






资源准备
课程链接:2023新版黑马程序员大数据入门到实战教程,大数据开发必会的Hadoop、Hive,云平台实战项目全套一网打尽_哔哩哔哩_bilibili
hadoop 3.1.0百度网盘下载:https://pan.baidu.com/s/1p47t1BNn66T2xNpuBPB1SA 密码: 36nd
jdk 1.8百度网盘下载:https://pan.baidu.com/s/1_e9EyVfxss25jVCL_PtBZw 密码: 7drg
Linux系统:CentOS 7
一、Linux系统设置
1、固定ip
给每台服务器固定一个ip地址,方便控制
修改网卡配置文件
先进入网卡配置文件的目录/etc/sysconfig/network-scripts,每个人的Linux系统的情况可能不同,不能完全按照视频上的来
cd /etc/sysconfig/network-scripts进入到对应目录后,敲入ls命令查看有哪些网卡配置文件,每个网卡都有一个对应的配置文件,以ifcfg-<网卡名称>命名,后面紧跟网卡的名字以便区分
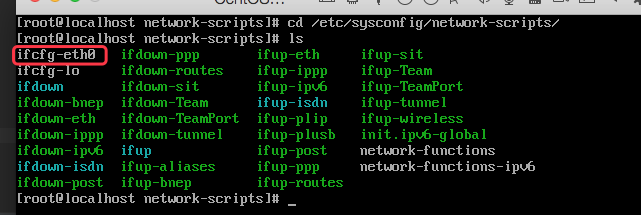
修改网卡配置文件:ifcfg-eth0:
# 编辑网卡配置文件
vim ifcfg-eth0
# 修改或添加以下参数
BOOTPROTO='static' # 协议设置为静态,即固定IP
IPADDR = 192.168.88.101 # 要设置的IP
NETMASK=255.255.255.0 # 子网掩码
GATEWAY=192.168.88.2 # 网关
重启网卡
systemctl stop network
systemctl start network
# 或
systemctl restart network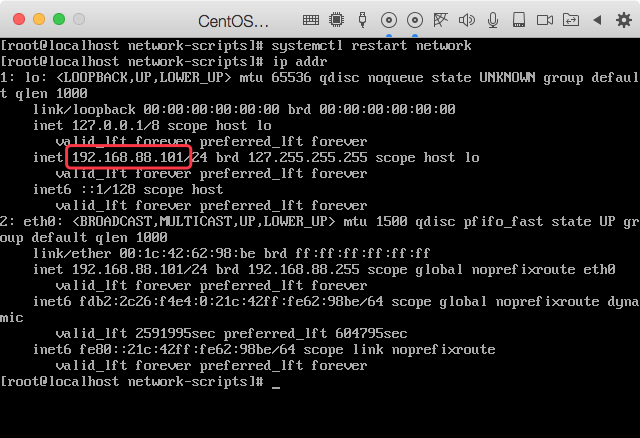
注:这里是为了演示所以IP改成了192.168.88.101,后续我把IP改回192.168.88.3了
2、SSH免密登录
创建ssh秘钥
一路回车到底
ssh-keygen -t rsa -b 4096将ssh秘钥发送到其他服务器
ssh-copy-id <目标服务器IP地址>免密登录其他服务器
ssh <目标服务器IP地址>3、关闭防火墙
集群化软件之间需要通过端口互相通讯,为了避免出现网络不同的问题,我们可以简单的在集群内部关闭防火墙
systemctl stop firewalld # 关闭防火墙
systemctl disable firewalld # 关闭防火墙的开机自启4、关闭SELinux
linux有一个安全模块:SELinux,用以限制用户和程序的相关权限,以确保系统的安全稳定,因为我们当前属于学习过程,只需要将其关闭,避免后续Hadoop运行出现问题
vim /etc/sysconfig/selinux
# 将SELINUX=enforcing改为
SELINUX=disabled
# 保存退出后重启虚拟机,一个字母都不能写错,不然无法启动虚拟机5、时间同步
同步多台linux的时间
# 安装ntp软件
yum install -y ntp
# 更新时区
rm -f /etc/localtime
sudo ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
# 同步时间
ntpdate -u ntp.aliyun.com
# 开启ntp服务并设置开机自启
systemctl start ntpd
systemctl enable ntpd二、安装JDK、Hadoop
1、安装JDK
解压
jdk的安装位置不一定要跟课程上的一样,我将jdk安装在/opt目录下,将安装包放在安装目录下后,解压到当前目录
tar -zxvf jdk-8u371-linux-x64.tar.gz创建软连接
ln -s /opt/jdk1.8.0_371 /opt/jdk配置环境变量
