







matlab仿真-霍夫曼树(二叉树)实现二元、三元Huffman编码
离散无记忆信源概率模型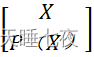 已知的条件下进行设计编码方法包括:
已知的条件下进行设计编码方法包括:
1. 二元霍夫曼编码
2. 三元霍夫曼编码
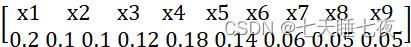
分别做成自定义函数,任意一个概率适量作为输入,可以调用函数获得相应输出,输出数据包括码字、码长、平均码长、码长方差、编码效率。
一、先了解霍夫曼编码的基本原理步骤:
(以二元霍夫曼为例)
1. 写下字符串中每个字符的概率。
2. 按照字符概率进行排序,组成一个队列。
3.最小的两个相加。
4.重复2、3步骤。
5. 直至概率为“1”对字符进行编码。
例子:
symbols = ["A", "B", "C", "D","E","F","G"];
p = [0.4 0.3 0.15 0.05 0.04 0.03 0.03];
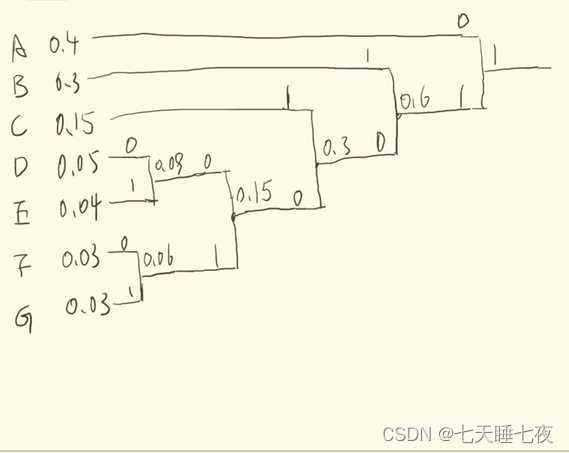
二、建立霍夫曼树
还是以二元霍夫曼为例
symbols = ["A", "B", "C", "D","E","F","G"];
p = [0.4 0.3 0.15 0.05 0.04 0.03 0.03];
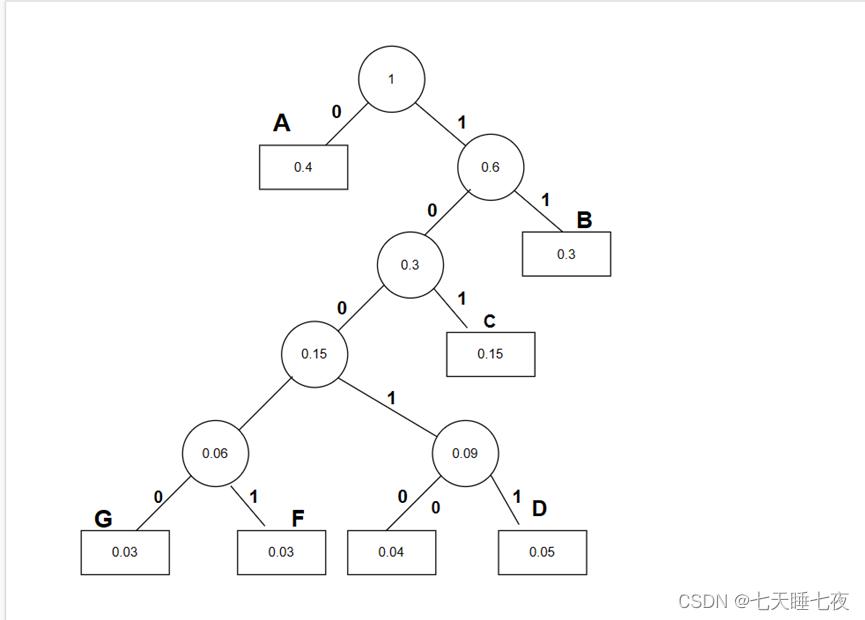
建立霍夫曼二叉树
%建立一个元细胞数组
leaves = cell(N,1);
%先进行排序,也可以在建立霍夫曼树是再排序,这里是现在这里排序
[probabilities,index] = sort(probabilities,'ascend');
symbols = symbols(index);%符号也跟着概率排序,避免丢失不对应
%使用结构体来存储建立的霍夫曼树
for i = 1 : N
leaves{i} = struct('symbol', symbols(i), 'probability', probabilities(i), 'code', '');
end
%建立霍夫曼二叉树
while length(leaves) > 1
%找最小概率为左子树
left_child = leaves{1};
%第二小概率为右子树
right_child = leaves{2};
%左右子树概率和为父节点概率
parent_prob = left_child.probability + right_child.probability;
% 将父节点插入list中
parent = struct('symbol', [],'probability',parent_prob, 'code', '');
%同时相应的左右子树树干给命名为'0','1'
left_child.code = '0';
right_child.code = '1';
parent.left = left_child;
parent.right = right_child;
% 将父节点插入结构体(树)中
leaves = [ {parent} ; leaves(3:end) ];
%建立一个空数组,存储最新的树叶子(节点)概率,方便再次对结构排序
leave = [];
for i = 1:length(leaves)
a = leaves{i}.probability;
leave = [leave,a];
end
%索引排序,找到最小的两片树叶
[~,index] = sort(leave,'ascend');
leaves = leaves(index);
end
递归计算编码
% 递归计算编码
root = leaves{1};
% dict - 一个结构体,包含每个符号的编码
dict = struct();
stack = {};
%递推的树干
stack{end+1} = root;
while ~isempty(stack)
node = stack{end};
%将树干清空,方便递推存入新的树干
stack(end) = [];
%判断是否已经到达树叶,输出码字
if isfield(node,'left')==0 && isfield(node,'right')==0
dict.(node.symbol) = node.code;
end
%处理左子树,将它加入路径中
if isfield(node,'left')==1
node.left.code = strcat(node.code, node.left.code);
stack{end+1} = node.left;
end
%处理右子树,将它加入路径中
if isfield(node,'right')==1
node.right.code = strcat(node.code, node.right.code);
stack{end+1 } = node.right;
end
end三、总体代码
二元Huffman编码
封装成binary_huffman函数
% creater : gxu.jd
% date:2023.4.30
function [symbols , probabilities , Code , L_average ,Code_L_error, Hx , Code_efficiency] = binary_huffman(symbols,probabilities)
%{
二元霍夫曼编码函数
%}
%{
%编写调试代码
symbols = ["A", "B", "C", "D","E","F","G"];
