







一,BigInteger
(一)BigInteger 概述
Java的BigInteger类是一个用于处理任意精度的整型数据的主类。它位于java.math包中,属于Java标准库的一部分。BigInteger可以用于进行大整数的算术运算,包括加减乘除等操作,并且可以表示的整数范围不受Java的Integer类型(在Java中是int)的限制。
BigInteger有两种使用方式,一种是作为基本类型的封装器,另一种是作为BigInteger对象的引用。作为基本类型的封装器时,BigInteger对象包含了一个int类型的字段,该字段存储了要表示的整数值。作为BigInteger对象的引用时,BigInteger对象存储了一个指向实际数据的引用,该数据可能是一个数组或一个更复杂的数据结构。
BigInteger类提供了一系列的方法来实现各种数学运算。例如,add方法用于加法运算,subtract方法用于减法运算,multiply方法用于乘法运算,divide方法用于除法运算。此外,BigInteger还提供了诸如mod方法(求模)、pow方法(求幂)等其他方法。
注意:BigInteger的运算结果通常是新的BigInteger对象,而不是直接修改原有的BigInteger对象。此外,对于加法和乘法运算,BigInteger实现了循环向前和循环向后的模式,这意味着当操作超出可表示的整数范围时,不会发生溢出错误,而是会回绕到可表示的整数范围的另一端。例如,2^31 + 1会返回-2。
总结来说,BigInteger是一个非常强大的工具,用于在Java中处理任意精度的整数,它适合于需要处理超出普通整数范围或者需要精确计算的场景。
(二)BigInteger 的构造方法
BigInteger类在Java中提供了以下几种构造方法:
BigInteger(int value):将给定的int类型值转换为BigInteger类型。BigInteger(String val):将给定的字符串表示形式的数值转换为BigInteger类型。需要注意的是,该字符串必须表示一个整数,否则会抛出NumberFormatException异常。BigInteger(String val, int radix):将给定的字符串表示形式的数值转换为BigInteger类型,并指定进制数。例如,如果val是"1010",并且radix是2,那么BigInteger的值就是10。BigInteger(int[] bits):根据给定的位数组创建一个BigInteger对象。数组的每个元素代表BigInteger对象的一个位,从最高位开始。BigInteger(byte[] bytes, boolean isUnsigned):根据给定的字节数组创建一个BigInteger对象。如果isUnsigned为true,那么可以创建无符号的BigInteger对象,否则创建的是有符号的BigInteger对象。BigInteger(byte[] bytes, int signum):根据给定的字节数组和符号创建一个BigInteger对象。如果signum是正数或零,那么创建的是有符号的BigInteger对象;如果signum是负数,那么创建的是无符号的BigInteger对象。
这些构造方法可以根据需求灵活选择,以满足不同情况下的整数表示和计算需求。
(三)BigInteger 的底层存储方法
BigInteger的底层存储方式是使用一个int的数组来存储大整数的各个位。具体来说,BigInteger的底层数组是一个名为mag的int数组,用于存储绝对值的二进制位。当要存储的整数大于32位时,就会将整数分割成32位为一组的形式,每组作为底层数组的一个元素。同时,BigInteger还使用一个名为signum的整数来存储该大整数的符号,signum为0代表该大整数为0,signum为1代表该大整数为正数,signum为-1代表该大整数为负数。
在BigInteger中,底层数组mag是按照大端序(即最高有效字节在前)存储的,并且数组的索引是从0开始的。也就是说,mag[0]存储的是整数的最高32位,mag[1]存储的是次高32位,以此类推。
这种底层存储方式使得BigInteger可以方便地进行算术运算,例如加法、乘法等。在进行运算时,可以直接对底层数组进行操作,而不需要进行任何的位运算或调整。同时,由于使用了大端序存储,也使得BigInteger在进行一些特定运算时可以更加高效。
(四)BigInteger 的存储上限
BigInteger的存储上限主要取决于存储空间和计算能力。理论上,BigInteger的存储上限是2126(约等于3.7乘以1038),这远远超过了Java中int类型的最大值2^31 - 1(约等于2.1乘以10^9)。因此,BigInteger可以存储的整数大小远远超过了int类型可以存储的范围。
然而,实际上,由于计算机的存储和计算资源的限制,BigInteger能够存储的整数大小也是有限的。例如,计算机的内存和CPU都有一定的限制,如果BigInteger的存储空间超过了计算机的可用内存大小,那么将无法创建过大的BigInteger对象。此外,在进行大整数的算术运算时,也需要消耗大量的CPU资源,如果BigInteger的运算量超过了计算机的计算能力,那么将无法进行过大的计算操作。
