







242.有效的字母异位词
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
示例 1: 输入: s = "anagram", t = "nagaram" 输出: true
示例 2: 输入: s = "rat", t = "car" 输出: false
说明: 你可以假设字符串只包含小写字母。
第一种解法:暴力解法
两层for循环,同时还要记录字符是否重复出现,很明显时间复杂度是 O(n^2)。
暴力的方法这里就不做介绍了,直接看一下有没有更优的方式。
第二种解法:哈希表
数组其实就是一个简单哈希表,而且这道题目中字符串只有小写字符,那么就可以定义一个数组,来记录字符串s里字符出现的次数。
如果对哈希表的理论基础关于数组,set,map不了解的话可以看这篇:代码随想录算法| 哈希表先导知识 | 哈希表理论基础-CSDN博客
需要定义一个多大的数组呢,定一个数组叫做record,大小为26就可以了,初始化为0,因为字符a到字符z的ASCII也是26个连续的数值。
需要把字符映射到数组也就是哈希表的索引下标上,因为字符a到字符z的ASCII是26个连续的数值,所以字符a映射为下标0,相应的字符z映射为下标25。
再遍历 字符串s的时候,只需要将 s[i] - ‘a’ 所在的元素做+1 操作即可,并不需要记住字符a的ASCII,只要求出一个相对数值就可以了。 这样就将字符串s中字符出现的次数,统计出来了。
那看一下如何检查字符串t中是否出现了这些字符,同样在遍历字符串t的时候,对t中出现的字符映射哈希表索引上的数值再做-1的操作。
那么最后检查一下,record数组如果有的元素不为零0,说明字符串s和t一定是谁多了字符或者谁少了字符,return false。
最后如果record数组所有元素都为零0,说明字符串s和t是字母异位词,return true。
时间复杂度为O(n),空间上因为定义是的一个常量大小的辅助数组,所以空间复杂度为O(1)。
class Solution {
public boolean isAnagram(String s, String t) {
int[] record = new int[26]; // 26个字母的长度
for (int i = 0; i < s.length(); i++) {
record[s.charAt(i) - 'a']++; // 并不需要记住字符a的ASCII,只要求出一个相对数值就可以了
}
for (int i = 0; i < t.length(); i++) {
record[t.charAt(i) - 'a']--;
}
for (int count: record) {
if (count != 0) { // record数组如果有的元素不为零0,说明字符串s和t 一定是谁多了字符或者谁少了字符。
return false;
}
}
return true; // record数组所有元素都为零0,说明字符串s和t是字母异位词
}
}- 时间复杂度: O(n)
- 空间复杂度: O(1)
349. 两个数组的交集
给定两个数组,编写一个函数来计算它们的交集。