vim /etc/profile
# 在后面追加下面内容
JAVA_HOME=/opt/jdk
PATH=$PATH:$JAVA_HOME/bin
# 使环境变量生效
source /etc/profile配置Java执行程序的软链接
# 删除系统自带的java软链接
rm -f /usr/bin/java
# 软链接自己安装的java程序
ln -s /opt/jdk/bin/java /usr/bin/java验证安装
java -version 
安装成功
2、安装Hadoop
解压
tar -zxvf hadoop-3.1.0.tar.gz创建软连接
ln -s /opt/hadoop-3.1.0 /opt/hadoop配置环境变量
vim /etc/profile
# 在后面追加下面内容
HADOOP_HOME=/opt/hadoop
PATH=$PATH:$HADOOP_HOME/bin
PATH=$PATH:$HADOOP_HOME/sbin
# 使环境变量生效
source /etc/profile三、hdfs部署
1、修改配置文件
配置文件存放位置在hadoop/etc/hadoop/目录下
Hadoop核心配置文件:core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.88.3:8020</value>
<description>hads的网络通信路径</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
<description>io操作文件缓冲区大小</description>
</property>
</configuration>hdfs核心配置文件:hdfs-site.xml
<configuration>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
<description>hdfs文件系统,默认创建的文件权限设置</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
<description>namenode元数据的存储位置</description>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>192.168.88.3,192.168.88.4,192.168.88.5</value>
<description>NameNode允许哪几个节点的DataNode连接</description>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
<description>hdfs默认块大小</description>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
<description>NameNode处理的并发线程数</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
<description>从节点NameNode的数据存储目录</description>
</property>
</configuration>
记得在linux中创建/data/nn目录
配置从节点:workers
192.168.88.3
192.168.88.4
192.168.88.5配置Hadoop相关环境变量:hadoop-env.sh
export JAVA_HOME=/opt/jdk
export HADOOP_HOME=/opt/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs将配置文件分发到其他服务器
scp -r hadoop-3.1.0 192.168.88.4:`pwd`/