因此,虽然BigInteger理论上没有存储上限,但在实际应用中,需要根据计算机的存储和计算能力进行合理的选择和优化,以确保BigInteger的使用效率和性能。
(五)BigInteger 的常见操作
BigInteger类提供了许多常见的数学运算操作,包括加法、减法、乘法、除法、取余数等。以下是BigInteger类的常见操作方法:
- 加法:add(BigInteger val)
- 减法:subtract(BigInteger val)
- 乘法:multiply(BigInteger val)
- 除法:divide(BigInteger val),返回商,余数为0
- 取余数:remainder(BigInteger val),返回余数
- 绝对值:abs(),返回绝对值
- 相反数:negate(),返回相反数
- 与操作:and(BigInteger val)
- 或操作:or(BigInteger val)
- 异或操作:xor(BigInteger val)
- 非操作:not()
- 左移操作:shiftLeft(int distance)
- 右移操作:shiftRight(int distance)
- 按位与操作:and(BigInteger val)
- 按位或操作:or(BigInteger val)
- 按位异或操作:xor(BigInteger val)
- 按位非操作:not()
- 判断是否为质数:probablePrime(int certainty),返回true表示可能是质数,false表示不是质数
- 返回可能是合数的概率:nextProbablePrime(),返回大于此BigInteger的有可能是质数的概率
除了上述常见的数学运算操作外,BigInteger类还提供了其他一些操作,例如将数据转换为字符串、比较大小、获取位数等。具体可以查看BigInteger类的API文档。
二,BigDecimal
(一)BigDecimal 概述
BigDecimal是Java中提供的一个类,用于对超过16位有效位的数进行精确的运算。它提供了一种使用BigDecimal对象进行数学运算的方法。这个类提供了一系列的方法,可以用于对BigDecimal对象进行加、减、乘、除等基本算术运算,以及取绝对值、取相反数、求幂运算等其他操作。
BigDecimal的构造方法包括:
- BigDecimal(double val):将一个double类型的值构造为一个BigDecimal对象。
- BigDecimal(String val):将一个字符串表示的值构造为一个BigDecimal对象。
BigDecimal类提供了一系列的方法,可以用于对BigDecimal对象进行算术运算,例如加法、减法、乘法、除法等。此外,还可以使用其他方法对BigDecimal对象进行位运算,例如按位与、按位或等。
由于BigDecimal是Java的一个类,因此它提供了线程安全的特性。在多线程环境下,可以放心地使用BigDecimal进行数学运算,而不需要担心精度问题。
总之,BigDecimal是Java中提供的一个用于对超过16位有效位的数进行精确运算的类。它提供了一系列的方法,可以用于对BigDecimal对象进行算术运算和位运算等操作。
(二)BigDecimal 的构造方法
在Java中,BigDecimal类提供了多种构造方法,可以根据不同的需求创建BigDecimal对象。以下是BigDecimal类的一些常用构造方法:
BigDecimal(double val): 根据一个double类型的值创建BigDecimal对象。BigDecimal(String val): 根据一个字符串表示的值创建BigDecimal对象。BigDecimal(BigInteger val): 根据一个BigInteger类型的值创建BigDecimal对象。BigDecimal(int val): 根据一个int类型的值创建BigDecimal对象。BigDecimal(long val): 根据一个long类型的值创建BigDecimal对象。BigDecimal(String val, int scale): 根据一个字符串表示的值和指定位数的小数点位置创建BigDecimal对象。
这些构造方法提供了灵活的创建BigDecimal对象的方式,可以根据需要进行选择。
(三)BigDecimal 的底层存储方法
BigDecimal在Java中是使用一个BigInteger对象来存储数值,并使用一个int型变量来存储小数点的位置。它的底层实现是使用双精度浮点数来存储数值,并使用一个整数来存储小数点的位置。具体来说,当创建一个BigDecimal对象时,如果传入的是一个整数值,则该值会被转换为一个BigInteger对象,并且小数点位置默认为0;如果传入的是一个浮点数值,则该值会被拆分为整数部分和小数部分,并分别用一个BigInteger对象和一个int型变量来存储。在进行加减乘除等运算时,BigDecimal会先将两个操作数的小数点位置对齐,并将其整数部分和小数部分分别相加、相减、相乘、相除等。在这个过程中,BigDecimal会根据需要调整小数点位置,并且在计算完成后将结果存储为一个新的BigDecimal对象。