说明: 输出结果中的每个元素一定是唯一的。 我们可以不考虑输出结果的顺序。

这道题目,主要要学会使用一种哈希数据结构:unordered_set,这个数据结构可以解决很多类似的问题。
注意题目特意说明:输出结果中的每个元素一定是唯一的,也就是说输出的结果的去重的, 同时可以不考虑输出结果的顺序
这道题用暴力的解法时间复杂度是O(n^2),那来看看使用哈希法进一步优化。
第一种解法:哈希数组
要注意,使用数组来做哈希的题目,是因为题目都限制了数值的大小。
class Solution {
public int[] intersection(int[] nums1, int[] nums2) {
int[] hash1 = new int[1002]; // 题目限定大小为(1-1000)
int[] hash2 = new int[1002];
// 以元素值为索引存进hash表
for(int i : nums1)
hash1[i]++;
for(int i : nums2)
hash2[i]++;
List<Integer> resList = new ArrayList<>();
// 将两个表中都有的元素写进resList中,加入一个List的意义是为了确定res数组的大小
for(int i = 0; i < 1002; i++)
if(hash1[i] > 0 && hash2[i] > 0)
resList.add(i);
int index = 0;
int res[] = new int[resList.size()];
// 将List转换为数组
for(int i : resList)
res[index++] = i;
return res;
}
}第二种解法:HashSet
如果哈希值比较少、特别分散、跨度非常大,使用数组就造成空间的极大浪费。
此时就要使用另一种结构体了——set ,关于set,C++ 给提供了如下三种可用的数据结构:
- std::set
- std::multiset
- std::unordered_set
std::set和std::multiset底层实现都是红黑树,std::unordered_set的底层实现是哈希表, 使用unordered_set 读写效率是最高的,并不需要对数据进行排序,而且还不要让数据重复,所以选择unordered_set。
代码随想录算法| 哈希表先导知识 | 哈希表理论基础-CSDN博客
思路如图所示:
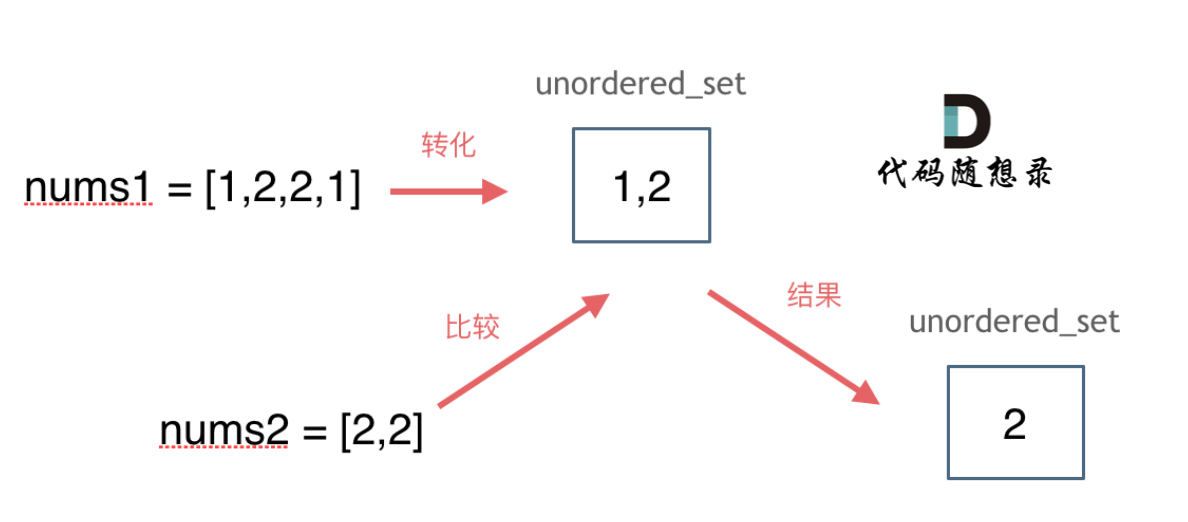
import java.util.HashSet;
import java.util.Set;
class Solution {
public int[] intersection(int[] nums1, int[] nums2) {
if (nums1 == null || nums1.length == 0 || nums2 == null || nums2.length == 0) {
return new int[0];
}
Set<Integer> set1 = new HashSet<>();
