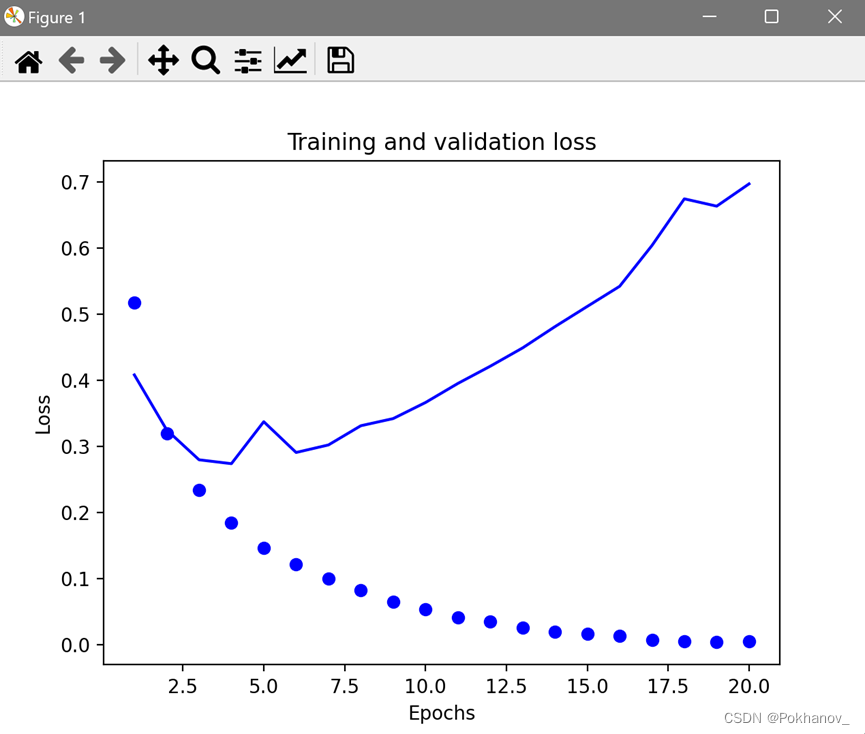
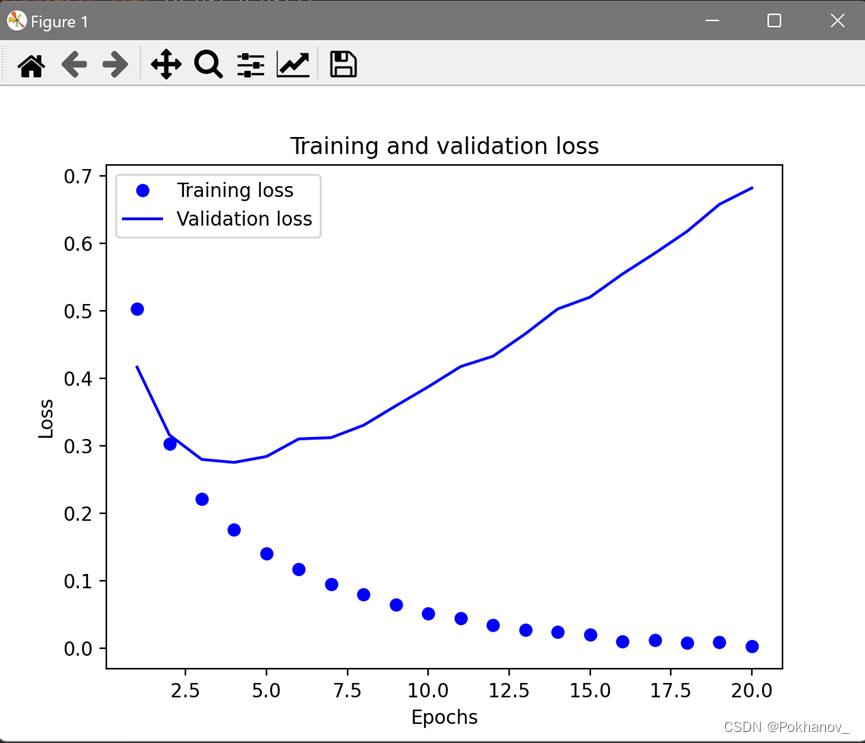
补充:关于legend()
作用是添加图例。
无legend():
有legend():
重新训练数据防止过拟合,并在测试集上评估
model = keras.Sequential([
layers.Dense(16, activation="relu"),
layers.Dense(16, activation="relu"),
layers.Dense(1, activation="sigmoid")
])
model.compile(optimizer=rmsprop_v2.RMSProp(),
loss="binary_crossentropy" ,
metrics=["accuracy"])
history = model.fit(x_train,
y_train,
epochs=4, #根据之前的图像决定只训练4轮防止过拟合
batch_size=512)
# 在测试集上评估
results = model.evaluate(x_test, y_test)loss: 0.3540 - accuracy: 0.8780
可见精度约88%。
利用训练好的模型对新数据进行预测
# 用模型来预测x_test里各评论为正面的可能性并输出
predicts = model.predict(x_test)
print(predicts)[[0.20161915]
[0.9999629 ]
[0.91244537]
...
