






组合:
通过直接传对象进行组合
class School:
def __init__(self,name,addr):
self.name=name
self.addr=addr
class Course:
def __init__(self,name,price,period,school):
self.name=name
self.price=price
self.period=period
self.school=school
s1 = School('新东方', '北京')
c1 = Course('数学',100,'1h',s1)
print(c1.school.name) #新东方
print(s1.name) #新东方通过输入传入对象
class School:
def __init__(self,name,addr):
self.name=name
self.addr=addr
class Course:
def __init__(self,name,price,period,school):
self.name=name
self.price=price
self.period=period
self.school=school
s1 = School('新东方', '北京')
s2 = School('新东方', '南京')
s3 = School('新东方', '东京')
meg = '''
1 新东方 北京
2 新东方 南京
3 新东方 东京
'''
while True:
print(meg)
enum = {
'1': s1,
'2': s2,
'3': s3,
}
school_obj = input("选择学校>>")
school_obj = enum[school_obj]
new_course = input('课程>>')
new_price = input('价格>>')
new_period = input('周期>>')
new_school = Course(new_course,new_price,new_period,school_obj)
print('课程【%s】 属于 【%s】学校' %(new_school.name,new_school.school.name))继承:
类的继承跟现实生活中父、子、孙子、重孙子继承关系一样,父类又称为基类。python中类的继承分为:单继承和多继承
#!/usr/bin/python3
class ParentClass1:
pass
class ParentClass2:
pass
class SubClass(ParentClass1): #单继承
pass
class SubClass(ParentClass1, ParentClass2): # 多继承
pass
子类继承了父类的所有属性,子类自定义的属性如果跟父类的重名,子类调用的时候会优先选择子类的去使用
class Dad:
money = 10
def __init__(self,name):
self.name = name
def show(self):
print('来自父类')
class Son(Dad):
def show(self):
print('来自子类')
s1 = Son('james')
s1.show() #来自子类
print(Son.money) #10
print(s1.__dict__) #{'name': 'james'}
print(s1.__dict__)什么时候用继承
1、当类之间有显著不同,并且较小的类十较大的类所需要的组件时,用组合比较好
例如:描述一个机器人类,机器人这个大类是由很多互不相关的小类组成,如机械胳膊类、腿类、身体类、电池类
2、当类之间有很多相同的功能,提取这些共同的功能做成基类,用继承比较好
例如:猫可以:喵喵叫、吃、喝、拉、撒
狗可以:汪汪叫、吃、喝、拉、撒
如果我们要分别问猫和狗创建一个类,那么就需要为猫和狗实现他们所有的功能
接口继承
1、实践中,继承的第一种含义意义并不很大,甚至常常是有害的。因为它使得子类与基类出现强耦合。继承的第二种含义非常重要。它又叫"接口继承"。
2、接继承实质上是要求"做出一个良好的抽象,这个抽象规定了一个兼容接口,使得外部调用者无需关心具体细节,可一视同仁的处理实现了特定接口的所有对象"——这在程序设计上,叫做归一化。
3、归一化使得高层的外部使用者可以不加区分的处理所有接口兼容的对象集合——就好象linux的泛文件概念一样,所有东西都可以当文件处理,不必关心它是内存、磁盘、网络还是屏幕(当然,对底层设计者,当然也可以区分出“字符设备"和“块设备",然后做出针对性的设计:细致到什么程度,视需求而定)。
import abc
class ALL_file(metaclass=abc.ABCMeta):
@abc.abstractmethod
def read(self):
pass
@abc.abstractmethod
def write(self):
pass
class Disk(ALL_file):
def read(self):
pass
def write(self):
pass
class Mem(ALL_file):
def read(self):
print('mem read')
def write(self):
print('mem write')
m1 = Mem()
m1.read()
m1.write()
在子类中调用父类的方法
class Vehicle:
Country = 'China'
def __init__(self,name,speed,load,power):
self.name = name
self.speed = speed
self.load = load
self.power = power
def run(self):
print('开动了')
class Subway(Vehicle):
def __init__(self,name,speed,load,power,line):
Vehicle.__init__(self,name,speed,load,power)
self.line = line
pass
def show_info(self):
print(self.name, self.speed, self.load, self.power)
def run(self):
Vehicle.run(self)
print('Subway 开动了')
line13 = Subway('广州地铁', '10km/s',100000,'电',13)
line13.show_info()
line13.run()注意:调用父类的时候记得加上self在参数那里,但一般不这么用,一般用下面的方法,用supper调用