Set<Integer> resSet = new HashSet<>();
//遍历数组1
for (int i : nums1) {
set1.add(i);
}
//遍历数组2的过程中判断哈希表中是否存在该元素
for (int i : nums2) {
if (set1.contains(i)) {
resSet.add(i);
}
}
//方法1:将结果集合转为数组
return resSet.stream().mapToInt(x -> x).toArray();
//方法2:另外申请一个数组存放setRes中的元素,最后返回数组
int[] arr = new int[resSet.size()];
int j = 0;
for(int i : resSet){
arr[j++] = i;
}
return arr;
}
}- 时间复杂度: O(n + m) m 是最后要把 set转成vector
- 空间复杂度: O(n)
拓展
那遇到哈希问题我直接都用set不就得了,用什么数组啊。
直接使用set不仅占用空间比数组大,而且速度要比数组慢,set把数值映射到key上都要做hash计算的。
不要小瞧这个耗时,在数据量大的情况,差距是很明显的
第202题. 快乐数
编写一个算法来判断一个数 n 是不是快乐数。
「快乐数」定义为:对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和,然后重复这个过程直到这个数变为 1,也可能是无限循环但始终变不到 1。如果 可以变为 1,那么这个数就是快乐数。
如果 n 是快乐数就返回 True ;不是,则返回 False 。
示例:
输入:19
输出:true
解释:
1^2 + 9^2 = 82
8^2 + 2^2 = 68
6^2 + 8^2 = 100
1^2 + 0^2 + 0^2 = 1
class Solution {
public boolean isHappy(int n) {
Set<Integer> record = new HashSet<>();
while (n != 1 && !record.contains(n)) {
record.add(n);
n = getNextNumber(n);
}
return n == 1;
}
private int getNextNumber(int n) {
int res = 0;
while (n > 0) {
int temp = n % 10;
res += temp * temp;
n = n / 10;
}
return res;
}
}- 时间复杂度: O(logn)
- 空间复杂度: O(logn)
这道题有个需要注意的点就是无法把控n会是几位数,不能依靠/10,/100这种方式取整数位,所以代码这里用了一个while循环:每个循环都处理最后一位数,然后在运算完抛弃最后一位数
两数之和
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍。
示例:
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
