






模块
import:
1、执行对应文件
2、引入变量名
首先添加一个 Python Package,在这个文件下多了一个init文件就是package文件,没有就是普通文件,然后添加对应的.py文件
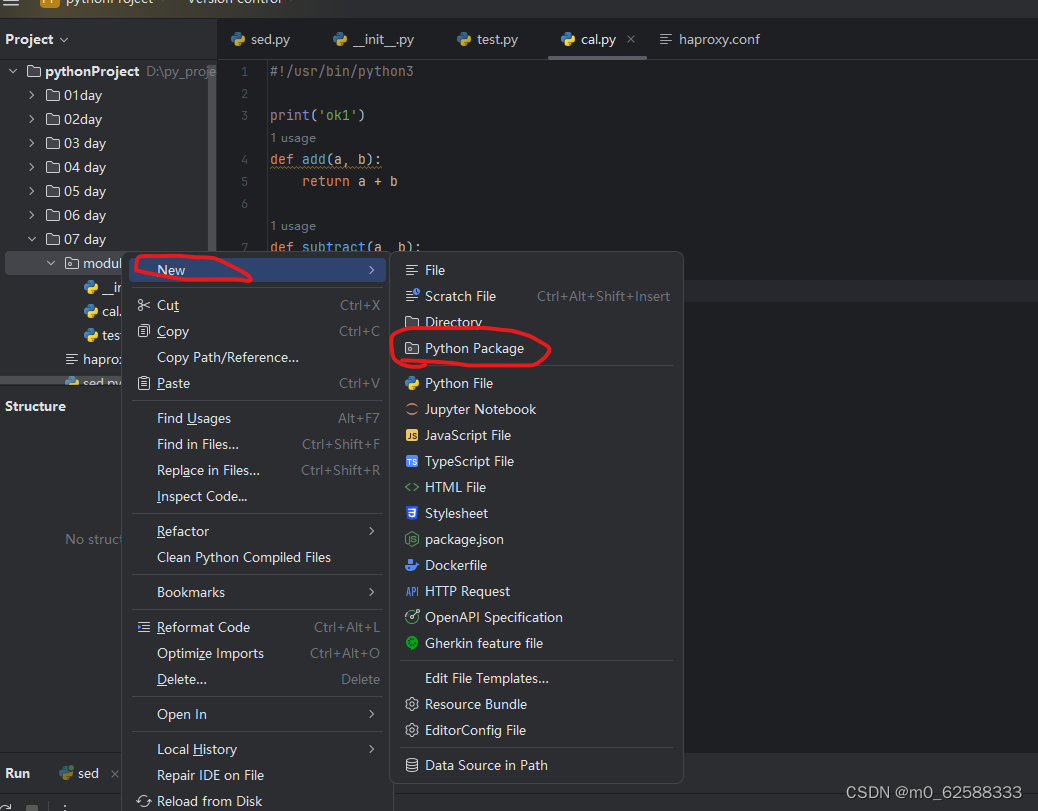
我这里定义一个test.py 和 cal.py文件,然后通过在cal.py文件里面实现功能函数,在test.py里面通过import cal加载模块,然后调用cal.py文件里面的函数
简单的模块加载
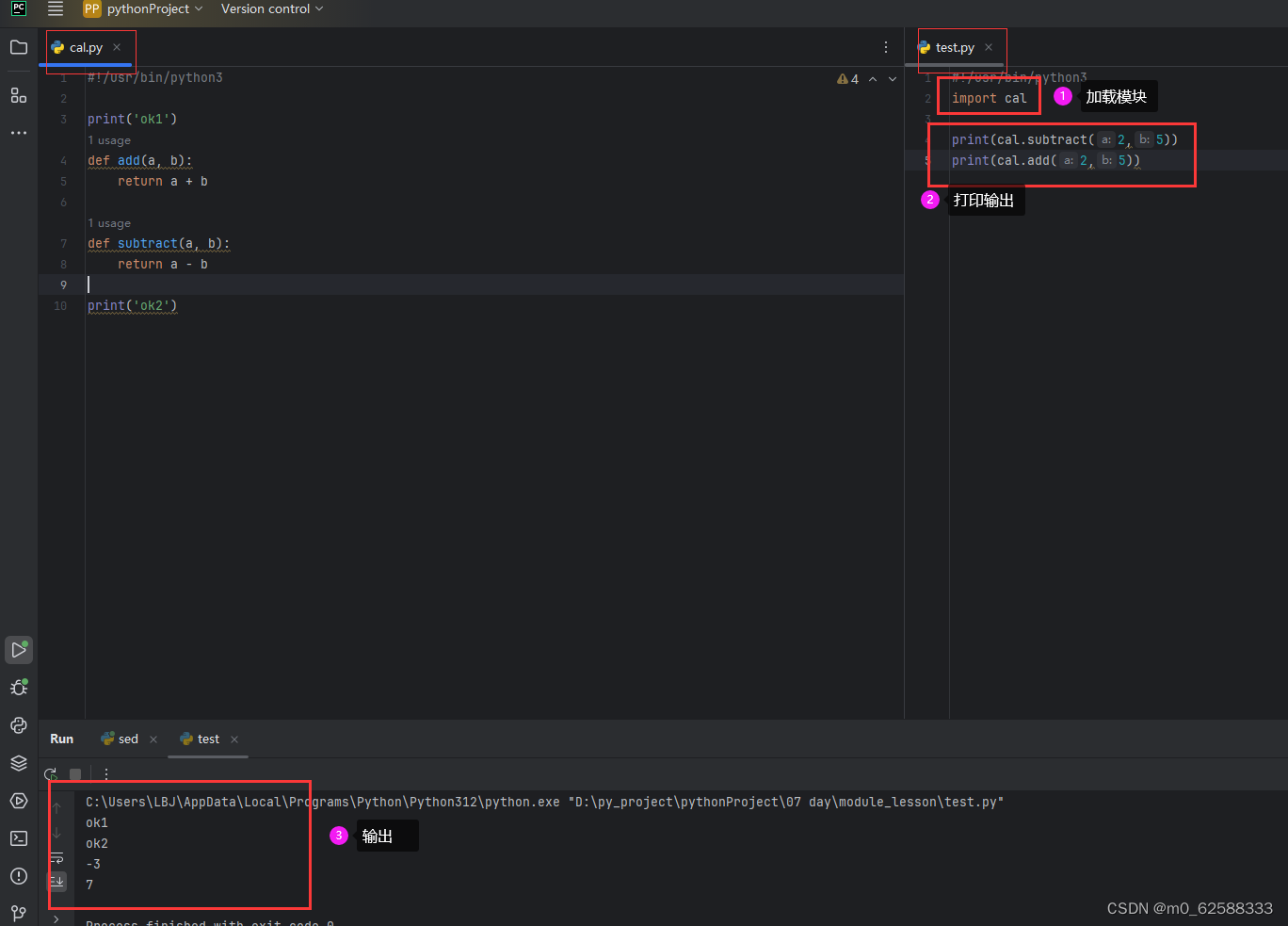
注意:注意调用模块的时候要加上模块的名字来调用
直接加载模块里的功能函数
注意:不管怎么加载模块,都会先执行一遍对应加载模块的文件,所以通常不在加载的模块里面写逻辑功能
包的调用多层的用点来寻找
包的本质就是一个文件夹,那么文件夹唯一的功能就是将文件组织起来 随着功能越写越多,我们无法将所以功能都放到一个文件中,于是我们使用模块去组织功能,而随着模块越来越多,我们就需要用文件夹将模块文件组织起来,以此来提高程序的结构性和可维护性总结包的使用需要牢记三点 1、导包就是在导包下__init__.py文件 2、包内部的导入应该使用相对导入,相对导入也只能在包内部使用,而且...取上一级不能出包 3、 使用语句中的点代表的是访问属性 m.n.x ----> 向m要n,向n要x 而导入语句中的点代表的是路径分隔符 import a.b.c --> a/b/c,文件夹下a下有子文件夹b,文件夹b下有子文件或文件夹c 所以导入语句中点的左边必须是一个包
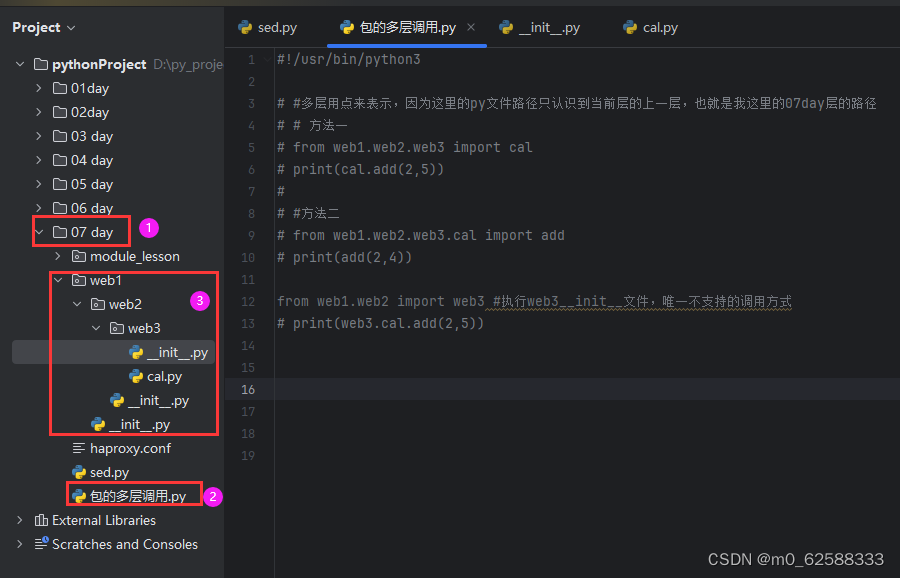
建议用前两种方法来实现
# #多层用点来表示,因为这里的py文件路径只认识到当前层的上一层,也就是我这里的07day层的路径
# # 方法一
# from web1.web2.web3 import cal
# print(cal.add(2,5))
#
# #方法二
# from web1.web2.web3.cal import add
# print(add(2,4))
from web1.web2 import web3 #执行web3__init__文件,唯一不支持的调用方式
# print(web3.cal.add(2,5))执行的是‘包的多层调用.py文件’那么cal.py文件就相当于模块的加载,所以print(__name__)就是web1.web2.web3.cal,而‘包的多层调用.py文件’是执行文件,所以print(__name__)他是__main__
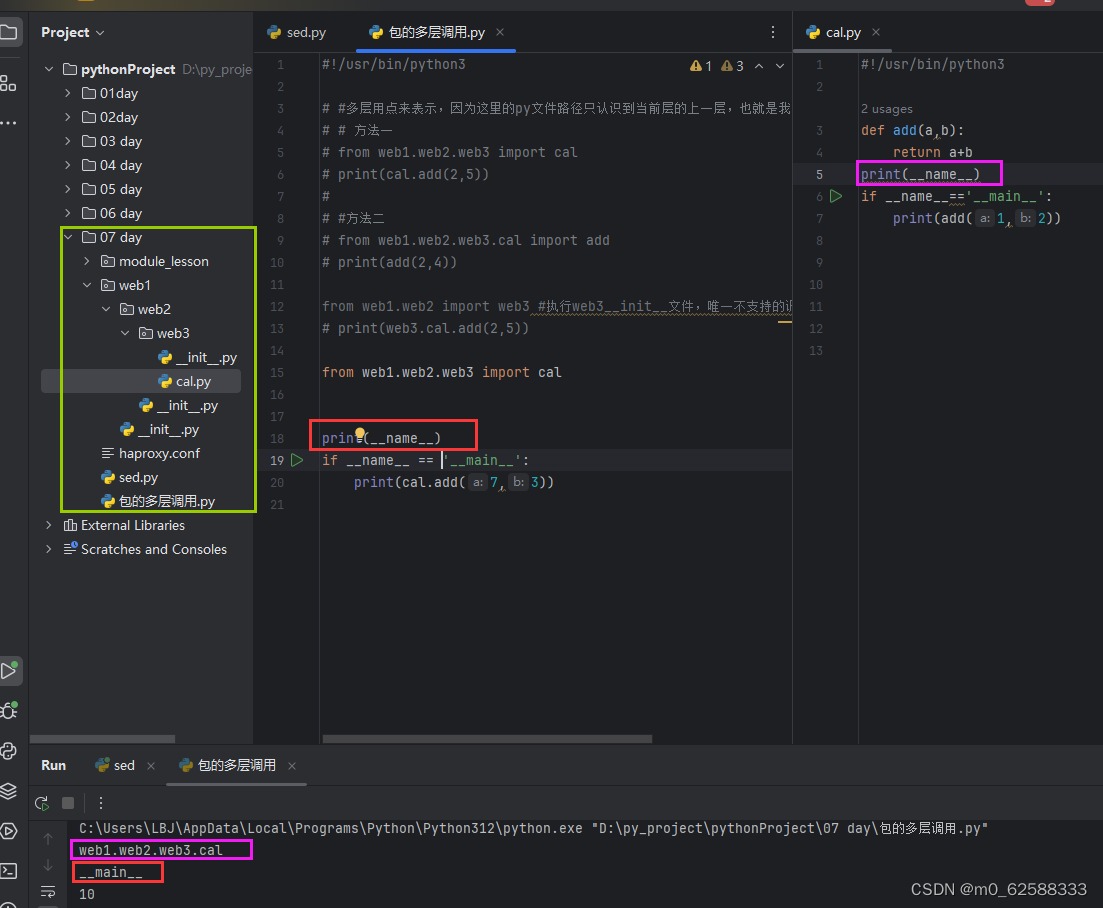 模块的查找顺序是:内存中已经加载的模块->内置模块->sys.path路径中包含的模块
模块的查找顺序是:内存中已经加载的模块->内置模块->sys.path路径中包含的模块
内置模块是Python自带的功能,在使用内置模块相应的功能时,需要【先导入】再【使用】
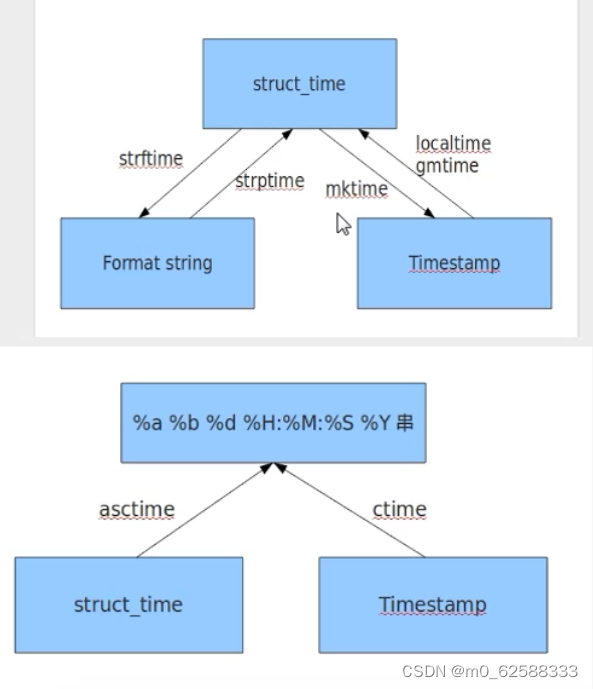
时间模块 time:
#!/usr/bin/python3
import time
#时间戳 #计算
print(time.time())
#当地时间
print(time.localtime())
print(time.gmtime())
#结构化时间 --- UTC
t = time.localtime()
print(t.tm_year)
# -- 将结构化时间转换成时间戳
print(time.mktime(time.localtime()))
print(time.time())
#---将结构化时间转换成字符串时间 strftime
#%H:%M:%S === %X
print(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()))