[0.13068038]
[0.07985511]
[0.6722022 ]]
其中对某些样本的结果非常确信(大于0.99或小于0.01),也对某些样本的结果不那么确信(0.6)
改进方向
- 改变表示层层数:实验过程中在最后的分类层前使用了两个表示层,可以尝试改用一个或三个表示层,观察其对精度的影响。
- 改变损失函数:尝试使用mse损失函数代替binary_crossentropy
- 改变激活函数:尝试使用tanh激活函数(这种激活函数在神经网络早期非常流行)代替relu。
本节要点
- 通常需要对原始数据进行大量预处理,以便将其转换为张量输入到神经网络中。单词序列可以被编码为二进制向量,也有其他编码方式。
- 带有relu激活函数的Dense层堆叠是一种应用范围很广的常见的模型。
- 对于二分类问题,模型的最后一层应该是只有一个单元并使用sigmoid激活函数的Dense层,输出模型是一个0到1的标量,表示概率值。
- 对于二分类问题的sigmoid标量输出,应该使用binary_corssentropy二元交叉熵损失函数。
- 无论面对什么问题,rmsprop优化器通常都是一个足够好的选择,不用改它。
- 随着神经网络在训练数据上的表现越来越好,模型最终会过拟合,并在前所未见的数据上表现越来越差。一定要一直监控模型在训练集之外的数据上的性能。
多分类问题示例——新闻分类
本节将构建一个模型,把路透社新闻划分到46个互斥的主题中。由于有多个类别,因此这是一个多分类multiclass classification问题。
由于每个数据点只能划分到一个类别中,因此更具体地说,这是一个单标签、多分类(single-label, multiclass classification)问题。如果每个数据点可以划分到多个类别中,那就是多标签、多分类(multilabel, multiclass classification)问题。
路透社数据集
路透社数据集包含许多短新闻及其对应的主题,其中包括46个主题。某些主题的样本相对较多,但训练集中的每个主题都至少有10个样本。
路透社数据集也内置于Keras。
# 加载路透社数据集
from tensorflow.keras.datasets import reuters
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=10000)
# 与IMDB数据集一样,参数num_words=10 000将数据限定为前10 000个最常出现的单词与IMDB数据集一样,每个样本都是一个整数列表,表示单词索引。如果好奇可以用与前面解码IMDB数据集一样将样本解码为文本。
样本对应的标签是一个介于0和45之间的整数,即话题索引编号。
准备数据
可以直接沿用IMDB例子中的代码来将数据向量化。
x_train = vectorize_sequences(train_data) # 将训练数据向量化
x_test = vectorize_sequences(test_data) # 将测试数据向量化将标签向量化有两种方法:
- 将标签列表转换为一个整数张量
- one-hot编码。one-hot编码是分类数据的一种常用格式,也叫分类编码categorical encoding。在这个例子中,标签one-hot编码就是将每个标签表示为全零向量,只有标签索引对应的元素为1
def to_one_hot(labels, dimension=46):
results = np.zeros((len(labels), dimension))
for i, label in enumerate(labels):
results[i, label] = 1.
