







在复习的路途中,自己总结的各种后端开发笔记,每一题都是直接进入主题,包括(Java、MySQL、Redis、Spring、分布式、RocketMQ、Docker等流行技术架构的知识点),欢迎大家前来学习,如有错误请指点,期待大家能收获知识。
如果需要获取最新的文章,欢迎访问我的个人博客 哈利的小屋 我经常在这里更新编程技巧、项目教程和最新的技术动态。无论你是初学者还是资深开发者,都能找到有价值的内容。快来探索,提升你的编程技能吧!
Java 集合知识
HashMap的原理以及扩容机制
HashMap 是基于哈希表的数据结构,用于键值对存储。
JDK1.8 前描述:
- HashMap 底层采用数组和链表结合在一起使用(链表散列)。
- 通过 key 的 hashCode 经过扰动函数处理后得到的 hash 值,通过
(n-1) & hash找到元素存储的位置。 - 如果目前位置元素存在的话,就要判断它们的 hash 值和 key 是否相同,相同就覆盖,不同就通过拉链法解决冲突。
JDK1.8 后描述:
哈希冲突的处理方式出现了很大的变化。
- 当链表长度大于等于阈值(默认 8)。
- 如果当前数组长度 < 64,则会先进行扩容来减少哈希冲突。
- 如果数组长度 >= 64,则将链表转为红黑树,减少搜索时间。
put方法流程
- 计算键对象的 hashCode() 方法来获取 hash 值。
- 根据 hash 值,通过
hash & (n-1)操作定位到哈希表的某个桶中。 - 处理哈希冲突,调整表的大小。
- 如果存在的话,返回先前与指定键关联的值,否则返回 null。
HashMap和HashTable的区别
- 是否线程安全:HashMap 非线程安全,Hashtable 线程安全(内部方法采用 synchronized 修饰)。
- 效率:由于线程安全问题,HashMap 效率比 Hashtable 高。
- 是否支持空值:HashMap 可以存储 null 的 key 和 value,但 null 键只能存在一个。Hashtable 不允许空值存在,否则抛出
NullPointerException。 - 初始容量和扩容容量不同:Hashtable 默认大小为 11 ,扩容默认大小为原来的
2n + 1,HashMap 默认为 16 ,扩容默认大小为原来的2n。如果 HashMap 指定了大小,会扩充为 2 的幂次方。 - 底层数据结构:见
### HashMap的原理以及扩容机制,而 Hashtable 没有这样的结构。 - 哈希函数的实现:Hashtable 直接使用键的 hashCode() 的值。
ArrayList和LinkedList的区别
- 是否保证线程安全: 都不是线程安全的,需要外部同步。
- 底层数据结构:
- ArrayList: 基于动态数组实现。数组在初始化时有固定的容量,当元素数量超过容量时,数组会自动扩容(通常是原容量的 1.5 倍)。
- LinkedList: 基于双向链表实现。每个元素(节点)包含一个数据值和指向前后节点的引用。
- 插入和删除的影响:
- ArrayList: 在末尾插入或删除元素的时间复杂度为 O(1)。但是,在中间插入或删除元素需要移动后续元素,时间复杂度为 O(n)。
