






DOM-DIFF
React16及以前:新老虚拟DOM进行比对
React17及以后:老的DOM会构建出Fiber链表,拿最新创建的虚拟DOM和Fiber链表比对。
优化原则
-
深度优先原则
-
同级比对
*:初次创建虚拟DOM,直接转换为真实DOM,并且构建原则采样深度优先遍历,如图。当更新的时候,又会创建新的虚拟DOM进行比对,新旧虚拟DOM之间只能同级比对。不能跨级。但是这样子会带来一个问题:如右图,新的虚拟DOM仅仅是多了一层结构,ui及其子元素没有任何改变。但是在旧虚拟DOM中,红色的ul只能和蓝色的新虚拟DOM的div进行比对,两次比对不一样,会销毁就的虚拟dom创建新的。这样子会大大增加性能消耗。因此我们在更新的时候,应该尽可能的保持层级结构不变。
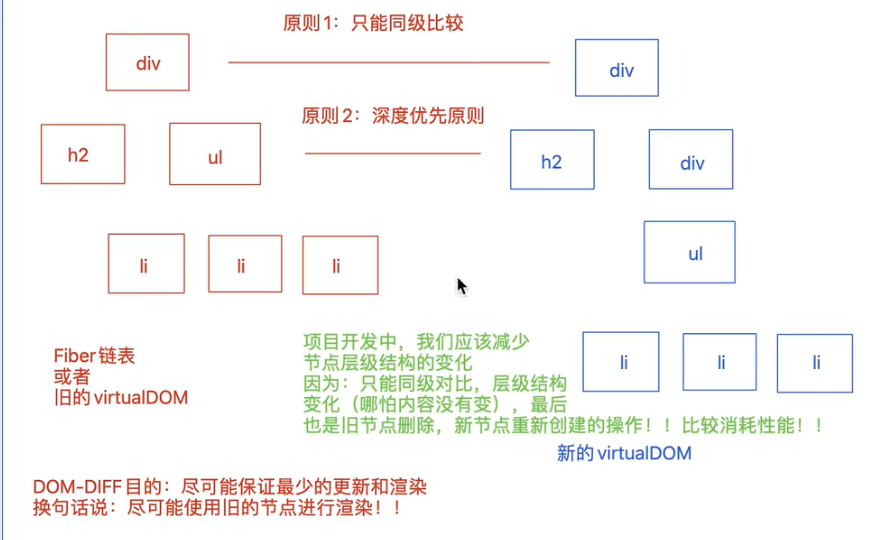
-
不同类型的元素,会产出不同的结构,销毁老结构,创建新结构
-
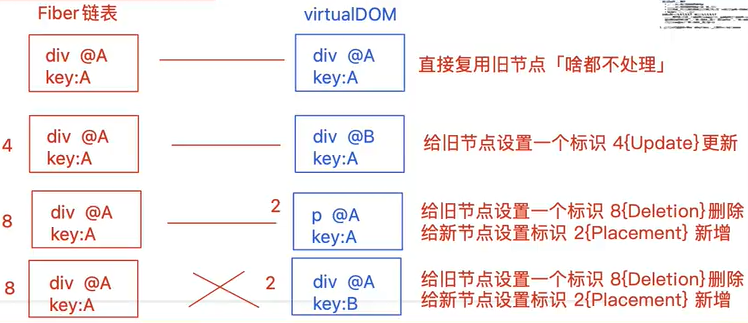
可以通过key表示移动元素,如果不设置key,则默认元素的索引就是key
*:key和类型相同,但是内容不同:更新且复用老的节点==>Update(4)做标识
*:key和类型只要有一个不匹配:都是删除旧的节点==>Deletion(8),插入新的节点==>Placement(2)。
*:还有一种可能是位置改变的情况:插入并更新,摞动位置==>PlacementAndUpdate(6)

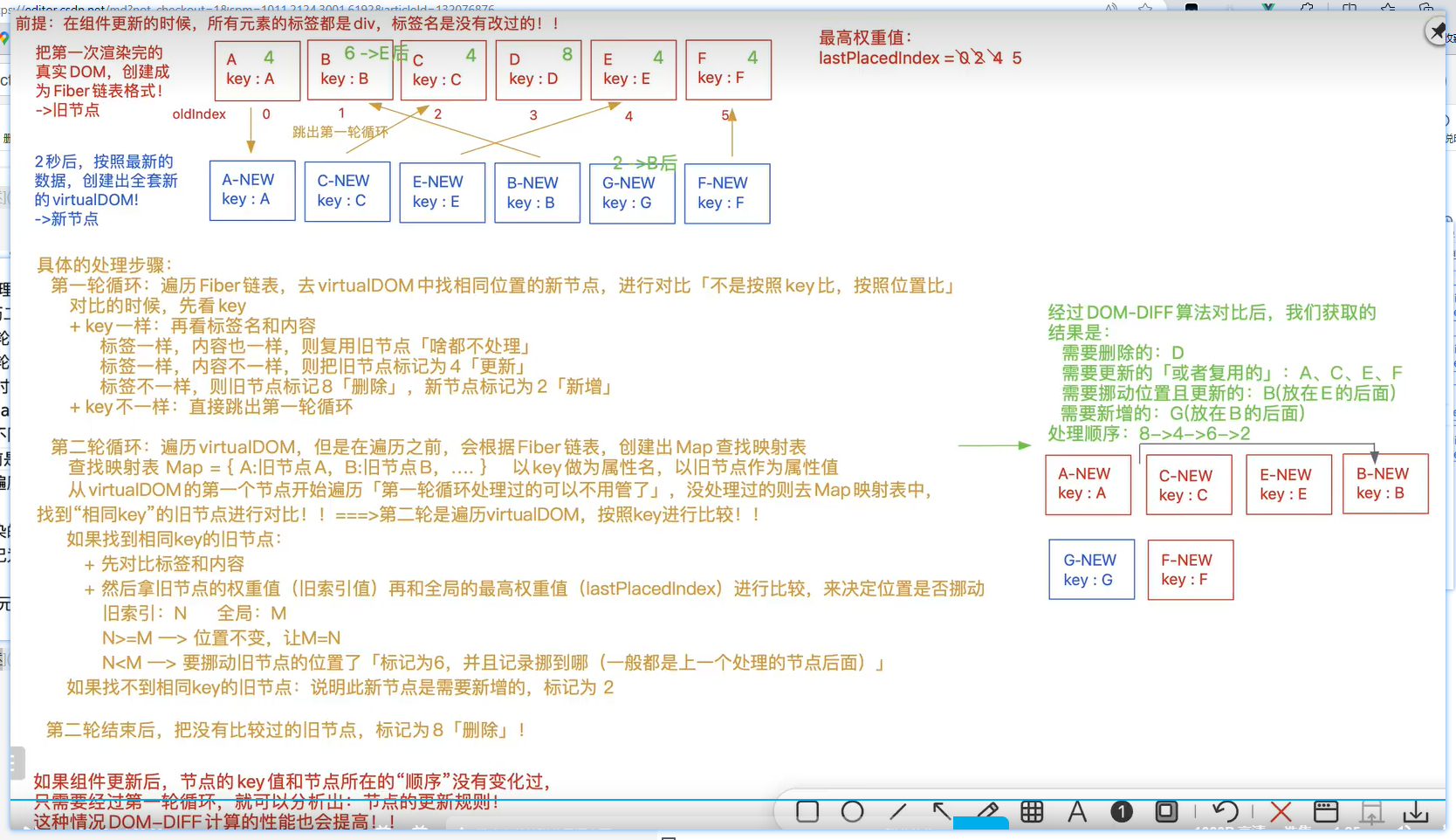
执行过程:在第一次执行的时候,会遍历旧的虚拟DOM部分,即Fiber链表,第一轮循环,会先去新的虚拟DOM中根据位置,查看相同位置上的节点信息。如旧的虚拟DOM A根据位置找到了第一个新的虚拟DOM A,然后比较key值是否一样,然后在比较元素是否一致,这里都是DIV。都没有变化,那么比较内容,这里内容改变了,因此给旧虚拟DOM做标记 4 ,为复用元素做准备。然后开始第二个虚拟DOM B,匹配相同位置的新的虚拟DOM, 比较key值发现不一样,直接退出第一轮循序。开启第二轮循环比较。 在第二轮循环比较的时候,会先根据Fiber链表,创建一个Map结构的映射表,在该映射表中,将旧的虚拟DOM中的key值作为属性,旧节点(真实DOM)作为属性值保存。然后根据新的虚拟DOM进行比较,第一个新节点(这里统一是新的虚拟DOM)A会去Map结构中查找,根据key值找到了其值,但是如果在之前就做过标记处理的,这里会直接跳过不进行处理。比如旧节点A。进行第二个新节点的匹配,新节点C会根据map结构去匹配,找到了旧节点C,key值和元素类型一致,只有内容不同,打上标记 4,然后会进行权重比较:图中oldindex是每一个旧节点的位置,也是权重信息。然后还有一个全局权重lastPlaceIndex,初始为0。打上标记后,会将旧节点对应的权重oldindex=2和全局权重lastPlaceIndex=0进行比较,发现大于全局权重,则不进行移位处理。同时将全局权重修改为当前节点的权重,结束当前元素的比较。第三个元素开始,新节点E去map中匹配,情况和上一个一致,只是内容改变,打上标记 4,然后进行权重比较,当前元素权重oldindex=4大于全局权重lastPlaceIndex=2,不进行移位处理,将全局权重修改为4。第四次比较,新节点B区匹配,也是只有内容不同,打上表示4,但是做权重比较的时候。oldIndex=1小于lastPlaceIndex=4,因此需要做移位处理,再次打上移位标识2,因此该元素最终的标识为6。并且移位通常都是放在上一个处理完的元素后面,即将旧节点B移动到旧节点E后面。第五个比较,新节点G去map中匹配,没有匹配到,因此需要新增该元素。打上标识2,移位到上一个处理完的元素后面即B。第六个元素比较,新节点F去map中匹配,内容改变,打上4标识,当前权重oldIndex=5大于全局权重lastPlaceIndex=4,不做移位处理,全局权重修改为5。然后旧节点中没有做标识的统一打上删除标识8,即旧节点D做删除标识,代表删除该节点,最终结束。
最终,根据标识,先删除为8的,即将D节点删除。然后执行标记为4的,代表节点内容更新(更新旧节点的内容,非创建新节点处理),然后执行标记为6的,代表移动元素和更新。最后执行标记为2的,代表新增。处理顺序:8>4>6>2
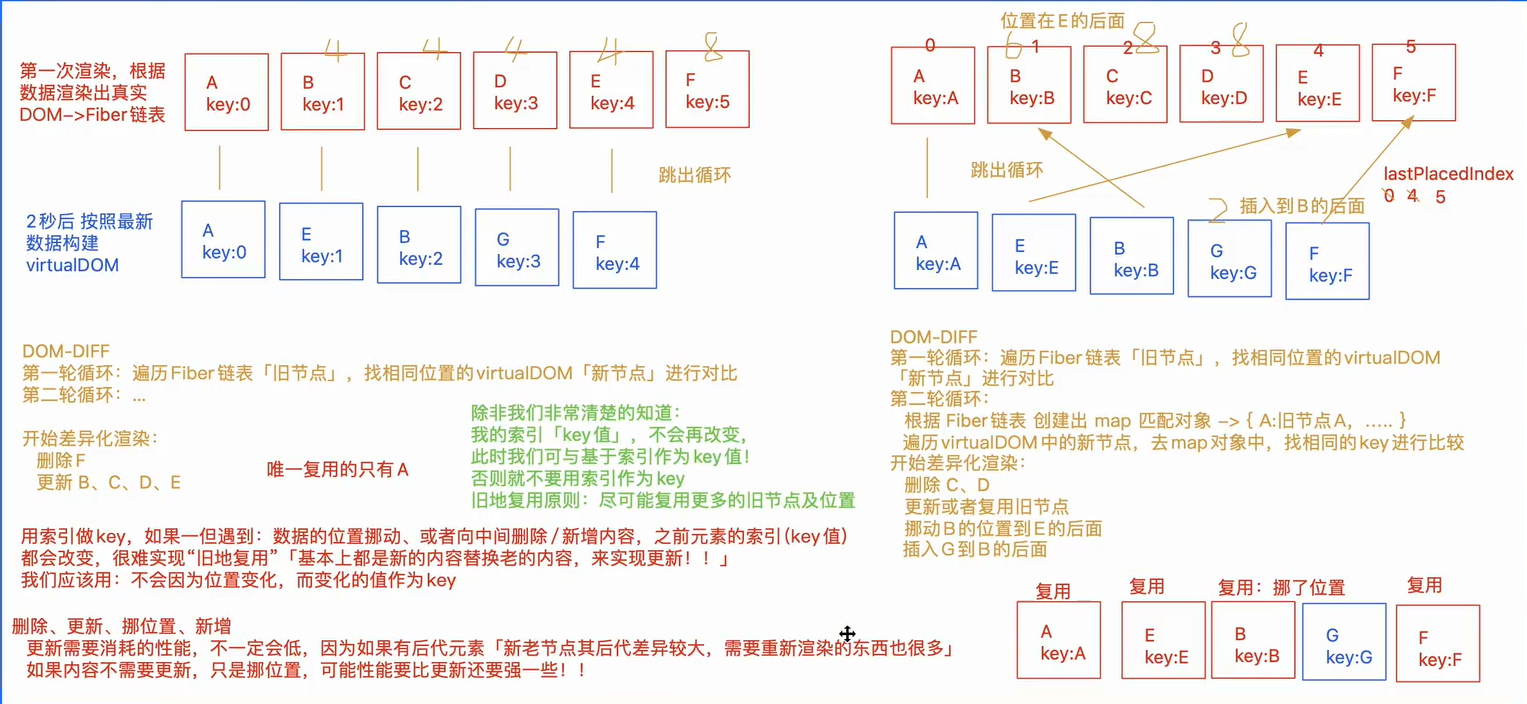
关于key值的有关细节
循环创建的元素,都需要绑定一个key值,尽可能的避免将索引直接作为key的值,应该使用一个不会因为位置或索引改变而改变的值作为key。如果使用索引作为key值,那么应该尽可能的避免更新后,元素的位置发生变化,如移位,删除,新增等。这些都有可能造成大量性能消耗。
Iterator迭代器和Generator生成器
Iterator迭代器
遍历器(Iterator)是一种机制(接口):为各种不同的数据结构提供统一的访问机制,任何数据结构只要部署Iterator接口,就可以完成遍历操作「for of循环」,依次处理该数据结构的所有成员。
一个Iterator接口必须包含一下条件
- 拥有
next方法用于依次遍历数据结构的成员 - 每一次遍历返回的结果是一个对象
{done:false,value:xxx} done:记录是否遍历完成,为false代表未遍历完成,true代表遍历结束value:当前遍历的结果,当遍历结束的时候,值为undefined。
*符合以上两个条件的称之为符合迭代器规范的对象
以下是大致思想
class Iterator {
constructor(assemble) {
this.assemble = assemble
this.index = -1
}
next() {
this.index++
let { assemble, index } = this
if (index >= assemble.length) { //迭代完成返回
return {
done: true,
value: undefined
}
}
return {
done: false,
value: assemble[index]
}
}
}
let itor = new Iterator([1, 2, 3, 4])
// itor必须包含next方法
console.log(itor.next()) // {done:false,value:1}
console.log(itor.next()) // {done:false,value:2}
console.log(itor.next()) // {done:false,value:3}
console.log(itor.next()) // {done:false,value:4}
console.log(itor.next()) // {done:true,value:undefined}
凡是数据结构符合Iterator规范,就可以使用for/of循环。凡是符合迭代器规范的,都具有Symbol(Symbol.iterator)属性。
常见符合Iterator规范的数据结构
- 数组,其原型存在
Symbol(Symbol.iterator)属性,其值是一个函数 - 字符串,
String类型的原型上也具备Symbol(Symbol.iterator)属性,值是一个函数 - 类数组(伪数组):函数的剩余参数,NodeList节点集合,HTMLCollection元素集合身上都具备
Symbol(Symbol.iterator) - Set/Map结构
但是对于纯粹对象(原型直接指向Object)或自己构建的类数组对象,默认都不具备Iterator规范,所以没有Symbol(Symbol.iterator),因此不能使用for/of循环。 如果想让一个对象使用for/of循环,那么我们可以修改其结构使符合Iterator规范。
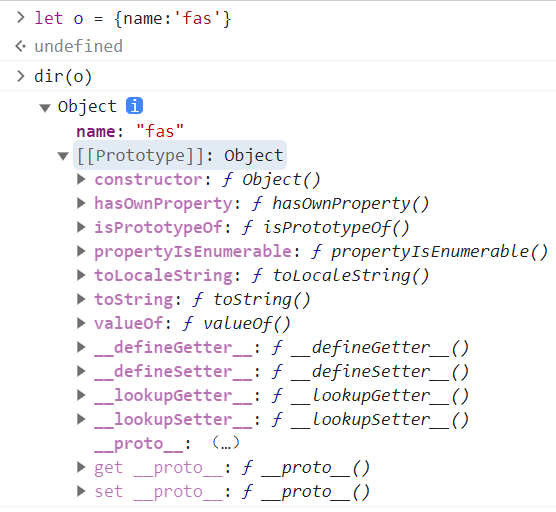
以下是自己构建的类数组对象
for/of原理
数组常见的迭代方式:for,while,forEach/map,for/of,for/in(数组属于对象)等。但是对象不能反过来使用for/of
let arr = [1, 2, 3]
for (let val of arr) { //每次循环执行,就是在执行next方法
console.log(val );
}
原理:迭代执行,执行数组的Symbol.iterator方法,该方法返回一个符合Iterator规范的对象,因此具备next方法,这里命名为itor。开始迭代,将itor.next方法执行,该方法会返回一个结果:{done:false,value:值}。然后会将value值赋值给for/of循环中定义的val属性,即当前数组的元素值。同时根据done的值决定循环的结束条件。
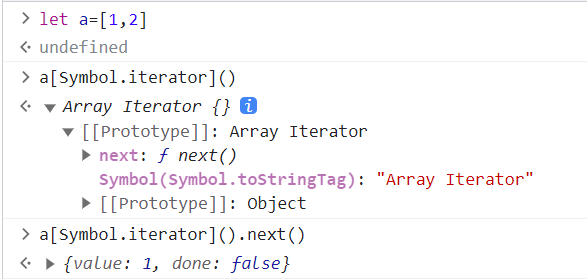
那么开始重写这个Symbol.iterator方法。下面是一个验证for/of循环会去执行Symbol.iterator方法的例子
let arr = [1, 2, 3]
// 重写Symbol.iterator方法
arr[Symbol.iterator] = function () {
console.log('Symbol.iterator重写');
console.log(this) //需要用到this,这里输出查看,谁调用指向谁,这里调用类似arr.Symbol.iterator。this=arr
}
for (let i of arr) {
console.log(i);
}