#将字符串时间转成结构化时间 strptime
#1、
print(time.strptime('2018-08-01 00:00:00', '%Y-%m-%d %X'))
#2、
t = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
print(time.strptime(t, '%Y-%m-%d %X'))
#转换成固定格式的时间 Tue May 14 15:44:48 2024
print(time.asctime(time.localtime()))
print(time.ctime())
import datetime
print(datetime.datetime.now())random模块
#!/usr/bin/python3
import random
ret = random.random() #(0,1) --- float
ret = random.randint(1,6) #[1,6]
ret = random.randrange(1,6) # [1,6) 不回取到6
ret = random.choice([11,22,33,44,55,66,77,88])
ret = random.sample([11, 22, 33], 3) # 选择所有元素
# 或者
ret = random.sample([11, 22, 33], 2) # 选择2个元素
ret = random.uniform(1,4)
print(ret)
# ******************************生成随机数************************************
def v_code():
ret = ""
for i in range(5):
num = random.randint(0,9)
alf = chr(random.randint(65,122))
s = str(random.choice([num,alf]))
ret += s
return ret
print(v_code())sys模块
用于提供对Python解释器相关的操作
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.stdin 输入相关
sys.stdout 输出相关
sys.stderror 错误相关例子:进度条显示
import sys,time
for i in range(100):
sys.stdout.write('#')
time.sleep(0.1)
sys.stdout.flush()os模块:用于系统级别的操作
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dir1/dir2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","new") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 用于分割文件路径的字符串
os.name 字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间具体实现的一些操作
#!/usr/bin/python3
import os
print(__file__) #获取当前文件路径的文件名,只有文件名,没有路径
print(os.getcwd())
os.chdir('test1')#进入test1的目录
print(os.getcwd())
os.chdir('..') # 退回上一层目录
print(os.getcwd())
os.makedirs('dir1/dir2') #建立多层文件夹