(四)BigDecimal 的常见操作
BigDecimal类提供了许多常见操作,包括加法、减法、乘法、除法、取余数等。以下是BigDecimal类的常见操作方法:
- 加法:add(BigDecimal val)。
- 减法:subtract(BigDecimal val)。
- 乘法:multiply(BigDecimal val)。
- 除法:divide(BigDecimal val, int scale, int roundingMode)。其中,scale表示小数点位置,roundingMode表示舍入模式。
- 取余数:remainder(BigDecimal val)。
- 绝对值:abs()。
- 相反数:negate()。
- 比较大小:compareTo(BigDecimal val)。
- 转换为double类型:doubleValue()。
- 转换为int类型:intValue()。
- 转换为long类型:longValue()。
- 转换为BigInteger类型:BigIntegerValue()。
此外,还可以使用setScale()方法设置小数点位置,使用setRoundingMode()方法设置舍入模式等。
总之,BigDecimal类提供了许多常见操作,可以用于对BigDecimal对象进行算术运算和格式化操作等。在使用时,可以根据具体需求选择适当的方法进行操作。
三,正则表达式
(一)正则表达式概述
Java正则表达式是一种强大的工具,用于在Java中匹配、搜索、替换、验证等操作。它是正则表达式语言的一种实现,该语言被广泛用于文本处理和数据提取。
正则表达式由一系列字符和特殊符号组成,可以用来描述和匹配字符串的模式。通过使用正则表达式,我们可以方便地搜索、提取、替换文本中的特定部分。
Java中的正则表达式主要通过java.util.regex包中的类和方法来实现。这个包提供了三个主要的类:Pattern、Matcher和MatchResult。
- Pattern类:用于编译正则表达式,将其转换为可重复使用的形式。
- Matcher类:用于在文本中搜索匹配正则表达式的字符串,并对匹配的字符串执行各种操作。
- MatchResult类:用于保存Matcher找到的匹配结果。
(二)正则入门案例 - 校验QQ号
需求:假设现在要校验一个QQ号是否正确。
规则:6位及20位之内,0不能在开头,必须全部是数字。
-
不使用正则表达式校验
以下是使用Java来实现QQ号校验的代码:
public class QQNumberValidator { public static boolean isValidQQNumber(String qqNumber) { if (qqNumber == null || qqNumber.length() > 20 || qqNumber.length() < 6) { return false; } if (qqNumber.charAt(0) == '0') { return false; } for (int i = 0; i < qqNumber.length(); i++) { if (qqNumber.charAt(i) < '0' || qqNumber.charAt(i) > '9') { return false; } } return true; } public static void main(String[] args) { String qqNumber1 = "123456"; // 6位QQ号 String qqNumber2 = "12345678901234567890"; // 20位QQ号 String qqNumber3 = "123A456"; // 非数字开头 String qqNumber4 = "012345"; // 首位为0 System.out.println(isValidQQNumber(qqNumber1)); // true System.out.println(isValidQQNumber(qqNumber2)); // true System.out.println(isValidQQNumber(qqNumber3)); // false System.out.println(isValidQQNumber(qqNumber4)); // false } }该代码中,我们通过字符串长度、字符串第一个字符和字符串中每个字符的判断来实现QQ号的校验。首先,我们判断字符串长度是否在6位和20位之间;然后,我们判断字符串第一个字符是否为数字;最后,我们遍历字符串中的每个字符,判断是否都是数字。如果以上条件都满足,则返回true,否则返回false。
-
使用正则表达式校验
在Java中,你可以使用正则表达式来校验QQ号。以下是一个简单的示例:
