






SQL(Structured Query Lanauage)
Mysql的登陆与退出
登录
登录
mysql -uroot -p3.14159265358
mysql -hip -u(用户名) -p(密码)
退出
exit
quitmysql目录结构
数据库:文件夹
表:文件
数据
SQL的通用语法
- SQL语句可以单行或多行书写,以分号结尾
- 可以使用空格和缩进增强语句的可读性
- mysql数据库的sql语句不区分大小写,关键字建议大写
- 3种注释
- 单行注释:--注释内容 或 #注释
- 多行注释:/*注释*/
Sql分类
| 分类 | 全称 | 说明 |
| DDL | 数据定义语言,用于定义数据库对象(数据库,表,字段) | |
| DML | 数据操作语言,用于对数据库表中的数据进行增删改 | |
| DQL | 数据查询语言,用于查询数据库中表的记录 | |
| DCL | 数据控制语言,用来创建数据库用户,控制数据库的方法权限 |
数据类型:

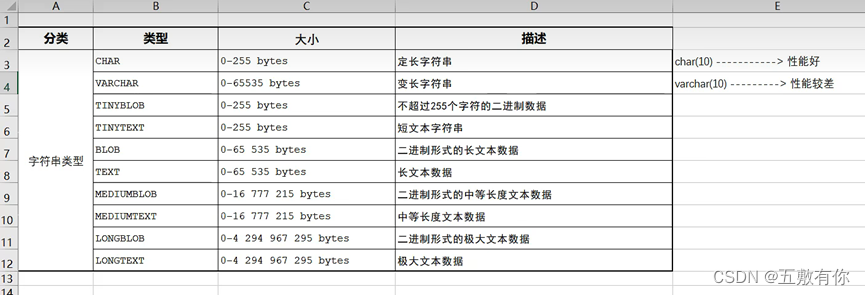

DDL
数据库操作
查询:show databases;
查询当前数据库:select database();
创建数据库:create database[if not exists] 数据库名 [default charset 字符集] [collate 排序规则]
删除:drop database [if exists] 数据库名
使用:use 数据库名表操作-查询
查询当前数据库所有表:show tables;
查询表结构:desc 表名;
查询指定表的建表语句:show create table 表名;表操作-创建
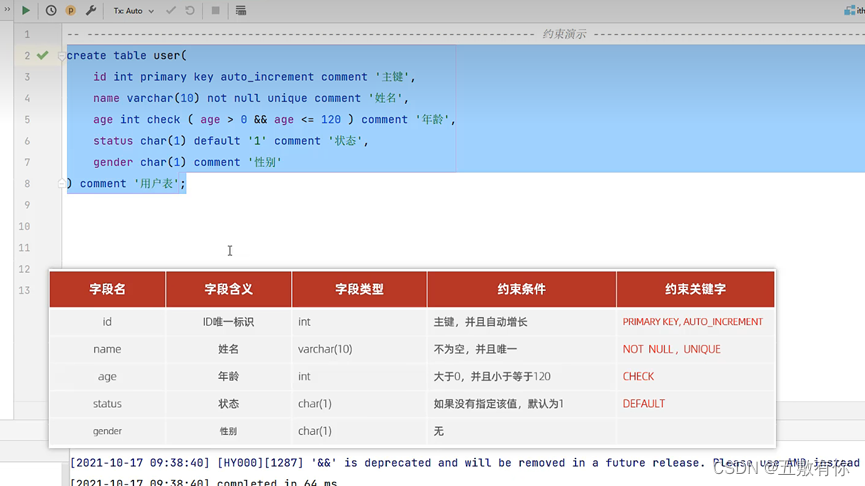
create table 表名(
字段1 类型 [COMMENT 字段1注释],
字段2 类型 [COMMENT 字段2注释],
字段3 类型 [COMMENT 字段3注释],
。。。
字段n 类型 [COMMENT 字段n注释]
)[COMMENT 表注释]表修改-修改
添加字段
alter table 表名 add 字段名 类型(长度) [comment 注释] [约束]
修改数据类型
alter table 表名 modify 字段名 新数据类型;
修改字段名和数据类型
alter table 表名 change 旧字段名 新字段名 类型 [comment 注释][约束]
删除字段
alter table 表名 drop 字段名
修改表名
alter table 表名 rename to 新表名表操作-删除
删除表
drop table [if exists] 表名
删除指定表,并重新创建该表
truncate table 表名DML
DML-添加数据
给指定字段添加数据
insert into 表名(字段名1,字段名2,...) values(值1,值2);
给全部字段添加数据
insert into 表名 values(值1,值2);
批量添加数据
insert into 表名(字段名1,字段名2,...)values(值1,值2...),(值1,值2...),(值1,值2...);
insert into 表名 values(值1,值2,...),(值1,值2,...)(值1,值2,...),(值1,值2,...);注意:
- 插入数据时,指定的字段顺序需要与值的顺序一一对应的。
- 字符串和日期类型应该包含在引号中。
- 插入的数据大小,应该在字段的规定范围之内。
DML-修改数据
update 表名 set 字段名=值1,字段名2=值2,...[where 条件]
注意:
修改语句的条件可有可无。没有条件就会修改整张表DML-删除数据
delete from 表名 [where 条件]
注意:
delete语句的条件可有可无,没有就删除整张表的所有数据。
delete语句不能删除某个字段的值,(可以用update)DQL
DQL-基本查询
查询多个字段
select 字段1,字段2,...from 表名;
select * from 表名;
设置别名
select 字段1[AS 别名],字段2[AS 别名]...from 表名;
去除重复记录
select distinct 字段列表 from 表名;DQL-条件查询
1、语法:select 字段列表 from 表名 where 条件列表
2、条件
| 比较运算符 | 功能 |
| < = > != | 小于 等于 大于 不等于 |
| between...and... | 在某个范围之内(包含边界) |
| in(...) | 在in之后的列表中的值,多选一 |
| LIKE 占位符 | 模糊匹配(_ 匹配单个字符,%匹配任意个字符) |
| IS NULL | 是null |
| AND 或 && | 并且(多个条件同时成立) |
| OR 或 || | 或者(多个条件成立一个) |
| NOT 或 ! | 非,不是 |
DQL-聚合函数
1、介绍
将一列数据作为一个整体,进行纵向计算
2、常见的聚合函数
| 函数 | 功能 |
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
3、语法:select 聚合函数(字段列表) from 表名
注意:null值不参与任何聚合函数的运算
DQL-分组查询
- 语法:
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后的过滤条件] - where与having区别:
- 执行时机不同:where是分组前进行过滤,不满足where条件,不参与分组; 而having是分组之后对结果进行过滤。
- 判断条件不同:where不能对聚合函数进行判断。而having可以。
DQL-排序查询
- 语法
select 字段列表 from 表名 order by 字段1 排序方法1,字段2 排序方式2;-
排序方式:
- asc : 升序(默认值)
- desc : 降序
注意:如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序。