return results
y_train = to_one_hot(train_labels) # 将训练标签向量化
y_test = to_one_hot(test_labels) # 将测试标签向量化Keras有一个内置方法可以实现这种编码
from tensorflow.keras.utils import to_categorical
y_train = to_categorical(train_labels)
y_test = to_categorical(test_labels)构建模型
这个主题分类问题与前面的影评分类问题类似,二者都是对简短的文本片段进行分类。但这个问题有一个新的限制条件:输出类别从2个变成46个,输出空间的维度要大得多。
对于前面使用过的Dense层堆叠,每一层只能访问上一层输出的信息。如果某一层丢失了与分类问题相关的信息,那么后面的层永远无法恢复这些信息,也就是说每一层都可能成为信息瓶颈。上一个例子使用了16维的中间层,但对于这个例子来说,16维太小了,无法学会区分46个类别,这种维度较小的层可能成为信息瓶颈,导致相关信息永久丢失。
因此我们将使用维度更大的层,它包含64个单元
model = keras.Sequential([
layers.Dense(64, activation="relu"),
layers.Dense(64, activation="relu"),
layers.Dense(46, activation="softmax")
])关于这个架构还应注意以下两点
- 模型的最后一层是大小为46的Dense层。也即对于每个输入样本,神经网络都会输出一个46维向量,这个向量的每个元素代表不同的输出类别。
- 最后一层使用了softmax激活函数,模型将输出一个在46个输出类别上的概率分别——对于每个输入样本,模型都会生成一个46维输出向量,其中output[i]是样本属于第i个类别的概率。46个概率值总和为1.
对于这个例子,最好的损失函数是categorical_crossentropy(分类交叉熵),它衡量的是两个概率分布之间的距离,这里两个概率分布分别是模型输出的概率分布和标签的真实距离。我们训练模型将这两个分布的距离最小化,从而让输出结果尽可能接近真实标签。
# 编译模型
from tensorflow.python.keras.optimizers import rmsprop_v2
model.compile(optimizer= rmsprop_v2.RMSProp(),
loss="categorical_crossentropy",
metrics=["accuracy"])验证
# 留出验证集
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = y_train[:1000]
partial_y_train = y_train[1000:]
# 训练模型
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
# 绘制训练损失和验证损失
loss = history.history["loss"]
val_loss = history.history["val_loss"]
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, "bo", label="Training loss")
plt.plot(epochs, val_loss, "b", label="Validation loss")
