







最快的入门学习路线
之前妄图看几个博客花几十分钟就入门sql,其实是有点异想天开了.以我的水平还达不到看几篇博客就入门.摸爬滚打了一段时间之后总结出了我认为的最快的可以做项目应用sql的入门方法,推荐了一个千万观看,点赞量24w+的入门视频,以及一本快速入门的畅销书. 并提供一套舒适编辑环境方案,还有我的参考答案(在我认为比较难的地方做了标记). 油管上的教学视频可以在B站上找到无字幕版的,Mysql必知必会的书不贵(网上资源也很多).虽然我墙裂推荐买正版的,但是如果你想快速开始,仍然可以很快的在网上下到盗版的书(及其不推荐).
1. 一天时间,看四个小时视频,敲一遍视频里的代码,快速了解SQL的使用,建立大致的轮廓.
YouTube上有FreeCodeCamp的SQL四小时教程,可以带着初学者在一天内快速了解数据库的常用操作,建立对增删改查,建表,外键,触发器,ER图,数据库设计等的大体了解,学完这个再结合自己顺手的语言,可以快速搭建数据库查询的后端服务.

https://www.youtube.com/watch?v=HXV3zeQKqGY&t=4s
油管上看可以开中文字幕,还是很舒服的,B站上也有,但是看了一下发现没有字幕,没个英语四级的水平看起来估计会很难受.
SQL Tutorial - Full Database Course for Beginners_搜索_哔哩哔哩-bilibili
但是这个课程中的样例有限,一天时间学这么多东西,很容易忘记.而且越靠后,感觉越难,可能最后真的拿来用的时候,会逃避增删改查以外的操作.
2. 再快速看一遍SQL必知必会,做一遍练习巩固一下

如果时间充足,可以再花两天时间,看一遍SQL必知必会,看一遍书,把书上的练习都做了,趁着热乎,可能一天就够了,很快的.与其相同字数的小说,大概看个一两个小时不到就读完了.
SQL必知必会这本书,不愧是入门神书,感觉比大话数据结构看起来还简单,彻彻底底面向快速入门应用,提供通俗生动的讲解.示例代码可直接运行.几张表从书的开头用到最后,减少了读者去看表了解业务逻辑的时间.
3.拿自己的项目练手
这一步根据自己的情况来看就好了,看完第一个其实就可以上手了,但是可能掌握的很一般,写出来的orm很低级(不堪入目),感觉时间充足的话做完第二部再搞也不迟.
*4. 更进一步
写这篇博客的时候,博主目前还没到这一步,所以也给不出太多很好的意见.
一般学这些的多半是计算机类的专业,学校还会有专业课,看了下课程目录,有很多涉及到底层的东西,这些感觉不是能一两天快速入门的,不过靠着前两个先用起来,做点小项目,对后续理解书本上的东西会有帮助.
最舒适的编程环境
自学的路上摸爬滚打,用了许多SQL编辑器,最后找到还是这套环境用起来最舒服,墙裂推荐:
这些软件过于好用,以至于收费,不过新用户都有免费的体验时间(14天到一个月不等),如果正赶上国庆节放假之类有一整天的时间,花个两三天就把书上的练习做完了,根本等不到过期,很舒服.
环境配置
1.准备以下条件:
-
Navicate
Navicat | 下载 Navicat Premium 14 天免费 Windows、macOS 和 Linux 的试用版
是不是Premium版都行,推荐Premium版,主要是用这个直观的看数据库里的数据,下载好了有个十几天的试用.
-
Jetbrains DataGrip
Download DataGrip: Cross-Platform IDE for Databases & SQL (jetbrains.com)
比Popsql等感觉好用,可以之间运行触发器的sql语句,功能非常强大,也有三十天的免费试用期.
-
Git+Github/Gitee(可选)
gitee,本地gitlab都行,这里只给出git+github的示例了
-
MySql8.0
https://www.mysql.com/downloads/
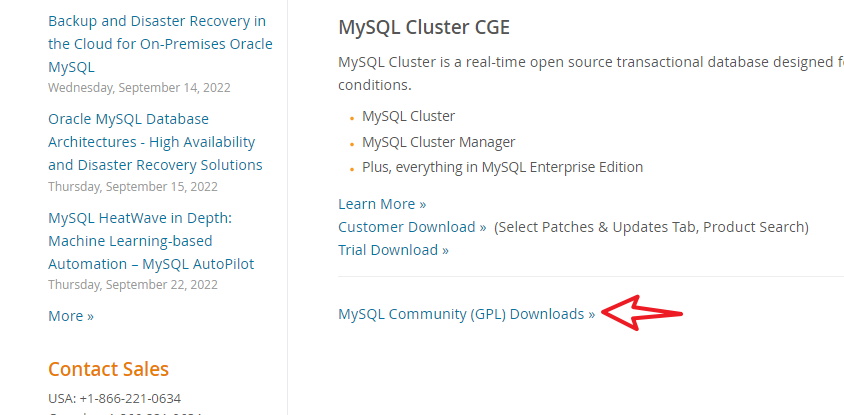
下载点这个开源版的就好了,不然好像还要一堆注册啥的,安装完了会自己后台运行,很省心. 会在引导界面里让用户自己设置用户名和密码, 用户名和密码要记住. 后续终端设备就是通过这个连接的.
-
StarUml(画ER图用,可选)
这个关系模型画出来后,只要信息给的全,图画的对,可以自动生成建表的SQL语句.
下载好了像安软件一样无脑next就好了,它自己会配置开机自启这些.
SQL必知必会目录
看完四小时的快速入门课程,快速看一遍SQL必知必会的目录,大概能回忆起来,没啥印象的地方一定要去做一下练习,不然很快就完全忘了.
mysql必知必会练习的参考答案放在了下一个章节里,其中链接给出的是官网的答案,博客里的也有我自己写的,我把我感觉不太理解的地方加了注释,还有些内容那个数据库里边没有,为了方便看到结果,改变了几个搜索的限制条件.