以下是完整的重写代码
let arr = [1, 2, 3]
// 重写Symbol.iterator方法
arr[Symbol.iterator] = function () {
console.log('Symbol.iterator重写');
console.log(this)
let self = this
self.index = -1
return {
next() {
self.index++
if (self.index >= self.length) {
return {
done: true,
value: undefined
}
}
return {
done: false,
value: self[self.index]
}
}
}
}
for (let val of arr) {
console.log(val);
}

纯粹对象如何使用for/of循环
那么一个常见的对象如何遍历。可以使用for/in,循环获取键遍历。重点是一个纯粹对象默认是没有设置Iterator规范的,因此无法使用for/of遍历。那么我们可以手动设置对象符合Iterator规范。
let obj = {
name: '张三',
age: 13,
0: 100,
[Symbol('AA')]: 200
}
Object.prototype[Symbol.iterator] = function () {
// 对象遍历本质是获取key
let self = this //this指向obj
let keys = Reflect.ownKeys(self) //获取所有私有属性,包括Symbol类型.['0', 'name', 'age', Symbol(AA)]
let index = -1
return {
next() {
index++
if (index >= keys.length) {
return {
done: true,
value: undefined
}
}
return {
done: false,
value: self[keys[index]]
}
}
}
}
for (let val of obj) {
console.log(val);
}

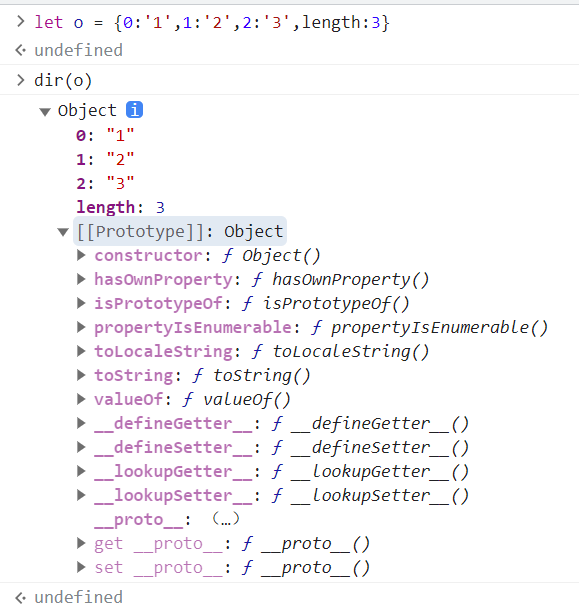
那么一个自定义的类数组对象如何使用for/of遍历,处理方式很简单。(自定义的类数组对象默认没有设置Iterator规范)
let obj = {
0: '张三',
1: '王五',
2: '爱迪',
length: 3
}
// 自定义类数组,可以理解为数组,处理方式和数组一样,使用下标遍历。那么就可以直接服用Array原型的Symbol.iterator方法处理
obj[Symbol.iterator] = Array.prototype[Symbol.iterator]
for (let val of obj) {
console.log(val);
}