DQL-分页查询
语法:select 字段列表 from 表名 limit 起始索引,查询记录数;
注意:起始索引从0开始,起始索引=(查询页码-1)*每页显示记录数
分页查询是数据库的方言,不同数据库有不同的实现,Mysql是LIMIT
如果查询的是第一页数据,起始索引可以省略,直接写为limit 10
DCL
DCL-管理用户
查询用户
use mysql;
select * from user;
创建用户:
create user '用户名' @ ’主机名‘ identified by '密码';
修改用户密码:
alter user ’用户'@'主机名' identified with mysql_native_password by '新密码';
删除用户:
drop user ‘用户名'@'主机名'注意:
- 主机名可以使用%通配。
- 这类SQL开发人员操作比较少。主要是DBA(数据库管理员)使用
DCL-权限控制
| 权限 | 说明 |
| ALL、ALL PRIVILEGES | 所有权限 |
| select | 查询数据 |
| insert | 插入数据 |
| update | 修改数据 |
| delete | 删除数据 |
| alter | 修改表 |
| drop | 删除数据库/表/视图 |
| create | 创建数据库/表 |
DCL-权限控制
查询权限
show grants for '用户名'@'主机';
授予权限
grant 权限列表 on 数据库.表名 to '用户名'@'主机名';
撤销权限
revoke 权限列表 on 数据库名.表名 from '用户名'@'主机名';注意:
- 多个权限之间,使用逗号进行分割
- 授权时,数据库名和表名可以用*通配,代表所有
函数
字符串函数
| 函数 | 功能 |
| concat(s1,s2,...sn) | 字符串拼接,将s1、s2...sn拼成一个字符串 |
| lower(str) | 将字符串全部转为小写 |
| upper(str) | 将字符串全部转为大写 |
| lpad(str,n,pad) | 左填充,用字符串pad对str的左边进行填充,达到n个字符串的长度 |
| rpad(str,n,pad) | 右填充,用字符串pad对str进行右边填充,达到n个字符串长度 |
| trim(str) | 去掉字符串头部与尾部的空格 |
| subtring(str,start,len) | 返回字符串从start位置起len个长度的字符串 |
流程函数
流程函数可以在sql语句中实现筛选,从而提高语句的效率
| 函数 | 功能 |
| if(value,t,f) | 如果value是true,返回 t ,否则返回 f |
| ifnull(value1,value2) | 如果value1不为空,返回value1,否则返回value2 |
| case when [val1] then [res] ... else [default] end | 如果val1为true,返回res1,...否则返回default默认值 |
| case [expr] when [val1] then [res1]...else [default] end | 如果expr的值等于val1,返回res1,否则返回default默认值 |

