







评估之模型评估
什么是模型评估
模型评估是指对训练的机器学习模型进行性能评估和验证的过程。模型评估旨在确定模型的泛化能力,即模型在未见过的数据上的表现。
下面是一些模型评估相关的概念:
训练集、验证集和测试集:在模型训练过程中,通常将数据集划分为训练集、验证集和测试集。训练集用于训练模型,验证集用于调整模型的超参数和评估模型的性能,而测试集则用于最终评估模型的泛化能力。
性能指标:模型评估的主要目标是使用适当的性能指标来衡量模型的表现。常见的性能指标包括准确率、精确率、召回率、F1分数、ROC曲线下面积等。
过拟合和欠拟合:模型评估也可以帮助识别模型的过拟合和欠拟合问题。过拟合指模型在训练集上表现良好但在测试集上表现较差,而欠拟合则指模型无法捕捉数据中的模式,导致在训练集和测试集上都表现不佳。
模型评估的意义
首先,研究评测对于我们全面了解大型语言模型的优势和限制至关重要。尽管许多研究表明大型语言模型在多个通用任务上已经达到或超越了人类水平,但仍然存在质疑,即这些模型的能力是否只是对训练数据的记忆而非真正的理解。例如,即使只提供LeetCode题目编号而不提供具体信息,大型语言模型也能够正确输出答案,这暗示着训练数据可能存在污染现象。
其次,研究评测有助于指导和改进人类与大型语言模型之间的协同交互。考虑到大型语言模型的最终服务对象是人类,为了更好地设计人机交互的新范式,我们有必要全面评估模型的各项能力。
最后,研究评测可以帮助我们更好地规划大型语言模型未来的发展,并预防未知和潜在的风险。随着大型语言模型的不断演进,其能力也在不断增强。通过合理科学的评测机制,我们能够从进化的角度评估模型的能力,并提前预测潜在的风险,这是至关重要的研究内容。
对于大多数人来说,大型语言模型可能似乎与他们无关,因为训练这样的模型成本较高。然而,就像飞机的制造一样,尽管成本高昂,但一旦制造完成,大家使用的机会就会非常频繁。因此,了解不同语言模型之间的性能、舒适性和安全性,能够帮助人们更好地选择适合的模型,这对于研究人员和产品开发者而言同样具有重要意义。
OpenCompass的使用
1.准备运行环境
面向开源模型的GPU环境
conda create --name opencompass python=3.10 pytorch torchvision pytorch-cuda -c nvidia -c pytorch -y
conda activate opencompass面向API模型测试的CPU环境
conda create -n opencompass python=3.10 pytorch torchvision torchaudio cpuonly -c pytorch -y