os.removedirs('dir1/dir2') # 删除多层文件夹 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依次类推
os.mkdir('dir1') # 建立一层文件夹
os.removedirs('dir1') #删除一层文件夹
print(os.listdir()) #列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
print(os.path.split(__file__)) #文件和目录分割
print(os.path.dirname(__file__)) #获取文件的目录
os.path.split(os.path.abspath(__file__)) #返回上一层路径
print(os.path.basename(__file__)) #获取文件的名字
"""
输出内容:
('D:\\py_project\\pythonProject\\07 day', 'os模块.py')
D:\py_project\pythonProject\07 day
os模块.py
"""
print(os.path.join(os.path.dirname(os.path.abspath(__file__)), 'aa','123.txt')) #字符串拼接
re = os.stat('练习.py')
print(type(re), re.st_size)
json&pickle:
json:
json.dump()和json.dumps()的区别在于:
json.dump(obj, fp, *args, **kwds):将对象obj序列化为一个 JSON 格式的字符串,并写入到fp指定的文件中。json.dumps(obj, *args, **kwds):将对象obj序列化为一个 JSON 格式的字符串,但不写入文件,而是返回这个字符串。
注意:json.dump会将全部单引号变为双引号,json不管什么类型全部变为字符串类型的,json.loads里面的内容一定要符合字符串类型,也就是都是双引号的,但凡有一个单引号都不行
dict1 = {'a':1,'b':2,'c':3}
#1、使用dumps
dic_str = json.dumps(dict1)
with open('json_file', 'w') as f_write:
f_write.write(dic_str)
#2、使用dump
with open('json_file', 'w') as f_write:
json.dump(dict1, f_write)
#*****************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************
# 创建一个字典
dict1 = {'a': 1, 'b': 2, 'c': 3}
# 使用json.dumps()将字典转换为JSON格式的字符串
dic_str = json.dumps(dict1)
# 使用with语句以写入模式('w')打开文件,文件名为'json_file'
# with语句会在代码块结束时自动关闭文件,即使发生异常也是如此
with open('json_file', 'w') as f_write: # 'w'模式会截断文件,即删除文件中原有的所有内容
# 将JSON字符串写入文件
f_write.write(dic_str)
# 使用with语句以只读模式('r')再次打开同一个文件
with open('json_file', 'r') as f_read: # 'r'模式用于读取文件
# 读取文件的全部内容到变量data
data = json.loads(f_read.read()) # 使用json.loads()将JSON字符串反序列化为Python字典