plt.title("Training and validation loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()
# 绘制训练精度和验证精度
plt.clf() # 清空图像
acc = history.history["accuracy"]
val_acc = history.history["val_accuracy"]
plt.plot(epochs, acc, "bo", label="Training accuracy")
plt.plot(epochs, val_acc, "b", label="Validation accuracy")
plt.title("Training and validation accuracy")
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
plt.show() 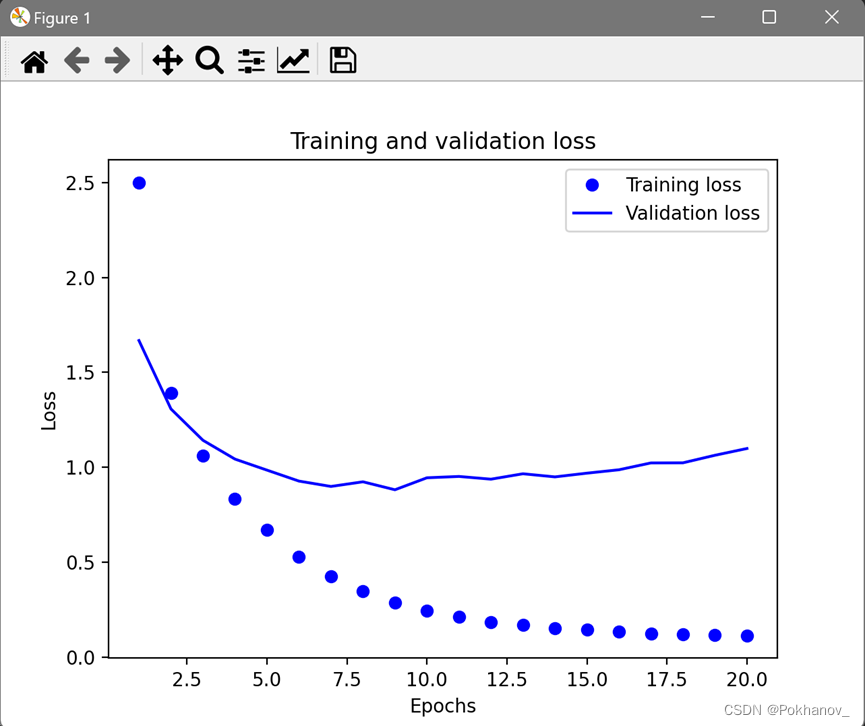
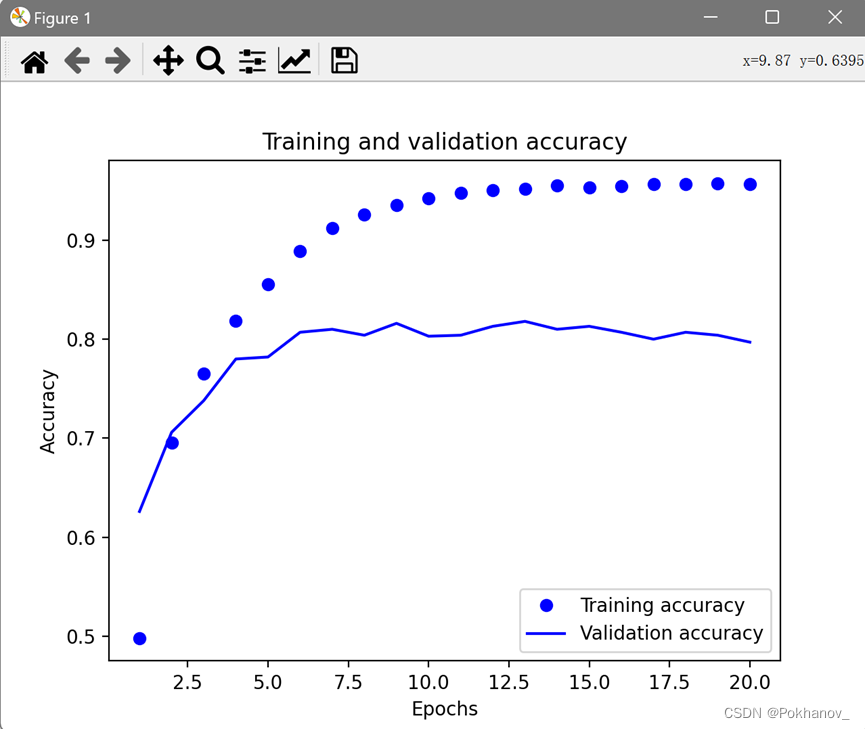
从图可以看出大概在第9轮之后开始过拟合,重新训练一个模型,只训练9轮,并拿到测试集上评估。
history = model.fit(partial_x_train,
partial_y_train,
epochs=9,
batch_size=512,
validation_data=(x_val, y_val))
print(history.history.keys())
results = model.evaluate(x_test, y_test)loss: 1.7710 - accuracy: 0.7854
可见大约可以达到80%的精度
遇到的问题:TypeError: 'module' object is not callable
解决方案:
网上搜索大多给出的原因是模块调用出错,反复修改后发现没用。
其实问题出在编译器写错了
model.compile(optimizer=rmsprop_v2(),正确的写法应该是
model.compile(optimizer=rmsprop_v2.RMSProp(),更改后不再报错。
出现这个报错可以顺便检查一下编译模型部分的写法。
利用模型对新数据进行预测
predictions = model.predict(x_test)predictions的每个元素都是长度为46的向量:
>>predictions[0].shape
(46,)
每个向量的所有元素总和为1,形成概率分布:
>>np.sum(predictions[0])
1.0000001
每个向量中值最大元素的下标就是预测类别,即概率最高类别:
>>np.argmax(predictions[0])
3
处理标签和损失的另一种方法
前面提到过另一种编码标签的方法,也就是将其转换为整数张量,如下:
y_train = np.asarray(train_labels)
y_test = np.asarray(test_labels)对于这种编码方式,唯一需要改变的就是损失函数的选择,对于整数标签,应该使用sparse_categorical_crossentropy(稀疏交叉熵)损失函数,这个损失函数在数学上跟categorical_crossentropy相同,二者只是接口不同。
拥有足够大中间层的重要性
因为最终输出层是46维的,所以中间层的单元应该不少于46个。如果中间层的维度远小于46(比如四维),造成了信息瓶颈,那么会发生什么?