创建数组遍历方法的时间消耗
let arr = new Array(999999).fill(undefined)
console.time('for')
for (let i = 0; i < arr.length; i++) { }
console.timeEnd('for')
console.time('while')
let i = 0
while (i < arr.length) {
i++
}
console.timeEnd('while')
console.time('forEach')
arr.forEach((i) => { })
console.timeEnd('forEach')
console.time('for-of')
for (let i of arr) {
}
console.timeEnd('for-of')
console.time('for-in')
for (let i in arr) { }
console.timeEnd('for-in')
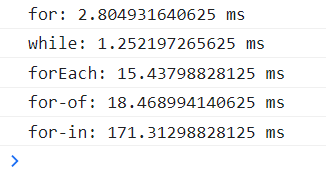
结果如图:结论就是无论任何情况,都应该尽可能的少用for/in循环,因为其会遍历私有属性和公有属性,及其浪费性能。最原始的for/while循环属于命令式操作,优点就是性能好,缺点就是需要自己处理细节。而诸如封装好的forEach等方法就属于函数式编程,其优点就是使用方便,性能中规中矩。
generator生成器
生成器语法:在一个由function创建的函数后面添加*符号,即创建一个生成函数。function* (){}。箭头函数无法成为生成器函数。 如果在一个对象中:let obj = { *sum(){} }这种写法是基于function的简写,因此可以使用生成器函数
普通函数._proto__ ==> Function.prototype
生成器函数.__protot__ ==> GeneratorFunction.prototype GeneratorFunction.__protot__==>Function.prototype
const fn = function* () {
console.log('执行中', 10);
return 100
}
console.log(fn());
当把一个生成器函数执行,不会立即去执行函数体中的内容,而是返回一个符合迭代器规范的对象,在该对象的原型上有next方法和Symbol(Symbol.iterator)方法。 可以执行next方法,那么就一定会返回一个对象。

当执行next方法后,生成器函数执行了,且调用结果如下
const fn = function* () {
console.log('执行中', 10);
return 100
}
let iterator = fn()
console.log(iterator.next()); //{value: 100, done: false}
console.log(iterator.next()); //{value: undefined, done: true}
使用生成器函数的作用:可以基于返回的迭代器对象,基于其next方法,控制函数体中的代码执行。
在生成器函数中提供了yield关键字。用于配合next方法。
每次执行next方法可以控制函数体中的代码执行,直到遇见了yield关键字或函数执行完毕返回。当遇见yield暂停函数执行的时候,返回的对象中value就是yield后面的值,done为false。当遇见return,或函数自己执行到末尾,则done为true,value为return后面的值。只要done为true后,再次执行next方法,则done为true,value为undefined
const fn = function* () {
console.log('A');
yield 10
console.log('B');
yield 20
console.log('C');
yield 30
}
let iterator = fn()
console.log(iterator.next()); //{value: 10, done: false}
console.log(iterator.next()); //{value: 20, done: false}
console.log(iterator.next()); //{value: 30, done: false}
console.log(iterator.next()); //{value: undefined, done: true} //函数体执行完毕,默认return undefined
返回的迭代器对象的原型除了有next方法,还有throw方法和return方法
const fn = function* () {
console.log('A');
yield 10
console.log('B');
yield 20
}
let iterator = fn()
console.log(iterator.next());
console.log(iterator.throw('哈哈哈')) //当遇见throw方法的时候,报错错误,后续代码都不会执行
console.log(iterator.next())

当遇见return方法的时候,类似在函数体中遇见return作用一致。
const fn = function* () {
console.log('A');
yield 10
console.log('B');
yield 20
}
let iterator = fn()
console.log(iterator.next());
console.log(iterator.return('哈哈哈'))
console.log(iterator.next())

生成器传参
可以在执行next方法的时候,传入参数。
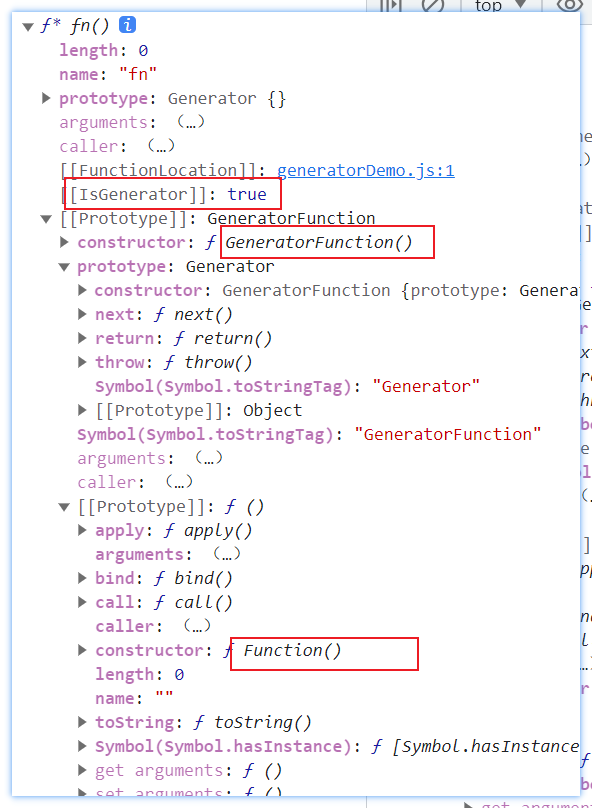
简单理解:当执行next方法传入参数的时候,会执行函数体中代码,直到遇见yield停止,注意这个时候将yield右边的代码结束返回,即{value: 10, done: false},未处理yield左边的情况。因此第一次传递的值是没有实际用处的无效值。 第二次执行next方法传值的时候,会从上一次暂停的yield左边开始,这个时候会将传递的参数赋值给左边的变量接收使用。同时执行到下一个yield暂停。总结就是每次next方法传递的参数值,都会作为上一个yield的返回值使用。因此第一次会无效,因为没有yield
const fn = function* () {
let r1 = yield 10
console.log(r1);
let r2 = yield 20
console.log(r2);
}
let iterator = fn()
console.log(iterator.next('first'));
console.log(iterator.next('second'));
console.log(iterator.next('third'));
生成器嵌套
如下有两个生成器函数,本意是想在一个生成函数中执行另一个生成器函数,但是sum最终没有进入执行,输出如下。
const sum = function* () {
yield 100
yield 200
}
const fn = function* () {
yield 10
sum()
yield 20
}
let iterator = fn()
console.log(iterator.next()); //{done:false,value:10}
console.log(iterator.next()); // {done:false,value:20}
console.log(iterator.next()); //{done:true,value:undefined}
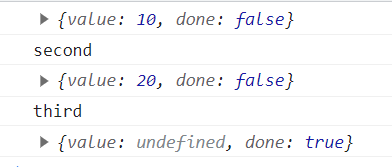
修改后的代码如下:在生成器函数前面使用yield关键字,发现还是没有按照预期进入迭代器中执行。
const sum = function* () {
yield 100
yield 200
}
const fn = function* () {
yield 10
yield sum()
yield 20
}
let iterator = fn()
console.log(iterator.next()); //{done:false,value:10}
console.log(iterator.next()); // {done:false,value:生成器对象}
console.log(iterator.next()); //{done:false,value:20}
console.log(iterator.next()); //{done:true,value:undefined}
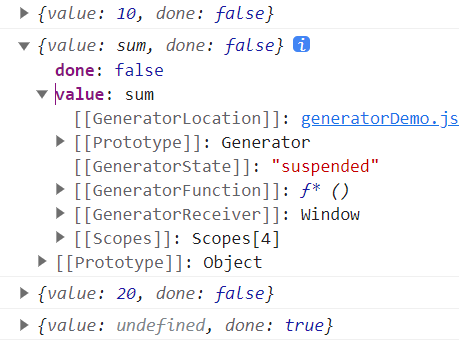
如果想进入嵌套的迭代器函数中执行,需要在yield后面添加一个*符号
const sum = function* () {
yield 100
yield 200
}
const fn = function* () {
yield 10
yield* sum()
yield 20
}
let iterator = fn()
console.log(iterator.next()); //{done:false,value:10}
console.log(iterator.next()); // {done:false,value:100}
console.log(iterator.next()); //{done:false,value:200}
console.log(iterator.next()); //{done:false,value:20}
console.log(iterator.next()); //{done:true,value:undefined}
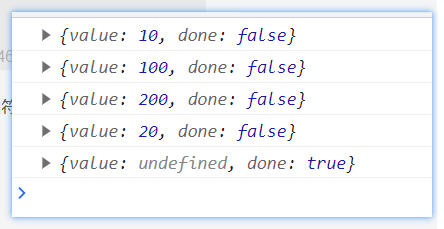
当嵌套遇见传参的时候,处理情况如下
const sum = function* () {
let r = yield 100
console.log('嵌套', r);
let r1 = yield 200
console.log('嵌套', r1);
}
const fn = function* () {
let r = yield 10
console.log(r);
let r1 = yield* sum()
console.log(r1); //该值为undefined
let r2 = yield 20
console.log(r2);
}
let iterator = fn()
console.log(iterator.next('first')); //{done:false,value:10}
console.log(iterator.next('second')); // {done:false,value:100}
console.log(iterator.next('three')); //{done:false,value:200}
console.log(iterator.next('four')); //{done:false,value:20}
console.log(iterator.next('five')); //{done:true,value:undefined}
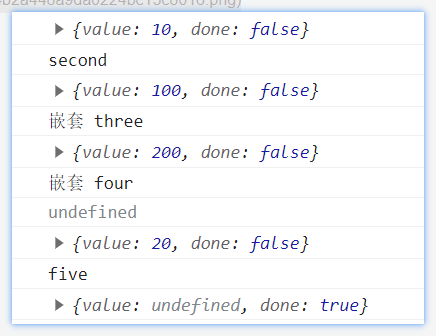
模拟串行请求
const delay = (time = 1000) => {
return new Promise(resolve => {
setTimeout(() => {
resolve(time)
}, time)
})
}
const fn = function* () {
let r1 = yield delay(1000)
console.log('第一次耗时', r1);
r1 = yield delay(2000)
console.log('第二次耗时', r1);
r1 = yield delay(3000)
console.log('第三次耗时', r1);
}
let itor = fn()
let { done, value } = itor.next()
value.then(val => { //1000
let { done, value } = itor.next(val)
value.then(val => { //2000
let { done, value } = itor.next(val)
value.then(val => { //3000
let { done, value } = itor.next(val)
})
})
})
但是这么写完发现,代码很难理解和维护,本质就是一个递归行为,根据done设置结束条件。以下是一个递归处理上面嵌套then的例子。在递归中做统一处理,这样子即使有很多个yield需要执行,那么就只需要一个函数就可以解决
const AsyncFun = function (generator, ...params) {
let itor = generator(...params) //给生成器函数传递参数
const next = (x) => {
let { done, value } = itor.next(x)//第一次执行x可以为undefined,这里的x是给yield左边的值赋值
if (done) return//递归结束条件
if (!(value instanceof Promise)) value = Promise.resolve(value) //返回的不是promise实例就包装为promise
value.then(val => {
next(val)
})
}
next()
}
AsyncFun (fn) // 传递要执行的生成器函数
ES8中提供的async/await语法,本质是简化promise的操作的。其原理是基于Promise和Generator语法糖实现。在上面的递归函数中AsyncFun 类似async关键字,生成器中的yield类似await关键字。
下面第一段代码就类似第二段代码async/await
AsyncFun(function* () {
let res = yield 20
console.log('res =', res);
yield delay(2000)
res = yield 30
console.log('res =', res);
});
(async () => {
let res = await 20
console.log('res =', res);
await delay(2000)
res = await 30
console.log('res =', res);
})()
redux-saga
redux-saga是一个用于管理异步获取数据(副作用)的redux中间件。它的作用是让副作用管理更加容易,执行更高效,测试简单等。前提必须掌握Iterator迭代器和Generator生成器。
常见中间件:redux-logger,redux-thunk,redux-promise,redux-persist(持久化本地存储),redux-saga
redux-saga和redux-thunk比较
redux中的数据流:action --> reducer --> state
- action是一个纯粹对象(plain object),必须包含一个
type字段用于派发标识。 - reducer是一个纯函数。纯函数就是函数内部的所有操作都和外界没有关系,这也是为什么我们传入state后第一件事就是做拷贝操作。
// 第一个函数就是非纯函数,在函数体中需要用到外部变量,可能会对外部行为造成影响
let x = 1
function fn(y) {
let total = x + y
}
// 纯函数
function fn(x, y) {
let total = x + y
}
- 只能处理同步操作。在reducer中只会出现同步情况,不可能出现异步情况,即使是在action派发中,我们也是基于中间件帮助我们拦截了异步情况,同时处理了异步情况后,在帮助我们同步派发出去。
*:redux-thunk处理流程:action --> middleware --> action2 --> reducer --> state。中间都会多一层中间件处理。下图是原理代码。白色部分代码就是执行返回的action字段。这里如果是同步的情况返回的就是{type}这种格式。但是这里返回一个异步函数。在displach(action函数)接收到函数的时候,基于中间件重写了。在函数内部对自动执行了返回的函数同时传入了dispatch实现最终的派发行为。
*:redux-thunk中间件将异步操作分散到了每一个actionCreator中,无法实现集中管理。在下面的代码中也发现了这个问题。而且在返回的函数中代码也具有多样性。比如这里可以返回一个async/awiat,也可以返回.then格式的等等。