- LinkedList: 在头尾插入或者删除元素的时间复杂度为 O(1),因为只需调整前后节点的引用。但在指定位置时,需要先找到插入或删除的位置,时间复杂度为 O(n)。
- 快速随机访问:
- ArrayList: 支持快速随机访问,因为底层是数组(实现了
RandomAccess接口),可以直接通过索引访问元素。 - LinkedList: 不支持快速随机访问。需要遍历链表来访问元素。
- ArrayList: 支持快速随机访问,因为底层是数组(实现了
- 内存空间占用:
- ArrayList: 在列表的结尾会预留一定的容量空间,会导致一定量的内存浪费。
- LinkedList: 每个元素(节点)都需要额外的空间来存储指向前后节点的引用。
- 总结: 因此,
LinkedList的每个元素比ArrayList的元素占用更多的内存。
Java JVM 知识
Java内存区域
运行时数据区域
引用图片JavaGuide
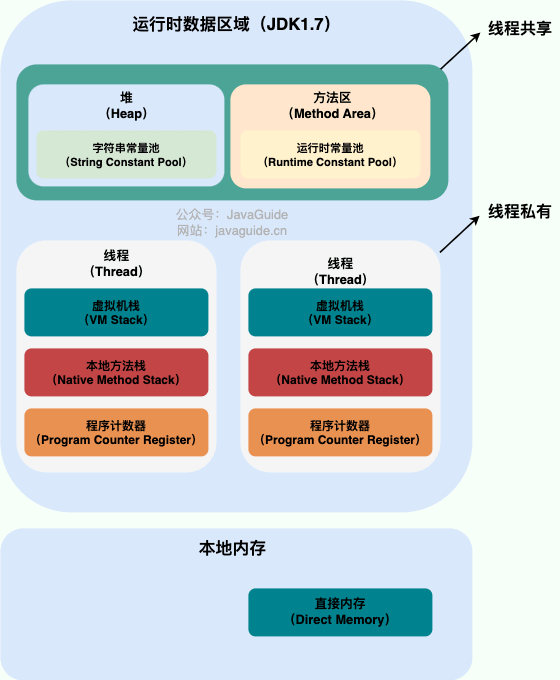
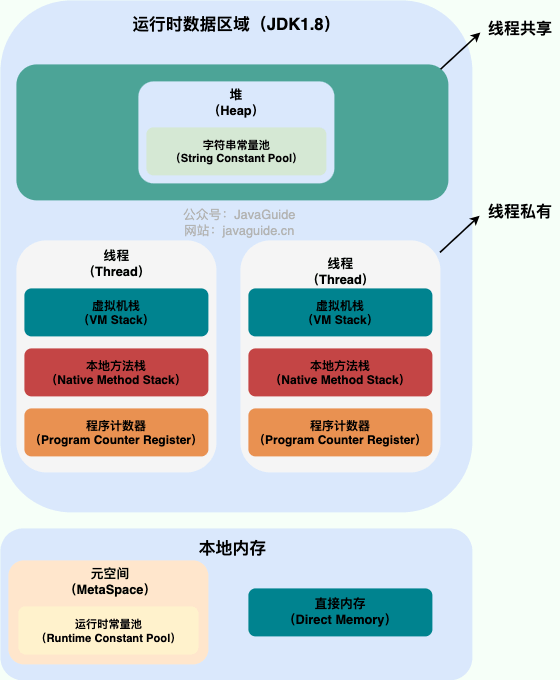
程序计数器
描述:
- 较小的内存空间。
- 可以看作为当前线程所执行的字节码的行号指示器。
- 任何时候都指向当前正在执行的字节码指令地址。
- 每个线程都独立维护一个程序计数器(线程私有)。
作用:
- 存储当前线程的字节码指令地址。
- 如果线程执行
Native方法,这个计数器值为空(Undefined)。
虚拟机栈
描述:
- 线程私有的,生命周期与线程相同。。
- 生命周期和线程相同。
- 描述 Java 方法执行的内存模型。
- 每个方法执行的同时都会创建一个栈帧,存储局部变量表、操作数栈、动态链接、方法出口等信息。
本地方法栈
描述:
- 线程私有的,生命周期与线程相同。
- 与虚拟机栈类似,只不过虚拟机栈为虚拟机执行 Java 方法服务,而本地方法栈为虚拟机使用到的 Native 方法服务。
堆
描述:
- 线程共享的,生命周期与虚拟机相同。
- 唯一目的就是用于存放对象的实例,几乎所有的对象实例都在这里分配内存。
- 垃圾回收器管理的主要区域就是这里。
方法区
别名:非堆(Non-Heap)
描述:
- 线程共享的,生命周期与虚拟机相同。
- 存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
运行时常量池
描述:
- 方法区的一部分。
- Class 文件中除了有类的版本号、字段、方法、接口等描述信息外,还有一项常量池,用于存放编译器生成的各种字面量和符号引用,会在类加载后进入方法区的运行时常量池中存放。
- 具有动态性,运行期间产生的新常量也会被加入到这里。
字符串常量池
描述:
- 方法区的一部分。
- 专门存放字符串字面量的区域。存放通过
intern()方法加入的字符串。 - 避免了创建重复字符串对象,节省内存。
直接内存
描述:
- 不是 JVM 运行时数据区的一部分,但也被频繁使用。
- 主要用于提高 I/O 操作的性能。
垃圾回收算法
垃圾回收(GC)是 JVM 内存管理的重要组成部分,通过自动回收不再使用的对象,释放内存空间,避免内存泄漏。