supper调用父类的方法
这样的好处可以在修改基类名字的时候可以不用修改下面逻辑的代码,因为不用传父类名,也不用传self参数
class Vehicle:
Country = 'China'
def __init__(self,name,speed,load,power):
self.name = name
self.speed = speed
self.load = load
self.power = power
def run(self):
print('开动了')
class Subway(Vehicle):
def __init__(self,name,speed,load,power,line):
# Vehicle.__init__(self,name,speed,load,power)
super().__init__(name,speed,load,power) #调用父类的构造方法
self.line = line
pass
def show_info(self):
print(self.name, self.speed, self.load, self.power)
def run(self):
# Vehicle.run(self)
super().run()
print('Subway 开动了')
line13 = Subway('广州地铁', '10km/s',100000,'电',13)
line13.show_info()
line13.run()利用Pickle将对象存入文件中去
#!/usr/bin/python3
import pickle
import hashlib
import time
def creat_md5():
md5 = hashlib.md5()
md5.update(str(time.time()).encode('utf-8'))
print(md5.hexdigest())
return md5.hexdigest()
class Base:
def save(self,file_name):
with open(file_name,'wb') as f:
pickle.dump(self,f) #将对象保存到路径中,注意pickle 是用wb方式写入,其他方式是错误的
class School(Base):
def __init__(self,school_name,addr):
self.id = creat_md5()
self.school_name = school_name
self.addr = addr
class Course(Base):
def __init__(self,course_name,period,price,shcool):
self.id = creat_md5()
self.course_name = course_name
self.period = period
self.price = price
self.shcool = shcool
class Teacher:
pass
s1 = School('新东方','北京')
s1.save(s1.id)
school_obj = pickle.load(open(s1.id,'rb'))
print(school_obj.school_name,school_obj.addr)
多态
什么是多态
由不同的类实例化得到的对象,调用同一个方法,执行的逻辑不同
#!/usr/bin/python3
class H2O:
def __init__(self,name, temperature):
self.name = name
self.temperature = temperature
def turn_ice(self):
if self.temperature < 0:
print('[%s]温度太低结冰了' %self.name)
elif self.temperature > 0 and self.temperature < 100:
print('[%s]液化成冰' %self.name)
elif self.temperature > 100 :
print('[%s] 温度太高变成了水蒸气' %self.name)
class Water(H2O):
pass
class Ice(H2O):
pass
class Steam(H2O):
pass
w1 = Water('水',25)
i1 =Ice('冰',-20)
s1 = Steam('蒸汽',3000)
# w1.turn_ice()
# i1.turn_ice()
# s1.turn_ice()
def func(obj):
obj.turn_ice()
func(w1)
func(i1)多态的概念指出了对象如何通过他们共同的属性和动作来操作及访问,而不需要考虑他们具体的类,多态表明了动态(又名,运行时)绑定的存在,允计重载及运行时类型确定和验证
面向对象三大特征:封装、多态、继承
封装:
1、一个下划线的是私有属性,是一种约定,和调用者的约定,不应该去调用这个是一个下划线开头的,但是你要强制调用也可以,python没有强制限定不给调用
2、两个下划线的也是私有属性,一般外部是调用不到的,因为类内部给它变了个名字,换名字的格式是 _类名__名字 ,例如以下例子
class People:
__star = 'earth'
def __init__(self,name,age):
self.name=name
self.age=age
p1 = People('地球',2434)
print(p1._People__star)
print(People.__dict__) #{'__module__': '__main__', '_People__star': 'earth',_star 变成了 _People__star
类的继承有两层意义:1、改变 2、扩展
多态就是类的这两层意义的一个具体的实现机制
即,调用不同的类实例化得对象下的相同的方法,实现的过程不一样
python中的标准类型就是多态概念的一个很好的示范
第三个层面的封装:明确区分内外,内部的实现逻辑,外部无法知晓r并且为封装到内部的逻辑提供一个访问接口给外部使用(这才是真正的封装,具体实现,会在面向对象进阶中讲)
#!/usr/bin/python3
class People:
__star = 'earth'
def __init__(self,name,age):
self.name=name
self.age=age
#访问函数
def get_star(self):
print(self.__star)
p1 = People('地球',2434)
p1.get_star()通过在内部定义一个访问函数(接口函数),外部可以使用这个函数来调用