import java.util.regex.Pattern; import java.util.regex.Matcher; public class QQNumberValidator { public static boolean isValidQQNumber(String qqNumber) { // 正则表达式,表示以非0数字开头,后面跟着5-19位的数字 String regex = "^[1-9][0-9]{5,19}$"; Pattern pattern = Pattern.compile(regex); Matcher matcher = pattern.matcher(qqNumber); return matcher.matches(); } public static void main(String[] args) { String qqNumber1 = "123456"; // 6位QQ号 String qqNumber2 = "12345678901234567890"; // 20位QQ号 String qqNumber3 = "123A456"; // 非数字开头 String qqNumber4 = "012345"; // 首位为0 System.out.println(isValidQQNumber(qqNumber1)); // true System.out.println(isValidQQNumber(qqNumber2)); // true System.out.println(isValidQQNumber(qqNumber3)); // false System.out.println(isValidQQNumber(qqNumber4)); // false } }在这个代码中,我们使用了正则表达式
^[1-9][0-9]{5,19}$来匹配QQ号。这个正则表达式表示:字符串必须以非0数字开头,后面跟着5到19位的数字。^表示字符串的开头,[1-9]表示非0的数字,[0-9]{5,19}表示后面跟着5到19位的数字,$表示字符串的结尾。然后我们使用Pattern.compile()方法来编译这个正则表达式,再使用Matcher对象来匹配待校验的QQ号。如果QQ号符合规则,matches()方法返回true,否则返回false。
(三)正则表达式的基本规则
正则表达式是一种用于匹配和操作文本的模式匹配工具。以下是正则表达式的一些基本规则:
-
字面量:正则表达式可以直接以字面形式写在代码中,例如,匹配所有的数字可以写为
\d。 -
元字符:元字符是正则表达式中具有特殊含义的字符,包括
.、*、?、+、^、$、[...]、[...]、{...}等。- `.:**代表匹配任意单个字符;
- `*:**代表匹配前面的子表达式零次或多次;
- `?:**代表匹配前面的子表达式一次或零次;
- `+:**代表匹配前面的子表达式一次或多次;
- `^:**表示行的开头,即从前往后开始匹配;
- `$:**表示行的结尾,即从后往前开始匹配;
- `[…]:**表示可以匹配的字符集合;
- `[^…]:**表示不包括在字符集合中的字符;
- `{…}:**表示匹配的次数,例如{3}表示前面的子表达式正好匹配3次。
-
转义:某些字符在正则表达式中有特殊的含义,如果要匹配这些字符本身,就需要使用反斜杠进行转义,例如
\d匹配数字字符。 -
字符类:使用方括号括起来的字符集合表示可以匹配的字符集合,例如
[a-z]表示匹配小写字母a到z中的任意一个。 -
分组和捕获:使用括号可以将一组字符组合起来作为一个整体进行匹配和操作,还可以通过括号内的子表达式进行捕获。
-
反查:使用
\d匹配单词边界,\D匹配非单词边界。 -
否定:在字符类中使用
^表示否定,例如[^a-z]表示除了小写字母a到z之外的任意字符。 -
锚定:使用
^和$分别表示字符串的开头和结尾,例如^abc$表示只匹配字符串abc。 -
选择、交替和管道:使用管道符号
|表示选择,例如a|b|c表示匹配a或b或c。 -
重复:使用星号、加号、问号等符号表示重复次数,例如
a*表示零次或多次重复,a+表示一次或多次重复,a?表示零次或一次重复。
这些规则是正则表达式的基础,通过灵活运用这些规则可以实现各种复杂的模式匹配和操作。
(四)IDEA 常用的正则表达式插件
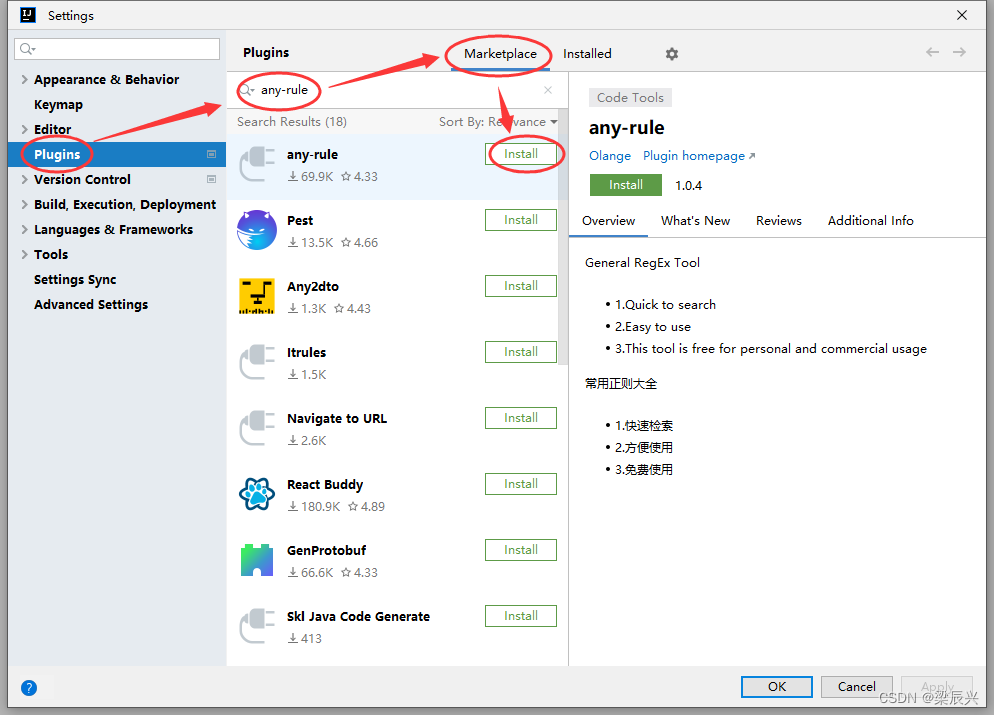
1.单击【File】-【Settings…】

2.选择【Plugins】-【Marketplace】- 在搜索框输入【ang-rule】- 单击右边【Install】按钮,安装插件
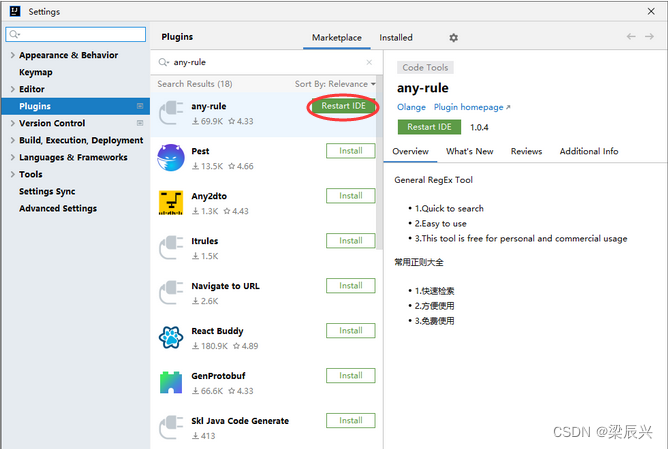
3.单击【Restart IDE】按钮,重启软件
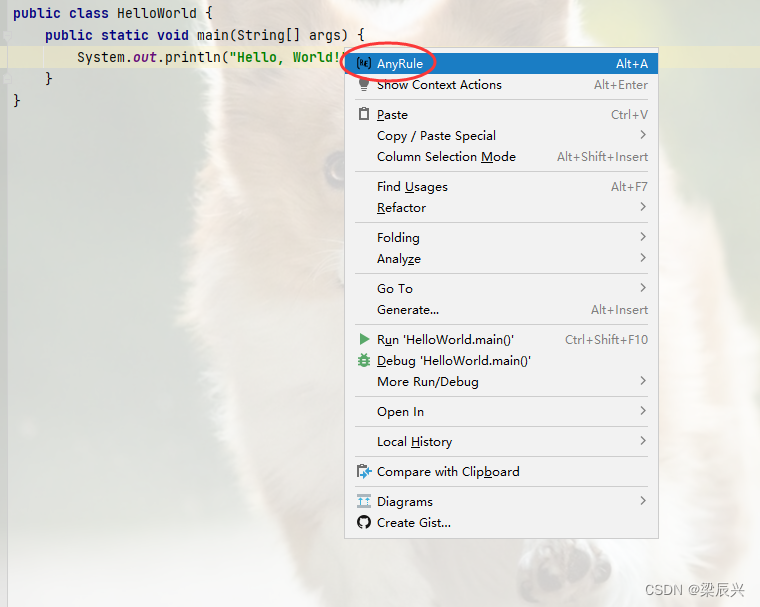
4.此时右击代码区,在弹出的菜单中选择【AnyRule】
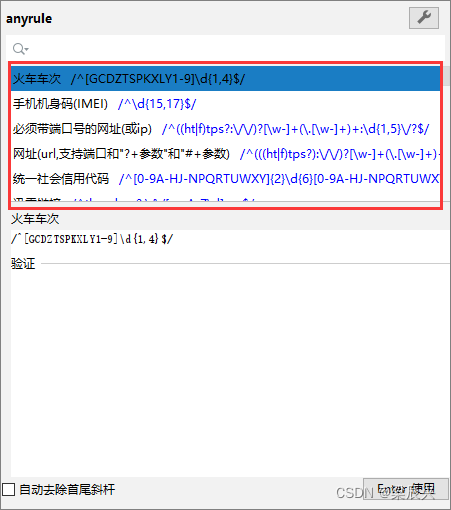
5.会有一些设定好的正则表达式可以直接使用
四,爬虫
(一)爬虫简介
Java爬虫是一种网络爬虫技术,它使用Java编程语言来实现自动化采集、处理和存储海量数据。这种技术通过模拟浏览器行为,自动访问网站并提取所需数据,为后续的数据分析、挖掘等工作提供了基础。
Java爬虫主要由以下三个部分组成:
- 爬虫框架:Java爬虫通常使用特定的框架来帮助编写和组织代码,例如Jsoup、HttpClient等。
- 解析库:Java爬虫需要使用解析库来解析网页内容,提取所需数据。解析库通常包括DOM解析器、XPath解析器、正则表达式等。