将之前代码的模型构建部分改为:
model = keras.Sequential([
layers.Dense(64, activation="relu"),
layers.Dense(4, activation="relu"),
layers.Dense(46, activation="softmax")
])loss: 2.2128 - accuracy: 0.6460
可见精度明显下降了。导致下降的主要原因在于:我们试图将大量信息压缩到维度过小的中间层,模型能够将大部分必要信息塞进这个4维表示中,但不是全部信息。
本节要点
- 如果要对N个类别的数据点进行分类,那么模型的最后一层应该是大小为N的Dense层。
- 对于单标签、多分类问题,最后一层应使用softmax激活函数,这样可以输出一个在N个输出类别上的概率分布。
- 对于这种问题,损失函数几乎总是应该使用分类交叉熵,它将模型输出的概率分布与目标的真实分布之间的距离最小化。
- 处理多分类问题的标签有两种方法:
- 通过分类编码(one-hot编码)对标签进行编码,然后使用categorical_crossentropy损失函数
- 将标签编码为整数,然后使用sparse_categorical_crossentropy损失函数
- 如果需要将数据划分到多个类别中,那么应该避免使用太小的中间层,以免在模型中造成信息瓶颈。
标量回归问题示例——预测房价
前面两个例子都是分类问题,其目标是预测输入数据点所对应的单一离散标签。另一种常见的机器学习问题是回归regression问题,它预测的是一个连续值,而不是离散的标签,比如根据气象数据预测明天的气温等。
注意:logistic回归算法不是回归算法,而是分类算法。
波士顿房价数据集
# 加载数据集
from tensorflow.keras.datasets import boston_housing
(train_data, train_targets), (test_data, test_targets) = boston_housing.load_data()>>train_data.shape
(404, 13)
>>test_data.shape
(102, 13)
可见有404个训练样本和102个测试样本,每个样本都有13个数值特征,比如人均犯罪率、住宅平均房间数、高速公路可达性等。
>>train_targets[:10]
array([15.2, 42.3, 50. , 21.1, 17.7, 18.5, 11.3, 15.6, 15.6, 14.4])
目标是房价中位数,单位是千美元。
该数据集包含的数据点相对较少。输入数据的每个特征都有不同的取值范围,有的特征是比例,取值在0和1之间;有的取值在1和2之间;有的取值在1和12之间;还有的取值在0和100之间。
准备数据
将取值范围差异很大的数据输入到神经网络中是有问题的,模型虽然可能自动适应这种取值范围不同的数据,但这肯定会让学习变得更加困难。对于这类数据,普遍采用的最佳处理方法是对每个特征进行标准化:对输入数据的每个特征,减去平均值,再除以标准差。这样得到的特征平均值为0,标准差为1。用NumPy可以很容易实现数据标准化。
# 数据标准化
mean = train_data.mean(axis=0)
train_data -= mean
std = train_data.std(axis=0)
train_data /= std