# 打印反序列化得到的字典及其类型
print(data, type(data)) # 预期输出: {'a': 1, 'b': 2, 'c': 3} <class 'dict'>pickle:
import pickle # 导入pickle模块,用于序列化和反序列化Python对象
# 创建一个字典
dict1 = {'a':1, 'b':2, 'c':3}
# 使用pickle.dumps()将字典序列化为字节流
dic_str = pickle.dumps(dict1)
# 使用with语句以二进制写入模式('wb')打开文件,文件名为'json_file'
# 'wb'模式允许我们将字节流写入文件
with open('json_file', 'wb') as f_write:
# 将序列化后的字节流写入文件
f_write.write(dic_str)
# 可选的pickle.dump()用法,直接将对象写入文件
# with open('json_file', 'w') as f_write:
# pickle.dump(dict1, f_write) # pickle.dump()同时处理序列化和写入操作
# 使用with语句以二进制读取模式('rb')再次打开同一个文件
# 'rb'模式用于读取二进制文件,即之前写入的字节流
with open('json_file', 'rb') as f_read:
# 读取文件的全部内容
data = f_read.read()
# 使用pickle.loads()将字节流反序列化为Python字典
data = pickle.loads(data)
# 打印反序列化得到的字典及其类型
print(data, type(data)) # 预期输出: {'a': 1, 'b': 2, 'c': 3} <class 'dict'>pickle与 json区别
pickle 模块与 json 模块不同,pickle 模块处理的是 Python 的字节流,因此需要使用 'wb' 和 'rb' 模式打开文件,分别对应二进制写入和二进制读取
xml模块
xml一行文件内容 <rank updated="yes">5</rank>属性:updated="yes"
文本:5
xml 查找
# 导入xml.etree.ElementTree模块,并给它取一个简短的别名ET
import xml.etree.ElementTree as ET
# 解析名为'xml_lesson'的XML文件,并将解析得到的树对象赋值给tree变量
tree = ET.parse('xml_lesson')
# 通过树对象获取XML文档的根元素,并将其赋值给root变量
root = tree.getroot()
# 打印根元素的标签名
print(root.tag)
# 遍历根元素的所有直接子元素
for i in root:
# 打印当前遍历到的子元素
print(i)
# 打印当前子元素的标签名
print(i.tag)
# 打印当前子元素的所有属性
print(i.items())
# 打印当前子元素的属性字典(如果元素没有属性,返回空字典)
print(i.attrib)
# 打印当前子元素的文本内容(如果元素有文本内容,返回文本;否则返回None)
print(i.text)
# 遍历当前子元素的所有直接子元素
for j in i:
print(j)
print(j.tag)
print(j.items())
print(j.attrib)
print(j.text)
# 更简洁地遍历根元素的直接子元素,并打印它们的标签和属性
for child in root:
print(child.tag, child.attrib)
# 遍历当前子元素的所有直接子元素,并打印它们的标签和文本内容
for i in child:
print(i.tag, i.text)
# 使用iter()方法遍历所有'year'标签的元素,并打印它们的标签和文本内容
for child in root.iter('year'):