### 目录:第1 课 了解SQL 1
#### 1.1 数据库基础 1
#### 1.2 什么是SQL 6
#### 1.3 动手实践 7
#### 1.4 小结 9
### 第2 课 检索数据 10
#### 2.1 SELECT 语句 10
#### 2.2 检索单个列 11
#### 2.3 检索多个列 13
#### 2.4 检索所有列 14
#### 2.5 检索不同的值 15
#### 2.6 限制结果 17
#### 2.7 使用注释 20
#### 2.8 小结 22
#### 2.9 挑战题 22
### 第3 课 排序检索数据 23
#### 3.1 排序数据 23
#### 3.2 按多个列排序 25
#### 3.3 按列位置排序 26
#### 3.4 指定排序方向 27
#### 3.5 小结 30
#### 3.6 挑战题 30
### 第4 课 过滤数据 31
#### 4.1 使用WHERE 子句 31
#### 4.2 WHERE 子句操作符 33
#### 4.3 小结 37
#### 4.4 挑战题 38
### 第5 课 高级数据过滤 39
#### 5.1 组合WHERE 子句 39
#### 5.2 IN 操作符 43
#### 5.3 NOT 操作符 45
#### 5.4 小结 47
#### 5.5 挑战题 47
### 第6 课 用通配符进行过滤 49
#### 6.1 LIKE 操作符 49
#### 6.2 使用通配符的技巧 55
#### 6.3 小结 56
#### 6.4 挑战题 56
### 第7 课 创建计算字段 58
#### 7.1 计算字段 58
#### 7.2 拼接字段 59
#### 7.3 执行算术计算 65
#### 7.4 小结 67
#### 7.5 挑战题 67
### 第8 课 使用函数处理数据 68
#### 8.1 函数 68
#### 8.2 使用函数 69
#### 8.3 小结 77
#### 8.4 挑战题 77
### 第9 课 汇总数据 78
#### 9.1 聚集函数 78
#### 9.2 聚集不同值 85
#### 9.3 组合聚集函数 86
#### 9.4 小结 87
#### 9.5 挑战题 88
### 第10 课 分组数据 89
#### 10.1 数据分组 89
#### 10.2 创建分组 90
#### 10.3 过滤分组 92
#### 10.4 分组和排序 95
#### 10.5 SELECT 子句顺序 97
#### 10.6 小结 97
#### 10.7 挑战题 98
### 第11 课 使用子查询 99
#### 11.1 子查询 99
#### 11.2 利用子查询进行过滤 99
#### 11.3 作为计算字段使用子查询 103
#### 11.4 小结 106
#### 11.5 挑战题 107
### 第12 课 联结表 108
#### 12.1 联结 108
#### 12.2 创建联结 111
#### 12.3 小结 118
#### 12.4 挑战题 118
### 第13 课 创建高级联结 . 120
#### 13.1 使用表别名 120
#### 13.2 使用不同类型的联结 121
#### 13.3 使用带聚集函数的联结 127
#### 13.4 使用联结和联结条件 129
#### 13.5 小结 129
#### 13.6 挑战题 129
### 第14 课 组合查询 131
#### 14.1 组合查询 131
#### 14.2 创建组合查询 132
#### 14.3 小结 138
#### 14.4 挑战题 139
### 第15 课 插入数据 140
#### 15.1 数据插入 140
#### 15.2 从一个表复制到另一个表 147
#### 15.3 小结 148
#### 15.4 挑战题 149
### 第16 课 更新和删除数据 150
#### 16.1 更新数据 150
#### 16.2 删除数据 152
#### 16.3 更新和删除的指导原则 154
#### 16.4 小结 155
#### 16.5 挑战题 156
### 第17 课 创建和操纵表 157
#### 17.1 创建表 157
#### 17.2 更新表 162
#### 17.3 删除表 165
#### 17.4 重命名表 165
#### 17.5 小结 166
#### 17.6 挑战题 166
### 第18 课 使用视图 167
#### 18.1 视图 167
#### 18.2 创建视图 170
#### 18.3 小结 177
#### 18.4 挑战题 177
### 第19 课 使用存储过程 178
#### 19.1 存储过程 178
#### 19.2 为什么要使用存储过程 179
#### 19.3 执行存储过程 181
#### 19.4 创建存储过程 182
#### 19.5 小结 187
### 第20 课 管理事务处理 . 188
#### 20.1 事务处理 188
#### 20.2 控制事务处理 190
#### 20.3 小结 195
### 第21 课 使用游标 196
#### 21.1 游标 196
#### 21.2 使用游标 197
#### 21.3 小结 202
### 第22 课 高级SQL 特性 203
#### 22.1 约束 203
#### 22.2 索引 210
#### 22.3 触发器 212
#### 22.4 数据库安全 214
#### 22.5 小结 215
### 附录A 样例表脚本 216
### 附录B SQL 语句的语法 223
### 附录C SQL 数据类型 228
### 附录D SQL 保留字 234
### 常用SQL 语句速查 238
### 索 引 240
SQL必知必会练习
书籍配套资源网址:
Sams Teach Yourself SQL in 10 Minutes (Fifth Edition) – Ben Forta
1.环境配置与数据集下载
1.准备以下条件:
-
Navicate
Navicat | 下载 Navicat Premium 14 天免费 Windows、macOS 和 Linux 的试用版
是不是Premium版都行,推荐Premium版,主要是用这个直观的看数据库里的数据,下载好了有个十几天的试用.
-
Jetbrains DataGrip
Download DataGrip: Cross-Platform IDE for Databases & SQL (jetbrains.com)
比Popsql等感觉好用,可以之间运行触发器的sql语句,功能非常强大,也有三十天的免费试用期.
-
Git+Github(可选)
gitee,本地gitlab都行,这里只给出git+github的示例了
-
MySql8.0
https://www.mysql.com/downloads/
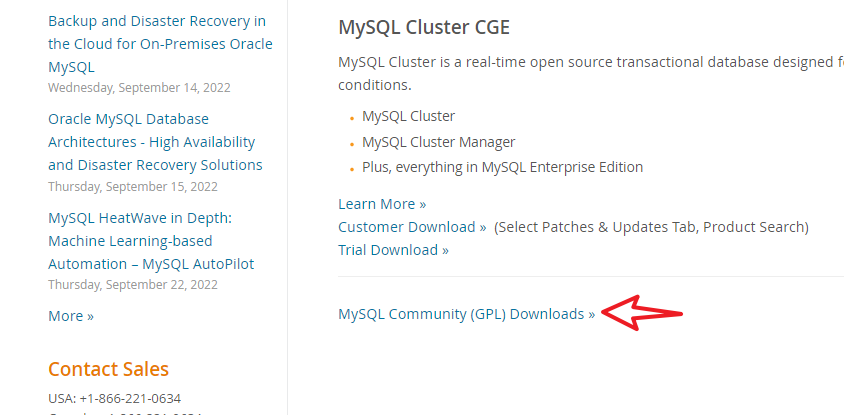
下载点这个开源版的就好了,不然好像还要一堆注册啥的,安装完了会自己后台运行,很省心. 会在引导界面里让用户自己设置用户名和密码, 用户名和密码要记住. 后续终端设备就是通过这个连接的.
-
StarUml(画ER图用,可选)
这个关系模型画出来后,只要信息给的全,图画的对,可以自动生成建表的SQL语句.
下载好了像安软件一样无脑next就好了,它自己会配置开机自启这些.