- 数据存储:爬取的数据需要被存储到本地文件、数据库或其他存储设备中,以便后续处理和分析。Java爬虫可以使用Java的文件I/O、JDBC连接等机制来实现数据存储。
使用Java爬虫可以很方便地实现网页爬取、图片爬取、音频爬取等多种类型的爬取任务,但是在实际应用中也需要注意反爬虫策略、并发处理等问题,以避免触犯目标网站的法律和规定,同时也要尊重目标网站的隐私和安全。
(二)本地爬虫和网络爬虫
Java本地爬虫和网络爬虫的主要区别在于它们爬取的对象和范围不同。
Java本地爬虫通常针对本地文件或网络资源进行爬取、分析和处理。这种爬虫程序通常不需要访问互联网,而是针对本地文件系统或局域网内的资源进行爬取。例如,一些网站会定期更新它们的本地文件,这时就可以使用Java本地爬虫来监控这些文件的更新,并将更新的内容爬取下来。
Java网络爬虫则是一种自动化程序,能够在互联网上自动抓取、分析和收集数据。它们按照一定的规则和算法,遍历互联网上的网页,收集数据并将其存储在本地计算机或数据库中,以供后续分析和利用。Java网络爬虫可以用于很多不同的领域,例如搜索引擎、数据挖掘、竞争情报、价格监测等等。
除此之外,Java网络爬虫和Java本地爬虫在实现技术上也有所不同。Java网络爬虫需要使用HTTP请求来访问网站,并使用HTML解析器来解析网页内容,因此需要更多的网络编程和协议知识。而Java本地爬虫则需要使用本地文件I/O或数据库API来读取和处理数据。
总之,Java本地爬虫和Java网络爬虫是两种不同的爬虫技术,它们分别针对本地资源和互联网上的网页进行爬取、分析和处理。
(三)练习
练习一
有如下文本,请按照要求爬取数据。
Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台。
要求:找出里面所有的JavaXX
实例代码:
package net.army.java.test;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 功能:爬取JavaXX
* 日期:2023年09月13日
* 作者:梁辰兴
*/
public class Test {
public static void main(String[] args) {
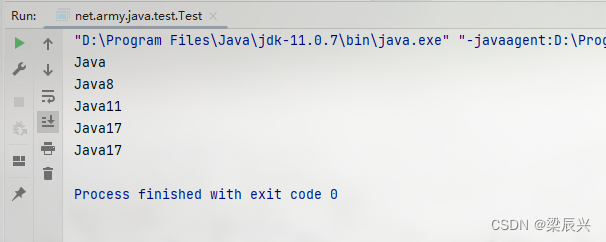
String text = "Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台。";
Pattern pattern = Pattern.compile("Java\\d{0,2}");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
String javaVersion = matcher.group();
System.out.println(javaVersion);
}
}
}
运行效果:
练习二
需求:把下面文本中的电话,邮箱,手机号和热线都爬取出来。
在CSDN学习编程,
电话:18888888000,18886666000
联系邮箱:csdn@abc.cn
座机电话:010-98745621,01025465485
邮箱:csdn@abc.cn
热线电话:400-342-4040,400-342-6060,4003424040,4003426060
要从文本中提取电话号码、邮箱和热线号码,可以使用正则表达式进行匹配。下面是一个示例代码,可以满足您的需求:
package net.army.java.test;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 功能:爬取联系方式
* 日期:2023年09月13日
* 作者:梁辰兴
*/
public class Test1 {
public static void main(String[] args) {
String text = "在CSDN学习编程,\n" +
"电话:18888888000,18886666000\n" +
"联系邮箱:csdn@abc.cn\n" +
"座机电话:010-98745621,01025465485\n" +
"邮箱:csdn@abc.cn\n" +
"热线电话:400-342-4040,400-342-6060,4003424040,4003426060";
extractPhoneNumbers(text);
extractEmails(text);
extractHotlineNumbers(text);
}
private static void extractPhoneNumbers(String text) {
Pattern pattern = Pattern.compile("(?<!\\d)(1\\d{10})(?!\\d)|(\\d{3}-\\d{8}|\\d{4}-\\d{7})(?!\\d)");
Matcher matcher = pattern.matcher(text);
System.out.println("Phone Numbers:");
while (matcher.find()) {
String phoneNumber = matcher.group();
System.out.println(phoneNumber);