test_data -= mean
test_data /= std注意,标准化过程中平均值和标准差都是在训练数据上计算得到的。在深度学习流程中,不能使用在测试数据上计算得的任何结果,即使是数据标准化这么简单的事也不行。
构建模型
由于样本容量很小,我们将使用一个非常小的模型,因为训练数据越少,过拟合就会越严重,而较小的模型可以降低过拟合。模型包含两个中间层,每层有64个单元。
# 模型定义,因为需要将一个模型多次实例化,所以使用一个函数来构建模型
from tensorflow.keras import layers
from tensorflow.python.keras.optimizers import rmsprop_v2
def build_model():
model = keras.Sequential([
layers.Dense(64, activation="relu"),
layers.Dense(64, activation="relu"),
layers.Dense(1)
])
model.compile(optimizer=rmsprop_v2.RMSProp(),
loss="mse",
metrics=["mea"])
return model模型的最后一层只有一个单元且没有激活,它是一个线性层,这是标量回归的典型设置(标量回归是预测单一连续值的回归)。添加激活函数将限制输出范围,如果向最后一层添加sigmoid激活函数,那么模型只能学会预测0到1的值,这里最后一层是纯线性的,所以模型可以学会预测任意范围的值。
我们编译模型用的是mse损失函数,即均方误差(mean squared error,MSE),预测值与目标值之差的平方。这是回归问题常用的损失函数。
在训练过程中监视的新指标mea是:平均绝对误差(mean absolute error, MAE)。它是预测值与目标值之差的绝对值。
K折交叉验证
由于数据点很少,验证集会非常小(比如大约100个样本),因此验证分数可能会有很大波动,这取决于我们所选择的验证集和训练集,也就是验证分数相对于验证集的划分方式可能会有很大的方差,这样我们就无法对模型进行可靠的评估。
这种情况下,最佳做法是使用K折交叉验证。
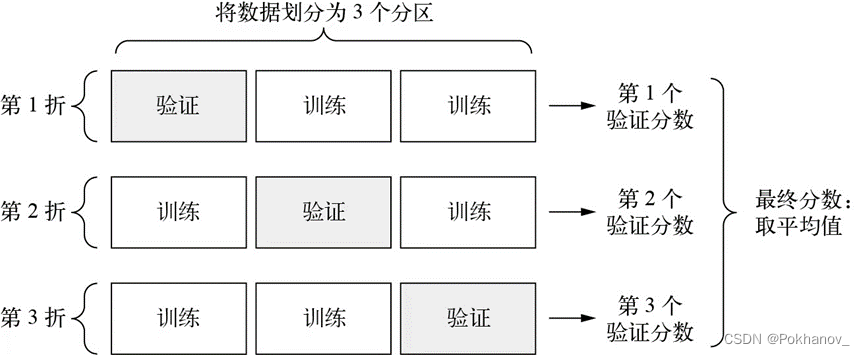
图表 1K折交叉验证(K=3)
这种方法将可用数据划分为K个分区(K通常取4或5),实例化K个相同的模型,然后将每个模型在K-1个分区上训练,并在剩下的一个分区上进行评估。模型的验证分数等于这K个验证分数的平均值。
# K折交叉验证
k = 4
num_val_samples = len(train_data) // k # //在python里是整除
num_epochs = 100 # 训练轮数
all_scores = [] # 用于保存每个验证分数
for i in range(k):
print(f"Processing fold #{i}")
val_data = train_data[i * num_val_samples : (i+1) * num_val_samples] # 拿出第i个分区的数据(作为验证数据)
val_targets = train_targets[i * num_val_samples : (i+1) * num_val_samples] # 拿出相应的目标