第一个层面的封装,类就是麻袋,这本身就是一种封装
第二个层面的封装:类中定义私有的,只在类的内部使用,外部无法访问呢
反射:
属性的增删改查
#hasattr 查看类中是否有这个方法或属性,参数一:对象,参数二:字符串类型的名字
getattr 获取这个类中的方法或属性的值 , 参数一:对象,参数二:字符串类型的名字,参数三:默认值
#setattr 参数一:对象,参数二:属性或者方法,参数三:对应的值
#delattr() 参数一:对象,参数二:字符串类型的名字
#!/usr/bin/python3
class Blackmdium:
def __init__(self,name,addr):
self.name=name
self.addr=addr
def sell_house(self):
print('%s sell house'%self.name)
b1 = Blackmdium('万达','北京')
# #hasattr 查看类中是否有这个方法或属性,参数一:对象,参数二:字符串类型的名字
# print(hasattr(b1,'addr')) #True
# print(hasattr(b1,'n')) #False
#getattr 获取这个类中的方法或属性的值 , 参数一:对象,参数二:字符串类型的名字,参数三:默认值None,可有可没有
print(getattr(b1,'addr')) #北京
print(getattr(b1,'sell_house')) #返回一个函数的地址<bound method Blackmdium.sell_house of <__main__.Blackmdium object at 0x00000
func = getattr(b1,'sell_house')
func() #万达 sell house
print(getattr(b1,'housdde','没有这个参数'))#没有默认参数找不到就报错,填了默认参数,找不到就输出填的默认参数的数据 #没有这个参数
#setattr 参数一:对象,参数二:属性或者方法,参数三:对应的值
setattr(b1,'sb',100)
setattr(b1,'func',lambda x:x+1)
print(b1.func(10))
print(b1.__dict__) #{'name': '万达', 'addr': '北京', 'sb': 100}
#delattr() 参数一:对象,参数二:字符串类型的名字
# del b1.sb
delattr(b1,'sb')
print(b1.__dict__)
使用例子
#ftp_client.py
class FtpClient:
def __init__(self,addr):
self.addr=addr
print('正在连接服务器[%s]' %addr)
def put(self):
print('正在上传文件')
#使用者
from ftp_client import FtpClient
ftp = FtpClient('ftp://172.16.17.32')
if hasattr(ftp, 'put'):
getattr(ftp, 'put')()
else:
print('执行其他逻辑')动态导入模块
module_t = __import__('m1.t')
# print(module_t)
module_t.t.test()
动态导入模块中有隐藏的方法函数
from m1.t import test1,_test2
test1() #test1
_test2() #test2
#m1.t
def test1():
print("test1")
def _test2():
print("test2")importlib
#这个方法可以调用有下划线开头的方法函数
import importlib
m = importlib.import_module('m1.t')
print(m) #<module 'm1.t'
m.test1()#test1
m._test2() #test2双下划线开头的attr方法
#!/usr/bin/python3
class Foo:
def __getattr__(self, attr):
print('-----__getattr__:你找的属性[%s]不存在------'%attr)
def __setattr__(self, attr, value):
print('-----__setattr__------')
self.__dict__[attr] = value #应该使用它
def __delattr__(self, attr):
print('-----__delattr__------')
self.__dict__.pop(attr)
print(dir(Foo))
foo = Foo()
print(foo.x) #只有在属性不存在时,会自动触发__getattr__,这个最有用
#设置属性的时候会出发__setattr__
foo.y = 10
foo.x = 3
del foo.x #删除属性时会触发 __delattr__
item方法:
class Foo:
def __getitem__(self, item):
print('getitem',item)
def __setitem__(self, item, value):
print('setitem')
self.__dict__[item] = value
def __delitem__(self, item):
print('delitem')
# del self.__dict__[item]#一样的
self.__dict__.pop(item)
f1 = Foo()
print(f1.__dict__)
# f1.name = 'egon'
f1['name'] = 'zhazha'
f1['age'] = 434
print(f1.__dict__)
f1.__delitem__('name')
# del f1.age
print(f1.__dict__)
print(f1['age'])注意attr 和 item的区别
用点的方式调用就是用attr的方法,用中括号字典的方式就是用item的方法
str方法:
python下一切皆对象
调用对象的时候返回系统定义好的东西,但是我们可以自己定义打印对象的时候返回的值
class Foo:
def __init__(self,name,age):
self.name = name
self.age = age
def __str__(self):
return '名字是%s 年龄是:%s' % (self.name,self.age)
f1 = Foo('zhouzhou',13)