print(child.tag, child.text)xml修改
import xml.etree.ElementTree as ET # 导入ElementTree模块,通常缩写为ET
# 解析名为'xml_lesson'的XML文件,tree是整个XML文档的树结构
tree = ET.parse('xml_lesson')
# 获取XML文档的根元素
root = tree.getroot()
# 遍历所有标签为'year'的元素
for node in root.iter('year'):
# 打印当前'year'元素的文本内容以及其类型
print(node.text, type(node.text))
# 将当前'year'元素的文本内容转换为整数,并加1
new_year = int(node.text) + 1
# 将计算出的新的年份赋值给当前'year'元素的文本内容,转换为字符串形式
node.text = str(new_year)
# 为当前'year'元素增加一个新的属性'updated',值为'yes'
node.set('updated', 'yes')
#写入文件
tree.write('xml_lesson')xml删除内容
import xml.etree.ElementTree as ET # 导入ElementTree模块,通常缩写为ET
# 解析XML文件,tree是整个XML文档的树结构
tree = ET.parse('xml_lesson')
# 获取XML文档的根元素
root = tree.getroot()
# 删除rank大于4的country元素
for child in root.findall('country'):
# 查找country元素下的rank元素,并获取其文本内容,然后转换为整数
rank = int(child.find('rank').text)
if rank > 4:
# 从root中移除该country元素
root.remove(child)
# 将修改后的XML树写入到output1.xml文件
tree.write('output1.xml') # 将修改后的XML文档写入文件
xml文件中新增内容
import xml.etree.ElementTree as ET
# 假设这是已有的 XML 文档的根元素
root = ET.parse('xml_lesson').getroot()
# 创建一个新的子元素并添加到根元素中
new_child = ET.SubElement(root, 'newElement', attrib={'key': 'value'})
new_child.text = 'This is the text of the new element'
# 也可以直接使用 ET.SubElement 创建并设置属性和文本
another_child = ET.SubElement(root, 'anotherElement', attrib={'feature': 'yes'})
another_child.text = 'This is another new element'
# 写入新的 XML 内容到文件
ET.ElementTree(root).write('updated.xml', encoding='utf-8', xml_declaration=True)xml生成一个xml文件
import xml.etree.ElementTree as ET # 导入ElementTree模块,通常缩写为ET
# 创建一个名为'namelist'的根元素
new_xml = ET.Element('namelist')
# 创建一个名为'name'的子元素,并为其添加一个属性'enrolled',值为'yes'
name = ET.SubElement(new_xml, 'name', attrib={'enrolled': 'yes'})
