






机器学习
机器学习库
scikit-learn,tensorflow
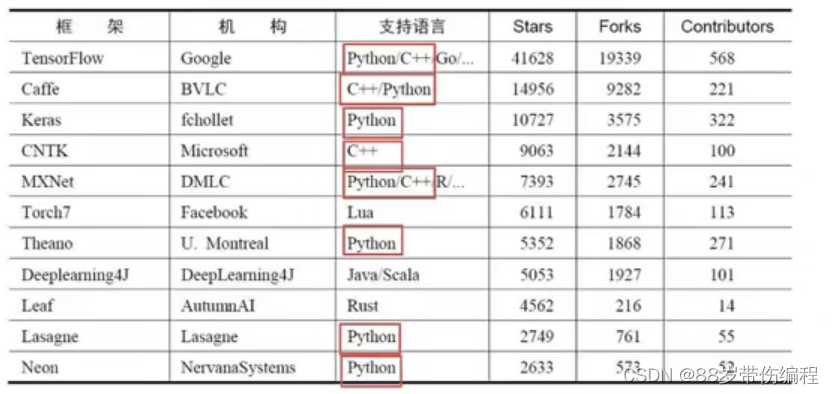
机器学习框架:
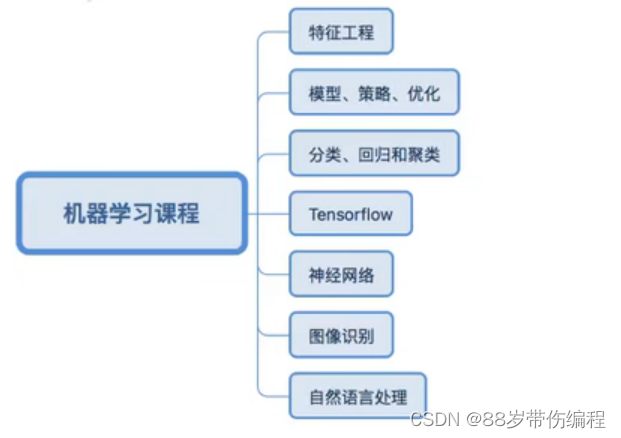
什么是机器学习?

数据集的组成
机器学习的数据:csv文件
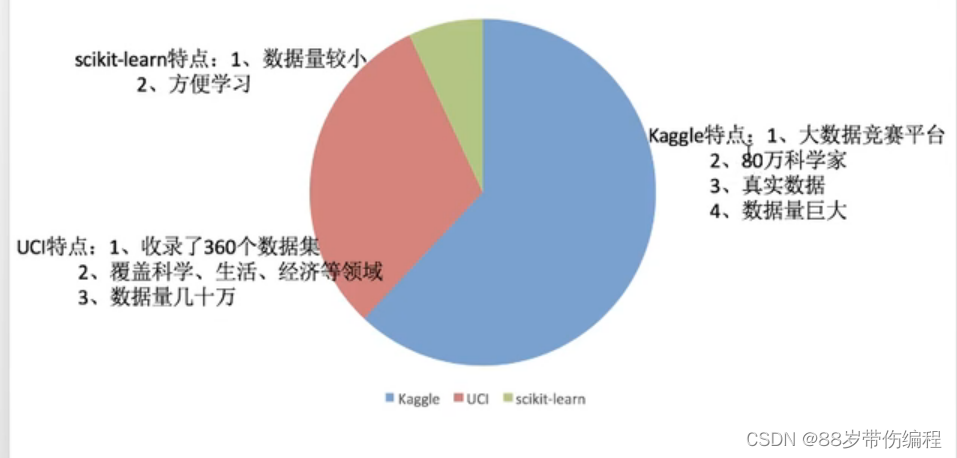
可用数据集:
常用数据集数据的结构:特征值+目标值。