}
System.out.println();
}
private static void extractEmails(String text) {
Pattern pattern = Pattern.compile("\\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\\.[A-Za-z]{2,}\\b");
Matcher matcher = pattern.matcher(text);
System.out.println("Emails:");
while (matcher.find()) {
String email = matcher.group();
System.out.println(email);
}
System.out.println();
}
private static void extractHotlineNumbers(String text) {
Pattern pattern = Pattern.compile("(?<!\\d)(400-\\d{3}-\\d{4}|400\\d{7})(?!\\d)");
Matcher matcher = pattern.matcher(text);
System.out.println("Hotline Numbers:");
while (matcher.find()) {
String hotlineNumber = matcher.group();
System.out.println(hotlineNumber);
}
System.out.println();
}
}
运行上述代码会输出以下结果:
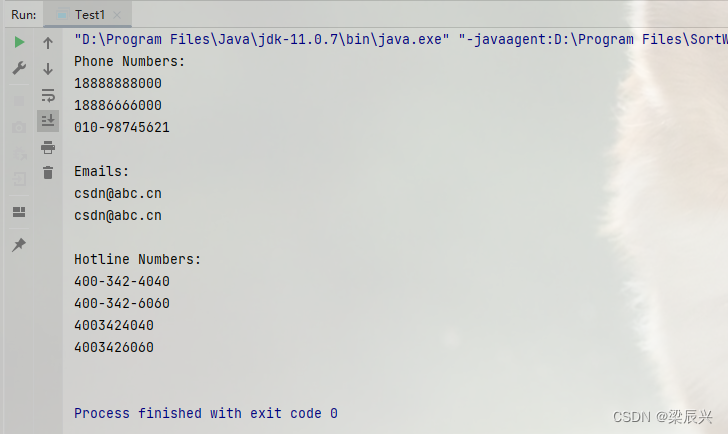
该代码通过正则表达式匹配提取了电话号码、邮箱和热线号码,并将它们分别打印出来。
练习三
有如下文本,请按照要求爬取数据。
Java自从95年问世以来,经历了很多版本,目前企业中使用最多的是Java8和Java11,因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会登上历史舞台。
需求1:爬取版本号为8,11,17的Java文本,但是只要Java不显示版本号,正确的输出 结果为:JavaJavaJavaJava。
需求2:爬取版本号为8,11,17的Java文本,正确爬取结果为:Java8Java11Java17Java17。
需求3:爬取除了版本号为8,11,17的Java文本,正确的输出结果为:java。
需求1:爬取版本号为8,11,17的Java文本,但是只要Java不显示版本号,正确的输出结果为:JavaJavaJavaJava。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class JavaVersionExtractor {
public static void main(String[] args) {
String text = "Java自从95年问世以来,经历了很多版本,目前企业中使用最多的是Java8和Java11,因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会登上历史舞台。";
extractJavaWithoutVersion(text);
}
private static void extractJavaWithoutVersion(String text) {
Pattern pattern = Pattern.compile("(?i)Java(?!(?:8|11|17))");
Matcher matcher = pattern.matcher(text);
StringBuilder result = new StringBuilder();
while (matcher.find()) {
String javaText = matcher.group();
result.append(javaText);
}
System.out.println(result.toString());
}
}
运行上述代码会输出以下结果:
JavaJavaJavaJava
需求2:爬取版本号为8,11,17的Java文本,正确爬取结果为:Java8Java11Java17Java17。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class JavaVersionExtractor {
public static void main(String[] args) {
String text = "Java自从95年问世以来,经历了很多版本,目前企业中使用最多的是Java8和Java11,因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会登上历史舞台。";
extractJavaWithVersion(text);
}
private static void extractJavaWithVersion(String text) {
Pattern pattern = Pattern.compile("(?i)Java(?:8|11|17)");