scp -r hadoop-3.1.0 192.168.88.5:`pwd`/记得在另外两台服务器上也创建好Hadoop的软链接,并配置环境变量
2、创建普通用户并设置目录权限
由于root用户权限太高,在root用户下启动Hadoop程序并不安全,因此创建一个普通用户hadoop
# 创建用户
useradd hadoop
passwd hadoop
# 设置目录归属和权限
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /opt3、hdfs初始化
在NameNode执行初始化命令
# 切换到hadoop用户
su hadoop
# 执行初始化命令
hadoop -namenode format
/data/nn文件夹出现新文件,表示NameNode初始化完成
4、集群启停
# 启动集群
start-dfs.sh
# 关闭集群
stop-dfs.sh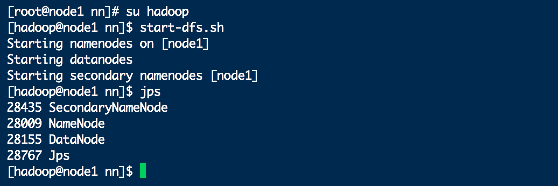
5、查看网页
在浏览器防卫NameNode(即:192.168.88.3)的9870端口,出现如下页面
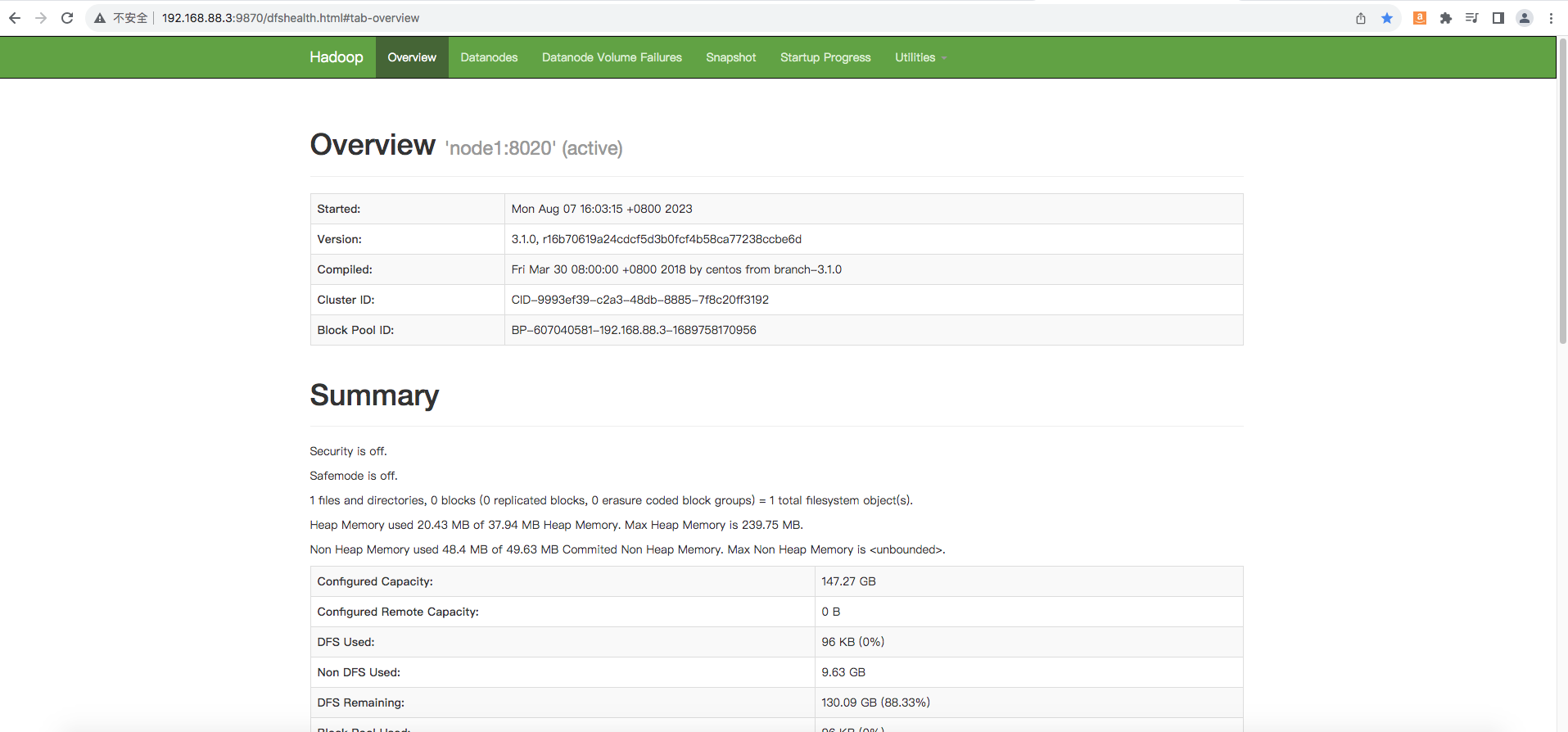
下面这一栏的数字为3(有多少个DataNode节点,数字就为多少,这里有3个DataNode节点),表示DataNode节点也启动成功了
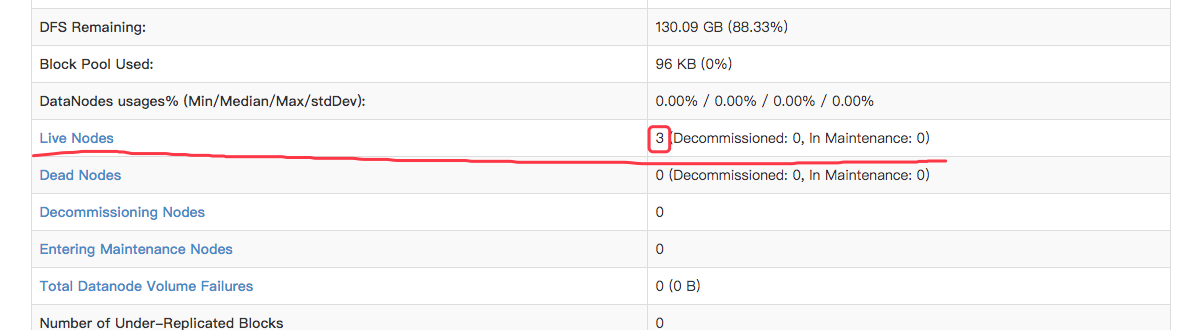
注:如果在操作过程中出现问题导致没法到达这一步,请检查下是否为虚拟机配置出错或没有正确修改配置文件
四、yarn配置
1、修改配置文件
MapReduce环境变量设置:mapred-env.sh
# 设置JDK路径
export JAVA_HOME=/opt/jdk1.8.0_371
# 设置JobHistoryServer进程内存为1G
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
# 设置日志级别为INFO
export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFAMapReduce配置:mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>MapReduce的运行框架设置为YARN</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.88.3:10020</value>
<description>设置历史服务器的通讯端口</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.88.3:19888</value>
<description>设置历史服务器的web端口</description>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/data/mr-history/tmp</value>
<description>历史信息在HDFS的记录临时路径</description>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/data/mr-history/done</value>
<description>历史信息在HDFS的记录路径</description>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description>MapReduce HOME设置为HADOOP_HOME</description>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description>MapReduce HOME设置为HADOOP_HOME</description>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description>MapReduce HOME设置为HADOOP_HOME</description>