probabilities = [0.4 0.3 0.15 0.05 0.04 0.03 0.03];
%}
% 输入:
% symbols - 一个行向量,其中包含要编码的符号
% probabilities - 一个与符号相同大小的向量,表示每个符号出现的概率
% 输出:
% symbols - 一个字符串数组,输入的符号symbol按照出现概率升序输出
% probabilities - 每个符号对应升序输出概率
% Code - 元细胞数组,与symbols、probabilities对应的码字
% L_average - 平均码长
% Code_L_error- 码长方差
% Hx - 信息熵
% Code_efficiency - 编码效率
%
N = length(probabilities);
%建立一个元细胞数组
leaves = cell(N,1);
%先进行排序,也可以在建立霍夫曼树是再排序,这里是现在这里排序
[probabilities,index] = sort(probabilities,'ascend');
symbols = symbols(index);%符号也跟着概率排序,避免丢失不对应
%使用结构体来存储建立的霍夫曼树
for i = 1 : N
leaves{i} = struct('symbol', symbols(i), 'probability', probabilities(i), 'code', '');
end
%建立霍夫曼二叉树
while length(leaves) > 1
%找最小概率为左子树
left_child = leaves{1};
%第二小概率为右子树
right_child = leaves{2};
%左右子树概率和为父节点概率
parent_prob = left_child.probability + right_child.probability;
% 将父节点插入list中
parent = struct('symbol', [],'probability',parent_prob, 'code', '');
%同时相应的左右子树树干给命名为'0','1'
left_child.code = '0';
right_child.code = '1';
parent.left = left_child;
parent.right = right_child;
% 将父节点插入结构体(树)中
leaves = [ {parent} ; leaves(3:end) ];
%建立一个空数组,存储最新的树叶子(节点)概率,方便再次对结构排序
leave = [];
for i = 1:length(leaves)
a = leaves{i}.probability;
leave = [leave,a];
end
%索引排序,找到最小的两片树叶
[~,index] = sort(leave,'ascend');
leaves = leaves(index);
end
% 递归计算编码
root = leaves{1};
% dict - 一个结构体,包含每个符号的编码
dict = struct();
stack = {};
%递推的树干
stack{end+1} = root;
while ~isempty(stack)
node = stack{end};
%将树干清空,方便递推存入新的树干
stack(end) = [];
%判断是否已经到达树叶,输出码字
if isfield(node,'left')==0 && isfield(node,'right')==0
dict.(node.symbol) = node.code;
end
%处理左子树,将它加入路径中
if isfield(node,'left')==1
node.left.code = strcat(node.code, node.left.code);
stack{end+1} = node.left;
end
%处理右子树,将它加入路径中
if isfield(node,'right')==1
node.right.code = strcat(node.code, node.right.code);
stack{end+1 } = node.right;
end
end
% 构造编码矩阵
Code = '';
for i = N:-1:1
Code{i} = dict.(symbols(i));
end
%计算平均码长
Code_length = [];
for i = 1:N
Code_length(i) = length(char(Code(i)));
end
L_average = sum(Code_length.*probabilities);
Code_L_error = 0;
for i = 1:N
Code_L_error = Code_L_error + (Code_length(i)-L_average) * (Code_length(i)-L_average).*probabilities(i);
end
%计算信息熵
Hx = sum(-probabilities.*log2(probabilities));
%计算编码效率
Code_efficiency = Hx/L_average;
%{
供调试使用
disp('信号符号: ');
disp(symbols);
disp('对应概率 ');
disp(probabilities);
disp('对应码字 ');
disp(Code);
disp('平均码长');
disp(L_average);
disp('码长方差');
disp(Code_L_error);