- 标记-清除算法(Mark-Sweep):最基础的垃圾回收算法,分为两个阶段:标记阶段和清除阶段。在标记阶段,GC 会遍历所有的对象,标记出所有可达的对象。在清除阶段,GC 会回收所有未被标记的对象。虽然该算法实现简单,但存在内存碎片问题,因为回收后的内存空间是不连续的。
- 标记-整理算法(Mark-Compact): 对标记-清除算法的改进,同样分为标记和整理两个阶段。在标记阶段标记所有可达对象后,整理阶段会将所有存活的对象移动到内存的一端,然后清理掉边界以外的内存。这种方式解决了内存碎片的问题,但移动对象的成本较高。
- 复制算法(Copying): 将内存分为两块相等的区域,每次只使用其中一块。当这块内存用完时,GC 会将存活的对象复制到另一块内存中,然后清空当前使用的内存区域。复制算法适用于对象生命周期较短的场景,因为大部分对象会在一次GC中被回收。其优点是没有内存碎片,缺点是需要双倍的内存空间。
- 分代收集算法(Generational Collection): 基于对象的生命周期特点,将堆内存分为新生代和老年代。新生代中的对象生命周期较短,使用复制算法进行垃圾回收;老年代中的对象生命周期较长,使用标记-清除或标记-整理算法进行垃圾回收。
具体的垃圾回收器有:
- Serial GC:使用单线程进行垃圾回收,适用于单线程环境。其优点是实现简单,缺点是垃圾回收时会暂停所有应用线程(Stop-The-World),导致较长的停顿时间。
- Parallel GC:使用多线程进行垃圾回收,适用于多处理器环境,提供更高的吞吐量。它在新生代使用复制算法,在老年代使用标记-整理算法。虽然停顿时间较长,但适合对响应时间要求不高的后台应用。
- CMS(Concurrent Mark-Sweep) GC:旨在减少垃圾回收的停顿时间,适用于低延迟应用。它在标记阶段和清除阶段都可以与应用线程并发执行,但在某些情况下可能会产生内存碎片。CMS GC 在老年代使用标记-清除算法,在新生代使用复制算法。
- G1(Garbage-First) GC:面向大内存、多处理器环境的垃圾回收器,旨在提供低停顿时间。它将堆内存划分为多个独立的区域(Region),并优先回收垃圾最多的区域。G1 GC 结合了并行和并发的特点,适用于对响应时间和吞吐量都有要求的应用。
拓展知识:
- 什么样的对象算垃圾?如果对象被标记成了垃圾,还能逃逸吗?
双亲委派是什么
每当一个类加载器收到加载请求时,它会先将请求转发给父类加载器。在父类加载器没有找到所请求的类的情况下,该类就会尝试去加载。
主要流程:
- 首先会判断当前类是否被加载过,加载过则直接返回。
- 没加载过,则请求委派给父类加载器进行加载。
- 当父类加载器无法完成加载时,子类加载器就会去尝试加载。
- 如果子类也无法加载这个类,抛出异常
ClassNotFoundException。
作用:
- 保证 Java 程序的稳定运行。
- 避免类的重复加载。
- 保证了 Java 的核心 API 不被篡改。
注意:
- JVM 区分不同类的方式不仅仅根据类名。
- 相同的类文件被不同的类加载器加载,会产生两个不同的类。
Java 并发知识
什么是线程,如何创建?