约束
- 概念:
约束是作用于表中字段上的规则,用于限制存储在表中的数据
- 目的:保证数据库中数据的正确性、有效性和完整性
- 分类:
| 约束 | 描述 | 关键字 |
| 非空约束 | 限制字段的数据不能为null | NOT NULL |
| 唯一约束 | 保证字段的所有数据都是唯一,不重复的 | UNIQUE |
| 主键约束 | 主键是一行数据的唯一标识,要求非空且唯一 | PRIMARY KEY |
| 默认约束 | 保存数据时未指定该字段的值,则采用默认值 | DEFAULT |
| 外键约束 | 用于两张表的数据之间建立联系,保证数据的一致性和完整性 | FOREIGN KEY |
注意:约束是作用于表中字段上的,可以在创建表、修改表的适合添加约束
外键约束
语法:
//创建表添加外键
create table 表名(
字段名 数据类型,
...
[constraint] [外键名称] FOREIGN KEY(外键字段名) REFERENCES 主表(主列表名)
);
//修改表添加外键
alter table 表名 add constraint[外键名称](外键字段名) FOREIGN KEY(外键字段名) REFERENCES 主表(主列表名);
//删除外键
alter table 表名 DROP FOREIGN KEY 外键名称删除/更新行为:
| 行为 | 说明 |
| NO ACTION | 在删除/更新记录时,首先检查记录是否有外键,如果有则不允许删除与更新 |
| RESTRICT | 与NO ACTION一样 |
| CASCADE | 在删除/更新记录时,首先检查该记录是否有外键,有则也删除/更新外键在子表中的记录 |
| SET NULL | 在父表中删除对应记录时,首先检查该记录是否有对应的外键,有则设置其子表中外键值为null,(允许才行) |
| SET DEFAULT | 父表有变更,子表将外键列设置成一个默认值 |
- 语法:
alter tables 表名 add constraint 外键名 foreign key (外键字段) references 主表名(主表字段) on update cascade on cascade;多表查询:



数据库的三大范式:
(在遵循后面范式的要求,必须遵循之前的所有范式的要求)
第一范式:每一列都是不可分割的数据项
第二范式:在1NF的基础上,非码属性必须完全依赖于候选码(在1NF基础上消除非主属性对主码部分函数的依赖)
第三范式:在2NF的基础上,任何非主属性不依赖于其他非主属性(在2NF的基础上,消除传递依赖)
多表查询分类:
连接查询:
内连接:相当于A、B的交集
隐式内连接:
select 字段名列表 from 表1,表2 where 条件显式内连接:
select 字段列表 from 表1 inner join 表2 on 连接条件; 
外连接:(就算交集中没有,也会显示出来)
左外连接:查询左表的所有数据,以及两张表的部分数据
select 字段列表 from 表1,left join 表2 on 连接条件右外连接:查询右表的所有数据,以及两张表的部分数据
select 字段列表 from 表1 right join 表2 on 连接条件 