# 创建一个名为'age'的子元素,并为其添加一个属性'checked',值为'no'
age = ET.SubElement(new_xml, 'age', attrib={'checked': 'no'})
# 创建一个名为'sex'的子元素
sex = ET.SubElement(new_xml, 'sex')
# 为'sex'元素设置文本内容
sex.text = '33'
# 生成包含new_xml元素的文档树
et = ET.ElementTree(new_xml)
# 将文档树写入到名为'test.xml'的文件中,指定使用utf-8编码,并包含XML声明
et.write('test.xml', encoding='utf-8', xml_declaration=True)输出结果:
"""
输出:
<?xml version='1.0' encoding='utf-8'?>
<namelist>
<name enrolled="yes" />
<age checked="no" />
<sex>33</sex>
</namelist>
"""re模块
正则表达式(或re)是一种小型的、高度专业化的编程语言,(在python中)它内嵌在Python中,并通过re模块实现,正则表达式模式被编译成一系列的字节码,然后由c编写的匹配引擎执行。
字符匹配(普通字符,元字符):
1、普通字符:大多数字符和字母都会和自身匹配
re.findall('aa','hgihgiaafg')
['aa']
2、元字符:^ $ + ? {} [] | () \
python中re模块提供了正则表达式相关操作
# search,浏览整个字符串去匹配第一个,未匹配成功返回None
# search(pattern, string, flags=0)
例子:ret = re.search('(?P<id>\d{2})/(?P<name>\w{3})','23/com') print(ret.group()) # 23/com print(ret.group('id')) # 23 print(ret.group('name')) # com
字符:
. 匹配除换行符以外的任意字符(一个点只匹配一个字符)
\w 匹配字母或数字或下划线或汉字
\s 匹配任意的空白符
\d 匹配数字
\b 匹配单词的开始或结束
^ 匹配字符串的开始(只能从字符串开始匹配)
$ 匹配字符串的结束
例子:
^: re.findall("^a..x","adsxaggihg")
$: re.findall("g..g$","adsxaggihg")
次数:
* 重复零次或更多次(靠着紧挨的字符重复0到无穷次)
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次 (表示单个字符的多次)
{n,} 重复n次或更多次
{n,m} 重复n到m次
例子:
*: re.findall("a..x*","afgaggihgalexxx")
+: re.findall("a..x+","afgaggihgale")
?: re.findall("a..x?","afgaggihgalexxx")
{}: re.findall("a..x{6}","afgaggihgalexxx")
#{n,m} print(re.findall('ab{2}','abbb')) #['abb'] print(re.findall('ab{2,4}','abbb')) #['abb'] print(re.findall('ab{1,}','abbb')) #'ab{1,}' ===> 'ab+' print(re.findall('ab{0,}','abbb')) #'ab{0,}' ===> 'ab*'
[]:特殊 - ^ \
#[]