disp('信息商');
disp(Hx);
disp('编码效率');
disp(Code_efficiency);
%}
end
二元Huffman编码调用函数输出
% creater : gxu.jd
% date:2023.4.30
clear all;
%{
%调试代码
symbols = ["A", "B", "C", "D","E","F","G"];
probabilities = [0.4 0.3 0.15 0.05 0.04 0.03 0.03];
实验要求部分
["X1","X2","X3","X4","X5","X6","X7","X8","X9"]
[0.2,0.1,0.1,0.12,0.18,0.14,0.06,0.05,0.05]
%}
symbols =input('请输入要编码的符号,比如["A", "B", "C", "D","E","F","G"]:\n');
probabilities = input('请输入对应编码符号出现的概率,比如[0.4,0.3,0.15,0.05,0.04,0.03,0.03]:\n');
[symbols , probabilities , Code , L_average ,Code_L_error, Hx , Code_efficiency] = binary_huffman(symbols,probabilities);
disp('信号符号: ');
disp(symbols);
disp('对应概率 ');
disp(probabilities);
disp('对应码字 ');
disp(Code);
disp('平均码长');
disp(L_average);
disp('码长方差');
disp(Code_L_error);
disp('信息熵');
disp(Hx);
disp('编码效率');
disp(Code_efficiency);三元Huffman编码
封装成ThreeHuffman_Code函数
% creater : gxu.jd
% date:2023.4.30
function [symbols , probabilities , Code , L_average ,Code_L_error, Hx , Code_efficiency] = ThreeHuffman_Code(symbols,probabilities)
%{
三元霍夫曼编码函数
%}
% 输入:
% symbols - 一个行向量,其中包含要编码的符号
% probabilities - 一个与符号相同大小的向量,表示每个符号出现的概率
% 输出:
% symbols - 一个字符串数组,输入的符号symbol按照出现概率升序输出
% probabilities - 每个符号对应升序输出概率
% Code - 元细胞数组,与symbols、probabilities对应的码字
% L_average - 平均码长
% Code_L_error- 码长方差
% Hx - 信息熵
% Code_efficiency - 编码效率
%
N = length(probabilities);
%建立一个元细胞数组
leaves = cell(N,1);
%先进行排序,也可以在建立霍夫曼树是再排序,这里是现在这里排序
[probabilities,index] = sort(probabilities,'ascend');
symbols = symbols(index);%符号也跟着概率排序,避免丢失不对应
%使用结构体来存储建立的霍夫曼树
for i = 1 : N
leaves{i} = struct('symbol', symbols(i), 'probability', probabilities(i), 'code', '');
end
%建立霍夫曼二叉树
while length(leaves) > 1
%找最小概率为左子树
left_child = leaves{1};
%第二小概率为中子树
middle_child = leaves{2};
%第三小概率为右子树
right_child = leaves{3};
%左中右子树概率和为父节点概率
parent_prob = left_child.probability + middle_child.probability + right_child.probability;
% 将父节点插入list中
parent = struct('symbol', [],'probability',parent_prob, 'code', '');
%同时相应的左右子树树干给命名为'0','1'
left_child.code = '0';
middle_child.code = '1';
right_child.code = '2';
parent.left = left_child;
parent.middle = middle_child;
parent.right = right_child;
% 将父节点插入结构体(树)中
leaves = [ {parent} ; leaves(4:end) ];
%建立一个空数组,存储最新的树叶子(节点)概率,方便再次对结构排序
leave = [];
for i = 1:length(leaves)
a = leaves{i}.probability;
leave = [leave,a];
end
%索引排序,找到最小的两片树叶
[~,index] = sort(leave,'ascend');
leaves = leaves(index);
end
% 递归计算编码
root = leaves{1};