很明显暴力的解法是两层for循环查找,时间复杂度是O(n^2)。
第一种解法:哈希表
首先再强调一下 什么时候使用哈希法,当我们需要查询一个元素是否出现过,或者一个元素是否在集合里的时候,就要第一时间想到哈希法。
本题呢,就需要一个集合来存放我们遍历过的元素,然后在遍历数组的时候去询问这个集合,某元素是否遍历过,也就是是否出现在这个集合。
那么就应该想到使用哈希法了。
因为本题不仅要知道元素有没有遍历过,还要知道这个元素对应的下标,需要使用 key value结构来存放,key来存元素,value来存下标,那么使用map正合适。
再来看一下使用数组和set来做哈希法的局限。
- 数组的大小是受限制的,而且如果元素很少,而哈希值太大会造成内存空间的浪费。
- set是一个集合,里面放的元素只能是一个key,而两数之和这道题目,不仅要判断y是否存在而且还要记录y的下标位置,因为要返回x 和 y的下标。所以set 也不能用。
此时就要选择另一种数据结构:map ,map是一种key value的存储结构,可以用key保存数值,用value再保存数值所在的下标。
接下来需要明确两点:
- map用来做什么
- map中key和value分别表示什么
map目的用来存放访问过的元素,因为遍历数组的时候,需要记录之前遍历过哪些元素和对应的下标,这样才能找到与当前元素相匹配的(也就是相加等于target)
接下来是map中key和value分别表示什么。
这道题需要给出一个元素,判断这个元素是否出现过,如果出现过,返回这个元素的下标。
那么判断元素是否出现,这个元素就要作为key,所以数组中的元素作为key,有key对应的就是value,value用来存下标。
所以 map中的存储结构为 {key:数据元素,value:数组元素对应的下标}。
在遍历数组的时候,只需要向map去查询是否有和目前遍历元素匹配的数值,如果有,就找到的匹配对,如果没有,就把目前遍历的元素放进map中,因为map存放的就是我们访问过的元素。
过程如下:
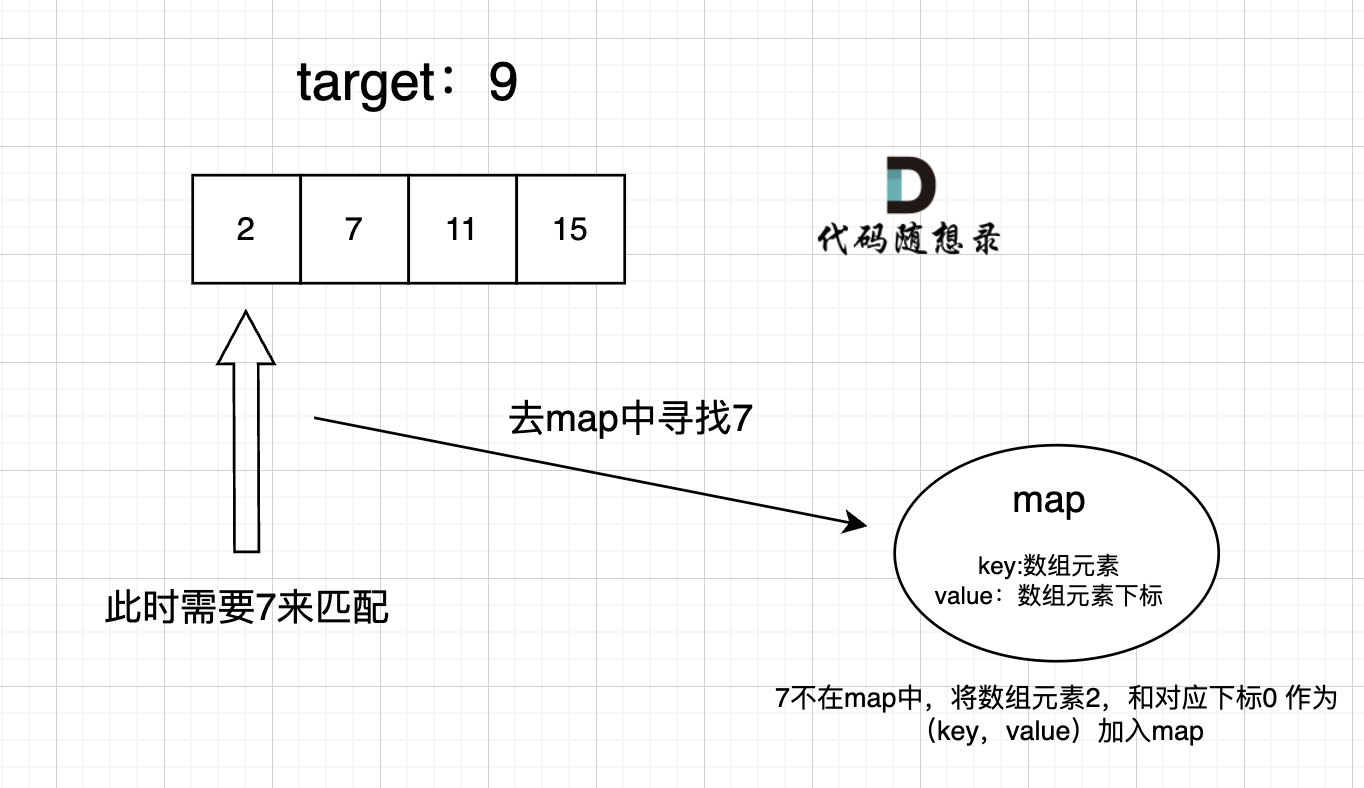
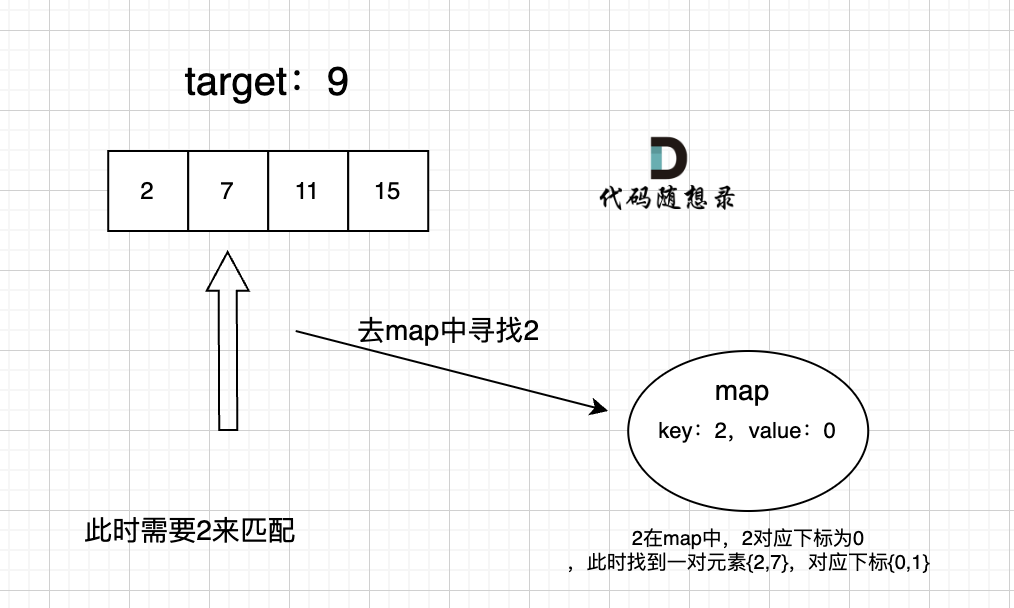
我的解答:
class Solution {
public int[] twoSum(int[] nums, int target) {
Map<Integer, Integer> hashMap = new HashMap<>();
int[] result = new int[2];
for(int i = 0; i < nums.length; i++){
hashMap.put(nums[i], i);
}
for(int num : nums){
int need = target - num;
if(hashMap.containsKey(need)){
result[0] = hashMap.get(num);
result[1] = hashMap.get(need);
}
}
return result;
}
}问题:示例3:[3,3]——>结果[1,1]
原因:一定要先判断再put!!不然像这种存在多元素key相同的时候会导致覆盖,所以出现双1的结果而不是预期的[0,1]