基于redux-saga重构投票案例
页面效果如图,两个异步按钮点击时候设置一个loading效果。代码都是基于redux和react-redux实现。将代码修改为基于redux-saga

在重构投票案例之前,先搭建一个简单的Demo文件。效果图如下。同时需要注意,该组件action没有通过actionCreator创建,且组件中并没有使用connect函数,而是使用hooks函数使用状态和派发。在如下代码中直接使用dispatch实现派发,属于同步情况,会直接通知reducer执行。
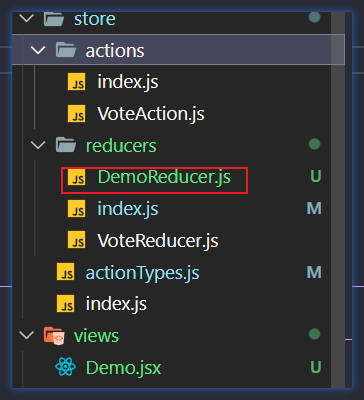


redux-saga的基本运行如下:首先使用中间件并启动,然后使用dispatch派发的时候,会进入中间件,在中间件中识别当前派发的任务是否是被监听的,这里无论是否被监听都会先执行一次reducer。 如果不是被监听的任务,就执行执行reducer后更新状态。如果是被监听的任务,则执行完reducer后会走具体的中间件内部的saga函数。在saga函数内部会处理对应的异步操作。执行完毕后会通知reducer执行。更新状态。
npm i redux-saga安装saga,按照上图指示搭建saga中间件使用。
redux-saga搭建
首先在store目录下创建一个saga.js文件,该文件作为监听器用于集中管理异步处理。在该文件内部创建一个名为saga函数。该函数必须是生成器函数
// 创建监听器,必须是一个生成器函数
export const saga = function* () {}
然后引入'redux-saga'中提供的createSagaMiddleware 方法执行创建中间件并使用。只有在使用后,才能使用该方法提供的run方法启动我们的监听器函数即saga。在run方法执行的时候会自动执行我们的生成器函数,基于递归的方式将next方法执行自动调用,这样子就会将我们生成器函数中的代码执行完。
import { createStore, applyMiddleware } from 'redux'
import { reducer } from '@/store/reducers/index.js'
// 引入提供的方法
import createSagaMiddleware from 'redux-saga'
import { saga } from './saga'
// 创建saga中间件
const sagaMiddleware = createSagaMiddleware()
const store = createStore(
reducer,
applyMiddleware(sagaMiddleware) //使用saga中间件
)
// 启动中间件后需要手动启动监听器
sagaMiddleware.run(saga)
export default store
然后就是针对saga.js文件做处理。首先在该文件中我们需要用到redux-saga/effects文件中提供的各种API使用。
// 前5个都是创建监听器用
import { take, takeEvery, takeLatest, throttle, debounce, call, apply, fork, delay, put } from 'redux-saga/effects'
首先在DemoReducer中输出验证,无论是否被监听都会先去执行reducer。
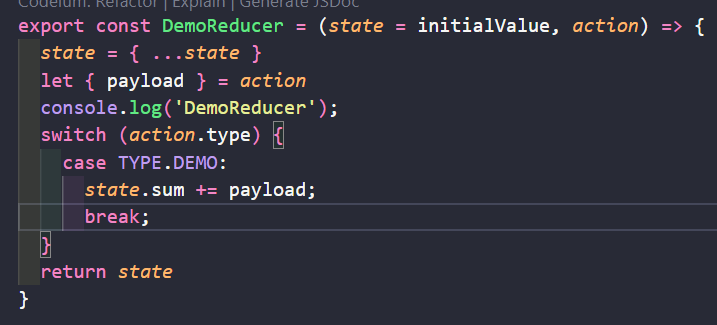
dispatch({ type: TYPE.DEMO, payload: 10 }) // Demo文件中派发
然后在saga.js文件中补充代码
export const saga = function* () {
yield take(TYPE.DEMO) //监听的任务,和上面dispatch中派发的任务标识一致
console.log('当前派发的任务被监听了');
yield put({ //异步处理完成用于执行reducer,类似dispatch
type: TYPE.DEMO,
payload: 10
})
}
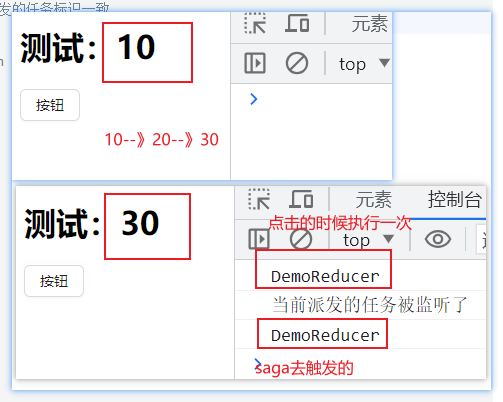
通过代码和结果,发现的确是无论是否被监听都先执行一次reducer。但是我们希望的是只会执行一次reducer操作,输出20,而不是执行两次。这里执行两次是第一次action.type去执行reducer的时候匹配到了,然后执行了一次累加,10变为20,。然后监听的派发标识又匹配到了action.type,于是会进入saga中执行。在saga中处理完毕后去执行reducer,最终将20变为30。
这个时候需要手动注意细节:即派发标识。如果是同步情况。那么只需要保证第一次执行reduce的时候,派发的action.type只会和reducer中的保持一致。并且在saga中并没有监听该标识。这样子就不会进入saga执行第二次reducer。
但是如果是异步情况。那么第一次派发的action.type就不能和reducer中的匹配成功,这样子就不会执行其中的代码。但是会和saga中的监听器的标识匹配上,于是会进入saga,执行异步处理。当异步处理完成后需要执行reducer的时候,put中派发的标识必须和reducer中的一致。
因此可以自定义派发标识规范,通常需要进入saga中处理的会在原先的标识后面带上:SAGA字符标注。如DEMO-SAGA
给Demo按钮添加一个异步按钮,注意标识上进行了SAGA处理。第二个按钮执行的时候,第一次进入reducer中不会执行任何操作。但是会跟saga中的匹配
<Button onClick={() => { dispatch({ type: TYPE.DEMO, payload: 5 }) }}> 按钮</Button >
<Button danger onClick={() => { dispatch({ type: TYPE.DEMO + 'SAGA', payload: 10 }) }}> 异步按钮</Button >
在saga中的代码
// 创建一个执行函数,在任务被监听后执行异步操作,也是一个生成器函数
const worker = function* () {
console.log('开始执行异步操作');
}
// 创建监听器,必须是一个生成器函数
export const saga = function* () {
yield take(TYPE.DEMO + 'SAGA') //监听的任务
yield worker() //由saga内部处理了,会对yield后面的值进行判断,如果是生成器函数会自动添加*
}
但是上面这段代码中,使用take(标识)方法创建的监听器只会执行一次。如果想执行多次就使用一个while循环处理。注意如下代码中并未是死循环,它是基于生成器函数配合yield实现。yield会暂停函数执行
while (true) {
yield take(TYPE.DEMO + 'SAGA') //监听的任务
yield worker() //由saga内部处理了,会对yield后面的值进行判断,如果是生成器函数会自动添加*
}
但是在这种写法中如何接收原本传递的{ type: TYPE.DEMO + 'SAGA', payload: 10} 值。写法如下
const worker = function* (action) {
console.log('开始执行异步操作', action); //收到action后可以基于put实现派发
}
// 创建监听器,必须是一个生成器函数
export const saga = function* () {
while (true) {
let action = yield take(TYPE.DEMO + 'SAGA') //监听的任务
yield worker(action) //由saga内部处理了,会对yield后面的值进行判断,如果是生成器函数会自动添加*
}
}

这样子写完,发现上面的这种写法很复杂,需要使用while循环,还需要使用变量接收参数并传递。简化这些操作就需要使用takeEvery(标识,执行的函数)方法代替take方法。该方法可以实现多次监听,并自动将参数传递给函数使用。
export const saga = function* () {
yield takeEvery(TYPE.DEMO + 'SAGA', worker)
}

这里在worker函数中模拟服务器请求,使用saga中解构的delay方法实现延迟效果(不需要手写了)。然后在延迟之后,基于put(action)方法执行reducer更新状态。在saga中异步处理完毕后更新reducer需要保持标识一致。
const worker = function* (action) {
console.log('开始执行异步操作', action);
yield delay(2000)
yield put({ // 类似dispatch派发
type: TYPE.DEMO, //跟reducer保持一致
payload: action.payload
})
}
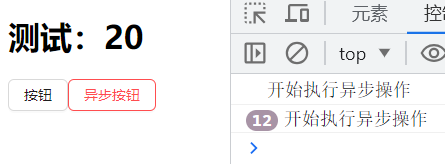
但是使用takeEvery方法的时候有一个弊端,就是频繁点击的时候会不断触发worker函数去执行异步操作,无法实现节流或防抖效果。那么这个时候就可以采用takeLatest(标识,执行的函数)方法代替。
yield takeLatest(TYPE.DEMO + 'SAGA', worker)
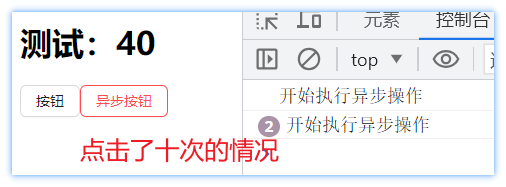
当代码修改为takeLatest方法后,按照理论分析,频繁点击后,worker函数应该只会执行一次。下图是频繁点击后worker函数的执行情况。实际情况是每次点击都会触发worker函数,但是在这里每次触发新的worker函数的时候,都会将上一次worker函数中执行的操作清除,只保留最新的任务。因此最终页面的值为20,实现了类似防抖的效果。 takeLatest方法每次点击都会触发worker函数,需要区别下面的几种方法。
throttle(时间,标识,执行的函数)方法类似实现节流效果,对异步派发实现节流处理,控制触发频率,实现降频效果。查看worker函数的执行情况。这个时候发现,频繁点击的时候worker函数的触发频率并没有像takeLatest方法那么频繁,throttle方法并不是对执行的方法做节流处理,而是对异步任务(当前派发标识)的监测做节流。第一次异步任务被监测到派发后,需要经过指定的时间,才能进行下一次监测。比如,第一次监测到后,需要等待500ms,在这段时间内频繁点击的不会被处理。当时间到了才会进行下一轮监测。
yield throttle(500, TYPE.DEMO + 'SAGA', worker)
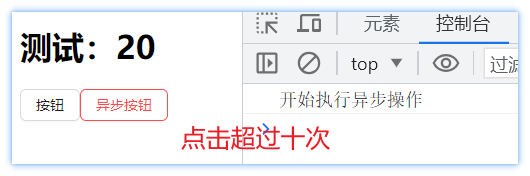
debounce(时间,标识,执行的函数)方法实现的效果类似函数防抖,那么它和takeLatest方法的区别是什么。查看结果图。发现最终worker函数只被执行了一次,那么就类似对当前的异步任务的监测做了节流处理。在指定的时间类,如果频繁触发异步任务标识,那么只会以最后一次为准去执行worker函数。比如,触发了异步任务,会等待500ms,如果这段时间内有触发了异步任务,则会清空上一次的。重新开始等待500ms。如果这段时间内没有触发了,就执行worker函数。
yield debounce(500, TYPE.DEMO + 'SAGA', worker)
take, takeEvery, takeLatest, throttle, debounce这种几个方法都是实现监测的,根据不同的场景使用不同的方法。call, apply, fork, delay, put,all这些方法是在执行监测的方法后执行某些事情需要用到的函数。
delay(时间):类似手写的延迟函数。模拟服务器发送请求的时间
put(action):类似dispatch派发,执行reducer更新状态。action必须包含type字段。
select(mapToState函数写法):取出状态值使用。
let { sum } = yield select(state => state.demo)
apply(this/null,函数,[参数1,参数2,...]):可以根据选择传入this。基本功能和call方法一致,只不过传参形式不同。
function fun(x, y){console.log(x, y);} // x,y分别接收数组中的每一个元素值
yield apply(null, fun, [1, 2])