2.下载数据集
https://forta.com/books/0135182794/
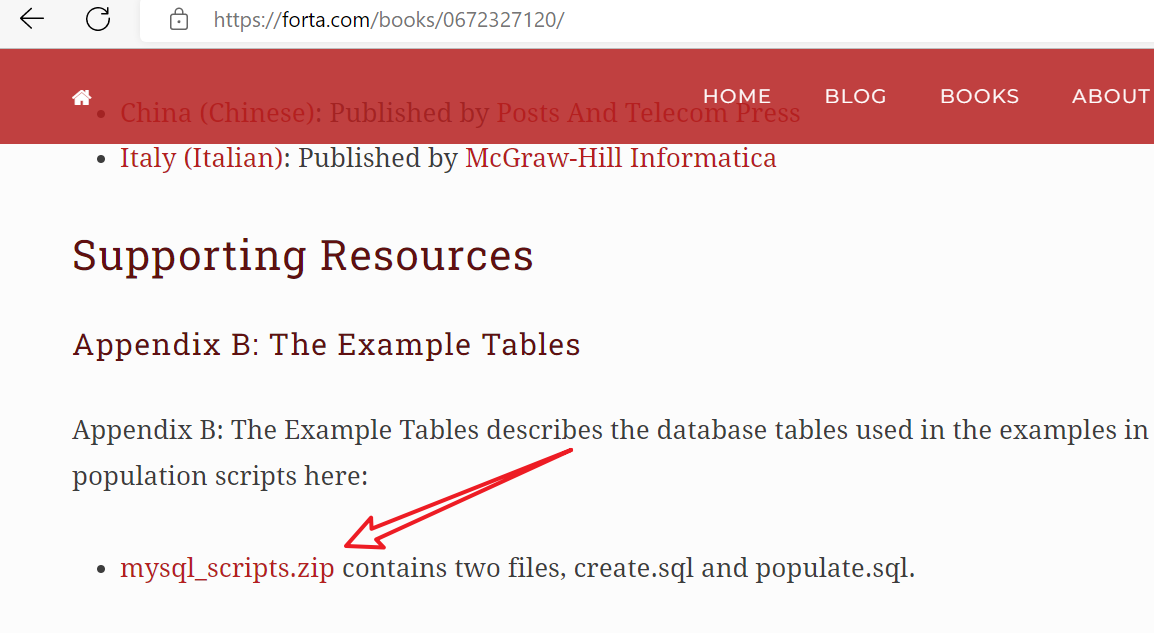
下载后加压到一个知道的地方,
随便建立一个数据库,我这里名字叫db_learning
然后运行sql文件:
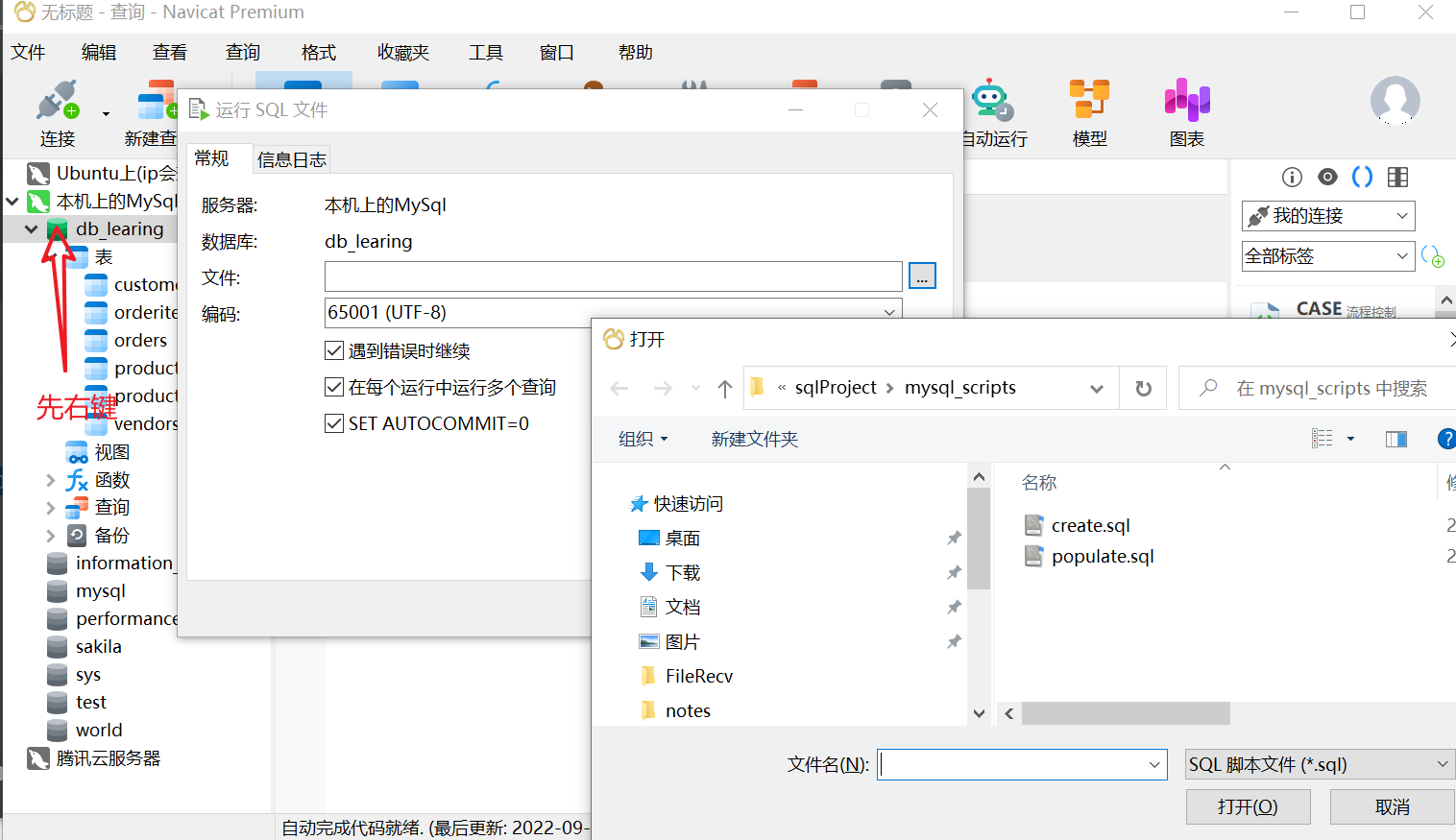
然后配置一下DataGrip连接:
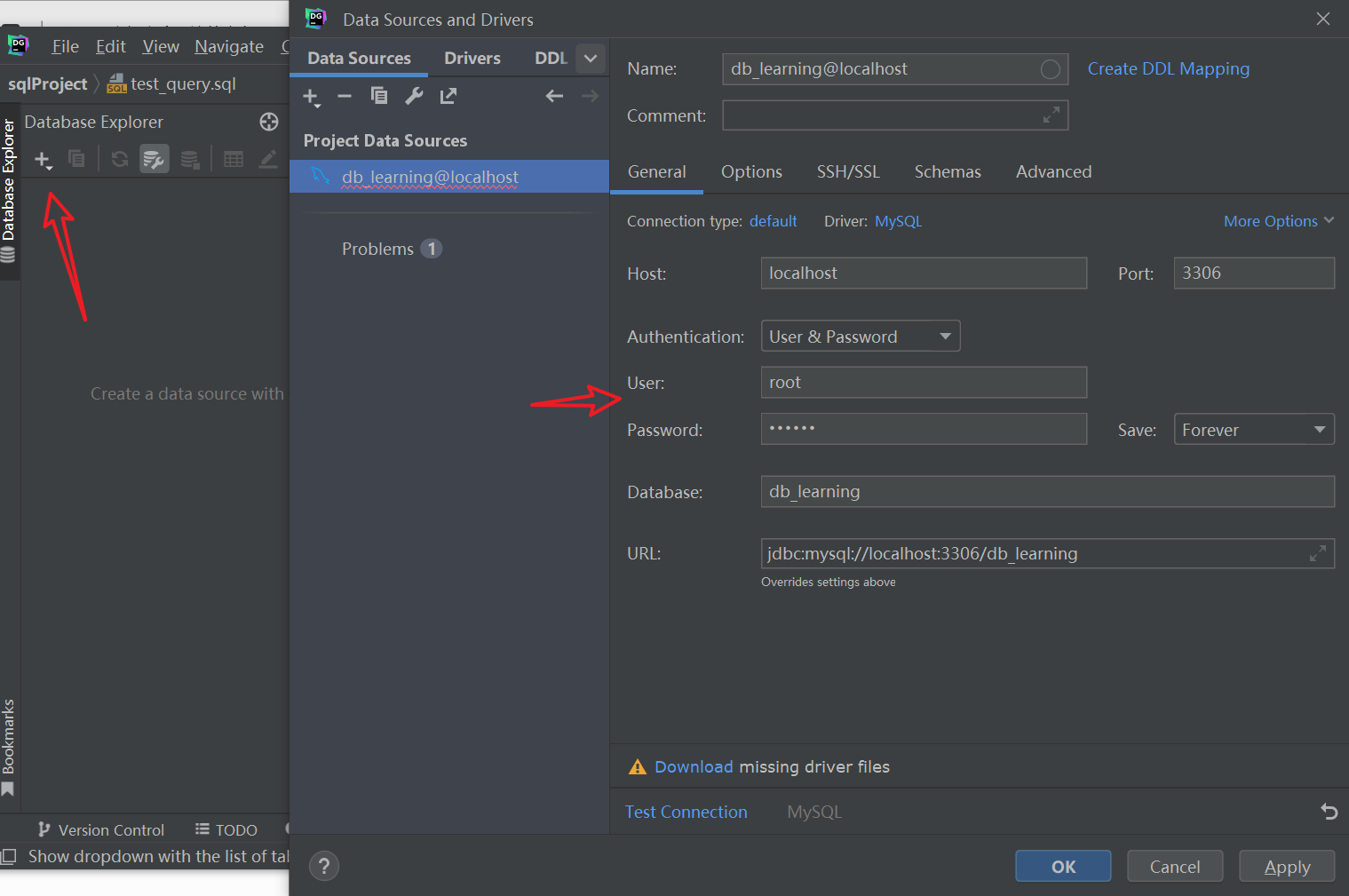
安装驱动: 点一下那个就好了
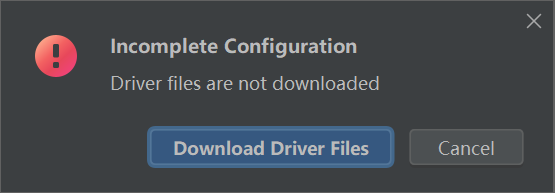
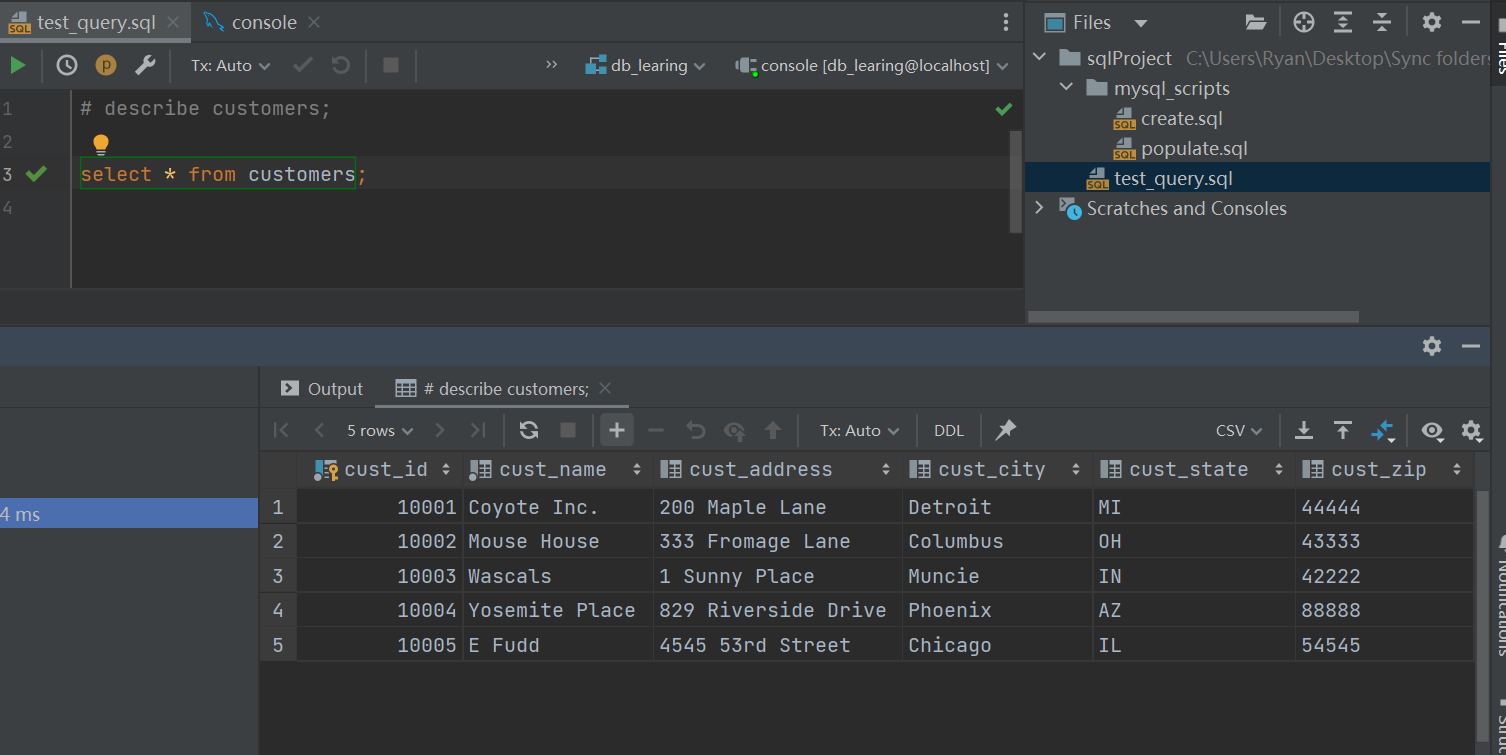
3.配置完成后随便运行一句话测试一下
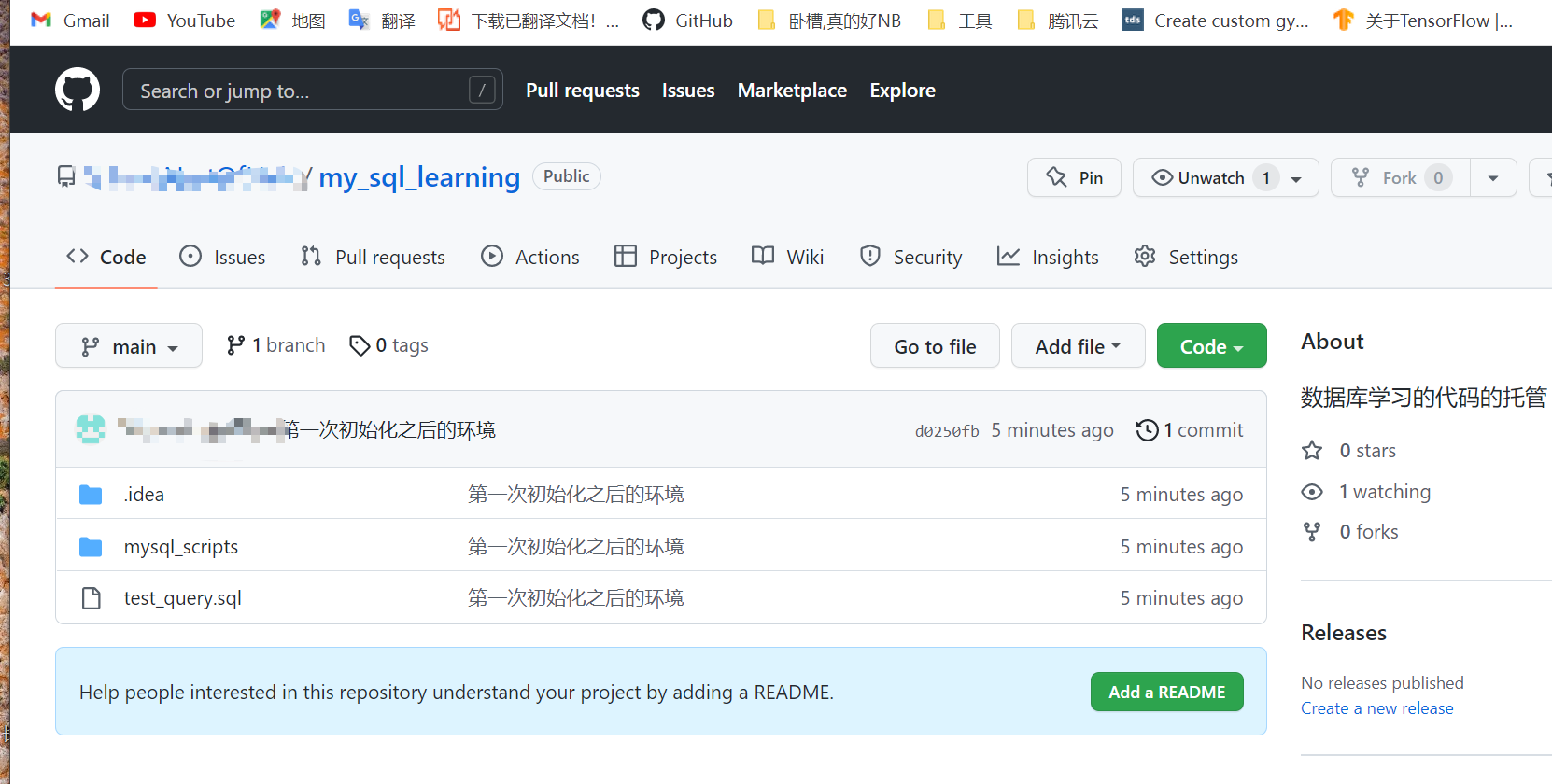
*4.git简单提交一下
SQL偏向一种工具,顺便和Git一起用也不错,一般这种的都是用着用着就会了,大概用个一年,就很熟悉很熟练了.
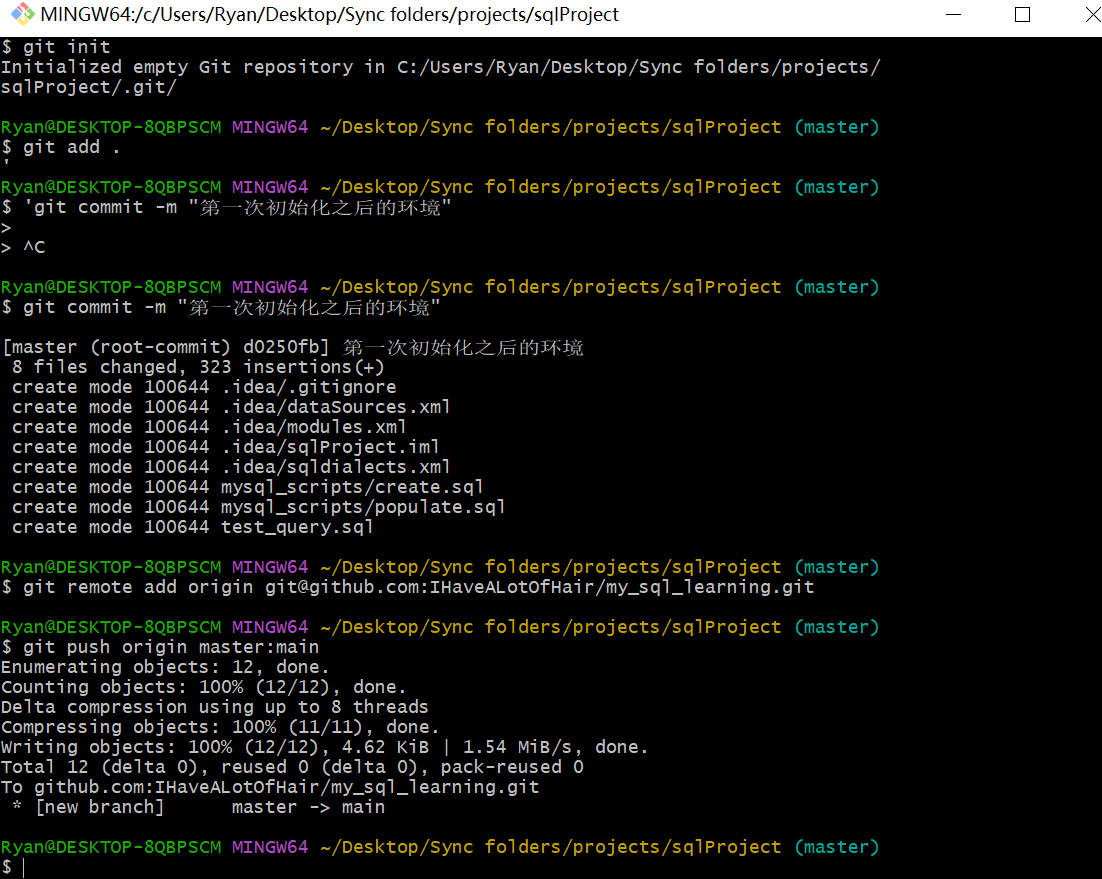

按ctrl+回车运行
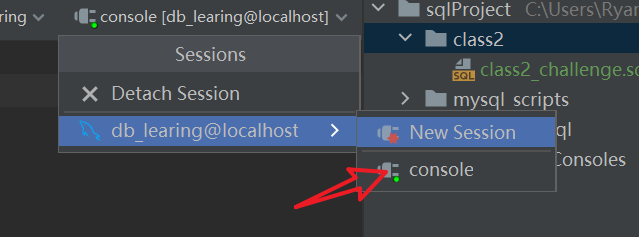
运行需要选择会话,选择这个
*5. 自动建立文件夹,建好了之后大概长这样
import os
#这里把路径改成自己文件夹的路径就好了
path = r'''C:\Users\Ryan\Desktop\Sync folders\projects\sqlProject'''
for i in range(9,22):
title = "class"+str(i)
new_path = os.path.join(path, title)
# #创建文件夹
if not os.path.isdir(new_path):
os.makedirs(new_path)
#创建文件
sql_file=f"challenge{i}.sql"
s_file=os.path.join(new_path,sql_file)
with open(s_file,'w',encoding='utf-8') as f:
f.write("#")
f.close()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PXbqxMcs-1663999999336)(assets/image-20220915105858928.png)]
Class2与Challenge2:
以下所有的练习的代码,我上传到了我的Github仓库:
https://github.com/IHaveALotOfHair/my_sql_learning
这一张绝大部分是增删改查,相比再各种地方都看到过类似的,这里就不在详细说了.
在选中的字段前加上DISTINCT关键字可以筛选出在这个字段不同步的数据
第一个练习在第22页,第二课
select cust_id from Customers; -- Challenge1
# select cust_id from Customers limit 3 offset 3;
# select DISTINCT vend_Id from products ;
# select vend_Id from products ;
select DISTINCT prod_id from orderitems; -- Challenge2