# 把其余数据连成一块作为训练数据和目标
partial_train_data = np.concatenate(
[train_data[:i*num_val_samples],
train_data[(i+1)*num_val_samples:]],
axis=0
)
partial_train_targets = np.concatenate(
[train_targets[:i*num_val_samples],
train_targets[(i+1)*num_val_samples:]],
axis=0
)
cur_model = build_model() # 构建模型+编译
cur_model.fit(partial_train_data, partial_train_targets, epochs=num_epochs, batch_size=16, verbose=0) # verbose=0意为静默模式
val_mse, val_mae = cur_model.evaluate(val_data, val_targets, verbose=0) # 在验证数据上评估模型
all_scores.append(val_mae)
print(all_scores)
print(np.mean(all_scores))[1.8917408, 2.6998038, 2.5071568, 2.3199794]
2.3546703
可见每次运行模型得到的验证分数确实有很大差异,从1.9到2.7不等,平均分数(2.35)是比单一分数更可靠的指标,这就是K折交叉验证的核心要点。
遇到的问题:
No module named 'tensorflow_core.estimator'
ModuleNotFoundError: No module named ‘tensorflow_core.estimator‘ 解决办法,已解决,可参考_Photon117的博客-CSDN博客
接下来让模型训练轮数更多一点:500轮。为了记录模型每轮的表现,修改训练循环,在每轮都保存每折的验证分数:
# K折交叉验证
k = 4
num_val_samples = len(train_data) // k # //在python里是整除
num_epochs = 500 # 训练轮数
all_mae_histories = [] # 用于保存每个验证分数
for i in range(k):
print(f"Processing fold #{i}")
val_data = train_data[i * num_val_samples : (i+1) * num_val_samples] # 拿出第i个分区的数据(作为验证数据)
val_targets = train_targets[i * num_val_samples : (i+1) * num_val_samples] # 拿出相应的目标
# 把其余数据连成一块作为训练数据和目标
partial_train_data = np.concatenate(
[train_data[:i*num_val_samples],
train_data[(i+1)*num_val_samples:]],
axis=0
)
partial_train_targets = np.concatenate(
[train_targets[:i*num_val_samples],