call(函数,参数1,参数2,...):可以传入一个 Generator 函数, 也可以是一个返回 Promise 或任意其它值的普通函数。基于call方法能够把函数执行同时传入参数,在项目中可以基于call方法向服务器发送请求,同时接收其返回结果。也可以使用try/catch包起来处理错误的返回情况。
function fun(x) {
return new Promise(resolve => {
setTimeout(() => {
let res = {
id: x
}
resolve(res)
}, 1000)
})
}
const worker = function* (action) {
let res = yield call(fun, 10000)
console.log(res);
}
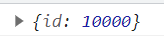
基于call方法实现异步处理,他们之间是串行执行的。测试如下,第一个函数执行一秒钟返回成功实例后,才会去执行第二个call方法。该方法耗时两秒,因此最终是三秒钟。可以验证他们之间是串行执行。
又添加一个异步函数
function fun2() {
return new Promise((resolve, reject) => {
setTimeout(() => {
resolve({ banner: '我是轮播图' })
}, 2000)
})
}
console.time('A')
let res = yield call(fun, 10000)
console.log(res);
res = yield call(fun2)
console.log(res);
console.timeEnd('A')
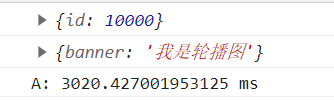
如果想实现并行效果,call方法需要配合all方法完成。这个时候结果如下。会并行执行两个call方法,等待全部获取到结果后才会继续往下执行。最终执行时间是两秒,证明了是并行完成的。
console.time('A')
let { home, banner } = yield all({
home: call(fun, 1000),
banner: call(fun2)
})
console.log(home, banner);
console.timeEnd('A')