标准答案:
/使用哈希表
public int[] twoSum(int[] nums, int target) {
int[] res = new int[2];
if(nums == null || nums.length == 0){
return res;
}
Map<Integer, Integer> map = new HashMap<>();
for(int i = 0; i < nums.length; i++){
int temp = target - nums[i]; // 遍历当前元素,并在map中寻找是否有匹配的key
if(map.containsKey(temp)){
res[1] = i;
res[0] = map.get(temp);
break;
}
map.put(nums[i], i); // 如果没找到匹配对,就把访问过的元素和下标加入到map中
}
return res;
}- 时间复杂度: O(n)
- 空间复杂度: O(n)
总结
本题其实有四个重点:
- 为什么会想到用哈希表
- 哈希表为什么用map
- 本题map是用来存什么的
- map中的key和value用来存什么的
把这四点想清楚了,本题才算是理解透彻了。
第二种解法:双指针法
思路:copy一份数组之后把数组按照从小到大排序,定义两个下标,一个下标指向数组的头,一个下标指向数组的尾:
1、如果两个数组相加 < target,则说明i不够大,所以进行i++操作
2、如果两个数组相加 > target,则说明j不够小,所以进行j--操作
//使用双指针
public int[] twoSum(int[] nums, int target) {
int m=0,n=0,k,board=0;
int[] res=new int[2];
int[] tmp1=new int[nums.length];
//备份原本下标的nums数组
System.arraycopy(nums,0,tmp1,0,nums.length);
//将nums排序
Arrays.sort(nums);
//双指针
for(int i=0,j=nums.length-1;i<j;){
if(nums[i]+nums[j]<target)
i++;
else if(nums[i]+nums[j]>target)
j--;
else if(nums[i]+nums[j]==target){
m=i;
n=j;
break;
}
}
//找到nums[m]在tmp1数组中的下标
for(k=0;k<nums.length;k++){
if(tmp1[k]==nums[m]){
res[0]=k;
break;
}
}
//找到nums[n]在tmp1数组中的下标
for(int i=0;i<nums.length;i++){
if(tmp1[i]==nums[n]&&i!=k)
res[1]=i;
}
return res;
}














 155
155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