描述:
- 线程是操作系统能够进行运算调度的基本单位,是 Java 的基本执行单元。
- 线程在独立的程序计数器、栈和局部变量空间运行。
- 共享堆内存中的资源。
创建:
- 继承
Thread类。
class MyThread extends Thread {
@Override
public void run() {
System.out.println("Thread is running");
}
}
public class Main {
public static void main(String[] args) {
MyThread thread = new MyThread();
thread.start(); // 启动线程
}
}
- 实现
Runnable接口。
class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println("Thread is running");
}
}
public class Main {
public static void main(String[] args) {
Thread thread = new Thread(new MyRunnable());
thread.start(); // 启动线程
}
}
- 匿名内部类实现。
public class Main {
public static void main(String[] args) {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("Thread is running");
}
});
thread.start(); // 启动线程
}
}
说说线程的生命周期和状态
Java 线程在运行的生命周期中的指定时刻只可能处于下面 6 种不同状态的其中一个状态:
- NEW:初始状态,线程被创建了,但没有使用
start()。 - RUNNABLE:运行状态,线程被
start(),等待运行的状态。 - BLOCKED:阻塞状态,等待锁的释放。
- WAITING:等待状态,线程等待其他线程做任务。
- TIME_WAITING:超时等待状态,在指定时间后自行返回。
- TERMINATED:终止状态,线程运行完毕。
拓展知识:
- 可以直接调用 Thread 类的 run 方法吗?:调用
start()方法方可启动线程并使线程进入就绪状态,直接执行run()方法的话不会以多线程的方式执行。
谈谈你对线程安全和不安全的理解
- 线程安全和不安全:指在多线程环境下,对同一份数据的访问是否能够保证其正确性和一致性(安全则保证了正确性和一致性,不安全则可能导致数据混乱、丢失、错误)。
什么是死锁?
描述:
- 指两个或多个线程在执行过程中因争夺资源而相互等待,导致所有线程都无法继续执行的情况。
- 简单来说,各个线程都在等待其他线程释放资源,而它们又不释放资源,最终陷入无限的等待。
四个必要条件:
- 互斥条件:某资源任意时刻只有一个线程占有。
- 请求与保持条件:一个线程持有某资源,同时请求新资源被阻塞,且对现有资源不释放。
- 不剥夺条件:线程持有资源未释放时,其他线程不能强行剥夺(独占)。
- 循环等待条件:多个线程之间形成一条头尾相连的循环等待关系(A->B->C->A)。
如何检测死锁?
- 使用 JDK 自带工具:
jmp、jstack等命令查看虚拟机线程和堆内存使用情况。一般出现线程的或会有deadlock的关键字样。 - 使用
top、df、free等命令查看CPU或内存使用情况,死锁时,通常会占用比较高。 - 使用
jconsole可视化工具来检测死锁。
如何预防和避免死锁?
如何预防:
- 破坏请求与保持条件:一次性申请所有的资源。
- 破会不剥夺条件:占用部分资源的线程再申请其他资源时,申请不到,就主动释放当前资源。
- 破坏等待条件:确保所有线程按照相同的顺序请求资源。
如何避免:
- 获取锁时设置一个合适的持有时间。
- 在分配资源时,借助算法(银行家算法)来对资源进行分配进行计算评估,使其进入安全状态。
谈谈你对volatile的理解
描述:
- 轻量级的同步机制。
- 用于确保可见性和有序性。
- 用于修饰变量。
主要作用:
- 可见性:每次对该变量的读写操作都会直接从主内存中进行。
- 有序性:JVM 具有指令重排的特性,使用
volatile可以让代码按顺序的进行与预期一致。
缺点:
- 不保证复合操作原子性:例如,使用
volatile修饰的自增操作(i++)并不是原子操作,因为它涉及读取、增加、写回等多个步骤,这种操作即使使用volatile也无法确保线程安全。
乐观锁和悲观锁
谈谈你对synchronized的理解
描述:
- synchronized 加锁的本质都是对对象监视器 monitor 的获取。
- 在 Java 6 之后,
synchronized进行了优化如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
主要作用:
- 在多线程之间访问资源的同步性,保证被它修饰的代码块或方法在某一时刻只有一个线程可以访问。
- 可以通过
wait()和notify()/notifyAll()方法来实现等待/通知机制。
使用:
- 修饰实例方法:进入同步代码时,需要获取当前对象实例的锁。
synchronized void method() {
//业务代码
}
- 修饰静态方法:对当前类加锁,作用于类的所有对象实例,进入同步代码块时,要获得当前类(class)的锁。
synchronized static void method() {
//业务代码
}
- 修饰代码块:使用
object,进入前需要获取给定对象的锁。使用类.class,进入前需要获取给定的 Class 的锁。
synchronized(this) {
//业务代码
}
综上:
- synchronized 加到
static方法和synchronized(class)代码块上都是给 Class 类加锁。 - synchronized 加到实例方法上都是给对象实例上锁。
ReentrantLock是什么?