train_targets[(i+1)*num_val_samples:]],
axis=0
)
cur_model = build_model() # 构建模型+编译
history = cur_model.fit(partial_train_data, partial_train_targets, validation_data=(val_data, val_targets), epochs=num_epochs, batch_size=16, verbose=0) # verbose=0意为静默模式
mae_history = history.history["val_mae"]
all_mae_histories.append(mae_history)
# 计算每轮所有折MAE的平均值
average_mae_history = [
np.mean([x[i] for x in all_mae_histories]) for i in range(num_epochs)
]
# 绘制MAE曲线
plt.plot(range(1, len(average_mae_history)+1), average_mae_history)
plt.xlabel("Epochs")
plt.ylabel("Validation MAE")
plt.show()计算每轮所有折MAE平均值的部分没太看懂。
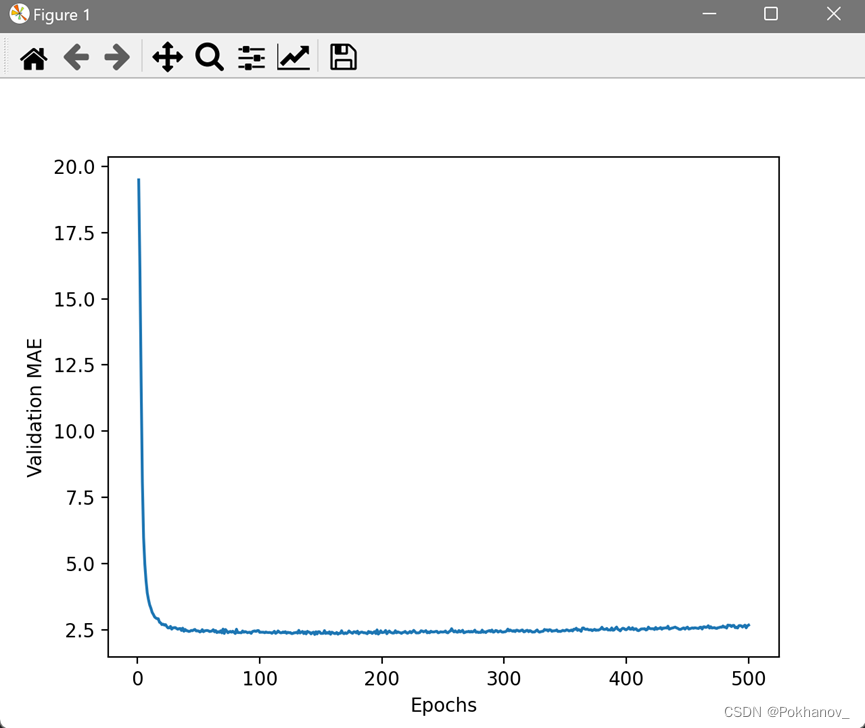
由于比例问题(?),前几轮的验证MAE远大于后面的轮次,很难看清这张图的规律。忽略前十个数据点,因为它们的取值范围与曲线上的其它点不同。
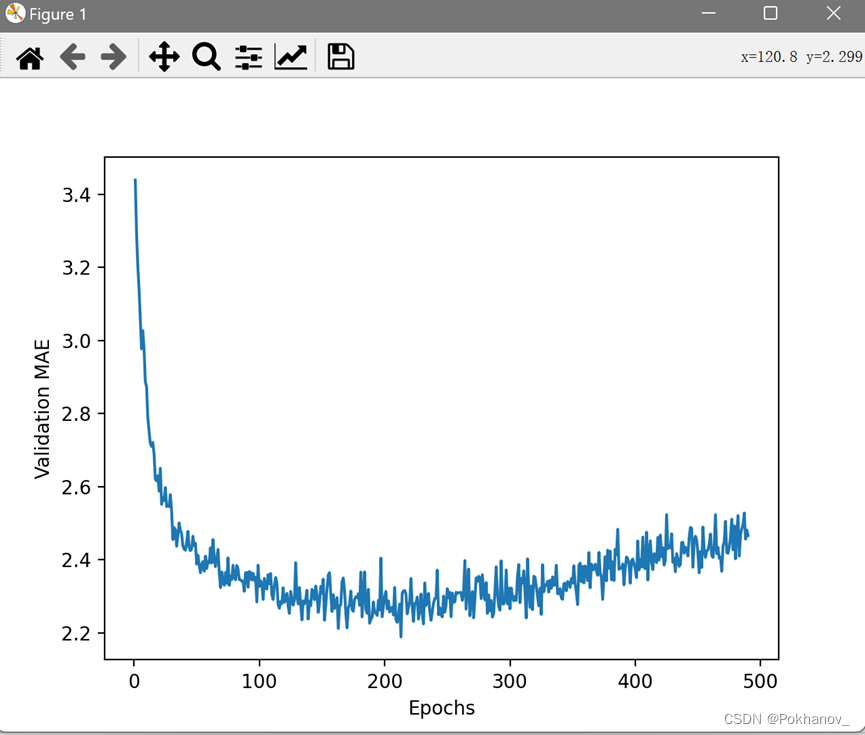
可以看出,验证MAE在x=120左右后不再显著降低(考虑上被舍弃的前10个点,应该是在130轮左右),之后就开始过拟合了,所以确定最终训练模型训练轮数为130.
# 最终训练模型
model = build_model()
model.fit(train_data, train_targets, epochs=130, batch_size=16, verbose=0)
test_mse_score, test_mae_score = model.evaluate(test_data, test_targets)loss: 56.8440 - mae: 2.7692
对新数据进行预测
predictions = model.predict(test_data)
print(predictions[0])
print(test_targets[0])[8.827408]
7.2
本节要点
- 回归问题使用的损失函数与分类问题不同。回归问题常用的损失函数是均方误差(MSE)。
- 回归问题的评估指标也与分类问题不同,精度概念不再适用于回归问题。常用的回归指标是平均绝对误差(MAE)。
- 如果输入数据的特征具有不同的取值范围,那么应该先进行预处理,对每个特征单独进行缩放,标准化到同一取值范围内。
- 如果可用的数据很少,那么K折交叉验证是评估模型的可靠方法。
- 如果可用的训练数据很少,那么最好使用中间层较少(通常只有一两个)的小模型,以避免严重的过拟合。















 575
575











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