print(re.findall('a[1*-]b','a1b a*b a-b')) #[]内的都为普通字符了,且如果-没有被转意的话,应该放到[]的开头或结尾
print(re.findall('a[^1*-]b','a1b a*b a-b a=b')) #[]内的^代表的意思是取反,所以结果为['a=b']
print(re.findall('a[0-9]b','a1b a*b a-b a=b')) #[]内的^代表的意思是取反,所以结果为['a=b']
print(re.findall('a[a-z]b','a1b a*b a-b a=b aeb')) #[]内的^代表的意思是取反,所以结果为['a=b']
print(re.findall('a[a-zA-Z]b','a1b a*b a-b a=b aeb aEb')) #[]内的^代表的意思是取反,所以结果为['a=b']
logging模块
输出日志文件,一般用logging的方法
#!/usr/bin/python3
# ----------------------------logging方法——————————————————
import logging
logging.basicConfig(
level=logging.DEBUG, #设置等级为DEBUG,不写默认是WARNING模式
filename='test.log', #生成一个日志文件,并将内容添加到日志文件中,
filemode='w', #默认是追加模式,加上这个参数就可以只是写,会先清空日志文件
format='%(asctime)s [%(lineno)d] - %(message)s'
)
logging.debug('debug')
logging.info('info')
logging.warning('warning')
logging.error('error')
logging.critical('critical')
#-----------------------logger
def logger():
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
fh = logging.FileHandler('test.log') #设置输出的文件
ch = logging.StreamHandler() #设置输出在屏幕的位置
fm = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setFormatter(fm)
ch.setFormatter(fm) #输出按自定义的格式输出
logger.addHandler(fh)
logger.addHandler(ch) #在屏幕显示出来,没有这一行屏幕不会输出出来
return logger
logger = logger()
logger.debug('debug message')
logger.info('info message')
logger.warning('warning message')
logger.error('error message')
logger.critical('critical message')
configparse模块
操作配置文件,相当于操作字典,操作类似
#!/usr/bin/python3
#写一个配置文件
import configparser
config = configparser.ConfigParser() # config ={} 类似于创建字典
config['DEFAULT'] = {
'ServerAlineInterval':'45',
'Compression':'yes',
'CompressionLevel':'9'
}
config['bitbucket.org'] = {}
config['bitbucket.org']['User'] = 'hg'