select * from customers; -- Challenge3
Class3与Challenge3
class3小结
这一节主要讲到两个关键字
-
order by
用来排序,可以是order by 某个列,
也可也是多个列,多个列会先按照第一个列排,然后是第二个列…
-
desc
Desc一般放在order by后,Mysql默认按照递增排列,加上这个可以换成递减排列 排序的列不是select选中也可以
拿Customers这张表来试一下:

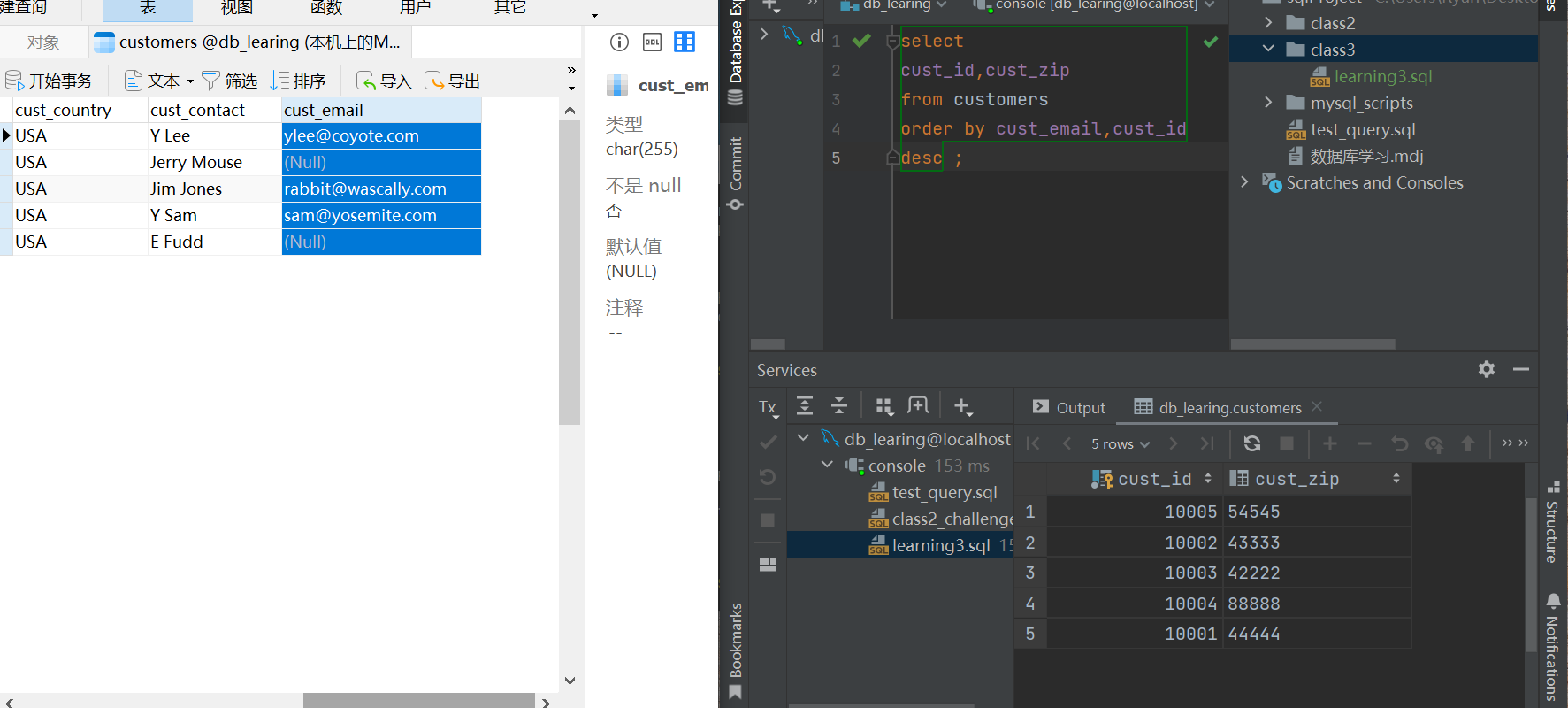
非int型的排序比如说char是按照长度来算的,有些字段长得像int,看一下发现是char
select
cust_id,cust_zip
from customers
order by cust_email,cust_id
desc ;
Challenge3
# Challenge3.1
select cust_name
from customers
order by cust_name
desc ;
#.2
select
cust_id,order_num-- ,orders.order_date
from orders
order by cust_id,orders.order_date
desc ;
#.3
select quantity,item_price
from orderitems
order by
quantity desc,
item_price desc;
#.4 多了,少了by
Class4与Challenge4
select
prod_id , prod_name ,prod_price
from products
where prod_price=9.99;
select prod_id,prod_name
from products
where prod_price>=9;
select distinct
order_num
from orderitems;
select prod_name,prod_price
from products
where prod_price
between 3 and 6
order by prod_price;
Class5与Challenge5
select vend_name
from vendors
where
vend_country in ('USA','CA')
and vend_state='CA';
select * from orderitems;-- 看看里边有哪些东西
# select * from orders;
# select * from products;
select
order_num,prod_id,quantity
from orderitems
where prod_id in ('BR01','BR02','BR03')
and quantity>=100
order by prod_id,quantity;
select prod_name,prod_price
from products
where prod_price between 3 and 6
order by prod_price;
select vend_name
from vendors
where vend_country='USA' and vend_state='CA'
order by vend_name;
