






目录
前言
本文章是利用python爬虫对指定登录页面进行验证码识别,并进行模拟登录的操作,主要是基于python中xpath和超级鹰验证码识别这两个模块来实现。
一、超级鹰的注册
超级鹰网址:超级鹰验证码识别-专业的验证码云端识别服务,让验证码识别更快速、更准确、更强大
点击右上方注册按钮,分别进行用户中心注册和软件开发商注册。注册过后进行软件开发商登录
并点击软件ID添加一个软件ID(随机注册)。
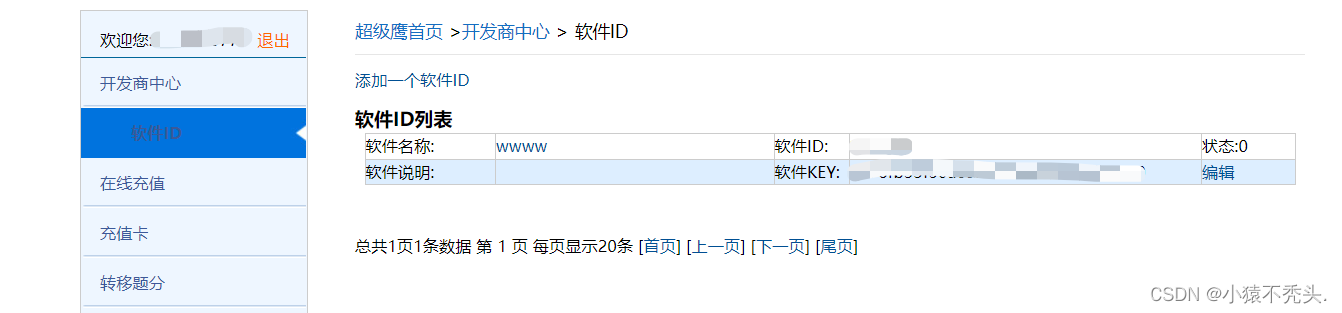
注册好后我们点击开发文档下载python版的开发文档并保存。
二、利用xpath解析登录页面的验证码图片
xpath解析
指定url,获取相应数据,解析获取验证码图片的url,再次发送请求,持久化存储
代码如下:
#指定url
url = "https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36"
}
#发送请求
page_text = requests.get(url=url, headers=headers).text
tree = etree.HTML(page_text)
# 进行数据解析
code_img = "https://so.gushiwen.cn" + tree.xpath('//*[@id="imgCode"]/@src')[0]
# print(code_img)
# 对验证码图片进行请求
img_data = requests.get(url=code_img, headers=headers).content
# 持久化存储
with open("./code.jpg", "wb") as fp:
fp.write(img_data)三、利用超级鹰识别获取验证码
示例如下
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files,
headers=self.headers)
return r.json()
def PostPic_base64(self, base64_str, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
'file_base64': base64_str
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
url = "https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36"
}
page_text = requests.get(url=url, headers=headers).text
tree = etree.HTML(page_text)
code_img = "https://so.gushiwen.cn" + tree.xpath('//*[@id="imgCode"]/@src')[0]
# print(code_img)
img_data = requests.get(url=code_img, headers=headers).content
with open("./code.jpg", "wb") as fp:
fp.write(img_data)
if __name__ == '__main__':
chaojiying = Chaojiying_Client('username', 'password', '软件ID')
#
# 用户名>>密码>> 软件ID
im = open('code.jpg', 'rb').read()
# 本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
pic = chaojiying.PostPic(im, 1902) # 1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
# print chaojiying.PostPic(base64_str, 1902) #此处为传入 base64代码
print(pic["pic_str"])
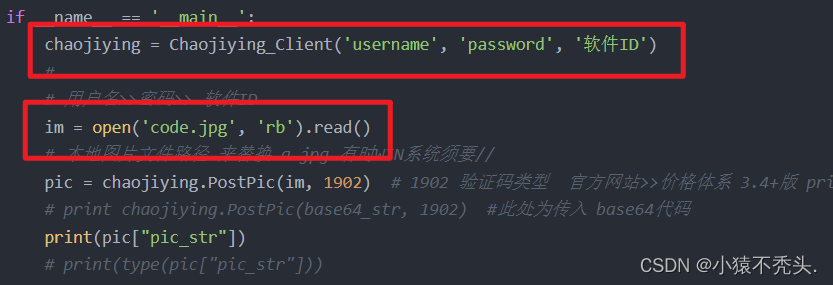
# print(type(pic["pic_str"]))以上我们下载的开发文档中我们要注意我们只需改动框选中的属性值(即我注册超级鹰中的用户名,密码)和添加软件生成的ID;图片即我们xpth解析获取的图片。
四、模拟浏览器发送请求进行模拟登录
以古诗词网为例
# post请求的发送
log_url= "https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx"
datas = {
"from": "http://so.gushiwen.cn/user/collect.aspx",
"email": "**********@qq.com",
"pwd": "********",
"code": pic["pic_str"],
"denglu": "登录"
}
response = requests.post(url=log_url,headers=headers,data=datas)
login_text = response.text
with open("gushi.html","w",encoding="utf-8")as fp:
fp.write(login_text)
print(login_text)
五、验证是否模拟登录成功
当浏览者访问一个网页时,浏览者的浏览器会向网页所在服务器发出请求。当浏览器接收并显示网页前,此网页所在的服务器会返回一个包含 HTTP 状态码的信息头(server header)用以响应浏览器的请求。
下面是常见的 HTTP 状态码:
- 200 - 请求成功
- 301 - 资源(网页等)被永久转移到其它URL
- 404 - 请求的资源(网页等)不存在
- 500 - 内部服务器错误
print(response.status_code)如果显示200则模拟登录成功。
喵都这么努力,你也要努力—https://v.douyin.com/rUvu8P4/














 778
778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