fork(函数,参数1,参数2)方法主要是非阻塞的调用一个函数。返回的是一个Task对象。如果函数是一个Promise函数,需要向服务器发送请求,则无法使用变量接收其返回结果,因为它是非阻塞的,会继续往下执行。通常用于两个任务一起派发,不需要同步执行也不需要用到返回的结果,就可以使用fork方法提升性能。
重构案例
首先删除action文件,使用了redux-saga后不需要再次创建actionCreator了。同时也不需要使用connect函数了。
修改Vote组件中的代码
let { sup, opp } = useSelector(state => state.vote)
let dispatch = useDispatch()
<Button type='primary' onClick={() => {
dispatch({
type: TYPE.VOTE_SUP
})
}}>支持</Button>
<Button type='primary' onClick={() => {
dispatch({
type: TYPE.VOTE_SUP + 'SAGA'
})
}}>支持异步</Button>
<Button type='primary' danger onClick={() => {
dispatch({
type: TYPE.VOTE_OPP
})
}}>反对</Button>
<Button type='primary' danger onClick={() => {
dispatch({
type: TYPE.VOTE_OPP + 'SAGA'
})
}}>反对异步</Button>
saga文件中的代码。每一个模块对应一个执行函数worker。
const workerSum = function* (action) {
yield delay(1000)
yield put({
type: TYPE.DEMO,
payload: 10
})
}
const workerSUp = function* (action) {
yield delay(1000)
yield put({
type: TYPE.VOTE_SUP
})
}
const workerOpp = function* (action) {
yield delay(1000)
yield put({
type: TYPE.VOTE_OPP
})
}
// 创建监听器,必须是一个生成器函数
export const saga = function* () {
// 这里需要注意,这个地方相当于一个进程处理这些任务,并没有实现无阻塞的执行。
// 并且这三个takeLatest处理的是不同的任务不会互相影响,只会清除各自之前的任务
yield takeLatest(TYPE.DEMO + 'SAGA', workerSum)
yield takeLatest(TYPE.VOTE_SUP + 'SAGA', workerSUp)
yield takeLatest(TYPE.VOTE_OPP + 'SAGA', workerOpp)
}
扩充fork方法使用环境。假设触发TYPE.DEMO + 'SAGA'表示后会将三个执行方法都去执行。
第一段代码,属于同步执行,每一个yield执行完毕后才会去执行后面的代码
while (true) {
let action = yield take(TYPE.DEMO + 'SAGA')
yield workerSum(action)
yield workerSUp(action)
yield workerOpp(action)
}
第二段代码利用了fork方法的非阻塞行为。可以发现三个代码的执行时机属于异步关系,谁先结束先页面先变化。
while (true) {
let action = yield take(TYPE.DEMO + 'SAGA')
yield fork(workerSum, action)
yield fork(workerSUp, action)
yield fork(workerOpp, action)
}
dva
dva官网
下图是dva中的数据流图
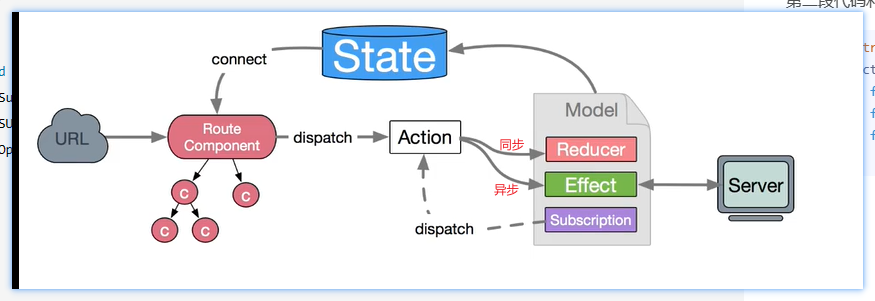
dva 首先是一个基于 redux 和 redux-saga 的数据流方案,然后为了简化开发体验,dva 还额外内置了 react-router 和 fetch,所以也可以理解为一个轻量级的应用框架。
如果是在一个create-react-app脚手架上使用dva。需要知道内容如下:
- 内置了
redux,redux-saga,react-router-dom。不需要再次安装。 - 需要注意
react-router-dom的版本并非是最新的,而是V5及以前的。 redux使用的版本是v3.7.2。- 集成的配套插件版本低
- 在react18版本中使用dva会有警告错误。
history是控制路由模式的。(会有错误提示,不用管),安装版本为V4.10.1.- index.jsx入口文件也有很大区别,需要使用dva语法。
整个页面的渲染是通过路由来控制的
各个模块中统一管理自己的内容,如状态,方法,异步任务等
派发的代码如下,根据不同模块,使用不同的方法。
dva脚手架
dva脚手架创建的项目是基于roadhog进行webpack配置的。roadhog是一个cli工具,提供了server,build和test三个命令,分别用于本地调试和构建,并且提供了简单的mock功能。默认配置和create-react-app有所不同,默认开启了css modules,还提供了json格式的配置方式。
安装脚手架:npm i dva-cli -g。创建项目:dva new my-project。项目安装完毕后需要手动安装:npm i roadhog 。
项目结构如下
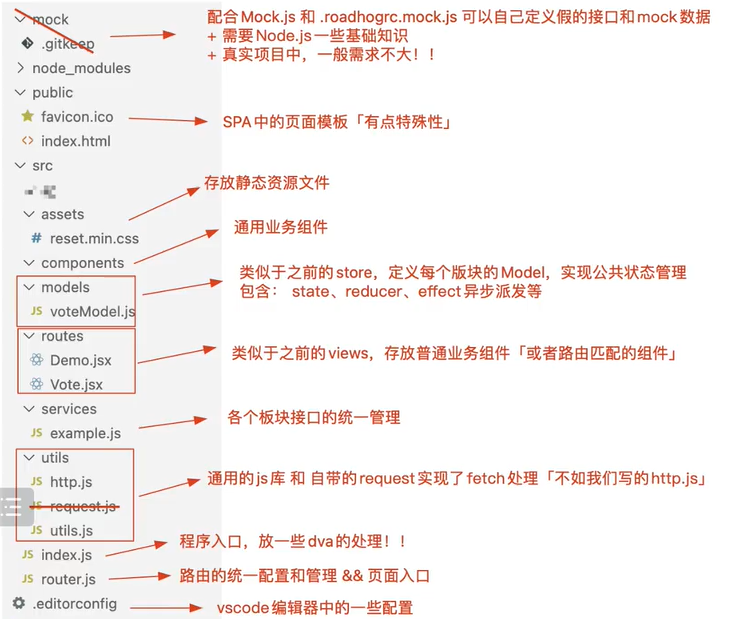
可以将原JSON文件后添加.js。这样子转换为js文件后就可以使用js语法
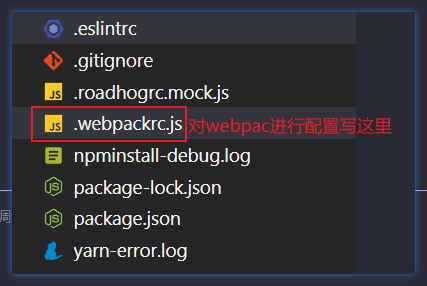
如果想在dva脚手架中使用antd组件,需要安装antd第四代版本。andV4默认不支持按需引入,需要额外安装插件支持。
安装:yarn add antd@4.24.7 babel-plugin-import。安装完毕还,需要在webpack的配置文件中配置插件信息。(antd版本尽量一致,否则会出错)
在.webpackrc.js文件中配置按需引入插件的使用。
export default {
extraBabelPlugins: [
[
"import",
{ "libraryName": "antd", "libraryDirectory": "es", "style": "css" }
]
]
}
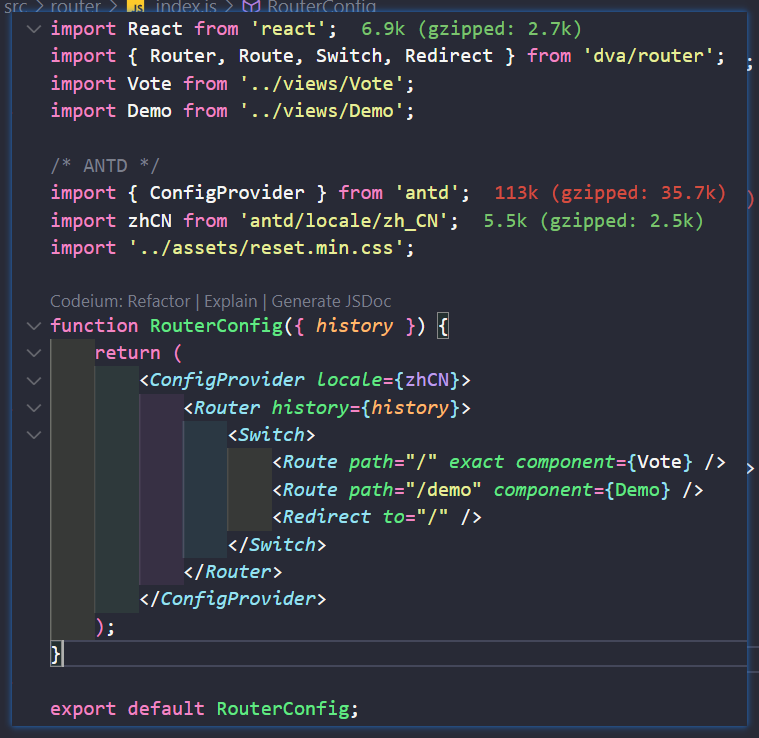
然后就是配置antd的国际化选项。注意在dva脚手架中,默认渲染的入口地址是router.js文件,通过路由渲染页面。
import { ConfigProvider } from 'antd'
import ZHCN from 'antd/es/locale/zh_CN'
const RouterConfig = function RouterConfig({ history }) {
return <ConfigProvider locale={ZHCN}>
...
</ConfigProvider>
};
页面渲染成功后,还可以添加less相关的样式,在dva脚手架中,当安装了less和less-loader后,默认不需要配置即可使用less相关的语法。。 脚手架自带的css modules如果不想使用还可以禁用,需要在.webpackrc.js文件中配置。
disableCSSModules: true
除了这些基本的配置以外,还默认提供了跨域代理。不需要额外安装插件支持。
proxy: {
"/api": {
target: "https://news-at.zhihu.com/api/4",
changeOrigin: true,
pathRewrite: { "^/api": "" }
}
}
如果想对响应式的插件进行配置,按照如下操作: lib-flexible, postcss-pxtorem@5.1.1,babel-plugin-styled-components-px2rem。测试后,px能够转换为rem处理。
import 'lib-flexible' //router入口文件中引入
extraPostCSSPlugins: [
require('postcss-pxtorem')({ // 将非css in js 的样式文件全部转换
rootValue: 75,
propList: ['*']
})
],
extraBabelPlugins: [
....
[
// 给babel指定插件,css in js形式也会被转换
'styled-components-px2rem',
{
rootValue: 75
}
]
],
默认情况下,dva脚手架中已经完成了对ES6语法的兼容处理以及CSS3的语法兼容处理,但是不包含非规范的语法处理,如装饰器。装饰器如果需要使用还需要我们安装额外的插件支持。 这些语法的兼容处理依赖于我们设置的浏览器兼容列表。如果不设置浏览器兼容列表,则默认情况下会考虑多种浏览器的情况,如ie之类,我们可以设置,使脚手架不考虑ie
- ES6语法兼容:
babel-loader , babel-preset-react-app - CSS3语法兼容:
postcss/loader , autoprefixer
由于dva脚手架只针对es6语法进行了转换处理,并没有对es6内置api进行重写处理,因此我们需要在入口文件中引入@babel/polyfill进行重写处理。
在.webpackrc.js文件中配置浏览器兼容处理,注意在roadhog中提供的例子中并没有针对开发环境或生产环境做兼容处理。但是在create-react-app脚手架中默认是对两中环境都进行了处理。然后我们想跟create-react-app脚手架保持一致,需要按照如下代码设置。
// 处理语法兼容
env: {
production: {
browserslist: [
">0.2%",
"not dead",
"not op_mini all"
],
},
development: {
extraBabelPlugins: ["dva-hmr"],
browserslist: [
"last 1 chrome version",
"last 1 firefox version",
"last 1 safari version"
]
},
}
这些基本都处理完成后,可以设置和打包相关的配置项。
使用hash配置项可以在打包时给生成的js和css文件添加一个唯一的hash值。 这个hash值可以用于缓存控制和版本管理。当你更新了你的应用程序时,你需要确保浏览器能够获取到最新的静态资源,而不是使用之前缓存的旧版本。通过给生成的文件添加一个hash值,你可以在每次打包时更改文件名,以确保浏览器能够获取到最新的版本。这样,当你更新应用程序时,浏览器会请求新的文件,而不是使用旧的缓存文件。这有助于避免浏览器缓存旧版本的问题,确保用户能够获取到最新的代码和样式。
hash: true
打包生产的目录如下,但是需要注意在dva脚手架中,index.html默认引入的js和css地址并无改变。需要通过配置项改变。
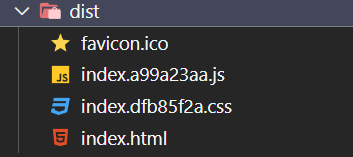
首先将public文件下的index.html修改为index.ejs文件,同时将文件中默认提供的引入删除。然后配置如下配置项后重新打包,这样子每次打包后的引入都是正确的,
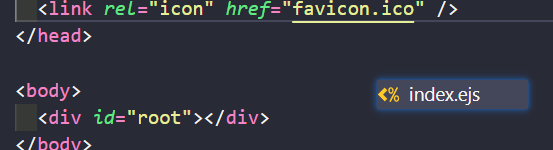
html: {
"template": "./public/index.ejs"
},
如果想修改默认的域名和端口号,需要用到环境变量,需要安装插件:npm i cross-env。然后在package.json文件中的start命令后面添加要修改的内容。"start": "cross-env HOST=127.0.0.1 PORT=3000 roadhog server",
更多配置信息可以进入官网查看:roadhog
dva中的router
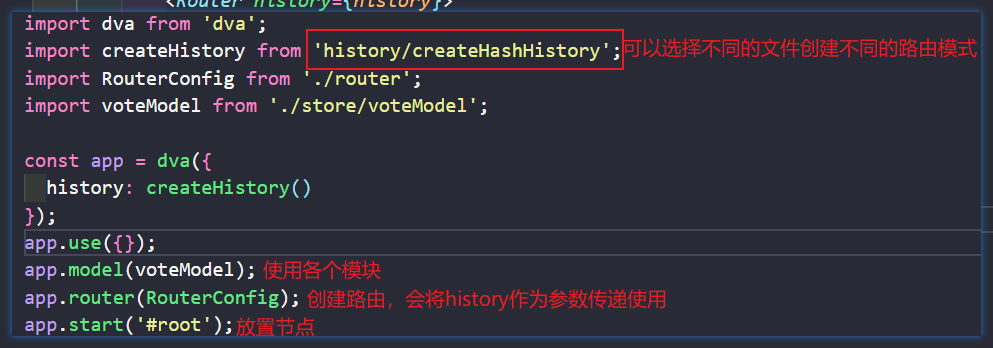
在index.js文件中设置路由模式和插件配置
import createHistory from 'history/createHashHistory'
// 1. Initialize
const app = dva({
history: createHistory(),
extraEnhancers: [] //使用插件,如redux-logger,redux-saga等
});
然后在dva提供的dva/router中提供了以下两个模块,一个是路由5版本及以下,还有一个是routerRedux。routerRedux的作用是提供在redux中实现路由跳转等功能。正常的路由跳转是用于组件中实现。如果想在redux中拥有该功能就需要额外使用该库中封装的方法。
在router入口文件中默认会传递一个history属性,该属性中具有路由相关的方法
function RouterConfig({ history }) {
console.log(history);
。。。
}