C6
/*
章节小结:
%操作符: 匹配任意字符
可以是 %x --> 匹配x结尾的任意行
也可以是 x% --> 匹配x开头的任意行
也可以是 %x% --> 匹配x在中间的任意行
_操作符: 匹配单一字符
_x ---> 匹配以x结尾,长度为2的行
x_ ---> 匹配以x开头,长度为2的行
_x_ ---> 匹配x在中间,长度为3的行
[]操作符: 匹配[]里边的任意单一字符,有点像in
[xy]% ---> x% and y%
不出现[]内的用法:
[^xy]
使用概要:
1.能用别的功能实现尽量不要用通配符,耗时较长
2.组合起来更好用
3.尽量不要放到搜索模式的开始处
*/
select prod_name,prod_desc
from products
where prod_desc like '%ton%';
select prod_name,prod_desc
from products
where prod_desc not like '%ton%'
order by prod_name;
select prod_name,prod_desc
from products
where prod_desc like '%ton%'
and prod_desc like '%car%';
select prod_name,prod_desc
from products
where prod_desc like '%ton%car%';
C7
/*
本节包括:
1.创建计算字段.
2.从应用程序中引用别名使用他们
使用方法概要:
在Mysql与其分支版本中,使用: Concat
SQLite :||
算数计算:
*/
#因为完全没用过这个,这里把书上的例子试一遍:
select
concat(vend_name,'(',vend_country,')')
from vendors
order by vend_name;
#rtrim:去掉右边的空格
select rtrim(vend_name)
from vendors
order by vend_name;
#使用别名,数据不变,表头变成别名
select rtrim(vend_name)
as a
from vendors
order by vend_name;
/*
在应用层语言中把sql查出来的数据映射到对象的属性中,
这时候如果字段名字和对象的名字不一样,就可以用as去改成一样的来引用
如果列名字是多个词,用as变成一个词,就能愉快在python等语言中的使用了
*/
select 2*3;
#=============challenge7部分===================
select
vend_id as vid,
vend_name as vname,
vend_city as vcity,
vend_address as vaddress
from vendors
order by vaddress;
select prod_id,prod_price,
prod_price*0.9 as sale_price
from products
order by sale_price;
C8
/*
这一节主要讲函数,在challenge7中因为mysql拼接要使用函数,已经提前了解了一部分
这个模块的内容和实验一实验部分基本相似,打算后续整理一下放到那个博客里去
=====
TODO: 整理函数部分的用法,放到实验一的博客中去
=====