Matcher matcher = pattern.matcher(text);
StringBuilder result = new StringBuilder();
while (matcher.find()) {
String javaText = matcher.group();
result.append(javaText);
}
System.out.println(result.toString());
}
}
运行上述代码会输出以下结果:
Java8Java11Java17Java17
需求3:爬取除了版本号为8,11,17的Java文本,正确的输出结果为:java。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class JavaVersionExtractor {
public static void main(String[] args) {
String text = "Java自从95年问世以来,经历了很多版本,目前企业中使用最多的是Java8和Java11,因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会登上历史舞台。";
extractOtherJavaVersions(text);
}
private static void extractOtherJavaVersions(String text) {
Pattern pattern = Pattern.compile("(?i)Java(?!8|11|17)");
Matcher matcher = pattern.matcher(text);
StringBuilder result = new StringBuilder();
while (matcher.find()) {
String javaText = matcher.group();
result.append(javaText);
}
System.out.println(result.toString());
}
}
运行上述代码会输出以下结果:
java
练习四
有如下文本,请按照要求爬取数据。
Java自从95年问世以来,abbbbbbbbbbaaaaaaaaaaaaaaa经历了许多版本,目前企业中用的做多的是Java8和Java11,因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史的舞台。
需求1:按照ab+的方式爬取ab,b尽可能的多获取。
需求2:按照ab+的方式爬取ab,b尽可能的少获取。
需求1:按照ab+的方式爬取ab,b尽可能的多获取。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class AbCrawler {
public static void main(String[] args) {
String text = "Java自从95年问世以来,abbbbbbbbbbaaaaaaaaaaaaaaa经历了许多版本,目前企业中用的做多的是Java8和Java11,因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史的舞台。";
extractAbWithMaxB(text);
}
private static void extractAbWithMaxB(String text) {
Pattern pattern = Pattern.compile("ab+");
Matcher matcher = pattern.matcher(text);
StringBuilder result = new StringBuilder();
while (matcher.find()) {
String abText = matcher.group();
result.append(abText);
}
System.out.println(result.toString());
}
}
运行上述代码会输出以下结果:
abbbbbbbbbb
需求2:按照ab+的方式爬取ab,b尽可能的少获取。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class AbCrawler {
public static void main(String[] args) {
String text = "Java自从95年问世以来,abbbbbbbbbbaaaaaaaaaaaaaaa经历了许多版本,目前企业中用的做多的是Java8和Java11,因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史的舞台。";
extractAbWithMinB(text);
}
private static void extractAbWithMinB(String text) {
Pattern pattern = Pattern.compile("ab+?");
Matcher matcher = pattern.matcher(text);
StringBuilder result = new StringBuilder();
