







urllib模块
抓取网络上的url资源。
实例一(访问网址并保存本地)
实例代码 (默认网址使用www.baidu.com)
from urllib.request import urlopen # 在urllib.request调用urlopen
url = 'http://www.baidu.com' # 输入网址
res = urlopen(url) # 如游览器打开网址,并返回响应的结果
a = res.read() # 读取响应里面的内容
print(res)
with open('a.html',mode='wb') as f: # 打开a.html这个文件,wb表示写入二进制文件。
f.write(res.read()) # 将响应的内容写进去如果没有a.html就会在本地生成。打开a.html就会发现响应的内容被写进来了。
实例二(解析url)
该功能用到模块urllib.parse,实现代码
from urllib.parse import urlparse
res = urlparse('http://www.baidu.com:80/index.html?id=100') # 对这一个url进行解析
print(type(res)) # 返回res的类型,为class
print(res.scheme) # scheme为url的协议,在这里是http
print(res.netloc) # netloc为域名和端口
print(res.path) # path为路径
print(res.query) # 查询字符串,指路径后面,id=100看运行结果为
requests模块
作用和urllib模块差不多,但比urllib模块方便。
实例一(爬取58同城相关python的招聘信息)
示例代码
import re
import requests
# requests模块获取数据
# re模块筛选数据
url = 'https://bj.58.com/job/'
data = { # 写要传入的参数,一般用字典的形式
'key':'python', # 这样就相当于
'final':1, # https://bj.58.com/job/?key=python&final=1&jump=1
'jump':1 # 哪种形式都可以
}
result = requests.get(url,params=data) # 添加参数访问
print(result) # 获取响应头和状态码200
html = result.content.decode("utf-8") # 对响应包的内容进行解码
print(html)
pat = '<span class="address">(.*?)</span> \| <span class="name">(.*?)</span>' # 编写正则表达式,筛选我们需要的信息
what = re.findall(pat,html) # 对响应的内容进行检索,并提取出来
print(len(what)) # 打印我们需要信息的长度
for item in what: # 遍历输出
print(item[0]+":"+item[1])但是在实验过程中行不通,可能不让爬了吧。
例题
速度要快
f12得到提示,找响应包。
出现了base64加密,拿去解密。
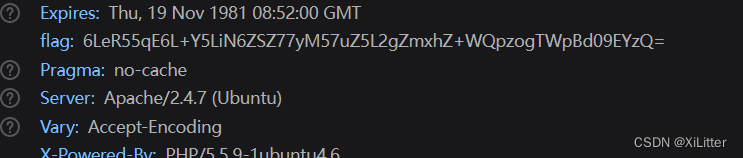
这个需要两次解码得到。密码为200878
但是直接用hackbar进行post传参出不来flag。经过尝试发现flag字段是不断变化的。

![]()
很明显了,flag字段的值一直在变化,所以我们要写一个脚本。
import requests
import base64
url = "http://114.67.175.224:13868/" # 创建一个session对象,它能够让我们跨http请求保持某些参数,爬虫和提交参数都需要
res = requests.Session() # 使用同一个session对象,为了保持flag键值对不发生变化。
header = res.get(url).headers # 获取响应头
str = base64.b64decode(header['flag']) # 在响应头里找到键名为flag的键值对,并返回键值
str = str.decode() # 注意:b64decode处理后的对象是byte类型的字符串,而split需要str类型的字符串,所以要转换一下。
str1 = base64.b64decode(str.split(":")[1]) # 第一次解码后结果为一段文字:base64编码
data = { # 用split函数以:分割为两部分,取第二部分再次进行base64编码
'margin':str1 # 编写post数据
}
flag = res.post("http://114.67.175.224:13868/",data = data) # 发送post数据包
print(flag.text)秋名山老司机
同样是一个编写脚本的题目。不断刷新页面会出现提示。

post传递一个value参数。两秒算出这么大的数根本不可能,用爬虫将网页内容爬取出来。然后用正则表达式提取出算式,用python算,岂不妙哉。
import requests
import re # 正则标准库
s = requests.Session() # 创建session对象
r = s.get("http://114.67.175.224:13816/") # 把网页爬下来
exp = re.search(r'(\d+[+\-*])+(\d+)', r.text) # 正则匹配出算式,数字在div标签里,也可以<div>(.*?)</div>匹配
value = eval(str(exp.group())) # group()把匹配的数据整合在一起,eval函数执行一个字符串表达式,所以要用str进行转化。
data = { # 再用eval执行算数命令
"value": value # 编写post数据
}
r = s.post("http://114.67.175.224:13816/", data = data) # 获取响应结果
print(r.text) # 打印结语
这只是学习python脚本的开始,这次练习仅仅是在实操中认识到了脚本是一个什么东西。想要充分玩好脚本还得继续努力。
















 4539
4539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