- ReentrantLock 实现了 Lock 接口。
- 可重入且可独占式的锁。
- 提供了轮询、超时、中断、公平锁盒非公平锁等高级功能。
- 默认使用非公平锁,也可以通过构造器来显式的指定公平锁。
- 需要显式的调用
lock()和unlock()来加锁和释放锁。
synchronized和ReentrantLock的区别?
- 都是可重入锁:线程可以再次获取自己的内部锁。比如一个线程获取了某个对象锁,此时这个对象锁还没释放,当其再次想获取这个锁的时候还是可以获取的,如果不可重入的话,就会变成死锁了。
- synchronized 依赖 JVM 而 ReentrantLock 依赖API:ReentrantLock 需要
lock()和unlock()方法配合try/finally语句来完成。 - ReentrantLock 提供了更多功能:如等待可中断(
lock.lockInterruptibly)、可实现公平锁、锁可以绑定多个条件(借助于Condition接口与newCondition()方法)。
AQS是什么?
描述:
- Java 并发包中的一个核心的同步框架,它定义了一套多线程访问共享资源的同步机制。
- 通过
volatile关键字来维护变量int state来表示同步状态。 - 通过 FIFO 队列(基于双向链表)来管理获取同步失败的线程。
- 当获取同步状态失败后,会被放入到等待队列中阻塞,直到同步状态释放后,队列中线程就会从等待队列中唤醒,并重新尝试获取同步状态。
两种资源共享方式:
- 独占模式:一次只有一个线程可以获取到同步状态,如
ReentrantLock。 - 共享模式:允许多个线程同时获取到同步状态,但是可能获取到的资源量不同,如
Semaphore和CountDownLatch。
CountDownLatch是什么?
- 它采用了共享锁来实现,构造了 AQS 的
state的值为count。 - 本质使用
tryReleaseShared()方法以 CAS 操作来减少count的值。 - 当调用
await()方法时,如果count不为 0 ,await()方法就会被阻塞(后面的语句无法执行),直到count个线程全部执行完成,把count变成 0 ,await()线程才会被唤醒,继续执行await()方法后面的语句。
ThreadLocal是什么?
描述:
- 让每个线程绑定自己的值。
- 可以比喻成存放数据的盒子,盒子中存放的是每个线程的私有数据。
原理:
- 最终的变量是存放在
ThreadLocalMap中,可以理解为ThreadLocal只是ThreadLocalMap的封装,传递了变量值。 - 每个
Thread中都有一个ThreadLocalMap,而ThreadLocalMap可以存储ThreadLocal为 key ,Object 对象为 value 的键值对。 - 不同线程的
ThreadLocalMap是相互独立的,不同线程对同一ThreadLocal的操作互不影响。
源码:
public void set(T value) {
// 获取当前线程
Thread t = Thread.currentThread();
// 获取当前线程的 ThreadLocalMap
ThreadLocalMap map = getMap(t);
if (map != null) {
// 如果 map 存在,则将当前 ThreadLocal 实例和 value 存入 map
map.set(this, value);
} else {
// 如果 map 不存在,则创建一个新的 map
createMap(t, value);
}
}
public T get() {
// 获取当前线程
Thread t = Thread.currentThread();
// 获取当前线程的 ThreadLocalMap
ThreadLocalMap map = getMap(t);
if (map != null) {
// 从 map 中获取当前 ThreadLocal 实例对应的值
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
// 如果 map 或 entry 不存在,则初始化
return setInitialValue();
}
ThreadLocal内存泄露问题
描述:
ThreadLocalMap的 key 为弱引用,而 value 为强引用。- 如果
ThreadLocal没有外部强引用的情况下,在垃圾回收时,key 会被清理掉,而 value 不会。 - 导致
ThreadLocalMap中出现 key 为 null 的 Entry,而 value 不会被 GC 回收,就产生内存泄露。
措施:
- 在使用
set()、get()、remove()方法时,会清理掉 key 为 null 的记录,使用完ThreadLocal后最好手动调用remove()方法。
线程池是什么?