函数不是每个数据库都一样的,
一个数据库不同版本可能也不一样,比如mysql5和8时间函数就不一样
没有必要去背每个函数,用的时候去查就好了.
单纯调用函数很简单,没什么好说的,后续组合起来用
*/
select
cust_id,
cust_name,
upper(
concat(left(cust_name,2),left(cust_city,3))
) as user_login
from customers;
select
order_num,
order_date
from orders
order by order_date desc; -- Mysql里有时间类型,能根据时间排序
C9
/*
能在数据库里边处理的尽量在数据库内部处理,
数据返回去在应用程序里处理会传输不必要的数据,增加io负担,
而且应用程序里边的各种对象映射啥的,肯定没数据库这种直接跑在系统和c上边的快
这一节感觉可以并入上一节,
也是讲函数的,这里是数据汇总常见的函数,
之前用过类似的好像,这里的比较常用
常用聚集函数(aggregate function):
avg() 平均值
count() 返回某列的行数
max() 最大值
min() 最小值
sum() 求和
可搭配distinct 选定不同值使用,distinct不能用于count *
*/
#听说count(*)挺好用的,能通过这个判断是不是空行,某种程度上可以预防空指针的问题
select sum(quantity) as total_quantity
from orderitems;
#题目里的数据貌似没有,于是把br01换成anv系列产品
select sum(order_num)
from orderitems where prod_id like 'ANV%';
select max(prod_price) from products where prod_price<=10;
c10
#这一章好久没用过了,把书上的敲一遍:
select count(*) as num_products
from products
where prod_id like 'D%';
select *
from products
where prod_id like 'D%';
#conut(*)可以统计一共又多少行,是一个函数,和上一章的差不多
select vend_id,count(*)
from products
group by vend_id;
/*having是用来过滤分组的,和where的区别是where用于过滤行,having过滤分组*/
select cust_id,count(*) as orders
from orders
group by cust_id
having count(*)>=2;
# where 在分组前过滤,会影响分组的结果
# # 以下的例子运行不了,会报错
# select cust_id,count(*) as orders
# from orders
# group by cust_id
# where orders>=2;
select vend_id,count(*) as num_prods
from products
where prod_price>=4
group by vend_id
having count(*) >=2;
select order_num,count(*) as item
from orderitems