print(f1) # --str(f1)-->f1.__str__() #名字是zhouzhou 年龄是:13
x = str(f1)
print(x) #名字是zhouzhou 年龄是:13
y = f1.__str__()
print(y)repr
class Foo:
def __init__(self,name,age):
self.name = name
self.age = age
def __str__(self):
return '这是str'
def __repr__(self):
return '名字是%s 年龄是:%s' % (self.name,self.age)
f1 = Foo('zz',18)
# repr(f1)-->f1.__repr__
#print 先调用__str如果没有就调用repr
print(f1) #名字是zz 年龄是:18 #str(f1)-->f1.__str__()--->f1.__repr__()repr和str的区别
repr和str都是用来print的输出print 先调用__str如果没有就调用repr
继承的方式包装
#!/usr/bin/python3
class List(list):
def append(self, item):
if type(item) is str:
super().append(item)
else:
print('【%s】不是str类型' %item)
l1 = List('helloworld')
l1.append('python')
print(l1) #['h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd', 'python']授权
授权是包装的一个特性,包装一个类型通常是对已存在的类型的一些定制,这种做法可以新建,修改或删除原有产品的功能。其它的则保持原样。授权的过程,即是所有更新的功能都是由新类的某部分来处理,但已存在的功能就授权给对象的默认属性。
实现授权的关键点就是覆盖__getattr__方法
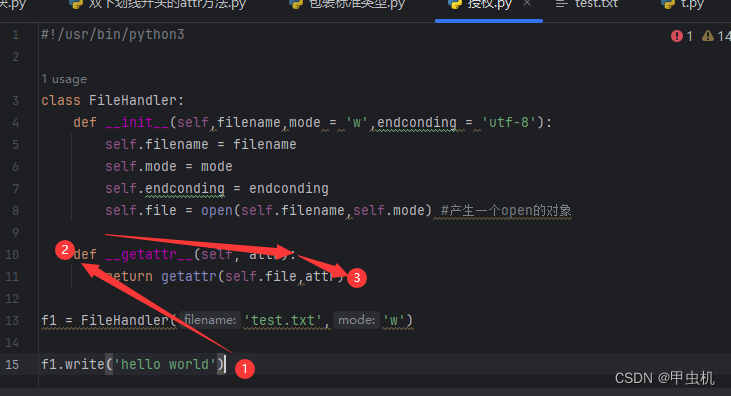
import time
class FileHandler:
def __init__(self,filename,mode = 'w',endconding = 'utf-8'):
self.filename = filename
self.mode = mode
self.endconding = endconding
self.file = open(self.filename,self.mode) #产生一个open的对象 , 关键的一步
#重写write方法
def write(self,line):
t = time.strftime('%Y-%m-%d %X')
self.file.write('%s %s' %(t,line))
#如果没有重写write方法则会调用这里的函数
def __getattr__(self, attr):
return getattr(self.file,attr)
f1 = FileHandler('test.txt','w+')
f1.write('helloworld\n')
f1.write('cpu过载\n')
f1.seek(0)
print(f1.read())
"""
输出:
2024-05-26 17:42:47 helloworld
2024-05-26 17:42:47 cpu过载
"""自定制format格式:
class Date:
def __init__(self, year, month, day):
self.year = year
self.month = month
self.day = day
def __format__(self, format_spec):
# print('我执行啦', format_spec)
if not format_spec or format_spec not in format_dic:
format_spec = 'ymd'
fm = format_dic[format_spec]
return fm.format(self)
d1 = Date(2020, 1, 11)
format(d1,'ymd') #d1.__format__()
print(format(d1)) #不写打印默认
print(format(d1,'m-y-d')) #按照指定字典的格式打印
print(format(d1,'md')) #不在字典里打印默认析构函数:
class Foo:
def __init__(self,name):
self.name = name
def __del__(self):
print('析构函数')
f1 = Foo('hh')
del f1.name
print('------')
"""
输出:
------
析构函数
"""
class Foo:
def __init__(self,name):
self.name = name
def __del__(self):
print('析构函数')
f1 = Foo('hh')
del f1.name
print('------')
del f1
print('------')
"""
输出:
------
析构函数
------
"""对象调用完会调用析构函数,也可以自己执行析构函数
call方法:
用对象加括号的方式就可以调用类的__call__方法
class Foo:
def __call__(self):
print('nihaoo')
foo = Foo()
foo() #Foo 下的 __call__方法
迭代器协议
在类中定义iter方法和next方法
class Foo:
def __init__(self,n):
self.n = n
def __iter__(self):
return self
def __next__(self):
if self.n == 13:
raise StopIteration('超出异常')
self.n += 1
return self.n
f1 = Foo(10)
print(f1.__next__())
print(next(f1)) # next(f1) --- > f1.__next__
print(next(f1)) # next(f1) --- > f1.__next__
print(next(f1)) # next(f1) --- > f1.__next__















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