conda activate opencompass2.安装OpenCompass
git clone https://github.com/open-compass/opencompass.git
cd opencompass
pip install -e .3.准备数据集
OpenCompass 支持的数据集主要包括两个部分:
-
Huggingface 数据集: Huggingface Dataset 提供了大量的数据集,这部分数据集运行时会自动下载。
-
自建以及第三方数据集:OpenCompass 还提供了一些第三方数据集及自建中文数据集。运行以下命令手动下载解压。
在 OpenCompass 项目根目录下运行下面命令,将数据集准备至 ${OpenCompass}/data 目录下:
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip
unzip OpenCompassData-core-20240207.zip但是此数据集在后续的评估过程中经常发生缺失模组的报错,建议下载更完整的数据集:
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-complete-20240207.zip
unzip OpenCompassData-complete-20240207.zip
cd ./data
find . -name "*.zip" -exec unzip "{}" \;4.进行简单评估
python run.py --datasets ceval_gen
--hf-path /hy-tmp/7B21/merged
--tokenizer-path /hy-tmp/7B21/merged
--tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True
--model-kwargs trust_remote_code=True device_map='auto'
--max-seq-len 1024
--max-out-len 16
--batch-size 2
--num-gpus 1
--debug得到运行结果
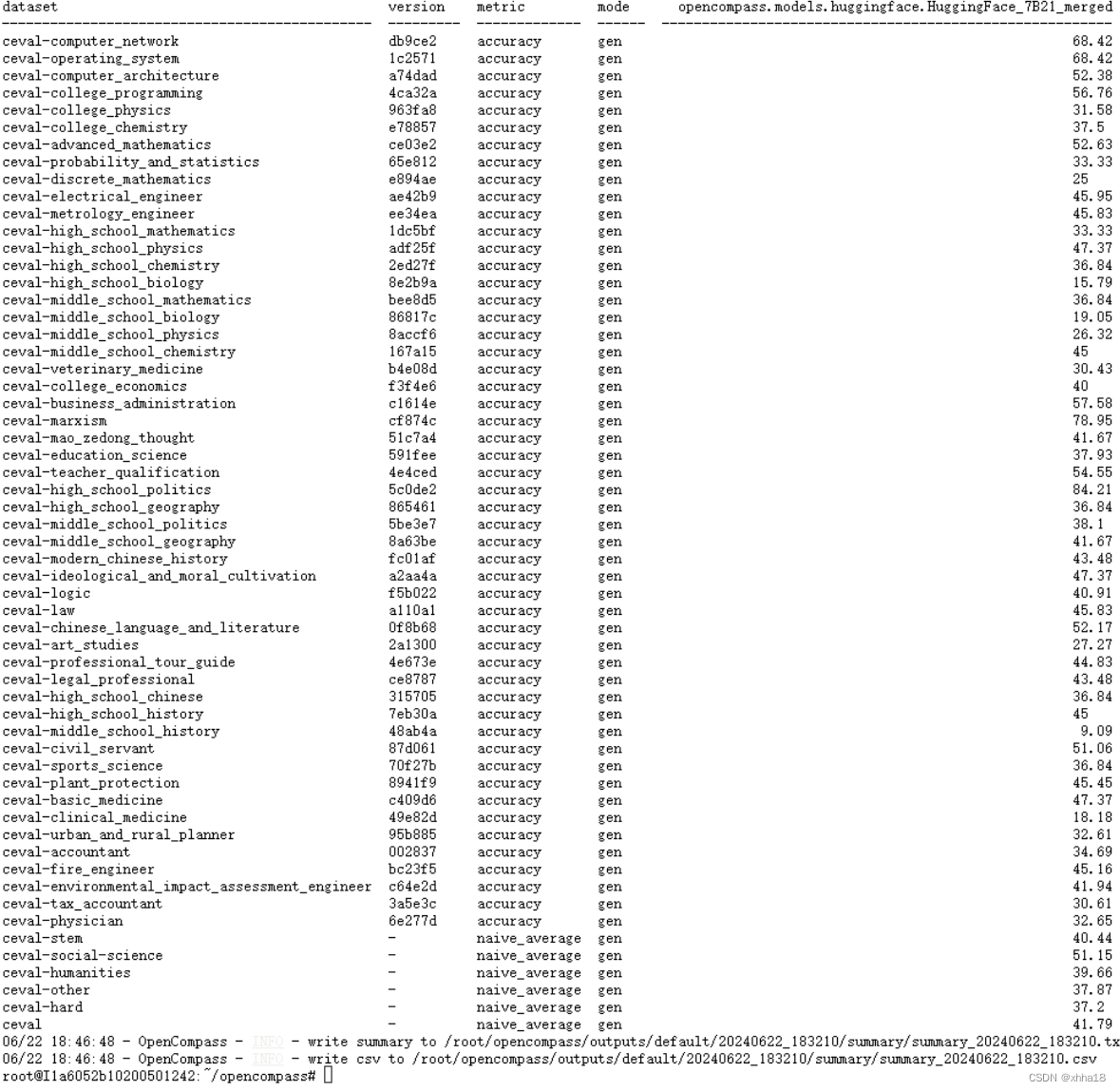
完成简单的评估。















 429
429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