group by order_num
order by item,order_num;
#==============================分界线======================
#==============================分界线======================
#Challenge10
#1.
select order_num,count(*) as order_lines
from orderitems
group by order_num
order by order_lines;
#2. 为了方便看,这里多选几列
select min(prod_price) as cheapest_item,
prod_desc,vend_id
from products
group by vend_id
order by cheapest_item;
#3.
select orderitems.order_num,sum(quantity)
from orderitems
group by orderitems.order_num
having sum(quantity)>=3
;
select order_num, (quantity*item_price) as s
from orderitems
group by order_num
having sum(quantity*item_price)>=100
order by s ;
SELECT order_num,count(*)
as item
from orderitems
# group by item
group by order_num
having count(*)>=3
# order by item
order by item,order_num;
#这一章挺有用的,妙啊
C11
#challenge11
#1
select orders.cust_id
from orders
where orders.order_num
in (select orderitems.order_num
from orderitems
where orderitems.item_price > 10
);
#2
select
orders.order_date,cust_id
from orders
where order_num in
(
select orderitems.order_num
from orderitems
where orderitems.prod_id='FB'
)
order by cust_id,order_date;
#3
#这个挺有意思,通过外键作为索引,从各个表跳来跳去
select customers.cust_email
from customers
where cust_id in
(select orders.cust_id
from orders
where order_num in
(select orderitems.order_num
from orderitems
where orderitems.prod_id = 'FB'));
#4
select cust_id,
(
select sum(quantity)
from orderitems
where orderitems.order_num=orders.order_num
) as total_ordered
from orders;
#5.