while (matcher.find()) {
String abText = matcher.group();
result.append(abText);
}
System.out.println(result.toString());
}
}
运行上述代码会输出以下结果:
ab
(四)识别正则的两个方法
在Java中,识别正则表达式的两个方法是使用Pattern和Matcher类以及String类的matches()方法。
方法1:使用Pattern和Matcher类
Pattern类代表一个正则表达式的模式,Matcher类用于在输入字符串中执行匹配操作。
示例代码:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexExample {
public static void main(String[] args) {
String text = "Hello, world!";
String regex = "Hello";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(text);
if (matcher.find()) {
System.out.println("匹配成功");
} else {
System.out.println("未找到匹配");
}
}
}
方法2:使用String类的matches()方法
String类提供了一个matches()方法,它可以直接使用正则表达式对字符串进行匹配。
示例代码:
public class RegexExample {
public static void main(String[] args) {
String text = "Hello, world!";
String regex = "Hello";
if (text.matches(regex)) {
System.out.println("匹配成功");
} else {
System.out.println("未找到匹配");
}
}
}
这两个方法都可以用于在Java中识别正则表达式,你可以根据具体的需求选择使用哪种方法。
(五)捕获分组和非捕获分组
在Java中,可以使用捕获分组和非捕获分组来提取正则表达式匹配结果中的特定部分。
捕获分组:
捕获分组使用括号 () 将需要捕获的部分括起来,可以通过匹配到的分组索引来提取捕获到的内容。
示例代码:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexExample {
public static void main(String[] args) {
String text = "Hello, world!";
String regex = "Hello, (\\w+)!";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(text);
if (matcher.find()) {
String capturedGroup = matcher.group(1);
System.out.println("捕获分组内容: " + capturedGroup);
}
}
}
在上面的示例中,正则表达式 “Hello, (\w+)!” 中的 “(\w+)” 是一个捕获分组,它会匹配一个或多个字母、数字或下划线字符。通过调用 Matcher 对象的 group(1) 方法,可以获取到捕获分组的内容。
非捕获分组:
非捕获分组使用语法 (?:pattern) 表示,它用于分组但不捕获其中的内容。非捕获分组在匹配时不会将其内容保存在匹配结果中,因此在提取匹配结果时只会获取到捕获分组的内容。
示例代码:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexExample {
public static void main(String[] args) {
String text = "Hello, world!";
String regex = "Hello, (?:\\w+)!";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(text);
if (matcher.find()) {
String capturedGroup = matcher.group(0);
System.out.println("非捕获分组内容: " + capturedGroup);
}
}
}
在上面的示例中,正则表达式 “Hello, (?:\w+)!” 中的 “(?:\w+)” 是一个非捕获分组。尽管这个分组匹配了一个或多个字母、数字或下划线字符,但在调用 Matcher 对象的 group(0) 方法时,只能获取到整个匹配结果,而不能获取到非捕获分组的内容。
通过使用捕获分组和非捕获分组,可以根据自己的需求提取正则表达式匹配结果中的特定部分。
















 209
209











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