</property>
</configuration>YARN环境变量设置:yarn-env.sh
# 设置JDK路径的环境变量
export JAVA_HOME=/opt/jdk
# 设置HADOOP_HOME的环境变量
export HADOOP_HOME=/opt/hadoop
# 设置配置文件路径的环境变量
export hadoop_conf_dir=$HADOOP_HOME/etc/hadoop
# 设置日志文件路径的环境变量
export HADOOP_LOG_DIR=$HADOOP_HOME/logsYARN配置:yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.88.3</value>
<description>ResourceManager设置在192.168.88.3节点</description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/nm-local</value>
<description>NodeManager中间数据本地存储路径</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/nm-log</value>
<description>NodeManager数据日志本地存储路径</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>为MapReduce程序开启Shuffle服务</description>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://192.168.88.3:19888/jobhistory/logs</value>
<description>历史服务器URL</description>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>192.168.88.3:8089</value>
<description>代理服务器主机和端口</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>开启日志聚合</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
<description>程序日志hdfs的存储路径</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description>选择公平调度器</description>
</property>
</configuration>2、启动集群
启动yarn前记得先查看hdfs是否在启动中
# 一键启动yarn集群
start-yarn.sh
# 一键停止yarn集群
stop-yarn.sh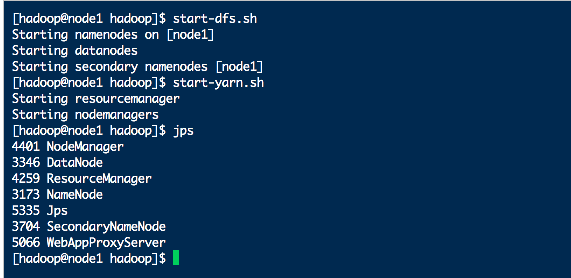
3、查看网页
在浏览器访问ResourceManager的8088端口
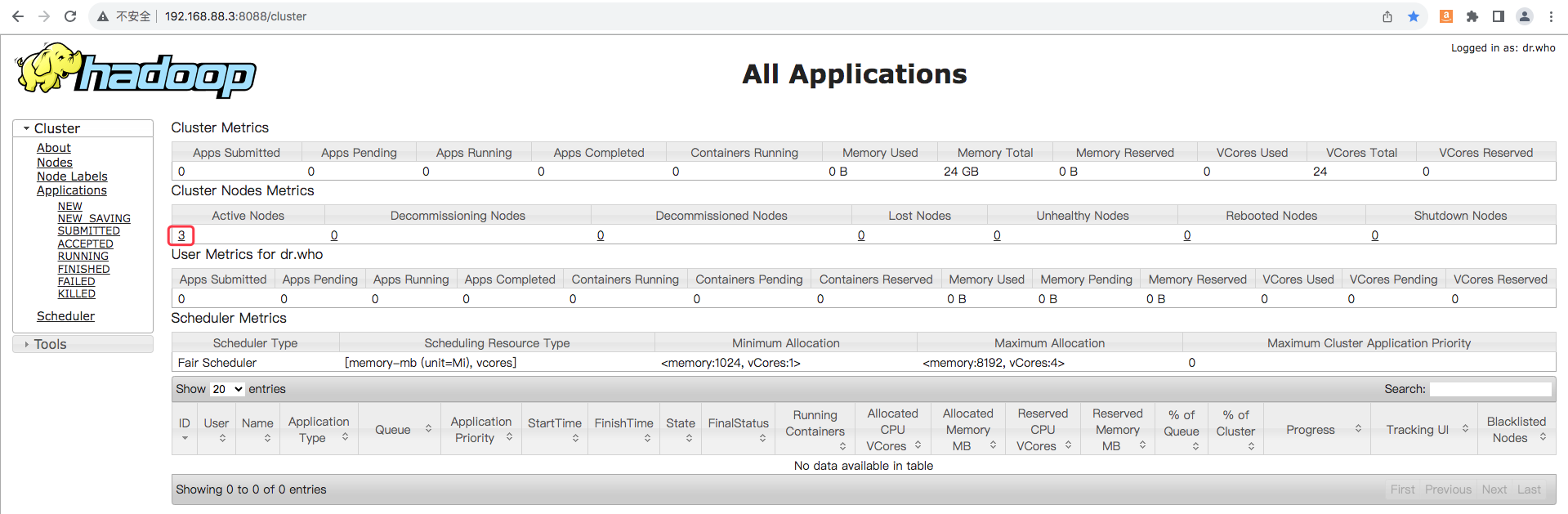
启动成功,如果在部署过程中出现错误,同样检查是否为虚拟机配置出错或没有正确修改配置文件
五、hive部署
(占位)















 595
595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