config['topsecret.server.com'] = {}
topsecret = config['topsecret.server.com'] #返回一个topsecret
topsecret['Host Port'] = '50022'
topsecret['fORWARDx11'] = 'no'
with open('config.ini', 'w') as f:
config.write(f)
import configparser
config = configparser.ConfigParser()
config.read('config.ini')
print(config.sections()) #输出['bitbucket.org', 'topsecret.server.com']
print('bytebong.com' in config) # False
print(config['bitbucket.org']['user']) # hg 取出键对应的值
print(config['DEFAULT']['compression'])# yes
#default 不管怎么样都会输出出来的
for key in config['bitbucket.org']:
print(key, config['bitbucket.org'][key])
print(config.options('bitbucket.org')) #['user', 'serveralineinterval', 'compression', 'compressionlevel']
print(config.items('bitbucket.org')) #[('serveralineinterval', '45'), ('compression', 'yes'), ('compressionlevel', '9'), ('user', 'hg')]
print(config.get('bitbucket.org', 'compression')) #yes
#新增一个块
config.add_section('yuan') # section 是 块
config.set('yuan', 'compression', 'zip')#在yuan这个块中新增一个键值
# 删除一个块
config.remove_section('topsecret.server.com') #块
config.remove_option('bitbucket.org', 'user')
#记得最后写入回文件中
config.write(open('i.cfb','w'))
hashlib模块
md5加密,只能加密不能解密
#!/usr/bin/python3
import hashlib
#加密md5
obj = hashlib.md5('sb'.encode('utf-8')) #自己加盐,这样就不会被反解出来了
obj.update('hello'.encode('utf-8'))
print(obj.hexdigest()) #没加盐之前5d41402abc4b2a76b9719d911017c592,加盐之后9a4f710207fb80475eae6bf9d61751e2
obj = hashlib.md5() #不加盐
obj.update('hello'.encode('utf-8'))
print(obj.hexdigest()) # 5d41402abc4b2a76b9719d911017c592
obj.update('admin'.encode('utf-8'))#在hello的加密基础上继续添加admin加密
print(obj.hexdigest()) # dbba06b11d94596b7169d83fed72e61b
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