根据特征找目标(进行判断)。
注:有些数据集可以没有目标值。
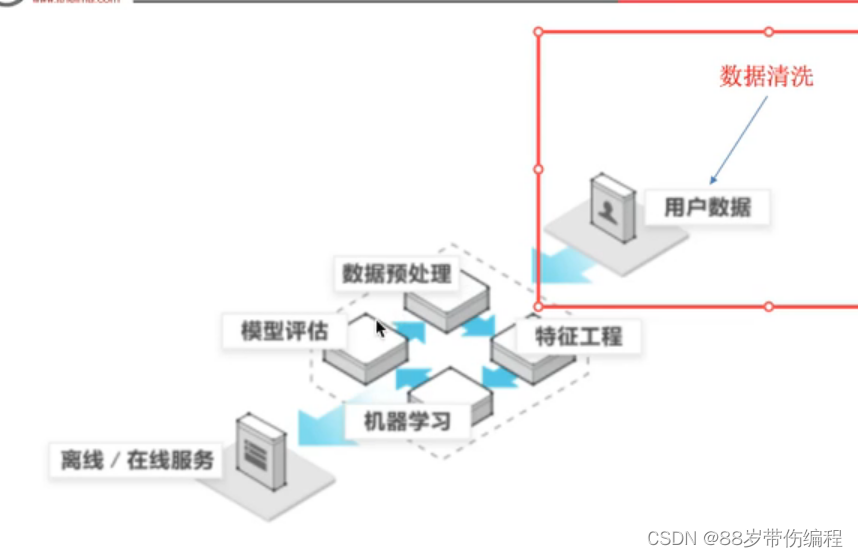
特征工程
特征工程是什么?



安装Scikit-learn:
pip3 install Scikit-learn
要在python安装目录下找到script,进行安装
输入以下指令判断是否安装成功。
import sklearn
注:安装前需要numpy,pandas等库
字典特征数据抽取
也就是转化为数字值,方便计算机识别

流程:

from sklearn.feature_extraction import DictVectorizer
def dictvet():
dict=DictVectorizer() #实例化
#传的是列表数据
data=dict.fit_transform([{"city":"北京","温度":100},{"city":"上海","温度":60},
{"city":"广州","温度":30}])
print(dict.get_feature_names_out()) #得到特征值
print(data) #默认返回一个sparse矩阵
#字典类型抽取:把字典中一些类别数据,分别进行转化为特征,使用one-hot编码,数字不需要变
#如果是数组类型数据,有类别,先转化为字典,在进行抽取
return None
dictvet()
运行结果:
['city=上海' 'city=北京' 'city=广州' '温度']
(0, 1) 1.0
(0, 3) 100.0
(1, 0) 1.0
(1, 3) 60.0
(2, 2) 1.0
(2, 3) 30.0
from sklearn.feature_extraction import DictVectorizer
def dictvet():
dict=DictVectorizer(sparse=False)
data=dict.fit_transform([{"city":"北京","温度":100},{"city":"上海","温度":60},
{"city":"广州","温度":30}])
print(data)
return None
dictvet()
运行结果:
[[ 0. 1. 0. 100.]
[ 1. 0. 0. 60.]
[ 0. 0. 1. 30.]]

文本特征数据抽取

和字典特征抽取大同小异。
from sklearn.feature_extraction.text import CountVectorizer #导入包
def countvec():
cv=CountVectorizer() #实例化
#传列表类型
data=cv.fit_transform(["Life is short,i like python","Life is too long,i dislike python"])
print(cv.get_feature_names_out()) #得出统计文章中所有的词,重复的只看做一次,单个字母不统计
print(data) #也是返回sparse矩阵,但是CountVectorizer api没有sparse参数,所以只能通过toarray将sparse转为数组形式
print(data.toarray())
countvec()
运行结果:
['dislike' 'is' 'life' 'like' 'long' 'python' 'short' 'too']
(0, 2) 1
(0, 1) 1
(0, 6) 1
(0, 3) 1
(0, 5) 1
(1, 2) 1
(1, 1) 1
(1, 5) 1
(1, 7) 1
(1, 4) 1
(1, 0) 1
[[0 1 1 1 0 1 1 0]
[1 1 1 0 1 1 0 1]]
对于中文文章:
应该先进行分词操作,使用jieba库
下载:
pip3 install jieba
from sklearn.feature_extraction.text import CountVectorizer #导入包
import jieba
def hanzivec():
dv = CountVectorizer() # 实例化
data1 = dv.fit_transform([' '.join(list(jieba.cut("人生苦短,及时行乐"))),
' '.join(list(jieba.cut("不以物喜,不以己悲")))]) #' '.join()转化为字符串
# 使用jieba进行分词,还需要转化为列表类型,再转化为字符串类型
print(dv.get_feature_names_out()) # 对于中文不支持这种抽取,因为不能表达出这篇文章的主题,先进行分词,
# 再进行抽取,英文不需要分词
print(data1)
print(data1.toarray())
运行结果:
['不以' '不以己' '人生' '及时行乐' '物喜' '苦短']
(0, 2) 1
(0, 5) 1
(0, 3) 1
(1, 0) 1
(1, 4) 1
(1, 1) 1
[[0 0 1 1 0 1]
[1 1 0 0 1 0]]
#若得到的列表相差不大,我们就可以进行预测















 2424
2424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