# select prod_name
# ,(
# select sum(orderitems.quantity) as quant_sold
# from orderitems
# group by prod_id
# )
# from products
# where products.prod_id in
# (select distinct prod_id from orderitems)
# ;
#
# select sum(orderitems.quantity) as quant_sold
# from orderitems
# group by prod_id;
#上边那个是自己写的,搞混了选出来的是一行还是多行,看了参考答案之后悟了
select prod_name,(
select sum(quantity)#这样算出来的也是一行的,而不是多行,合理了
from orderitems
where products.prod_id=orderitems.prod_id
) as quant_sold
from products;
C12
#challenge12
/*
连结用起来很舒服,不需要嵌套查询,
代价是性能会变差
联结越多越差
*/
#1. 复杂的方法
select cust_name,order_num
from customers
#内联结
inner join orders on customers.cust_id = orders.cust_id
order by cust_name;
#1. 简单的方法 运行出来是一样的结果,
select cust_name,order_num
from customers,orders
where customers.cust_id=orders.cust_id
order by cust_name;
#2.
select customers.cust_name,orderitems.order_num,
(select sum(orderitems.item_price*orderitems.quantity)
from orderitems
# group by orderitems.order_num
where orderitems.order_num=orders.order_num
)as OrderTotal
from customers,orders,orderitems
where orders.order_num=orderitems.order_num
and customers.cust_id=orders.cust_id;
#3.
select order_date
from orders,orderitems
where orders.order_num=orderitems.order_num
and orderitems.prod_id='FB';
select order_date
from orders
join orderitems on orders.order_num = orderitems.order_num
where orderitems.prod_id='FB';
#4.
select distinct cust_email
from customers,orders,orderitems
where orderitems.prod_id='FB'
and orderitems.order_num=orders.order_num
and orders.cust_id=customers.cust_id;
#5.
select cust_name,sum(quantity) as buy_total
from customers,orderitems,orders
where customers.cust_id=orders.cust_id
and orders.order_num=orders.order_num
group by cust_name
having buy_total>10;
C13
#challenge13
#1.
select
customers.cust_name,
order_num
from customers
inner join orders as o on customers.cust_id = o.cust_id;
#2.
select
customers.cust_name
# order_num
from customers;
# inner join orders as o on customers.cust_id = o.cust_id;
#3.
#右联结
select prod_name,order_num
from products
right outer join orderitems as o on o.prod_id=products.prod_id
order by prod_name;
#这两个运行出来结果不同
#左联结
#4.
select prod_name,order_num,sum(quantity)
from products
right outer join orderitems as o on o.prod_id=products.prod_id
group by order_num;
#这两个运行出来结果不同
#左联结
#5.
# 有这么几种写法,都能跑出来,
select v.vend_id,count(prod_id)
from vendors as v
left outer join products p on v.vend_id = p.vend_id
group by v.vend_id;
select v.vend_id,count(prod_id)
from vendors as v
right outer join products p on v.vend_id = p.vend_id
group by v.vend_id;
select v.vend_id,count(*)
from vendors as v
right outer join products p on v.vend_id = p.vend_id
group by v.vend_id;
select v.vend_id,count(prod_id)
from vendors as v
inner join products p on v.vend_id = p.vend_id
group by v.vend_id;
#官方的答案
SELECT Vendors.vend_id, COUNT(prod_id)
FROM Vendors
LEFT OUTER JOIN Products ON Vendors.vend_id = Products.vend_id
GROUP BY Vendors.vend_id;
C14
#challenge14
#1.
select prod_id,quantity
from orderitems
where quantity>1
# limit 100
union
select prod_id,quantity
from orderitems
where prod_id like 'O%'
order by prod_id
limit 10
;
#2.
select prod_id,quantity
from orderitems
where quantity>1 or prod_id like 'O%'
order by prod_id ;
#3.
select prod_name
from products
union
select cust_name
from customers
order by prod_name;
#4.
select cust_name,cust_email
from customers
where cust_state='MI'
# order by cust_state orderby要放到后边
union
select cust_name,
# cust_contact, 这多了一行,上下两列连不起来了
cust_email
from customers
where cust_state='IL'
order by cust_name;
C15
#challenge15
#1.
insert into customers
(
cust_name,
cust_address,
cust_city,
cust_state,
cust_zip,
cust_country,
cust_contact,
cust_email)
values (
'Ryan Lee',
'ccsu',
'ChangSha',
'HuNan',
'111111',
'CN',
'L',
'2922437656@qq.com'
);
#2.1
Create table Orders_backup
select * from orders;
#2.2
create table OrderItems_backup
select *from orderitems;
#看一下是不是备份成功了
select * from orderitems_backup;
C16
#challenge16
#1.
update vendors
set vend_state=upper(vend_state)
where vend_country='USA' ;
update customers
set cust_state=upper(cust_state)
where cust_country='USA';
#2.
delete from customers
where cust_id=10006;
C17
#challenge17
#1.
alter table vendors add vend_web text;
#2.
update vendors
set vend_web='www.lrj666.com'
where vend_id=1006;
C18
#challenge18
#这一章是视图之前貌似没听过,先把书上的敲一遍
select cust_name,cust_contact
from customers,orders,orderitems
where customers.cust_id=orders.cust_id
and orderitems.order_num =orders.order_num
and prod_id like '%%';
select cust_name,cust_contact
from Products,Customers
where prod_id>1;
# wher
create view ProductCustomers
as select cust_name,cust_contact,prod_id
from customers,orders,orderitems
where customers.cust_id=orders.cust_id
and orders.order_num=orderitems.order_num;
select * from ProductCustomers;
drop view VendorLocation;
create view VendorLocation as
select concat(RTRIM(vend_name),'(',RTRIM(vend_country),')') as title
from vendors;
select * from VendorLocation;
#好家伙,这么快就到最后一个challenge了,
#1.
create view CustomersWithOrders as
select customers.cust_id,cust_name,cust_address,
cust_city,cust_state,cust_zip,
cust_country,cust_contact,
cust_email
from customers,orders
where orders.cust_id=customers.cust_id;
select * from CustomersWithOrders;
#2.
create view OrderItemsExpanded as
select order_num,
prod_id,
quantity,
item_price,
quantity*orderitems.item_price as expanded_price
from orderitems
order by order_num;
#按照书上说,试图不支持 orderby,但是这里运行出来没问题,估计是更新了就允许ordeby了
select * from OrderItemsExpanded;















 1361
1361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