然后就是在组件中根据路由V5的语法搭建路由信息。
// 一级路由
<Router history={history}>
<Switch>
<Route path="/" exact component={Vote} />
<Route path="/demo" component={Demo} />
<Route path="/personal" component={Personal} />
<Redirect from='*' to='/'></Redirect>
</Switch>
</Router>
// 二级路由
<Switch>
<Redirect from='/personal' exact to='/personal/order'></Redirect>
<Route path='/personal/order' component={MyOrder}></Route>
<Route path='/personal/profile' component={MyProfile} ></Route>
<Redirect to='/personal/order'></Redirect>
</Switch>
dva中使用路由懒加载
在router.js入口文件中除了可以接收history属性,还可以接收一个app属性。这个app就是在index.js文件中通过dva函数创建的结果。
function RouterConfig({ history, app }) {}
从该文件中引入dynamic 方法,该方法就是对原路由中lazy方法和Suspence组件的结合,同时还扩充了模块的懒加载功能, import dynamic from 'dva/dynamic'
在一级路由处,删除原先的引入,添加如下代码。这样子就实现了懒加载的功能。
let lazyDemo = dynamic({
app,
models: () => [import('./models/demo')], // demo组件需要用到公共状态,进行懒加载
component: () => import('./routes/Demo')
})
let lazyPersonal = dynamic({
app,
models: () => [], // 不需要用到状态的可以不写
component: () => import('./routes/Personal')
})
<Route path="/demo" component={lazyDemo} />
<Route path="/personal" component={lazyPersonal} />
但是这么做完会将状态文件和组件分别进行打包,且名字是数字不好看,于是就可以使用webpack打包注释进行分类。
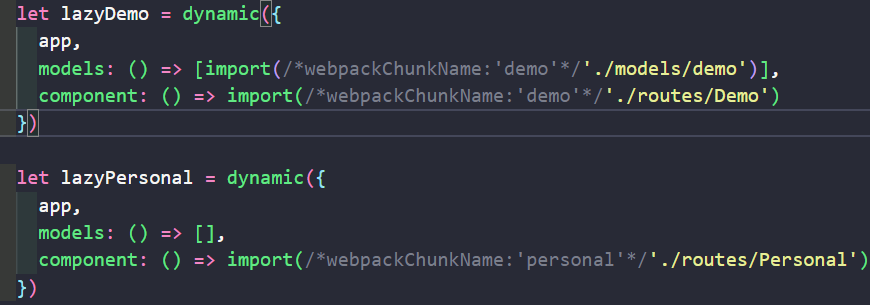
然后就是对二级路由进行懒加载处理,但是在二级路由中如何获取app属性是一个问题。
在router.js文件中的app属性是通过app.router(require('./router').default);传递来的默认属性,那么在其他地方该如何使用这些属性。
最简单的方法就是往window属性上挂载该属性,当前也可以使用上下文。
window.app = app
let lazyOrder = dynamic({
app: window.app,
models: () => [],
component: () => import(/*webpackChunkName:'personal'*/'./personal/MyOrder')
})
let lazyProfile = dynamic({
app: window.app,
models: () => [],
component: () => import(/*webpackChunkName:'personal'*/'./personal/MyProfile')
})
<Route path='/personal/order' component={lazyOrder}></Route>
<Route path='/personal/profile' component={lazyProfile} ></Route>
dva中搭建路由表
基本路由表搭建还是和V5差不多,只不过需要注意懒加载的处理方式是通过编写的函数处理。在函数中通过dynamic处理懒加载。
import Vote from "../routes/Vote"
import dynamic from "dva/dynamic"
// component, models均是要传入的函数, models可以不传
const lazy = (component, models) => {
// 指定models的默认值
if (typeof models === 'undefined') models = () => []
return dynamic({
app: window.app,
component,
models
})
}
export const perChil = [
{
path: '/personal',
exact: true,
redirect: '/personal/order',
},
{
path: '/personal/order',
component: lazy(() => import(/*webpackChunkName:'personal'*/'../routes/personal/MyOrder')),
meta: {
title: 'personal页/个人订单'
},
},
{
path: '/personal/profile',
component: lazy(() => import(/*webpackChunkName:'personal'*/'../routes/personal/MyProfile')),
meta: {
title: 'personal页/个人详情'
},
},
{
redirect: '/personal/order'
}
]
const routes = [
{
path: '/',
exact: true,
component: Vote,
meta: {
title: 'vote页'
}
},
{
path: '/demo',
component: lazy(
() => import(/*webpackChunkName:'demo'*/'../routes/Demo'),
() => [import(/*webpackChunkName:'demo'*/'../models/demo')]
),
meta: {
title: 'demo页'
}
},
{
path: '/personal',
component: lazy(
() => import(/*webpackChunkName:'personal'*/'../routes/Personal')
),
meta: {
title: 'personal页'
},
children: perChil
},
{
path: '*',
redirect: '/' //存在该属性代表是Redirect组件,则该属性代表to属性,path代表from属性
}
]
export default routes
然后在router.js文件中创建一个函数,用于创建Route组件
const Element = (props) => {
let { component: Component, history, location, match, meta } = props
let config = { history, location, match }
let title = meta?.title || ''
document.title = title
// 在返回实际组件之前可以做其他事情,如登录校验
return <Component {...config}></Component>
}
export const createRoute = (routes) => {
return <Switch>
{
routes.map((item, index) => {
let { path, exact, component, meta, redirect } = item
let config = {}
if (redirect) {
config.to = redirect //redirect就是to属性
if (path) config.from = path //path代表from属性
if (exact) config.exact = exact
return <Redirect key={index} {...config}></Redirect>
}
config.path = path
if (exact) config.exact = exact
return <Route key={index} {...config} render={(props) => {
return <Element {...props} {...item}></Element>
}}></Route>
})
}
</Switch>
}
return <ConfigProvider locale={ZHCN}>
<Router history={history}>
{/* 一级路由动态创建 */}
{createRoute(routes)}
</Router>
</ConfigProvider>
<div className="content">
<Switch>
{/* 二级路由创建 */}
{createRoute(perChil)}
</Switch>
</div>
当然除了这样子渲染二级路由还有使用如下办法,在router.js中创建一个方法,接收一个路径参数,渲染该路径下的子路由。最终返回的是一个createRoute方法返回的组件
export const LevelTwoRoutes = ({ path }) => { //二级路由匹配path,获取当前项path下的children子路由处理
let item = routes.find(item => item.path === path)
if (!item) return null
let children = item.children
if (children.length !== 0) {
return createRoute(children) //返回的是组件
}
}
使用的时候以组件的方式使用,同时传递参数过去
<LevelTwoRoutes path='/personal'></LevelTwoRoutes>
dva中的路由传参
dva中的路由传参基本和路由V5的写法差不多,都是使用history,location,match三个参数来实现路由跳转和获取路由信息。
- 问号传参:使用
search分别作为传递和接受的属性。location.search - 路径传参:修改路由表,使用参数占位,然后在
match.params中获取 - 隐式传参:使用
state分别作为传递和接受的属性。location.state
在dva/router中提供了withRouter函数,用于那些不是经过Route标签处理的组件没有默认的三个参数。经过withRouter(组件)处理的组件,会将三个参数作为属性传递给组件使用。
在dva/router中还提供了一个对象routerRedux。该对象身上有类似history对象身上的一些方法实现路由跳转。语法基本一致。唯一的区别是routerRedux不仅可以在正常的组件之间实现路由跳转,也可以在redux中实现跳转(redux中没有默认传递三个参数,同时也不是函数组件无法使用hooks函数)。

- 在redux中使用
yield put(routerRedux.push())
- 非redux中使用
dispatch(
routerRedux.push()
)
console.log(routerRedux.push('/personal/profile/1/张三'));执行后返回的是一个action对象,需要使用dispatch进行派发才会实现路由跳转。
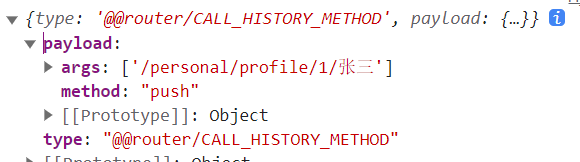
那么在dva中如何获取dispatch函数。使用提供的connect方法,使用方法一模一样。
import { connect } from 'dva'
//connect中什么都不写。则默认都会传递dispatch函数作为参数给组件使用
export default connect()(MyOrder);
dispatch(
routerRedux.push('/personal/profile/1/张三') //如何接收参数和之前的使用方法一样
)
dva中的model处理
在下图中,vote板块的model并没有进行懒加载处理,而demo板块的model做了懒加载处理。那么没有进行懒加载的model就可以在index.js文件中引入并使用了,这样子做的好处是如果一个model需要在多个地方页面被使用,就适用于在主js中提前引入使用,这样子在任何地方都可以使用该model的数据了。缺点就是如果有很多model需要在主js中引入,那么会造成主js的文件过大,首屏渲染慢。但是如果是model的懒加载处理。那么只会进入到对应的页面才会加载该model的数据,在此之前无法使用该model。
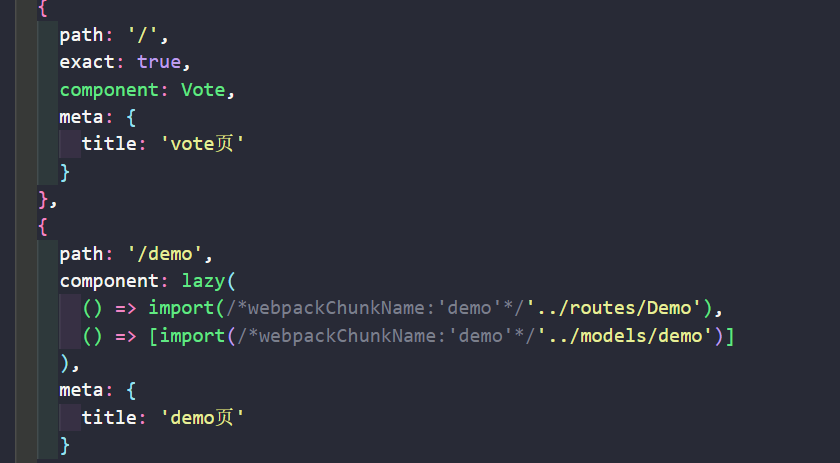
在index.js中引入vote板块的model并使用
import VoteModel from './models/vote'
app.model(VoteModel); // 如果需要使用多个model,就执行多次该方法传入model
每一个模块都具有五个组成部分,如果需要使用状态则使用dva提供的connect函数获取各个model的状态使用
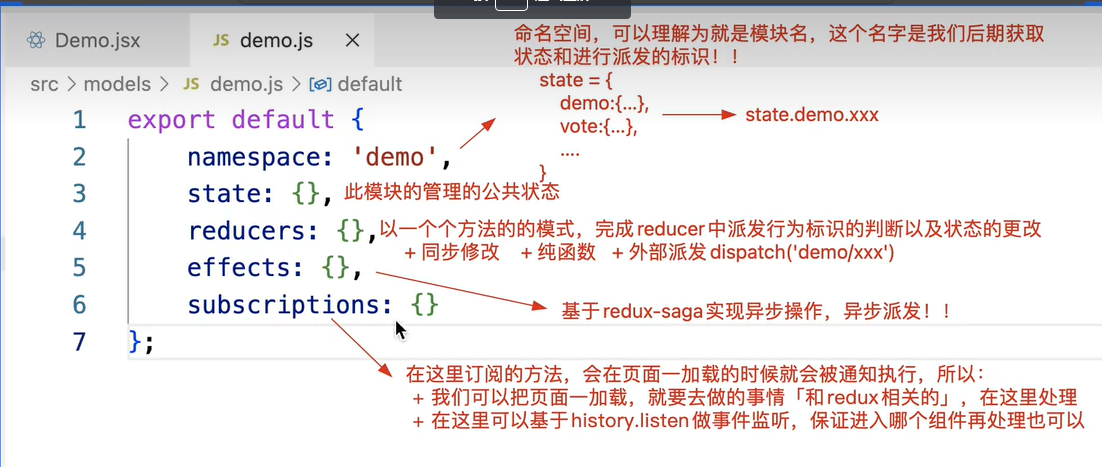
以下是一个简单的例子,假设在demo的state中存在num的属性。在组件中获取使用
import { connect } from 'dva'
const Demo = function Demo(props) {
console.log(props);
}
export default connect(state => state.demo)(Demo); // 使用redux-saga就不需要经过actionCreator处理了,默认传递dispatch使用
reducers中的处理
在dva中各个model中的reducer中只负责处理同步方法。 该属性中的每一个值都是一个函数,且函数名会被作为派发标识使用,并且每一个函数都会接收到两个属性:state和action,state代表当前model中的state值。action就是传递的派发标识和其他字段不过在这里type字段没有实际用处。 这里的reducer中的每一个函数实际上就对应原生的redux中的reducer函数中的switch分支,每一个分支就是一个函数。
最重要的是想要修改state中的状态值,只能通过reducers中的方法同步更新
state: {
num: 1
},
reducers: {
increment(state, { payload = 1 }) {
state = { ...state }
state.num += payload
return state
}
},
在demo组件中使用同步派发。注意派发标识,会找reducers和effects中的函数名进行比较,因此必须保证添加上各个模块名进行区分处理,且各自模块中的reducers和effects中不能出现重名的函数。
let { num, dispatch } = props
<Button type="primary" onClick={() => {
dispatch({
type: 'demo/increment',
payload: 5
})
}}>
按钮
</Button>
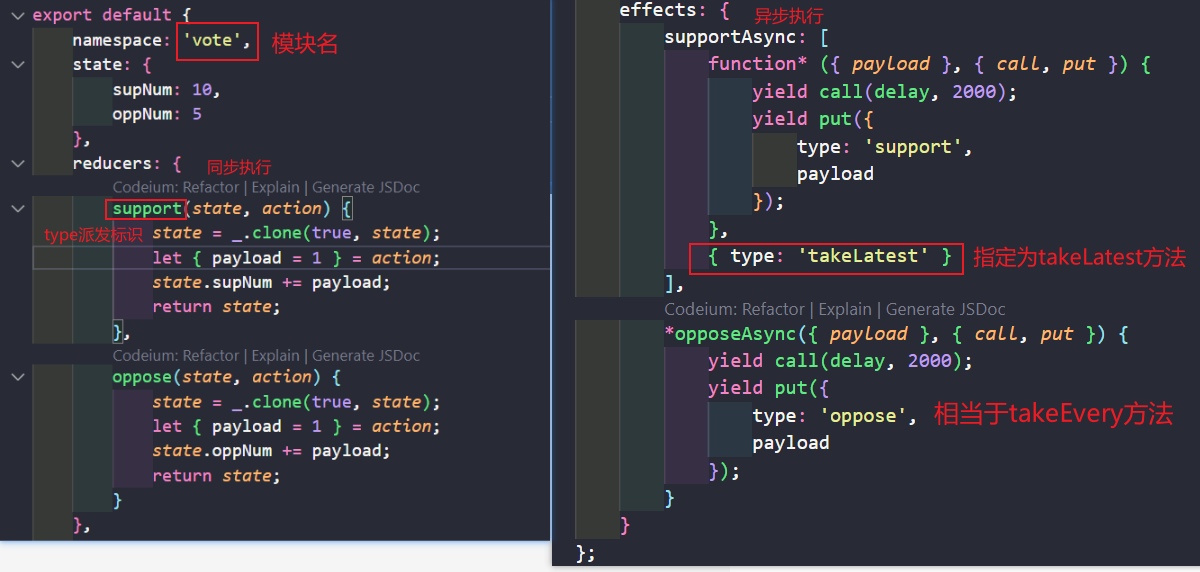
effects中的处理
effects中处理的函数,起始就是redux-saga中原先封装的saga函数中需要处理的内容。这里面的每一个函数都必须是生成器Generator函数。默认采用takeEvery方法。 在effects中的逻辑和redux-saga中的逻辑是一样的,都会执行先去执行reducer中进行处理,然后在进入saga中进行处理。那就需要保证同步只进入reducers中处理,异步进入effects中处理。处理的生成器函数名就是要监视的标识,因此函数名必须按照自定义的规范处理。以便区分reducers中的函数。
effects中每一个函数名相当于监听标识,函数体类似执行的生成器函数working
effects: {
*incrementAsync() {
}
}
// 等价于下面的写法
const saga = function* () {
yield takeEvery('incrementAsync', function* () {
})
}
<Button type="primary" danger onClick={() => {
dispatch({
type: 'demo/incrementAsync',
payload: 10
})
}}>
异步按钮
</Button>
每一个effects中的生成器函数都会接收两个参数:action和redux-saga中的常用effectApi。会发现并不是所有的effectApi都会有,比如delay和debounce就取消了。
*incrementAsync(action, effect) {
console.log(action, effect);
}
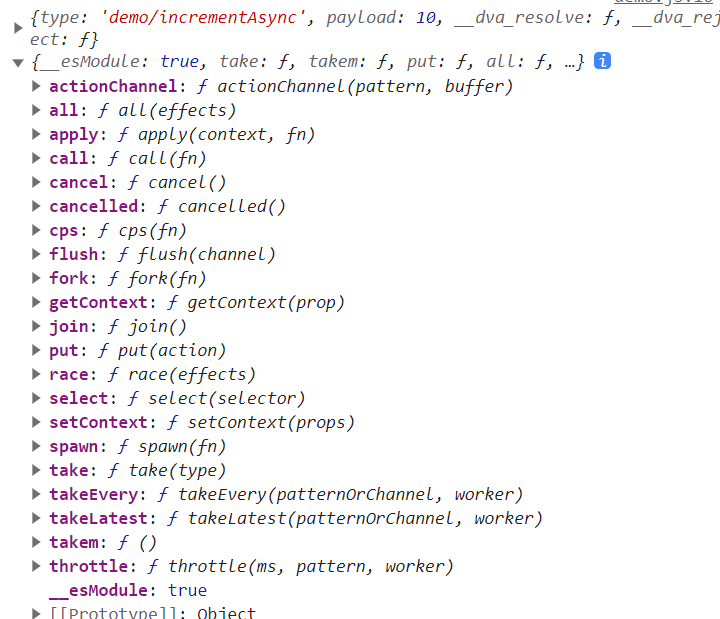
这里只解构常用的方法,select如果不传参数则默认获取所有板块的state信息。 假如当前板块的信息需要用到其他板块中的state值计算出,就可以在effects中的函数中完成。
*incrementAsync({ payload }, { put, select, call }) {
let x = yield select()
console.log(x);
}