描述:管理一系列线程的资源池。
作用:
- 降低资源的消耗:通过复用已有线程,降低线程创建和销毁的消耗。
- 提高响应速度:当任务到达时,可以不用等到创建线程就可以执行任务。
- 提高线程的可管理性:使用线程池可以同一分配线程,调优和监控。
创建线程池:
- 通过
ThreadPoolExecutor构造函数来创建(推荐)。 - 通过
Executor框架的工具类Executors来创建。(不推荐)。
Executors返回线程池对象的弊端:
FixedThreadPool和SingleThreadExecutor使用的是有界阻塞队列LinkedBlockingQueue,最大长度为Integer.MAX_VALUE,可能会堆积大量请求,导致 OOM 。CacheThreadPool使用的是SynchronousQueue,也是最大长度为Integer.MAX_VALUE,如果任务数量过多且执行较慢,会导致创建大量的线程,导致 OOM 。ScheduledThreadPool和SingleThreadScheduledExecutor使用的是无端延迟阻塞队列DelayedWorkQueue,最大长度也是Integer.MAX_VALUE,可能对接大量请求,导致 OOM 。
线程池的七个参数
corePoolSize:核心线程数。即在没有新任务提交时,线程池中保持的最小线程数。maximumPoolSize:最大线程数。当任务队列满时,可同时运行的线程数。workQueue:任务队列。新来的任务先判断线程数是否到达核心线程数,到达了就会把任务放到任务队列进行等待。keepAliveTime:线程池数量大于corePoolSize后,有非核心线程时,这些空闲的非核心线程不会立即销毁,到达keepAliveTime才销毁。unit:时间单位。threadFactory:线程工厂,用于创建新线程。handler:拒绝策略。
线程池拒绝策略
- AbortPolicy:当线程池无法接受新的任务时,该策略会直接抛出一个
RejectedExecutionException异常,通知提交任务的线程任务被拒绝了。 - CallerRunsPolicy:当线程池无法接受新的任务时,该策略不会丢弃任务或者抛出异常,而是将任务交给调用线程(即提交任务的线程)来执行。这可能会导致调用线程阻塞,直到任务完成。
- DiscardPolicy:当线程池无法接受新的任务时,该策略会直接丢弃任务,不做任何处理,也不抛出异常。
- DiscardOldestPolicy:当线程池无法接受新的任务时,该策略会丢弃等待队列中最旧的未处理任务,然后尝试重新提交被拒绝的任务。
当不希望任务被丢弃时,可采取的策略:
- 设计一张任务表(Tasks),将任务存储到 MySQL 中。
- 使用 Redis 缓存任务。
- 将任务放到消息队列中。
线程池中线程异常后,销毁还是复用?
如何设置线程池参数?
广泛的公式:
- CPU 密集型任务(N+1):多出来一个主要是为了防止线程偶尔的缺页中断,或其它原因导致任务暂停,当任务暂停后,CPU 会处于空闲状态,而多出来一个线程可以充分的利用 CPU 的空闲时间。
- I/O 密集型任务(2N):这种系统大部分的时间都在处理 I/O 任务,而处理 I/O 这段时间内,不会占用 CPU 来处理,这时可以将 CPU 交给其他线程使用。(选择2N可能是为了避免过多的创建线程吧)
动态线程池
推荐 why 神的 如何设置线程池参数?美团给出了一个让面试官虎躯一震的回答。
如何设计一个能够根据任务优先级来执行的线程池?