自连接:当前表与自身的连接进行查询,自连接必须使用表别名
![]()
联合查询--union,union all
对于union查询,就是把多次查询的结果合并起来形成一个新的查询结果集
语法:
select 字段列表 from 表A...
union[ALL]
select 字段列表 from 表B
//例子(输出的字段一致即可)
select id,name from sexer
union all
select p_id,p_name from sex_part;注意:
对于联合查询的多张表的字段列数必须保持一致,字段类型也需要保持一致
union all会将所有的数据进行合并在一起,union会对合并之后的数据进行去重
子查询(嵌套查询)
概念:SQL语句中,嵌套select语句,成为嵌套查询,又称子查询
语法: select * from t1 where column1=(select column1 from t2);子查询外部的语句可以是insert update delete select 的任何一个
根据子查询结果不同,分为:
- 标量子查询(子查询结果为单个值)
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式
常用操作符= <> > =
例子: select * from sexer where age=(select age from sexer where sexer.name='Rys');
- 列子查询(子查询结果为一列,重点是一列)
子查询返回的结果是一列(可以是多行)
常用操作符:
| in | 在指定的集合之内多选一 |
| not in | 不在指定的集合只内 |
| any | 子查询返回列表,有任意一个满足即可 |
| some | 与any一致 |
| all | 子查询返回的所有值必须都满足 |
例子:(只有一列age) select * from sexer where age=(select age from sexer where sexer.name='Rys');
- 行子查询(子查询结果为一行)
子查询返回的结果是一行(可以多列)
常用操作符:
= <> in not in
select id,name from sexer where (name,age)=(select name,age from sexer where id=1005)
- 表子查询(子查询结果为多行多列)
- (子查询结果只要是多列,肯定在 FROM 后面作为表)
- 子查询返回的结果是多行多列
- 常用操作符 in