% dict - 一个结构体,包含每个符号的编码
dict = struct();
stack = {};
%递推的树干
stack{end+1} = root;
while ~isempty(stack)
node = stack{end};
%将树干清空,方便递推存入新的树干
stack(end) = [];
%判断是否已经到达树叶,输出码字
if isfield(node,'left') == 0 && isfield(node,'middle') == 0 && isfield(node,'right') == 0
dict.(node.symbol) = node.code;
end
%处理左子树,将它加入路径中
if isfield(node,'left')==1
node.left.code = strcat(node.code, node.left.code);
stack{end+1} = node.left;
end
if isfield(node,'middle')==1
node.middle.code = strcat(node.code, node.middle.code);
stack{end+1} = node.middle;
end
%处理右子树,将它加入路径中
if isfield(node,'right')==1
node.right.code = strcat(node.code, node.right.code);
stack{end+1 } = node.right;
end
end
% 构造编码矩阵
Code = '';
for i = N:-1:1
Code{i} = dict.(symbols(i));
end
%计算平均码长
Code_length = [];
for i = 1:N
Code_length(i) = length(char(Code(i)));
end
L_average = sum(Code_length.*probabilities);
Code_L_error = 0;
for i = 1:N
Code_L_error = Code_L_error + (Code_length(i)-L_average) * (Code_length(i)-L_average).*probabilities(i);
end
%计算信息熵
Hx = sum(-probabilities.*log2(probabilities));
%计算编码效率
Code_efficiency = Hx/(L_average * log2(3));
%{
disp('信号符号: ');
disp(symbols);
disp('对应概率 ');
disp(probabilities);
disp('对应码字 ');
disp(Code);
disp('平均码长');
disp(L_average);
disp('码长方差');
disp(Code_L_error);
disp('信息商');
disp(Hx);
disp('编码效率');
disp(Code_efficiency);
%}
end
三元Huffman编码调用函数输出
% creater : gxu.jd
% date:2023.4.30
clear all;
%{
%调试代码
symbols = ["A", "B", "C", "D","E","F","G"];
probabilities = [0.4 0.3 0.15 0.05 0.04 0.03 0.03];
实验要求部分
["X1","X2","X3","X4","X5","X6","X7","X8","X9"]
[0.2,0.1,0.1,0.12,0.18,0.14,0.06,0.05,0.05]
%}
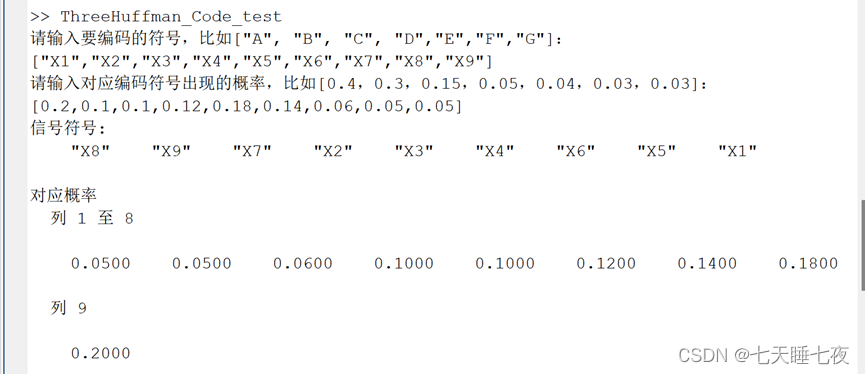
symbols =input('请输入要编码的符号,比如["A", "B", "C", "D","E","F","G"]:\n');
probabilities = input('请输入对应编码符号出现的概率,比如[0.4,0.3,0.15,0.05,0.04,0.03,0.03]:\n');
[symbols , probabilities , Code , L_average ,Code_L_error, Hx , Code_efficiency] = ThreeHuffman_Code(symbols,probabilities);
disp('信号符号: ');
disp(symbols);
disp('对应概率 ');
disp(probabilities);
disp('对应码字 ');
disp(Code);
disp('平均码长');
disp(L_average);
disp('码长方差');
disp(Code_L_error);
disp('信息熵');
disp(Hx);
disp('编码效率');
disp(Code_efficiency);四、运行结果





五、总结与展望
1、在输入端增加判断条件,判断输入的概率和为1,否则输出错误
2、霍夫曼树在建立时,是否要先进行排序,根据自己实验,不排序容易乱序
3、存储霍夫曼树使用的是元细胞数组加结构体的方式,在matlab中调用多次索引都无法实现,最后使用一个数组的方式暂时存储,得到索引后再写入结构体。虽然必须繁琐,但胜在好用与能成功运行。
















 2984
2984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