let x = yield select(state => state.demo) // 获取指定model下的state状态
以下是基本的使用方式。注意effects中每一个生成器函数执行完毕异步操作后,与reducers中的函数进行派发处理的时候,标识不需要再添加模块名了。
*incrementAsync({ payload }, { put, select, call }) {
yield call(delay, 2000) // 手写的延迟函数
yield put({
type: 'increment', // 不需要再添加模块名了,当前模块下派发可以省略
payload
})
}
当然这样子写完默认都是takeEvery方法,如果想修改为其他形式,需要将生成器函数修改为一个数组,数组的第一项就是生成器函数,第二项为配置项。
incrementAsync: [
function* ({ payload }, { put, select, call }) {
yield call(delay, 2000)
yield put({
type: 'increment',
payload
})
},
{ type: 'takeLatest' } // { type: 'throttle', ms: 500 }带有额外配置项的写法
]
subscription中的处理
在subscriptions中定义的函数会在页面一加载的时候,就全部执行(生成器函数不行)后期路由切换的时候不再执行。同时每一个函数都会接收一个参数,参数中包含两个属性分别为:dispatch派发的方法和history路由监听或路由跳转的方法。通常如果页面一加载或指定的某个条件下就想从服务器异步获取数据,修改模块的状态值,就可以写在subscriptions中。
subscriptions: {
init(params) {
console.log('init', params);
},
setup(params) {
console.log('setup', params);
}
}

但是上面这种代码是vote板块下的subscription,vote板块并没有做懒加载处理,因此无论在哪一个板块,例如personal下,vote板块下的subscription中的方法都会被执行。那么是否可以指定只有进入vote板块的时候,才会执行subscription中的方法。思路:可以通过路由判断。
在默认接收的history属性中提供了listen方法实现监听。该方法中传入一个函数。例如下代码,这个时候没有对路由进行任何处理,初次执行,订阅到事件池中后执行一次。以后每次路由切换的时候都会执行一次事件池中的方法。 示例图是从personal切换到首页的情况。history.listen()中指定的方法会传入一个location属性,该属性可以理解为路由中的locatino。在该属性中存放了当前路由的地址。可以对此进行判断。
setup({ history, dispatch }) {
history.listen(async (location) => {
console.log('setup',location);
})
}

setup({ history, dispatch }) {
history.listen(async (location) => {
if (location.pathname === '/') {
await delay(2000)
dispatch({
type: 'supFun' //同步方法
})
}
})
}
history.listen方法执行后会返回一个取消监听的函数取名unlisten。例如在上面的代码中,只有进入/路由下才会执行代码,但是每次从别的路由切换回来多次的时候,也会执行多次。如果想第一次进入/后执行,就不再执行了,就需要取消监听。
let unlisten = history.listen(async (location) => {
if (location.pathname === '/') {
await delay(2000)
dispatch({
type: 'supFun'
})
unlisten()
}
})
如果是一个懒加载的model,如demo,那么只有当当前的model被注册的时候,才会执行subscriptions中的方法,如果一直未进入到demo页面,则demoModel一直处于未注册的情况,则不会去执行subscriptions中的方法。
app.use()使用插件
给按钮绑定loading
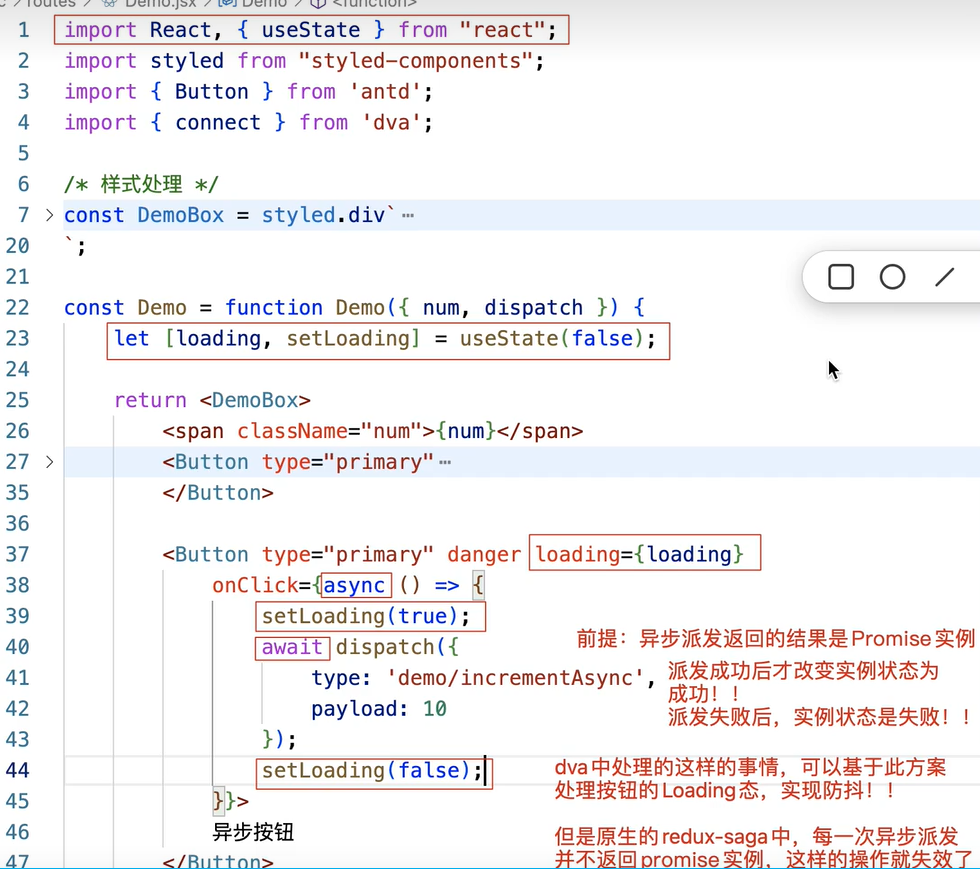
但是想上面这种情况使用useState创建的状态,如果在多个页面中的按钮需要用到loading,则需要重复创建多次。在dva中提供了dva-loading来快速实现loading效果。dva-loading是作为一个插件使用,因此需要在入口文件中引入并使用该插件。
import createLoading from 'dva-loading'
...
app.use(createLoading());
当app.use(createLoading());使用该插件后,会在全局的状态中多出一个loading属性。可以验证查看
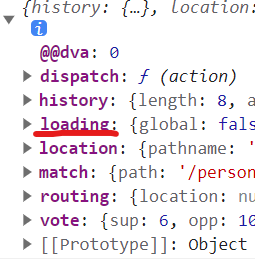
在Vote组件中将需要的属性传递给组件使用,每一个loading中包含了以下三个属性。
export default connect(state => {
return {
...state.vote,
loading: state.loading
}
})(Vote);
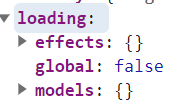
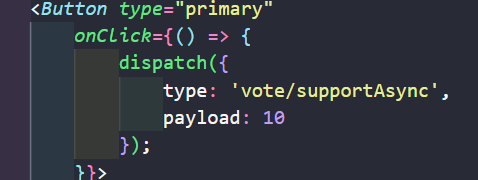
如果想对某一个按钮实现loading效果,就对其派发标识进行处理。
loadingB = loading.effects['vote/oppFunAsync'] // 对该派发标识做loading处理
console.log(loadingB); // 初始为undefined,然后点击后为true ==》 false
如果想对多个按钮进行处理,可以将loading.effects执行多次创建多个loading标识
let loadingA = loading.effects['vote/supFunAsync']
let loadingB = loading.effects['vote/oppFunAsync'] //分别将loadingA和loadingB用于不同按钮即可实现loading效果















 6848
6848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