事务
概念
事务是指一系列相关的操作,这些操作需要被视为一个整体来进行处理。在计算机科学中,事务通常是指对数据库进行的操作序列,这些操作必须满足一定的原子性、一致性、隔离性和持久性要求,以确保数据的正确性和完整性。
事务的特性:
原子性指在事务执行过程中,所有操作要么全部执行成功,要么全部不执行;
一致性指事务执行前后,数据应该保持一致性;
隔离性指多个事务同时执行时,彼此之间应该互相隔离,不应该相互影响;
持久性指事务执行后,对数据的修改应该永久保存在数据库中。
并发事务问题:
| 问题 | 描述 |
| 脏读 | 一个事务读到另一个事务还没有提交的数据 |
| 不可重复读 | 一个事务先后读取统一条数据,但两次读取的数据不同,称为不可重复读 |
| 幻读 | 一个事务按照条件查询数据时,没有对应的数据行,但在插入数据时,发现这行数据以及存在了,好像出现了‘幻影’ |
事务的隔离级别:
| 隔离级别 | 脏读 | 幻读 | 不可重复读 |
| Read uncommitted | √ | √ | √ |
| Read committed | × | √ | √ |
| Repeatable Read | × | × | √ |
| Serializable | × | × | × |
查看事务的隔离级别
查看事务的隔离级别
select @@transaction_isolation;
设置事务的隔离级别
set [session|global] transaction isolation level [read uncommitted|Read committed| | ...]索引
是帮助数据库高校获取数据的数据结构
优点:
- 提高数据查询的效率,降低数据库的IO成本
- 通过索引列表对数据进行排序,降低数据排序的成本,降低CPU的小号
缺点:
- 索引会占据存储空间。
- 索引大大提高了查询的效率,同时却降低了insert、update和delete的效率
结构
Mysql数据库支持的索引的索引结构很多。如:Hash索引、B+树等
B+树:(多路平衡搜索树)
操作语法:
创建索引
create [unique] index 索引名 on 表名(字段名);
查看索引
show index from 表名;
删除索引
drop index 索引名 on 表名;JDBC
概念:Java DataBase Connectivity java语言操作数据库
本质:是官方(sun)定义的一套操作所有关系型数据库的规则,即接口。各个数据库厂商去实现接口,提供数据库驱动jar包
这套接口,真正执行的代码是驱动jar包中的实现类
基础实现:
public static void main(String[] args) throws ClassNotFoundException, SQLException {
String url="jdbc:mysql://localhost:3306/user?serverTimezone=GMT";
String user="root";
String password="3.14159265358";
//2.注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");
Connection conn= DriverManager.getConnection(url,user,password);
Statement stmt=conn.createStatement();
String sql="select * from people ";
ResultSet res= stmt.executeQuery(sql);
while(res.next()){
Person p=new Person(res.getInt(1),res.getString(2),res.getInt(3),res.getString(4));
System.out.println(p.toString());
}
}JDBC各个类的对象
DriverManager
功能:
管理驱动对象
注册驱动:告诉程序使用哪个数据库驱动jar包
static void registerDriver(Driver driver): 注册与给定的驱动程序
写代码使用:class.forName("com.mysql.jdbc.Driver")
获取数据库的连接
方法:static Connection getConnection(String url,String name,String password)
参数:
url:路径
语法: jdbc:mysql://ip地址:端口//数据库名称?serverTimezone=GMTuser:用户名
password:密码
Connection:数据库连接对象
功能:
- 获取执行sql的对象
Statement createStatement();
PreparedStatement PrepareStatement
- 管理事务开启事务
SetAutoCommit(boolean autoCommit); 调用方法设置参数false 即开启事务。
提交事务
commit();
回滚事务
rollback();
Statement:执行sql的对象
- 执行sql
boolean execute(sql) 可以执行任意语句
ResultSet executeQueue(sql) 可以执行DML(DDL)语句,返回一个结果集
int executeUpdate(sql) 可以执行DQL语句 ,返回影响的行数
ResultSet:结果集对象
next(): 游标向下移动一行
getXxx(参数):获取数据
Xxx:代表数据类型,如:int getInt() ; String getString()
参数:
int: 代表列的编号(从1开始),如getString(1)
String: 代表列名称,如:getDouble("id”);
注意:
使用步骤:
游标向下移动一行
判断是否有数据
获取数据
while (res.next())
{
System.out.println(res.getInt("id")+res.getString("name")+"Rys");
}PrepareStatement:执行sql的对象
SQL注入问题:在拼接sql时,有一些sql的特殊关键字参与字符串的拼接,会造成安全性的问题
sql: select * from user where username='aksjdla' and password='a' or 'a'='a';解决问题:
预编译SQL:参数作为占位符
步骤:
导入驱动jar包
- 注册驱动
- 获取数据库连接对象
- 定义sql
注意:sql的参数使用?作为占位符 例子:
select * from user where username=? and password=?;获取sql语句的对象 PrepareStatement Connection.prepareStatement(String sql);
- 给?赋值
方法:setXxx(参数1,参数2)
参数1,?的位置编号,从1开始
参数2,?的值
执行sql,接受返回结果
- 处理结果
- 释放资源
JDBC工具类
数据库连接池
概念:其实就是一个容器(集合),存放数据库的容器
好处:
- 节约资源
- 用户访问高效
实现:
- 标准接口:DataSource javax.sql包下的
方法:
获取连接:getConnection()
归还连接:close() //代表归还连接
- 一般我们不去实现它,有数据库厂商实现
C3P0:数据库连接池技术
步骤:
- 导入jar包(两个)c3p0-0.9.5.2.jar mchange-commons-java-0.2.12.jar
- 定义配置文件
- 名称: c3p0.properties or c3p0-config.xml (必须是这两个名字)
- 路径:类路径指src目录下
- 创建核心对象 数据库连接对象 ComboPooledDataSource
- 获取连接: getConnection
Druid:数据库连接池实现技术,由阿里巴巴提供
步骤:
- 导入jar包 druid-1.0.9.jar
- 定义配置文件:
- 是properties 形式
- 可以叫任意名称,可以放在任意目录下
- 获取数据库连接池对象。通过工厂类获取 DruidDataSourceFactory
- 获取连接 getConnection
配置文件
driverClassName=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://127.0.0.1:3306/byshop?serverTimezone=PRC
username=root
password=3.14159265358
initialSize=10
minIdle=1
maxActive=10
maxWait=10000
timeBetweenEvictionRunsMillis=6000
minEvictableIdleTimeMillis=300000
testWhileIdle=true
testOnBorrow=true
testOnReturn=true
poolPreparedStatements=true
maxPoolPreparedStatementPerConnectionSize=20
validationQuery=select 1
filters=statpublic class JdbcUtils {
private static JdbcUtils instance;
DataSource dataSource;
/**
* 获取当前类的实例对象
*
* @return
*/
public static JdbcUtils getInstance() {
if (null == instance) {
instance = new JdbcUtils();
}
return instance;
}
/*
* 读取配置文件
* */
private JdbcUtils() {
//数据源配置
Properties prop = new Properties();
//读取配置文件
InputStream is = JdbcUtils.class.getResourceAsStream("/druid.properties");
try {
prop.load(is);
} catch (IOException e) {
e.printStackTrace();
}
try {
//返回的是DataSource
dataSource = DruidDataSourceFactory.createDataSource(prop);
} catch (Exception e) {
e.printStackTrace();
}
}
/**关闭链接
* @return
*/
public Connection getConnection() {
Connection conn = null;
try {
conn = dataSource.getConnection();
} catch (SQLException e) {
e.printStackTrace();
}
return conn;
}
}进阶篇=========》
下期再见,技术无极限!!!

















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