- 可以采用优先阻塞队列
PriorityBlockingQueue作为线程池任务队列。 - 让提交到线程池的任务实现
Comparable接口,同时重写compareTo接口来自定义任务排序规则。 - 创建优先阻塞任务队列时,传入一个
Comparator对象来自定义排序规则(推荐)。
Spring 知识
谈谈你对IOC的理解
IOC(Inversion of Control控制反转):原本在应用程序中手动创建对象的控制权,交给 Spring 管理。
- 控制:对象创建(实例化、管理)的权利。
- 反转:控制权交给外部环境(Spring框架、IOC容器)。
主要作用:将对象之间的相互依赖的关系交给 IOC 容器来管理,并由 IOC 容器来完成对象的注入。
Bean的注入方式
Bean:指被 IOC 管理的对象。
依赖注入 (Dependency Injection, DI)
- 构造函数注入(官方推荐)。
@Component
public class MyService {
private final MyRepository myRepository;
public MyService(MyRepository myRepository) {
this.myRepository = myRepository;
}
// 业务逻辑方法
}
- Setter方法注入。
@Component
public class MyService {
private MyRepository myRepository;
@Autowired
public void setMyRepository(MyRepository myRepository) {
this.myRepository = myRepository;
}
// 业务逻辑方法
}
- 字段注入。
@Component
public class MyService {
@Autowired
private MyRepository myRepository;
// 业务逻辑方法
}
Bean的生命周期
- 创建 Bean 实例:通过配置文件中的 Bean 定义,使用 Java 反射 API 创建 Bean 实例。
- Bean 属性赋值/填充:为 Bean 设置相关属性和依赖。如 @Autowired 或 @Resource 注入的各种对象或资源、@Value 属性注入的值、Setter 方法注入的依赖和值等等。
- Bean 初始化:
- 如果 Bean 实现了
BeanNameAware接口,就调用setBeanName()方法,传入 Bean 的名字。 - 如果 Bean 实现了
BeanClassLoaderAware接口,就调用setBeanClassLoader()方法,传入ClassLoader对象实例。 - 如果 Bean 实现了
BeanFactoryAware接口,就调用setBeanFactory()方法,传入BeanFactory对象实例。 - 如果配置了
BeanPostProcessor,初始化前就调用postProcessBeforeInitialization方法。 - 如果 Bean 实现了
InitializingBean接口,就调用afterPropertiesSet方法。 - 如果配置文件包含
init-method属性,就执行指定方法。
- 如果 Bean 实现了
- 销毁 Bean:
- 把 Bean 销毁的方法记录下来,当需要销毁时,就调用这些方法去释放 Bean 所持有的资源。
- 如果 Bean 实现了
DisposableBean接口,就执行destroy()方法。 - 如果 Bean 配置文件包含
destroy-method属性,执行指定的 Bean 销毁方法。
综上:
- 实例化->属性赋值->初始化->销毁
- 初始化:主要包含
Aware接口的依赖注入、BeanPostProcessor初始化前后的处理、InitializingBean和init-method的初始化操作。 - 销毁:注册相关销毁接口、通过
DisposableBean和destroy-method进行销毁。
@Autowired和@Resource的区别?
- @Autowired 是 Spring 提供的注解,@Resource 是 JDK 提供的注解。
- @Autowired 默认使用
byType根据类型进行注入,@Resource 默认使用byName根据名称进行注入。 - 当一个接口下存在多个实现类,@Autowired和@Resource都需要指定
Name来匹配对应的 Bean 。@Autowired 使用@Qualifier注解来指定名称,@Resource 使用name参数来指定。 - @Autowired 支持在构造函数、方法、字段、参数上使用。@Resource 支持在方法和字段上使用。
Spring AOP是什么?
AOP(Aspect-Oriented Programming:面向切面编程)
描述:
- 能够将那些与业务无关的,却为业务模块所共同调用的逻辑或责任(如:事务管理、日志管理、权限控制等)封装起来。
- AOP 是基于动态代理,需要代理对象时,可以通过 JDK Proxy 去创建代理对象。
- 也可以通过 AspectJ 实现 AOP 。
原理:
- 切面(Aspect): 切入点(Pointcut)+通知(Advice)。
- 通知(Advice): 切面在特定的连接点执行的动作。
- 连接点(Join Point): 目标对象的所属类中,定义的所有方法均为连接点。
- 切入点(Pointcut): 被切面拦截 / 增强的连接点(切入点一定是连接点,连接点不一定是切入点)。
- 织入(Weaving): 将通知应用到目标对象,进而生成代理对象的过程动作。
AspectJ定义的通知类型有哪些?
- Before(前置通知)
- After(后置通知)
- AfterReturning(返回通知)
- AfterThrowing(异常通知)
- Around(环绕通知):编程式控制目标对象的方法调用。
多个切面的执行顺序如何控制?
- 使用
@Order注解直接定义切面顺序(值越小优先级越高)。
@Aspect
@Component
@Order(1) // 优先级最高,最先执行
public class FirstAspect {
// 切面逻辑
}
@Aspect
@Component
@Order(2) // 优先级其次,第二个执行
public class SecondAspect {
// 切面逻辑
}
- 实现
Ordered接口重写getOrder方法。
@Aspect
@Component
public class FirstAspect implements Ordered {
@Override
public int getOrder() {
return 1; // 优先级最高,最先执行
}
// 切面逻辑
}
@Aspect
@Component
public class SecondAspect implements Ordered {
@Override
public int getOrder() {
return 2; // 优先级其次,第二个执行
}
// 切面逻辑
}
Spring MVC的核心组件
DispatcherServlet:核心中央处理器,负责接收请求、分发,给予客户端响应。HandlerMapping:处理器映射,根据 URL 去匹配查找能处理的Handler,并将会涉及到的拦截器和Handler一起封装。HandlerAdapter:处理器适配器,根据HandlerMapping找到的Handler,适配执行对应的Handler。Handler:请求处理器,处理实际请求的处理器。ViewResolver:视图解析器,根据Handler返回的逻辑视图,解析并渲染真正的视图,并传递给DispatcherServlet响应客户端。
Mybatis 知识
#{}和${}的区别是什么?
#{}:是占位符语法,用于安全的传递参数。会使用预编译的 SQL 语句,并将参数值绑定为变量传递给数据库。(可以有效防止 SQL 注入攻击)
<select id="selectUser" resultType="User">
SELECT * FROM users WHERE id = #{id}
</select>
在这个例子中,`#{id}` 会被替换为一个占位符(例如 `?`),并且实际的参数值会在 SQL 执行时绑定到这个占位符。
${}:是字符串替换语法,用于直接将参数值嵌入到 SQL 中。不会进行预编译,因此存在 SQL 注入问题。
<select id="selectUser" resultType="User">
SELECT * FROM users WHERE id = ${id}
</select>
在这个例子中,`${id}` 会被直接替换为参数的值。
Dao接口的原理是什么?
Dao 接口就是常说的 Mapper 接口。
描述:
- 一般在项目中都会有一个 xml 文件和一个 Dao 接口与之对应。
- 接口的全限定名称,就是映射文件的
namespace的值。 - 接口方法名,就是映射文件的
MappedStatement的 id 值。 - 接口方法内的参数,就是传递给 sql 的参数。
Dao接口方法,参数不同时,方法可以重载吗?
Dao 接口方法可以重载,需要满足几个条件:
- 仅有一个无参方法和一个有参方法。
- 多个无参方法时,参数数量保持一致。需使用相同的
@Param或param1。
参考:Dao工作原理
Mybatis的动态SQL有哪些?
动态 SQL 可以以标签的形式,进行逻辑判断和动态拼接 SQL 的功能。
<if></if><bind/><where></where><choose></choose><foreach></foreach>















 489
489

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









